Pytorch实战第一步--用经典神经网络实现猫狗大战
文章目录
- 前言
-
一、猫狗大战数据集
二、pytorch实战
1.程序整体结构
2.读入数据
3.网络结构
4.网络结构
5测试
总结
-
- 总结
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
在目前的深度学习中,应用最广泛的框架是pytorch ,同时在计算机视觉领域最基础的任务是图像分类
单纯的算法和程序学习不能很快的进入这个行列,我们用猫狗大战这个最简单的图像分类数据集来实现我们的pytorch深度学习第一步
猫狗大战数据集下载地址
一、猫狗大战数据集
数据集来自 kaggle 上的一个竞赛:Dogs vs. Cats,训练集有25000张,猫狗各占一半。测试集12500张,没有标定是猫还是狗。
数据集下载地址 https://www.kaggle.com/cuimdi/catdog

二、pytorch实战
1.程序整体结构
代码如下(示例):
要求环境 pytorch >=1.22.读入数据
# getdata.py
import os
import torch.utils.data as data
from PIL import Image
import numpy as np
import torch
import torchvision.transforms as transforms
# 默认输入网络的图片大小 #ALEXNET 为227 #vgg16 为224 #lenet 200
IMAGE_H = 224
IMAGE_W = 224
# 定义一个转换关系,用于将图像数据转换成PyTorch的Tensor形式
data_transform = transforms.Compose([
transforms.ToTensor() # 转换成Tensor形式,并且数值归一化到[0.0, 1.0]
])
class DogsVSCatsDataset(data.Dataset): # 新建一个数据集类,并且需要继承PyTorch中的data.Dataset父类
def __init__(self, mode, dir): # 默认构造函数,传入数据集类别(训练或测试),以及数据集路径
self.mode = mode
self.list_img = [] # 新建一个image list,用于存放图片路径,注意是图片路径
self.list_label = [] # 新建一个label list,用于存放图片对应猫或狗的标签,其中数值0表示猫,1表示狗
self.data_size = 0 # 记录数据集大小
self.transform = data_transform # 转换关系
if self.mode == 'train': # 训练集模式下,需要提取图片的路径和标签
dir = dir + '/train/' # 训练集路径在"dir"/train/
for file in os.listdir(dir): # 遍历dir文件夹
self.list_img.append(dir + file) # 将图片路径和文件名添加至image list
self.data_size += 1 # 数据集增1
name = file.split(sep='.') # 分割文件名,"cat.0.jpg"将分割成"cat",".","jpg"3个元素
# label采用one-hot编码,"1,0"表示猫,"0,1"表示狗,任何情况只有一个位置为"1",在采用CrossEntropyLoss()计算Loss情况下,label只需要输入"1"的索引,即猫应输入0,狗应输入1
if name[0] == 'cat':
self.list_label.append(0) # 图片为猫,label为0
else:
self.list_label.append(1) # 图片为狗,label为1,注意:list_img和list_label中的内容是一一配对的
elif self.mode == 'test': # 测试集模式下,只需要提取图片路径就行
dir = dir + '/test/' # 测试集路径为"dir"/test/
for file in os.listdir(dir):
self.list_img.append(dir + file) # 添加图片路径至image list
self.data_size += 1
self.list_label.append(2) # 添加2作为label,实际未用到,也无意义
else:
return print('Undefined Dataset!')
