独立成分分析(Independent Component Analysis,ICA)原理及代码实现
过程监控中会用到很多中方法,如主成分分析(PCA)、慢特征分析(SFA)、概率MVA方法或独立成分分析(ICA)等为主流算法。
其中PCA主要多用于降维及特征提取,且只对正太分布(高斯分布)数据样本有效;SFA被用来学习过程监控的时间相关表示,SFA不仅可以通过监测稳态分布来检测与运行条件的偏差,还可以根据时间分布来识别过程的动态异常,多用于分类分析;概率MVA方法,多以解决动力学、时变、非线性等问题。
今天要介绍的是独立成分分析(ICA),由浅入深,细细道来。
此外文末还附有ICA可实现的代码哟~不要错过
独立成分分析(Independent Component Analysis,ICA)
基本原理
在信号处理中,独立成分分析(ICA)是一种用于将多元信号分离为加性子分量的计算方法。这是通过假设子分量是非高斯信号,并且在统计上彼此独立来完成的。ICA是盲源分离的特例。一个常见的示例应用程序是在嘈杂的房间中聆听一个人的语音的“ 鸡尾酒会问题 ”。
首先,引入一下经典的鸡尾酒宴会问题(Cocktail Party Problem)。
如下图所示,假如在我们的Party中有 n n n个人,他(她)们可以同时且互相说话,我们也在房间中一些角落里共放置了n个声音接收器(Microphone)用来记录声音。宴会过后,我们从n个麦克风中得到了一组数据 X ( i ) = ( x 1 ( i ) , x 2 ( i ) , … , x n ( i ) ) ; ( i = 1 , … , m ) \mathrm{X}^{(i)}=\left(x_{1}^{(i)}, x_{2}^{(i)}, \ldots, x_{n}^{(i)}\right) ;( i=1, \ldots, m) X(i)=(x1(i),x2(i),…,xn(i));(i=1,…,m),其中 i i i表示采样的时间顺序,也就是说共得到了 m m m组采样,每一组采样都是 n n n维的,得到的是一个 n ∗ m n*m n∗m 的数据矩阵。
我们的目标是:单独从这 m m m组采样数据中分辨出每个人说话的信号。
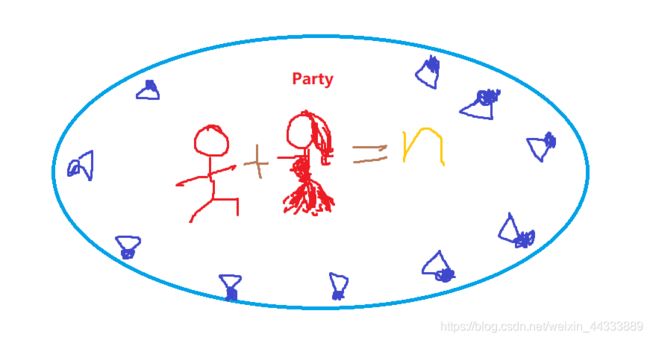
这里我们还需要另一组信息,那就是声音信号。我们把每个人的声音信号,那么也就是有 n n n个信号源 S = ( s 1 , s 2 , . . . , s n ) T , s ∈ R n S=(s_1,s_2,...,s_n)^T,s\in \mathfrak{R}^n S=(s1,s2,...,sn)T,s∈Rn,且每个人发出的声音都是相互独立的。同样我们做了 m m m组采样。
假设我们令一个未知的混合系数矩阵(mixing coefficient matrix)为 A A A,用来组合叠加信号 S S S,
X = A S X=AS X=AS
这里的 X X X不是一个向量,是一个矩阵。其中的列向量是 x ( i ) = A s ( i ) x^{(i)}=As^{(i)} x(i)=As(i)。
由此我们可知每一个 x ( i ) x^{(i)} x(i)都是由 s ( i ) s^{(i)} s(i)的分量线性表示的。
目前我们需要明确一点,只有 X X X是已知的可测量的(由麦克风得到),其中 A 、 S A、S A、S均为未知条件,我们要想办法根据 X X X来推出 S S S值。这个过程也称作为盲信号分离。
由于求矩阵的逆在实际运算中会出现一些问题,那么我们令 H = A − 1 H=A^{-1} H=A−1,则 s ( i ) = A − 1 x ( i ) = H x ( i ) s^{(i)}=A^{-1}x^{(i)}=Hx^{(i)} s(i)=A−1x(i)=Hx(i)。
其中我们 H H H可表示为,
[ h 1 T . . . h n T ] \begin{bmatrix} & h_{1}^{T} & \\ & ...&\\ & h_{n}^{T} & \end{bmatrix} ⎣⎡h1T...hnT⎦⎤
