研报复现系列(五)【光大证券】放量恰是入市时:成交量择时初探
前言
我们是国内普通高校的在校学生,同时也是量化投资的初学者。我们的学校不是清北复交,也没有金融工程实验室,同时地处三线小城,因此我们在校期间较难获得量化实习机会,但我们期待与业界进行沟通、交流。
蔡金航同学是我们其中的一员。其在寻找暑期量化实习时,收到了几家私募和券商金工组的笔试邀请,笔试内容皆为在给定时间内复现出一篇金工研报。蔡同学受到启发,发觉复现金工研报是我们学习量化策略、锻炼程序设计能力同时也是与业界交流的很好的途径。
在蔡同学的建议下,我们开启研报复现系列的创作,记录我们的学习过程,并将我们的创作内容分享出来,与读者们一起交流、学习、进步。
我们的水平有限,创作的内容难免会有错误或不严谨的内容,我们欢迎读者的批评指正。
如果您对我们的内容感兴趣,请联系我们:[email protected]
本系列会同步更新在微信公众号“HI投量化俱乐部”
本文作者:
蔡金航 哈尔滨工业大学威海校区 计算机科学与技术学院
舒意茗 哈尔滨工业大学威海校区 汽车工程学院
1.概述
本文是我们研报复现的第五篇,本文复现了【光大证券】的【放量恰是入市时:成交量择时初探】,这篇研报的主要思想是基于“价值量先行”的理论,在成交量放量的时刻入场。传统的描述成交量放量的思路是成交量连续若干天递增,但这种情况在市场上比较少见。该篇研报使用该日成交量与前N日成交量的相对排序位置,并将其映射到[-1,1]的区间,将该因子命名为成交量时序排名因子,使用该因子来量化成交量的放量程度。
基于成交量时序排名因子构建多种策略。
原始成交量时序排名策略为选取一个开平仓阈值,因子大于该阈值开仓,小于该阈值平仓。
后借助价格进行优化,通过价格涨幅把市场行情分为熊市、牛市和震荡市,不同的市场行情采用不同的开平仓阈值。该策略称为成交量时序排名行情分段策略。
最后将行情分段策略与RSRS策略结合,在不同的行情下对两个策略的信号做不同的处理。
本篇研报复现分享我们研究过程的部分源码。
2.研究环境
Python3
数据来源:优矿
回测区间:2005年3月到2021年5月
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import matplotlib as mpl
import datetime
import numpy as np
import statsmodels.api as sm
import math
import warnings
import seaborn as sns
sns.set()
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
数据获取函数,功能是获取数据,并更改字段名称。
def get_data(security,start_date,end_date):
df = DataAPI.MktIdxdGet(
ticker=security,
beginDate=start_date,
endDate=end_date,
field=["tradeDate","openIndex","closeIndex","highestIndex","lowestIndex","turnoverVol"],
pandas="1"
)
df = df.rename({
'tradeDate':'datetime',
'openIndex':'open',
'closeIndex':'close',
'highestIndex':'high',
'lowestIndex':'low',
'turnoverVol':'volume'
},axis=1)
df['ma20'] = pd.Series.rolling(df['close'],window = 20).mean()
return df
3.指标构建与分析
3.1成交量时序排名指标构建方法:
1.数据上除了当日的成交量以外,我们还需取前N个交易日的每日成
交量数据,共N+1个成交量的值。2.将该N+1个成交量数据按从小到大进行排序,计算当日成交量在这
N+1个数值中的排名n,最小即为1,最大即为N+1。
3.通过运算 (2* n-N-2 )/ N将当日成交量排名标准化为[-1, 1]内的数
值。
这里要注意,第三点的公式原研报给的是2 * (n-N-1) / N ,这是错误的,无法将排名标准化为[-1,1]
计算因子的函数如下:
def calc_rank_factor(df,N):
df = df.copy()
rank_list = [np.nan]*N
for i in range(N,df.shape[0]):
sorted_vol = list(df['volume'][i-N:i+1])
sorted_vol = sorted(sorted_vol)
rank_list.append(sorted_vol.index(df['volume'][i])+1)#得到排名
df['rank'] = rank_list
df['rank_factor'] = (2*df['rank'] - N -2)/N#标准化
return df
3.2 因子分析
以N=40为例,在沪深300上计算成交量时序排名因子,分析因子的特性。
3.2.1 时序排名出现频次