def __getitem__(self, item): # 重载data.Dataset父类方法,获取数据集中数据内容
if self.mode == 'train': # 训练集模式下需要读取数据集的image和label
img = Image.open(self.list_img[item]) # 打开图片
img = img.resize((IMAGE_H, IMAGE_W)) # 将图片resize成统一大小
img = np.array(img)[:, :, :3] # 数据转换成numpy数组形式
label = self.list_label[item] # 获取image对应的label
return self.transform(img), torch.LongTensor([label]) # 将image和label转换成PyTorch形式并返回
elif self.mode == 'test': # 测试集只需读取image
img = Image.open(self.list_img[item])
img = img.resize((IMAGE_H, IMAGE_W))
img = np.array(img)[:, :, :3]
return self.transform(img) # 只返回image
else:
print('None')
def __len__(self):
return self.data_size # 返回数据集大小3.网络结构
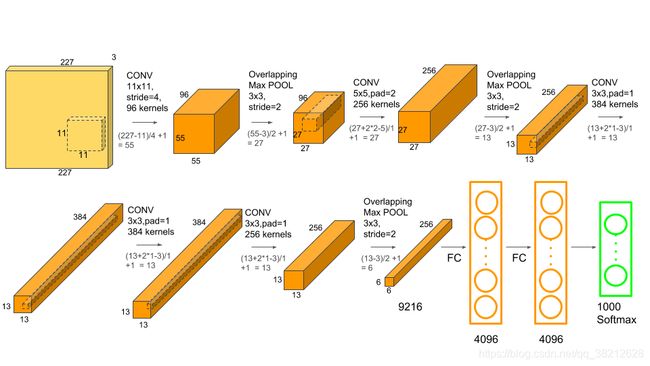 alexnet
alexnet
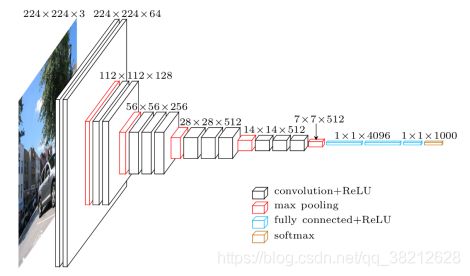 vgg
vgg
# network.py
import torch
import torch.nn as nn
import torch.utils.data
import torch.nn.functional as F
import torch.nn.utils.prune as prune
class Net(nn.Module): # 新建一个网络类,就是需要搭建的网络,必须继承PyTorch的nn.Module父类
def __init__(self): # 构造函数,用于设定网络层
super(Net, self).__init__() # 标准语句
self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1) # 第一个卷积层,输入通道数3,输出通道数16,卷积核大小3×3,padding大小1,其他参数默认
self.conv2 = torch.nn.Conv2d(16, 16, 3, padding=1) # 第二个卷积层,输入通道数16,输出通道数16,卷积核大小3×3,padding大小1,其他参数默认
self.fc1 = nn.Linear(50*50*16, 128) # 第一个全连层,线性连接,输入节点数50×50×16,输出节点数128
self.fc2 = nn.Linear(128, 64) # 第二个全连层,线性连接,输入节点数128,输出节点数64
self.fc3 = nn.Linear(64, 2) # 第三个全连层,线性连接,输入节点数64,输出节点数2
def forward(self, x): # 重写父类forward方法,即前向计算,通过该方法获取网络输入数据后的输出值
x = self.conv1(x) # 第一次卷积
x = F.relu(x) # 第一次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第一次池化,池化大小2×2,方式Max pooling
x = self.conv2(x) # 第二次卷积
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第二次池化,池化大小2×2,方式Max pooling
x = x.view(x.size()[0], -1) # 由于全连层输入的是一维张量,因此需要对输入的[50×50×16]格式数据排列成[40000×1]形式
x = F.relu(self.fc1(x)) # 第一次全连,ReLU激活
x = F.relu(self.fc2(x)) # 第二次全连,ReLU激活
x = self.fc3(x) # 第三次激活
return F.softmax(x, dim=1) # 采用SoftMax方法将输出的2个输出值调整至[0.0, 1.0],两者和为1,并返回
class LeNet(nn.Module):
def __init__(self): # 构造函数,用于设定网络层
super(LeNet, self).__init__() # 标准语句
self.conv1 = torch.nn.Conv2d(3, 6, 5) # 第一个卷积层,输入通道数3,输出通道数6,卷积核大小5×5,其他参数默认
self.conv2 = torch.nn.Conv2d(6, 16, 5) # 第二个卷积层,输入通道数6,输出通道数16,卷积核大小5×5,其他参数默认
self.conv3 = torch.nn.Conv2d(16,120,5) # 第三个卷积层,输入通道数16,输出通道数120,卷积核大小5×5,其他参数默认
self.fc1 = nn.Linear(43*43*120, 84) # 第一个全连层,线性连接,输入节点数50×50×16,输出节点数128