h i ∈ R n h_i\in \mathfrak{R}^n hi∈Rn,将 H H H 写成向量的形式。由此可得,
s j ( i ) = h j T x ( i ) s_{j}^{(i)}=h_{j}^{T}x^{(i)} sj(i)=hjTx(i)
ICA的不确定性(ICA ambiguities)
由于 h h h和 s s s都不确定,那么在没有先验知识的情况下,无法同时确定这两个相关参数。
比如上面的公式 s = h x s=hx s=hx。当 h h h 扩大两倍时, s s s 只需要同时扩大两倍即可,等式仍然满足,因此无法得到唯一的 s s s。同时如果将人的编号打乱,变成另外一个顺序,那么只需要调换A的列向量顺序即可,因此也无法单独确定 s s s。这两种情况称为原信号不确定。
还有一种ICA不适用的情况,那就是信号不能是高斯分布的。假设只有两个人发出的声音信号符合多值正态分布, s ∼ N ( 0 , 1 ) s \sim N(0,1) s∼N(0,1)。
简而言之,不合适,不适用于没先验知识的情况。
ICA 算法
下面直接上ICA算法。
独立成分分析 ICA(Independent Component Correlation Algorithm)是一种函数,X为n维观测信号矢量,S为独立的m(m<=n)维未知源信号矢量,矩阵A被称为混合矩阵。ICA的目的就是寻找解混矩阵W(A的逆矩阵),然后对X进行线性变换,得到输出向量U。
这里使用最大似然估计来解释算法,我们假定每个 s i s_i si有概率密度 p s p_s ps,那么给定时刻原信号的联合分布就是
p ( s ) = ∏ i = 1 n p s ( s i ) \mathrm{p}(\mathrm{s})=\prod_{i=1}^{n} p_{s}\left(s_{i}\right) p(s)=i=1∏nps(si)
此公式代表一个假设前提:每个人发出的声音信号各自独立。
有了 p ( s ) p(s) p(s),我们可以求得 p ( x ) p(x) p(x)
p ( x ) = p s ( H x ) ∣ H ∣ = ∣ H ∣ ∏ i = 1 n p s ( h i T x ) \mathrm{p}(\mathrm{x})=\mathrm{p}_{s}(H x)|\mathrm{H}|=|\mathrm{H}| \prod_{i=1}^{n} p_{s}\left(h_{i}{ }^{T} x\right) p(x)=ps(Hx)∣H∣=∣H∣i=1∏nps(hiTx)
左边是每个采样信号 x x x的概率,右边是每个原信号概率的乘积的 ∣ H ∣ |H| ∣H∣倍。
若没有先验知识,我们无法求得 H H H和 s s s。
因此我们需要知道 p s ( s i ) p_s(s_i) ps(si),我们打算选取一个概率密度函数赋给 s s s,但是我们不能选取高斯分布的密度函数。在概率论里我们知道密度函数p(x)由累计分布函数(cdf)F(x)求导得到。F(x)要满足两个性质是:单调递增和在[0,1]。我们发现sigmoid函数很适合,定义域负无穷到正无穷,值域0到1,缓慢递增。我们假定 s s s的累积分布函数符合sigmoid函数
g ( s ) = 1 1 + e − s g(s)=\frac{1}{1+e^{-s}} g(s)=1+e−s1
求导可得,
p s ( s ) = g ′ ( s ) = e s ( 1 + e s ) 2 p_{s}(s)=g^{\prime}(s)=\frac{e^{s}}{\left(1+e^{s}\right)^{2}} ps(s)=g′(s)=(1+es)2es
这就是 s s s的密度函数。此时的 s s s是实数。
要是我们预先知道 s s s的分布函数,那就不用假设了,但在未知的情况下,sigmoid函数能够在大多数问题上取得不错的效果。
由于上式中 p s ( s ) p_s(s) ps(s)是个对称函数,因此E[s]=0(s的均值为0),那么E[x]=E[As]=0,x的均值也是0。