rank_factor_count = df['rank_factor'].value_counts()
rank_factor_count = dict(rank_factor_count)
plt.figure(figsize=(18,10))
plt.bar(rank_factor_count.keys(),rank_factor_count.values(), align='center',width=0.03)
plt.xticks(sorted(list(rank_factor_count.keys()))[::2],sorted(list(rank_factor_count.keys()))[::2])
fig_style(plt,title=f'沪深300时序排名出现频次')

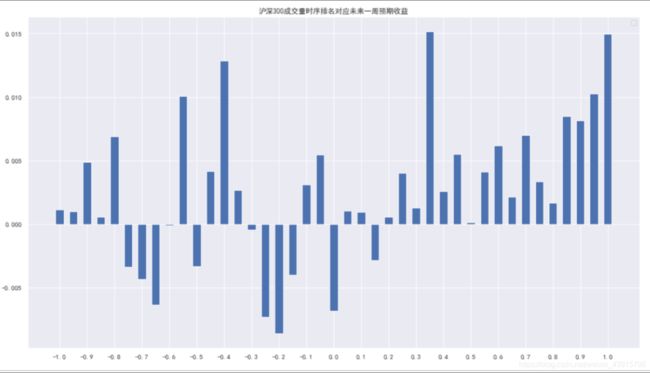
3.2.2 时序排名因子与未来一周预期收益率
df['week_ret'] = (df['close'].shift(-5) - df['close'])/df['close']
avg_week_ret_dic = {
}
week_ret_by_factor = df.groupby(by='rank_factor')
for factor,df1 in week_ret_by_factor:
avg_week_ret_dic
[factor] = df1['week_ret'].mean()
avg_week_ret = pd.DataFrame({
'rank_factor':list(avg_week_ret_dic.keys()),
'week_ret':list(avg_week_ret_dic.values())
}).sort_values(by='rank_factor').reset_index(drop=True)
plt.figure(figsize=(18,10))
plt.bar(avg_week_ret['rank_factor'],avg_week_ret['week_ret'], align='center',width=0.03)
plt.xticks(avg_week_ret['rank_factor'][::2],avg_week_ret['rank_factor'][::2])
fig_style(plt,title=f'沪深300成交量时序排名对应未来一周预期收益')
4策略构建
4.1 原始成交量时序排名策略
我们依据单日成交量时序排名来构造择时策略。具体的方式如下:
1.计算当日指数的成交量时序排名并标准化为[-1,1]值域内的指标值。
(涉及参数选择N,时序排名窗口长度)2.当成交量时序排名处于最大的一段范围内,或等价的,其标准化后
的值超过一定阈值S(例如时序排名位于最大的前四分之一,或等
价的,标准化后的值超过0.5),则开仓买入。(涉及参数选择S,
开仓阈值)3.当成交量时序排名离开高位,或等价的,其标准化后的值低于一定
阈值S,则平仓观望。
4.不进行看空与卖空交易。
策略代码如下:
def run_original_strategy(df,N,S):
df = df.copy()
df = df.copy()
df = calc_rank_factor(df,N)
df['flag'] = 0
df['position'] = 0
position = 0
df = df.dropna().reset_index(drop=True)
for i in range(df.shape[0]):
if df.loc[i,'rank_factor']>S and position == 0:
df.loc[i,'flag']=1
df.loc[i+1,'position'] = 1
position = 1
elif df.loc[i,'rank_factor']<S and position == 1:
df.loc[i,'flag']=-1
df.loc[i+1,'position'] = 0
position = 0
else:
df['position'][i+1] = df['position'][i]
return df.dropna()
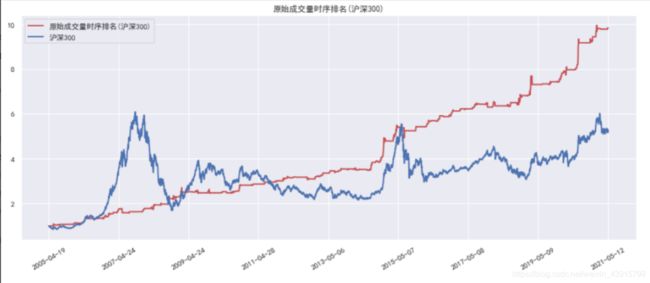
策略的净值走势如下图
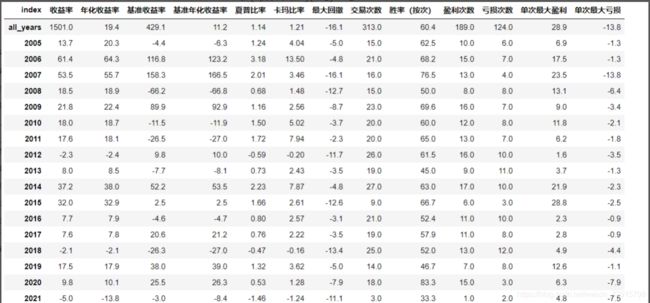
策略的统计指标如下图

4.2 成交量时序排名行情分段策略
在不同的市场环境下,成交量信息的解读方式也可能有所变化。从对未 来市场走势预测的角度来说,市场在牛市中时,可能成交量稍微放量甚至只要不缩量就预示后市大概率继续上涨;而在熊市中,可能只有在成交量大幅 放量时,后市才可能反弹。 我们通过前 10日指数的涨幅对市场行情进行分段,研究在不同市场行 情下成交量时序排名对未来指数走势的预示效果。如果指数前 10 日涨幅小于-5%,则认为目前处于熊市;如果指数前 10 日涨幅大于 5%,则认为目前 处于牛市;如果指数前 10 日涨幅处于-5%到5%之间,则认为目前是震荡市。
因此,构建成交量时序排名行情分段策略,构建方式如下:
- 按上一章节的定义计算当日标准化的成交量时序排名指标值。
- 根据前 10 日的指数涨幅决定当日处于哪种市场行情:牛市、熊市、 亦或震荡市。(涉及参数:用于行情划分的涨幅阈值 C,默认 5%)