self.fc2 = nn.Linear(84, 2) # 第二个全连层,线性连接,输入节点数84,输出节点数2
def forward(self, x): # 重写父类forward方法,即前向计算,通过该方法获取网络输入数据后的输出值
x = self.conv1(x) # 第一次卷积 200-5+1=196
x = F.relu(x) # 第一次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第一次池化,池化大小2×2,方式Max pooling 196/2 =98
x = self.conv2(x) # 第二次卷积 98-5+1=94
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第二次池化,池化大小2×2,方式Max pooling 94/2=47
x = self.conv3(x) # 第三次卷积 47-5+1=43
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = x.view(x.size() [0], -1) # 由于全连层输入的是一维张量,因此需要对输入的[43×43×120]格式数据排列成一维形式
x = F.relu(self.fc1(x)) # 第一次全连,ReLU激活
x = self.fc2(x) # 第三次激活
return F.softmax(x, dim=1) # 采用SoftMax方法将输出的2个输出值调整至[0.0, 1.0],两者和为1,并返回
class AlexNet(nn.Module):
def __init__(self): # 构造函数,用于设定网络层
super(AlexNet, self).__init__() # 标准语句
self.conv1 = torch.nn.Conv2d(3, 96, 11, stride=4) # 第一个卷积层,输入通道数3,输出通道数6,卷积核大小5×5,其他参数默认
self.conv2 = torch.nn.Conv2d(96, 256, 5,padding=2) # 第二个卷积层,输入通道数6,输出通道数16,卷积核大小5×5,其他参数默认
self.conv3 = torch.nn.Conv2d(256,384, 3,padding=1) # 第三个卷积层,输入通道数16,输出通道数120,卷积核大小5×5,其他参数默认
self.conv4 = torch.nn.Conv2d(384, 384, 3, padding=1) # 第三个卷积层,输入通道数16,输出通道数120,卷积核大小5×5,其他参数默认
self.conv5 = torch.nn.Conv2d(384, 256, 3, padding=1) # 第三个卷积层,输入通道数16,输出通道数120,卷积核大小5×5,其他参数默认
self.fc1 = nn.Linear(6*6*256, 4096) # 第一个全连层,线性连接,输入节点数50×50×16,输出节点数128
self.fc2 = nn.Linear(4096, 4096) # 第二个全连层,线性连接,输入节点数84,输出节点数2
self.fc3 = nn.Linear(4096, 2) # 第二个全连层,线性连接,输入节点数84,输出节点数2
def forward(self, x): # 重写父类forward方法,即前向计算,通过该方法获取网络输入数据后的输出值
x = self.conv1(x) # 第一次卷积 200-5+1=196
x = F.relu(x) # 第一次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 3,stride =2) # 第一次池化,池化大小2×2,方式Max pooling 196/2 =98
x = self.conv2(x) # 第二次卷积 98-5+1=94
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 3,stride =2) # 第二次池化,池化大小2×2,方式Max pooling 94/2=47
x = self.conv3(x) # 第三次卷积 47-5+1=43
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = self.conv4(x) # 第三次卷积 47-5+1=43
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = self.conv5(x) # 第三次卷积 47-5+1=43
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 3, stride=2) # 第二次池化,池化大小2×2,方式Max pooling 94/2=47
x = x.view(x.size() [0], -1) # 由于全连层输入的是一维张量,因此需要对输入的[43×43×120]格式数据排列成一维形式
x = F.relu(self.fc1(x)) # 第一次全连,ReLU激活
x = F.relu(self.fc2(x)) # 第一次全连,ReLU激活
x = self.fc3(x) # 第三次激活
return F.softmax(x, dim=1) # 采用SoftMax方法将输出的2个输出值调整至[0.0, 1.0],两者和为1,并返回
