技术动态 | 不确定性知识图谱的表示和推理
本文转载自漆桂林知乎。
作者 | 张嘉韬、漆桂林、吴天星
文章链接 |
https://zhuanlan.zhihu.com/p/369068016
随着近年人工智能的兴起,各种大型的通用知识图谱和领域知识图谱被构建出来,这些图谱在智能问答、语义搜索、辅助决策等应用中起到了重要作用。但在知识图谱的构建的过程中,始终存在着难以去除的噪声与错误,即不确定性,如何在对不确定性的知识图谱进行表示与推理逐渐引起广泛的关注。
一、知识图谱中的不确定性
有关不确定知识表示与推理的研究在人工智能和知识工程领域并不是什么新话题,早在1994年出版的人工智能领域的经典著作《人工智能——一种现代方法》[1]里就有整整五章的内容对于不确定知识表示与推理进行深入地探讨,其重要性可见一斑。知识图谱的不确定性表示方法早年就有一些研究成果,比如说fuzzy OWL, Probabilistic OWL[2] [3] [4] [5]。然而对于不确定性知识图谱的表示学习与推理的工作是近几年才引起大家的关注。
知识图谱中的不确定性主要来源于两方面:
首先是图谱构造过程中产生的噪声。早期的知识图谱通常由领域专家或人工标注的方式构建,然而大规模图谱的构建难以通过人工方式完成,越来越多的自动化方法参与到了图谱构建过程中,如关系抽取、实体匹配等,这些方法采用机器学习技术,所以往往会产生噪声和错误,许多噪声数据会随着图谱构造过程被保留到最后的图谱当中,并且难以被识别去除。
另一方面,一些知识本身就难以通过确定性的方式被表达。对于很多如医药、法律、金融等领域,许多知识往往带有很强的经验性与概率性,忽视这些性质而直接采用传统图谱三元组的方式表示这些知识是十分不准确甚至是错误的。
二、什么是不确定知识图谱
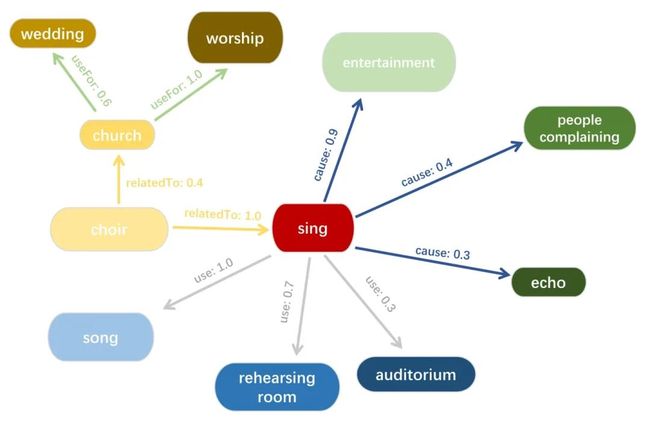
一些具有不确定性信息的开放知识图谱,如NELL[6]、ConceptNet[7]等,他们为每个三元组添加一个置信度来描述三元组的不确定性。形式化的来说,就是将我们通常知识图谱中三元组(h, r, t)拓展为<(h, r, t), s>,其中h、t代表头实体尾实体、r代表头尾实体之间的关系,s代表置信度。关于不确定性知识图谱的语法和语义,可以参考[2]。图1.给出了这样的一个例子。

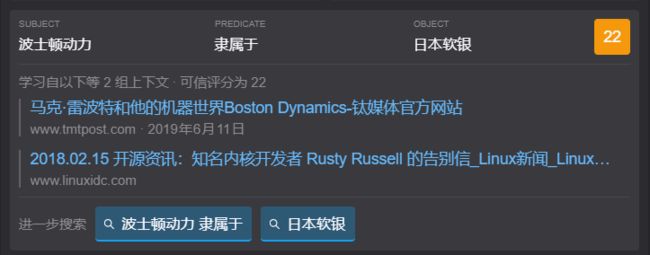
三元组的置信度是如何得到的呢?不同的知识库计算置信度的策略有所不同:ConceptNet中置信度是根据众包标注频率计算得到;而NELL则是通过EM算法计算得到的具有概率语义的置信度值;知识检索系统MAGI通过统计三元组的上下文数量计算置信度(如图2.所示)。对于图谱中三元组的置信度分数计算涉及到图谱质量评估方面的研究,比较有代表性的工作有CKRL[8]等。
确定性的知识图谱构建通常通过设定一个阈值过滤掉低质量的三元组从而保证图谱质量,不确定知识图谱构建则放松了知识都要是准确的和正确的这一假设,允许更多可能具有价值,但置信度较低的三元组保留下来,这样很大程度上提高了图谱的覆盖率,置信度的保留也更加方便了图谱的演化与更新。
三、不确定知识图谱表示学习与推理
如图3.所示,知识图谱表示学习的目标是将图谱中的实体和关系映射成低维、稠密的实值向量。表示学习能很好解决图表示具有的稀疏性,通过更加高效的计算实体和关系的语义联系,从而显著的提升了知识获取、融合和推理能力[9]。
 图3. 知识图谱表示学习
图3. 知识图谱表示学习
相较于确定性的知识图谱表示与推理,不确定知识图谱的表示与推理需要额外补全三元组的置信度。用通常的链接预测的形式来说,如果进行尾实体补全,传统知识图谱推理需要在给定头实体h和关系r的情况下预测尾实体t即(h, r, ?),而不确定知识图谱推理则需要额外预测推理结果的置信度,即<(h, r, ?), ?>。