- 根据当日所出市场行情,使用不同的交易阈值决定明日的持仓与否。 (涉及参数:三个不同行情下的交易阈值 Sf,、Sc、 Sr,分别对应 熊市、震荡市、牛市)
- 若时序排名指标值大于交易阈值,则持仓;反之,则空仓。
策略代码:
def divide_market(df,C):
df['10days_ret'] = df['close'].pct_change(10)
df['market'] = ''
df['market'].iloc[df[df['10days_ret']>C].index] = 'r'
df['market'].iloc[df[(df['10days_ret']<=C)&(df['10days_ret']>=-1*C)].index] = 'c'
df['market'].iloc[df[(df['10days_ret']<-1*C)].index] = 'f'
return df
def run_market_strategy(df,N,C,Sf,Sc,Sr):
df = df.copy()
df = calc_rank_factor(df,N)
df = divide_market(df,C)
S_dict = {
'f':Sf,'c':Sc,'r':Sr}
df['flag'] = 0
df['position'] = 0
position = 0
df = df.replace('',np.nan)
df = df.dropna().reset_index(drop=True)
for i in df.index:
if df['rank_factor'][i]>S_dict[df['market'][i]] and position == 0:
df['flag'][i]=1
df['position'][i+1] = 1
position = 1
elif df['rank_factor'][i]<S_dict[df['market'][i]] and position == 1:
df['flag'][i]=-1
df['position'][i+1] = 0
position = 0
else:
df['position'][i+1] = df['position'][i]
return df.dropna()
策略的表现如下图所示

4.3 成交量时序排名行情分段策略+RSRS
最后,我们进一步尝试将行情分段成交量时序排名指标与我们之前通过 最高价与最低价数据构造的 RSRS 择时信号相结合。我们这么做的原因与目的在于:通过信号结合,使得成交量时序排名择时在牛市持仓时间太少的缺陷能被 RSRS择时策略进一步弥补,同时尽可能地保留住其在震荡市与熊市中捕捉时长反弹上涨机会的能力。
结合方法如下:
1.获取当日的行情分段成交量时序排名策略与 RSRS 择时策略的信号。
2. 沿用上一小节的行情分段方式,确定当日所属市场行情:牛市、震 荡市、还是熊市。
3. 根据当日行情,决定择时信号:a) 如果行情为牛市,则完全依据 RSRS 信号作为择时信号。
b) 如果行情为震荡市,则有任何一个策略给出看多信号就持仓, 仅在所有信号都谨慎时,才空仓。(或关系)
c)如果行情为熊市,则必须所有信号看多时才持仓,否则空仓。 (与关系)
策略代码:
def calc_nbeta(df,n=18):
nbeta = []
r2 = []
trade_days = len(df.index)
for i in range(trade_days):
if i < (n-1):
#n-1为配合接下来用iloc索引
nbeta.append(np.nan)
r2.append(np.nan)
else:
try:
x = df['low'].iloc[i-n+1:i+1]
#iloc左闭右开
x = sm.add_constant(x)
y = df['high'].iloc[i-n+1:i+1]
regr = sm.OLS(y,x)
except:
print(x,y)
res = regr.fit()
beta = round(res.params[1],2)
nbeta.append(beta)
r2.append(res.rsquared)
df1 = df.copy()
df1 = df1.reset_index(drop=True)
df1['beta'] = nbeta
df1['r2'] = r2
return df1
def calc_stdbeta(df,n=18,m=650):
df1 = calc_nbeta(df,n)
df1['stdbeta'] = (df1['beta']-df1['beta'].rolling(window=m,min_periods=1).mean())/df1['beta'].rolling(window=m,min_periods=1).std()
return df1
def run_rsrs_strategy(df,N,C,Sf,Sc,Sr,S=0.7):
df = df.copy()
df = calc_stdbeta(df)
df = calc_rank_factor(df,N)
df = divide_market(df,C)
S_dict = {
'f':Sf,'c':Sc,'r':Sr}