现在我们知道了 p s ( s ) p_s(s) ps(s),下面开始求 H H H。
采样后的训练样本为 X ( i ) = ( x 1 ( i ) , x 2 ( i ) , … , x n ( i ) ) ; ( i = 1 , … , m ) \mathrm{X}^{(i)}=\left(x_{1}^{(i)}, x_{2}^{(i)}, \ldots, x_{n}^{(i)}\right) ;( i=1, \ldots, m) X(i)=(x1(i),x2(i),…,xn(i));(i=1,…,m),使用前面得到的 x x x的概率密度函数,得其样本对数似然估计:
ℓ ( H ) = ∑ i = 1 m ( ∑ j = 1 n log g ′ ( h j T x ( i ) ) + log ∣ H ∣ ) \ell(H)=\sum_{i=1}^{m}\left(\sum_{j=1}^{n} \log g^{\prime}\left(h_{j}^{T} x^{(i)}\right)+\log |H|\right) ℓ(H)=i=1∑m(j=1∑nlogg′(hjTx(i))+log∣H∣)
其中,括号里的一大堆为 p ( x ( i ) ) p(x^{(i)}) p(x(i)),然后再对 H H H进行求导操作。在上式中包含有行列式,对行列式|W|进行求导的方法可参考这里。
最终得到的求导结果公式(很复杂很繁琐–心情):
H : = H + α ( [ 1 − 2 g ( h 1 T x ( i ) ) 1 − 2 g ( h 2 T x ( i ) ) ⋮ 1 − 2 g ( h n T x ( i ) ) ] x ( i ) T + ( H T ) − 1 ) H:=H+\alpha\left(\left[\begin{array}{c} 1-2 g\left(h_{1}^{T} x^{(i)}\right) \\ 1-2 g\left(h_{2}^{T} x^{(i)}\right) \\ \vdots \\ 1-2 g\left(h_{n}^{T} x^{(i)}\right) \end{array}\right] x^{(i)^{T}}+\left(H^{T}\right)^{-1}\right) H:=H+α⎝⎜⎜⎜⎛⎣⎢⎢⎢⎡1−2g(h1Tx(i))1−2g(h2Tx(i))⋮1−2g(hnTx(i))⎦⎥⎥⎥⎤x(i)T+(HT)−1⎠⎟⎟⎟⎞
其中 α \alpha α表示的是梯度上升速率,可自定义。
当通过多次迭代后,可求出 H H H,便可得到 s ( i ) = H x ( i ) s^{(i)}=Hx^{(i)} s(i)=Hx(i)来还原出原始信号。
举个Paper的栗子
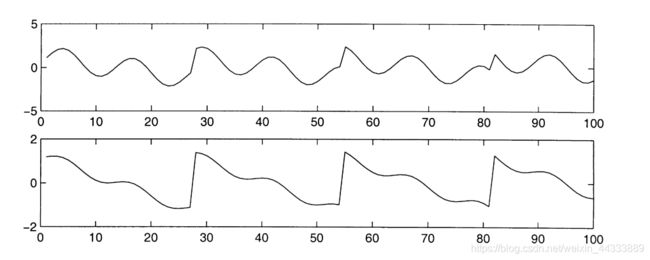
下面是 s = 2 s=2 s=2的原始信号:

下面为我们观测到的信号:
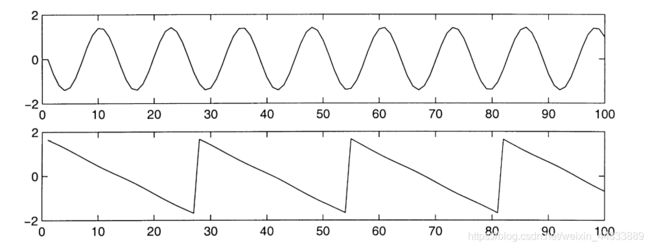
然后,再通过ICA还原后的信号为:
MATLAB代码实现
MATLAB代码:
Fast ICA
% Input:X 行变量维数,列采样个数;需要对原始矩阵转置
% Output:Sources重构的原信号, Q白化矩阵, P白化信号解混矩阵
function [Sources, Q, P] = FastICA(X, P)
% 白化处理
[dim, numSample] = size(X);
Xcov = cov(X');
[U, lambda] = eig(Xcov);
Q = lambda^(-1/2)*U';
Z = Q*X;
% FastICA
maxiteration = 10000; %最大迭代次数
error = 1e-5; % 收敛误差
% P = randn(dim,dim); % 随机初始化P,并按照列更新
for k = 1:dim
Pk = P(:,k);
Pk = Pk./norm(Pk); % 向量归一化
lastPk = zeros(dim,1); % 0不需要再归一化
count = 0;