对于确定性知识图谱来说,当前比较具有代表性的方法有TransE[10]、DistMult[11]、RESCAL[12]等,这些方法虽然在确定性知识图谱中有不错的效果,然而其并不适合直接应用于不确定知识图谱当中,面临的困难和挑战可分为三个方面:
首先是噪声问题,不确定知识图谱中通常具有较高比例的噪声数据,在该场景下传统的表示推理方法会学习到不准确的图谱表示,从而给出错误的推理结果;
其次是置信度或概率的嵌入及推理问题,传统表示推理方法既不能利用不确定三元组的置信度,也无法给出对于推理结果的置信度;
最后,是隐含信息的挖掘问题,在不确定知识图谱中,许多三元组所描述的事实可能是不够精确的,如何从大量的不精确的三元组中挖掘隐含的有效信息,需要模型具有较强的信息提取能力和归纳推理能力,这些点也是当前表示学习方法所缺少的。
为了解决以上方法存在的问题,当前一些研究从不同角度展开了不确定知识图谱的表示及推理的研究,这里介绍几个具有代表性的工作。
GTransE[14]的主要目标是提高表示模型在学习噪声数据上的鲁棒性,其主要思想是让模型更加专注于学习那些置信度更高的三元组,降低那些质量较差、置信度较低的三元组对实体及关系表示的贡献。具体来说,其基于TransE等表示方法所采用的Margin Loss,利用三元组的置信度动态的调整TransE中的Margin,让置信度更高的三元组的正负例间隔更大,而置信度较小的三元组正负例间隔更小,从而使得模型更加专注于置信度较高的三元组的学习,过程如图4.所示。采用类似思想的方法的还有CKRL[8],不过CKRL中则是将置信度直接乘以对应三元组的损失函数上,使得置信度较高的三元组具有更高的优化权重。
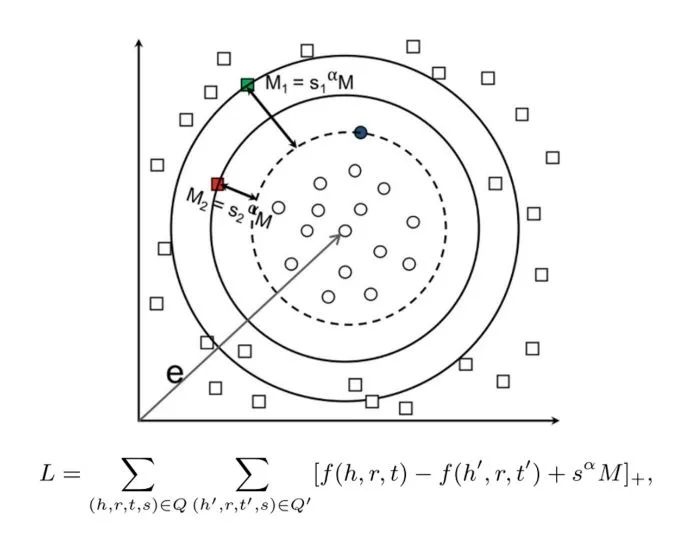
图4. GTransE
虽然以上方法从一定程度上提高了模型在噪声环境下的鲁棒性,然而其并没有将置信度的具体数值保留在嵌入空间当中,不能较为准确的预测一个三元组的置信度。UKGE[13]首先提出了不确定知识图谱表示学习任务,即实体与关系的表示向量需要同时嵌入图谱的结构信息与置信度信息。具体来说,其基于DistMult[11]的实体与关系的表示方法及能量函数,将原本的Margin Loss更改为MSE Loss来拟合三元组的置信度(如图5.所示),这样一方面将置信度信息嵌入到实体及关系的距离当中,另一方面只需要利用三元组的能量函数即可预测其置信度。
 图5. UKGE Loss Function
图5. UKGE Loss Function
此外,UKGE还引入规则作为先验知识,利用PSL概率软逻辑[15]的方式进行对unseen facts进行推理并将其也作为训练数据来训练embedding(如图6.所示),从而将规则的约束保留到嵌入表示当中。

四、我们的工作介绍
下面介绍两篇我们在这方面的工作
首先是被JIST 2019接收的一篇文章:Uncertain Ontology-aware Knowledge Graph Embeddings[16],当前已经有很多方法尝试对不确定知识图谱进行表示推理,然而其都关注于事实层面,缺少对具有不确定性的本体进行建模的方法,本文希望对包含:Subclass, Domain, Range, Subproperty, Type五类本体关系和数据层的Data类型数据进行建模。
实体、关系、概念的表示上,我们参考TransC[17]及EmbedS[18]的方式:将实体建模成n维空间中的点;概念建模为n维空间中的超球体;关系建模为2n维空间中超球体(也可认为是n维空间中的两个球体)分别用于建模关系的domain和range。这种建模方式的优势是可以直观的反应出来实体与概念、概念与概念间的关系。