df['flag'] = 0
df['position'] = 0
position = 0
df = df.replace('',np.nan)
df = df.dropna().reset_index(drop=True)
for i in df.index:
if df['market'][i] == 'r': #如果是牛市,完全按照RSRS择时
if df.loc[i,'stdbeta'] > S and position == 0:
df.loc[i,'flag'] = 1
df.loc[i+1,'position'] =1
position = 1
elif df.loc[i,'stdbeta'] < -1*S and position == 1:
df.loc[i,'flag'] = -1
df.loc[i+1,'position'] = 0
position = 0
else:
df.loc[i+1,'position'] = df.loc[i,'position']
elif df['market'][i] == 'c':
if (df.loc[i,'stdbeta'] > S or df['rank_factor'][i] > S) and position == 0:
df.loc[i,'flag'] = 1
df.loc[i+1,'position'] =1
position = 1
elif df.loc[i,'stdbeta'] < -1*S and df['rank_factor'][i] < -1*S and position == 1:
df.loc[i,'flag'] = -1
df.loc[i+1,'position'] = 0
position = 0
else:
df.loc[i+1,'position'] = df.loc[i,'position']
elif df['market'][i] == 'f':
if (df.loc[i,'stdbeta'] > S and df['rank_factor'][i] >S) and position == 0:
df.loc[i,'flag'] = 1
df.loc[i+1,'position'] =1
position = 1
elif (df.loc[i,'stdbeta'] < -1*S or df['rank_factor'][i]<-1*S) and position == 1:
df.loc[i,'flag'] = -1
df.loc[i+1,'position'] = 0
position = 0
else:
df.loc[i+1,'position'] = df.loc[i,'position']
else:
df['position'][i+1] = df['position'][i]
return df.dropna()
策略表现:


5 总结与补充
除了上述的内容。我们还对这篇研报做了其他的深入的研究。
5.1 策略总结
主要研究内容包括
1. 原始成交量时序排名策略的参数优化及表现
2. 行情分段成交量时序排名原始策略的参数优化及表现
3. 行情分段成交量时序排名原始+标准分RSRS策略的参数优化及表现
4. 行情分段成交量时序排名原始+均值标准分RSRS策略的参数优化及表现
5. 原始成交量时序排名策略在开平仓取不同阈值时的表现
完成以上的研究之后,得到了以下结论:
1. 原始成交量时序排名策略表现稳健。原始成交量时序排名策略在所有指数上的分年回测结果中,除了2021年其他所有年份的年化收益都为正。
2. 行情分段策略可以使得年化收益和最大回撤都小幅上升,卡玛比率小幅下降。
3. 行情分段+RSRS或者行情分段+均值RSRS策略的表现不佳,对策略年化收益的贡献有限,却使得最大回撤大幅上升。但本人认为这是熊市、牛市、震荡市的划分太过粗糙,按照不同行情使用不同策略的思想是正确的,后期可以结合其他因子划分行情,再进行测试。
4. 每一笔交易的年化收益分布极度不均,部分交易年化收益率达到了10000%以上。其原因是大部分交易的持仓时间很短,一半交易的持仓天数只有1天,使用复利的方式计算年化收益时,250次幂将较少的差距放得很大。后直接统计每笔交易的盈利率,大体呈正态分布,且各指数的分布相近。
5. 测试了原始策略开平仓取不同阈值时策略的表现,但对策略的优化有限。沪深300的全回测区间上,该策略对原始策略有较好的改善,但17年之后仍旧是原始成交量策略表现最优。中证500和上证50上,该策略表现与原始策略相似。
6. 综合各指数,原始成交量时序排名策略表现最稳定。同时,各策略在中证500上的表现最优。
5.2各策略在各指数上的最优参数为:
原始成交量时序排名:
沪深300:N=35,S=0.8
中证500:N=30,S=0.75
上证50:N=27,S=0.8
开平仓不同阈值的原始策略:
沪深300:N=35,S=0.8,S1=0.35
中证500:N=30,S=0.8,S1=0.55
上证50: N=27,S=0.85,S1=0.75
行情分段策略:
沪深300:N=35,C=0.07,Sf=0.8,Sc=0.6,Sr=0.2
中证500:N=30,C=0.05,Sf=0.8,Sc=0.6,Sr=0.4
上证50:C=0.05,Sf=1.0,Sc=0.6,Sr=0.1