while abs(Pk - lastPk)&abs(Pk + lastPk) > error
count = count + 1;
lastPk = Pk;
g = tanh(lastPk'*Z); % g(y)函数
dg = 1 - g.^2; % g(y)的一阶导函数
%-------------------------------核心公式------------------------------------
Pk = mean(Z.*repmat(g,dim,1), 2) - repmat(mean(dg),dim,1).*lastPk;
Pk = Pk - sum(repmat(Pk'*P(:,1:k-1),dim,1).*P(:,1:k-1),2);
Pk = Pk./norm(Pk);
%--------------------------------------------------------------------------
if count == maxiteration
fprintf('第%d个分量在%d次迭代内不收敛!\n',k,maxiteration);
break;
end
end
P(:,k) = Pk;
end
Sources = P'*Z;
% end
此外还有基于故障诊断的ICA算法代码实现->在这里
下面给出部分代码:
% 基于ICA的故障诊断
clear;clc;close all;
load('MPD2000.mat');
Xnormal = MPD0';
% 数据归一化
[dim, numSample] = size(Xnormal);
XnormalMean = mean(Xnormal, 2);
XnormalStd = std(Xnormal, 0, 2);
XnormalNorm = normalization(Xnormal, XnormalMean, XnormalStd);
% 正常数据计算 解混矩阵W
% P = rand(dim,dim)*100;
load('P.mat');
[S, Q, P] = FastICA(XnormalNorm, P);
W = P'*Q;
% ------------------------利用2范数大小对W的行重新排列---------------------
Wnorm = zeros(dim,1);
for k = 1:dim
Wnorm(k) = norm(W(k,:));
end
[Wnorm, indices] = sort(Wnorm, 'descend');
% -------------------------确定主导成分Sd与参与成分Se----------------------
threshold = 0.80;
percentage = cumsum(Wnorm)./sum(Wnorm);
for k = 1:dim
if percentage(k) > threshold
break;
end
end
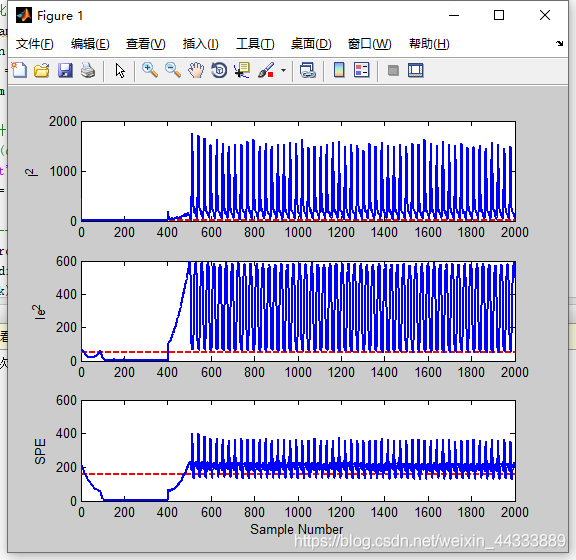
效果如下:
References
- https://www.cnblogs.com/jerrylead/archive/2011/04/19/2021071.html
- https://baike.baidu.com/item/ICA/4972405?fr=aladdin
- https://spaces.ac.cn/archives/2383
- A. Hyva¨rinen, E. Oja*. Independent component analysis: algorithms and applications.
❤坚持读Paper,坚持做笔记,坚持学习❤!!!
⚡To Be No.1⚡⚡哈哈哈哈
⚡创作不易⚡,过路能❤关注、收藏、点个赞❤三连就最好不过了
ღ( ´・ᴗ・` )
❤
『
Four short words sum up what has lifted most successful individuals above the crowd: a little bit more.
』