与UKGE类似,我们利用实体、概念、关系在嵌入空间中的距离来表征图谱本体的语义关系和不确定性。具体来说,对于Subclass, Domain, Range, Sub-property, Type, Data六类关系,我们定义了六种距离函数分别进行描述,如图7.所示。
 图7. 距离函数定义
图7. 距离函数定义
举一个例子,如图8.所示,对于一个不确定性的三元组来说,其描述了的类型是,并且这条三元组的置信度为,根据上面的距离函数定义,理想情况下其在嵌入空间中的表示应如下图所示,可以看出,我们利用实体和概念之间的距离表征了置信度。

最后,我们在CN15K数据集进行了置信度预测和三元组分类两项实验,根据实验结果可以看出(如图9.),对比相关方法我们的方法在不确定本体推理方面的效果是最好的。
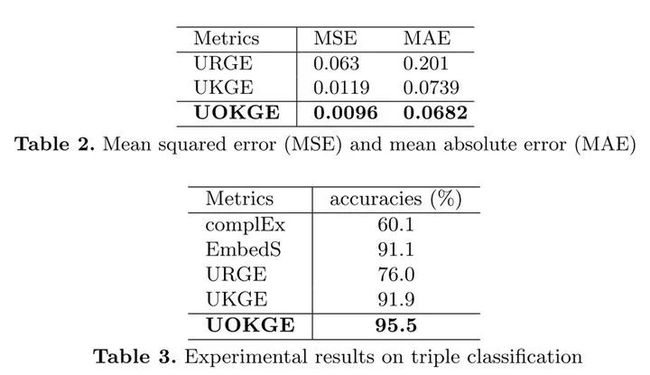 图9. 实验结果
图9. 实验结果
另外一篇是近期被DASFAA 2021接收的一篇文章:Gaussian Metric Learning for Few-Shot Uncertain Knowledge Graph Completion[19],本文主要希望解决以下问题:
不确定知识图谱中长尾关系的少样本问题:
由于知识图谱关系数量呈现长尾分布,即图谱中大部分的关系仅有少量三元组描述(如图10.)。当前的不确定知识图谱补全方法假设有充足的训练样本进行表示模型的训练,而对于这些长尾的关系来说,这些少量的样本显然不足以让模型上进行有效的训练,从而导致推理效果的下降。
 图10. 知识图谱中关系呈现长尾分布
图10. 知识图谱中关系呈现长尾分布
不确定知识图谱中实体及关系语义不确定性
在少样本设定情况下样本数量已经非常有限,然而更加困难的问题是,这些样本还存在很强的不确定性,这导致实体及关系的语义十分的模糊,使得模型无法学习到实体及关系准确的语义表示。举个例子,图11.是一些NELL中的真实数据,对于关系“synonymfor”(同义词)来说,根据常识我们知道,这个三元组比较准确的反映出了“synonymfor”的语义,而则是不准确的,而则是完全错误的,这些不准确或错误的数据都会让模型对于关系“synonymfor”进行不准确的表征,从而对于其本身的语义产生不确定性。
 图11. 关系及实体的语义不确定性
图11. 关系及实体的语义不确定性
针对以上两个问题,我们提出来一套基于高斯分布的度量学习方法,其主要思想是利用度量学习框架学习到的有效度量解决少样本的问题,利用Gaussian Embedding方式建模实体及关系的语义不确定性。
整体框架如图12.所示,对于关系“synonymfor”,模型仅有Support Set中的若干少样本的不确定三元组描述该关系,框架需要判定Query所描述的三元组是否属于该关系,并且给出置信度。框架首先通过一个Gaussian Encoder将Supports和Query都编码成Gaussian Embedding的形式,Gaussian Embedding由均值向量和方差向量构成,分别代表关系的语义信息和不确定信息。之后通过一个Gaussian Matching Function对两个Gaussian Embedding进行比较和度量。最后度量会给出Support 和Query的相似度及对该相似度的置信度,分别用来补全不确定知识图谱缺失的三元组及其置信度。
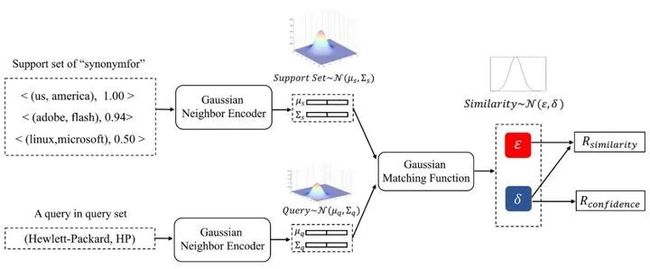 图12. 模型框架图
图12. 模型框架图