class VGG16(nn.Module):
def __init__(self): # 构造函数,用于设定网络层
super(VGG16, self).__init__() # 标准语句
self.conv1 = torch.nn.Conv2d(3, 64, 3, padding=1) # 第一个卷积层,输入通道数3,输出通道数6,卷积核大小5×5,其他参数默认
self.conv2 = torch.nn.Conv2d(64, 128, 3,padding=1) # 第二个卷积层,输入通道数6,输出通道数16,卷积核大小5×5,其他参数默认
self.conv3 = torch.nn.Conv2d(128,256, 3,padding=1) # 第三个卷积层,输入通道数16,输出通道数120,卷积核大小5×5,其他参数默认
self.conv4 = torch.nn.Conv2d(256, 512, 3, padding=1) # 第三个卷积层,输入通道数16,输出通道数120,卷积核大小5×5,其他参数默认
self.conv5 = torch.nn.Conv2d(512, 512, 3, padding=1) # 第三个卷积层,输入通道数16,输出通道数120,卷积核大小5×5,其他参数默认
self.fc1 = nn.Linear(7*7*512, 4096) # 第一个全连层,线性连接,输入节点数50×50×16,输出节点数128
self.fc2 = nn.Linear(4096, 4096) # 第二个全连层,线性连接,输入节点数84,输出节点数2
self.fc3 = nn.Linear(4096, 2) # 第二个全连层,线性连接,输入节点数84,输出节点数2
def forward(self, x): # 重写父类forward方法,即前向计算,通过该方法获取网络输入数据后的输出值
x = self.conv1(x) # 第一次卷积 200-5+1=196
x = F.relu(x) # 第一次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第一次池化,池化大小2×2,方式Max pooling 196/2 =98
x = self.conv2(x) # 第二次卷积 98-5+1=94
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第二次池化,池化大小2×2,方式Max pooling 94/2=47
x = self.conv3(x) # 第三次卷积 47-5+1=43
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第二次池化,池化大小2×2,方式Max pooling 94/2=47
x = self.conv4(x) # 第三次卷积 47-5+1=43
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第二次池化,池化大小2×2,方式Max pooling 94/2=47
x = self.conv5(x) # 第三次卷积 47-5+1=43
x = F.relu(x) # 第二次卷积结果经过ReLU激活函数处理
x = F.max_pool2d(x, 2) # 第二次池化,池化大小2×2,方式Max pooling 94/2=47
x = x.view(x.size() [0], -1) # 由于全连层输入的是一维张量,因此需要对输入的[43×43×120]格式数据排列成一维形式
x = F.relu(self.fc1(x)) # 第一次全连,ReLU激活
x = F.relu(self.fc2(x)) # 第一次全连,ReLU激活
x = self.fc3(x) # 第三次激活
return F.softmax(x, dim=1) # 采用SoftMax方法将输出的2个输出值调整至[0.0, 1.0],两者和为1,并返回4.网络结构
# train.py
from getdata import DogsVSCatsDataset as DVCD
from torch.utils.data import DataLoader as DataLoader
from network import Net,LeNet,AlexNet,VGG16
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.utils.prune as prune
dataset_dir = './' # 数据集路径
model_cp = './' # 网络参数保存位置
workers = 0 # PyTorch读取数据线程数量
batch_size = 16 # batch_size大小
lr = 0.0001 # 学习率
def train():
datafile = DVCD('train', dataset_dir) # 实例化一个数据集
dataloader = DataLoader(datafile, batch_size=batch_size, shuffle=True, num_workers=workers) # 用PyTorch的DataLoader类封装,实现数据集顺序打乱,多线程读取,一次取多个数据等效果
print('Dataset loaded! length of train set is {0}'.format(len(datafile)))
model = VGG16() # 实例化一个网络