选择Gaussian Embedding的方式建模实体及关系的不确定性的主要动机是,相较于UKGE中同时在语义空间中嵌入语义信息和置信度信息,这种表示方法可以将语义表示和不确定性表示拆分到两个语义空间中,避免两种信息对彼此表示造成的混淆和干扰,也更加方便我们组合不同特征分别进行三元组的推理和置信度的推理。
如图13.所示,我们通过Gaussian Neighbor Encoder结构将Query和Support中的每个三元组编码成一个多维高斯分布,具体做法是利用两个Neighbor Encoder结构来分别编码高斯分布的均值和方差,对于Support来说,还需要对多个多维高斯分布进行聚合,聚合成为一个多维高斯分布。
 图13. Gaussian Neighbor Encoder结构图
图13. Gaussian Neighbor Encoder结构图
如图14.所示,Matching Function是Metric Learning方法的核心,需要对Support和Query的Gaussian Embedding进行度量比较,并给出相似度及置信度。这里我们将Metric也表示成为一个一维高斯分布,其均值代表匹配的相似度,方差表示对于该相似度的置信度。均值和方差分别通过一个基于LSTM的Matching Network进行计算,该模块可以将两个Embedding利用LSTM进行多次循环匹配,从而发现深层次的有效度量。最后,我们通过Metric这个一维高斯分布随机变量来计算Support和Query的similarity和confidence。
 图14. Gaussian Matching Function结构图
图14. Gaussian Matching Function结构图
为了测试模型在少样本以及不确定知识图谱中的表现,我们基于NL27K数据集构建了四个少样本的数据集:NL27K-N0/N1/N2/N3,分别加入0%、10%、20%、40%比例的噪声数据模拟真实的不确定性环境,设定Support Set的size为3,即对于每种关系仅可以观测到三个样本,数据集统计如图15.所示。最后利用CKRL[8]方法赋予每个三元组置信度。
 图15. 数据集统计
图15. 数据集统计
部分实验结果如图16.所示,可以看到没有针对少样本情况进行优化的UKGE在样本数量较少情况下表现不佳,而其他少样本的方法如FSRL[20]和GMatching[21]在没有噪声情况下具有较好的表现,而随着噪声比例越来越高,这些方法性能也随之下降,而我们的方法在所有数据集中都可以取得最好效果,不过对于高比例的噪声数据,如N3,效果依然有很大的提升空间。
 图16. 链接预测实验结果
图16. 链接预测实验结果
这里提供数据集及代码地址:https://github.com/zhangjiatao/GMUC
五、思考及总结
本篇文章我们介绍了不确定知识图谱的表示与推理,具体包括:知识图谱中的不确定性及其来源、不确定知识图谱定义、不确定知识图谱表示推理方法与挑战、一个少样本不确定性知识图谱推理方法等内容。
可以看出,不确定知识图谱的表示推理的中蕴含的假设更加接近真实场景,所以可以在许多方面进行应用:首先,在一些风险敏感性应用(如自动驾驶、投资决策等)中,模型错误的决策往往会造成非常大的风险或损失,这时不确定的表示及推理方法给出的置信度可以作为重要的决策依据,降低模型造成的风险及损失;其也可以应用于机器人当中,尤其当机器人处于陌生场景下,其对周围环境认知存在很大不确定性,可以利用不确定性表示及推理方法来支持其在认知受限场景下进行推理及行动,此外还可以基于置信度触发机器人和人类的交互,让人类帮助机器人进行学习,也让机器人认知过程更加接近人类。
参考文献
[1] Stuart J. Russell, Peter Norvig: Artificial intelligence: a modern approach[J]. 1994.
[2] Chang Liu, Guilin Qi, Haofen Wang, Yong Yu: Reasoning with Large Scale Ontologies in Fuzzy pD* Using MapReduce. IEEE Comput. Intell. Mag. 7(2): 54-66 (2012)
[3] Zhangquan Zhou, Guilin Qi, Chang Liu, Pascal Hitzler, Raghava Mutharaju: Reasoning with Fuzzy-EL+ Ontologies Using MapReduce. ECAI 2012: 933-934
[4] Raghav Ramachandran, Guilin Qi, Kewen Wang, Junhu Wang, John Thornton: Probabilistic Reasoning in DL-Lite. PRICAI 2012: 480-491
[5] Chang Liu, Guilin Qi: Toward Scalable Reasoning over Annotated RDF Data Using MapReduce. RR 2012: 238-241
[6] Tom M. Mitchell, William W. Cohen, Estevam R. Hruschka Jr. , et al. Never-ending learning[J]. Communications of the ACM, 2018, 61(5): 103-115.
[7] Robyn Speer, Catherine Havasi: ConceptNet 5: A Large Semantic Network for Relational Knowledge. The People's Web Meets NLP 2013: 161-176
[8] Ruobing Xie, Zhiyuan Liu, Fen Lin, Leyu Lin: Does William Shakespeare REALLY Write Hamlet? Knowledge Representation Learning With Confidence. AAAI 2018: 4954-4961
[9] 刘知远, 孙茂松, 林衍凯, 等. 知识表示学习研究进展[J]. 计算机研究与发展, 2016, 53(2): 247-261.
[10] Antoine Bordes, Nicolas Usunier, Alberto García-Durán, Jason Weston, Oksana Yakhnenko: Translating Embeddings for Modeling Multi-relational Data. NIPS 2013: 2787-2795
[11] Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, Li Deng: Embedding Entities and Relations for Learning and Inference in Knowledge Bases. ICLR (Poster) 2015
[12] Maximilian Nickel, Volker Tresp, Hans-Peter Kriegel: A Three-Way Model for Collective Learning on Multi-Relational Data. ICML 2011: 809-816
[13] Xuelu Chen, Muhao Chen, Weijia Shi, Yizhou Sun, Carlo Zaniolo: Embedding Uncertain Knowledge Graphs. AAAI 2019: 3363-3370
[14] Natthawut Kertkeidkachorn, Xin Liu, Ryutaro Ichise: GTransE: Generalizing Translation-Based Model on Uncertain Knowledge Graph Embedding. JSAI 2019: 170-178
[15] Kimmig A, Bach S, Broecheler M, et al. A short introduction to probabilistic soft logic[C]//Proceedings of the NIPS Workshop on Probabilistic Programming: Foundations and Applications. 2012: 1-4.
[16] Khaoula Boutouhami, Jiatao Zhang, Guilin Qi, Huan Gao: Uncertain Ontology-Aware Knowledge Graph Embeddings. JIST (2) 2019: 129-136
[17] Xin Lv, Lei Hou, Juanzi Li, Zhiyuan Liu: Differentiating Concepts and Instances for Knowledge Graph Embedding. EMNLP 2018: 1971-1979
[18] Gonzalo I. Diaz, Achille Fokoue, Mohammad Sadoghi: EmbedS: Scalable, Ontology-aware Graph Embeddings. EDBT 2018: 433-436
[19] Jiatao Zhang, Tianxing Wu, Guilin Qi: Gaussian Metric Learning for Few-Shot Uncertain Knowledge Graph Completion. DASFAA (1) 2021: 256-271
[20] Chuxu Zhang, Huaxiu Yao, Chao Huang, Meng Jiang, Zhenhui Li, Nitesh V. Chawla: Few-Shot Knowledge Graph Completion. AAAI 2020: 3041-3048
[21] Wenhan Xiong, Mo Yu, Shiyu Chang, Xiaoxiao Guo, William Yang Wang: One-Shot Relational Learning for Knowledge Graphs. EMNLP 2018: 1980-1990
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。