model = model.cuda() # 网络送入GPU,即采用GPU计算,如果没有GPU加速,可以去掉".cuda()"
model.train() # 网络设定为训练模式,有两种模式可选,.train()和.eval(),训练模式和评估模式,区别就是训练模式采用了dropout策略,可以放置网络过拟合
optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 实例化一个优化器,即调整网络参数,优化方式为adam方法
criterion = torch.nn.CrossEntropyLoss() # 定义loss计算方法,cross entropy,交叉熵,可以理解为两者数值越接近其值越小
cnt = 0 # 训练图片数量
# 读取数据集中数据进行训练,因为dataloader的batch_size设置为16,所以每次读取的数据量为16,即img包含了16个图像,label有16个
for img, label in dataloader: # 循环读取封装后的数据集,其实就是调用了数据集中的__getitem__()方法,只是返回数据格式进行了一次封装
img, label = Variable(img).cuda(), Variable(label).cuda() # 将数据放置在PyTorch的Variable节点中,并送入GPU中作为网络计算起点
out = model(img) # 计算网络输出值,就是输入网络一个图像数据,输出猫和狗的概率,调用了网络中的forward()方法
loss = criterion(out, label.squeeze()) # 计算损失,也就是网络输出值和实际label的差异,显然差异越小说明网络拟合效果越好,此处需要注意的是第二个参数,必须是一个1维Tensor
loss.backward() # 误差反向传播,采用求导的方式,计算网络中每个节点参数的梯度,显然梯度越大说明参数设置不合理,需要调整
optimizer.step() # 优化采用设定的优化方法对网络中的各个参数进行调整
optimizer.zero_grad() # 清除优化器中的梯度以便下一次计算,因为优化器默认会保留,不清除的话,每次计算梯度都回累加
cnt += 1
print('Frame {0}, train_loss {1}'.format(cnt*batch_size, loss/batch_size)) # 打印一个batch size的训练结果
torch.save(model.state_dict(), '{0}/model.pth'.format(model_cp)) # 训练所有数据后,保存网络的参数
if __name__ == '__main__':
train()
5测试
from getdata import DogsVSCatsDataset as DVCD
from network import Net
import torch
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import torch.nn.utils.prune as prune
dataset_dir = './' # 数据集路径
model_file = './model.pth' # 模型保存路径
def test():
model = Net() # 实例化一个网络
model.cuda() # 送入GPU,利用GPU计算
model.load_state_dict(torch.load(model_file)) # 加载训练好的模型参数
model.eval() # 设定为评估模式,即计算过程中不要dropout
datafile = DVCD('test', dataset_dir) # 实例化一个数据集
print('Dataset loaded! length of train set is {0}'.format(len(datafile)))
index = np.random.randint(0, datafile.data_size, 1)[0] # 获取一个随机数,即随机从数据集中获取一个测试图片
img = datafile.__getitem__(index) # 获取一个图像
img = img.unsqueeze(0) # 因为网络的输入是一个4维Tensor,3维数据,1维样本大小,所以直接获取的图像数据需要增加1个维度
img = Variable(img).cuda() # 将数据放置在PyTorch的Variable节点中,并送入GPU中作为网络计算起点
out = model(img) # 网路前向计算,输出图片属于猫或狗的概率,第一列维猫的概率,第二列为狗的概率
print(out) # 输出该图像属于猫或狗的概率
if out[0, 0] > out[0, 1]: # 猫的概率大于狗
print('the image is a cat')
else: # 猫的概率小于狗
print('the image is a dog')
img = Image.open(datafile.list_img[index]) # 打开测试的图片
plt.figure('image') # 利用matplotlib库显示图片
plt.imshow(img)
plt.show()
if __name__ == '__main__':
test()
总结
以上就是今天要讲的内容,本文仅仅简单介绍了pytorch的使用