线性判别分析(LDA)与Fisher判别分析(FDA)降维原理
在故障诊断中,我们常常会面对大量的且维数很高的数组,通过我们需要先对数据集进行划分及预处理,而预处理阶段极为重要的一步就是对数据进行降维特征提取,通过某种数学变换将原始高维空间转变成一个低维的子空间。
然鹅,我们常用到的基本就只有两个,一个是主成分分析(PCA),另一个则是今天所要介绍的Fisher判别分析(Fisher Discriminant Analysis,FDA)。
- 主成分分析的基本思想:设法将原来众多具有一定相关性(比如P个指标,即主成分),重新组合成一组新的互相无关的综合指标来代替原来的指标。通过寻找在最小均方误差(Mean Square Error,MSE)下的最具代表性的投影向量,再用这些向量来表示数据。
- Fisher判别分析的基本思想:利用已知类别的样本建立判别模型,对未知类别的样本进行分类。在最小均方误差(也就是最小二乘法MSE)意义下,寻找最能分开各个类别的最佳方向。
最先的是提出的线性判别法(Linear Discriminant Analysis,LDA),这还是一种经典的线性学习方法。在降维方面LDA是最著名的监督学习降维方法。但是,在二分类问题上,因为最早是有(Fisher,1936)提出的,因此也被称为是“Fisher判别分析(Fisher Discriminant Analysis,FDA)”。
其实LDA和FDA两种判别分析方法,是略有不同的。其中LDA则假设了各类样本数据的协方差矩阵相同,且满秩。
线性判别分析(LDA)及Fisher判别分析(FDA)
LDA的思想:由所给定的数据集,设法将样例数据投影在一条直线上,使得同类数据的投影点尽可能的接近、而异类数据的投影点之间将可能间隔更远。在我们做新样本数据的分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别。如下图(源自周志华《机器学习》)所示:
这里的投影直线也用到了最小二乘的思想,所有数据样本垂直投影在直线上,只是我们的约束条件表为了不同数据样本之间的投影在直线上的距离度量。
我们需要寻找到在投影方向 w w w上,使得数据样本满足两个条件:1) 相同数据之间投影距离最小;2)不同数据之间投影点位置最大(可通过求其不同数据的投影中心点来判别)

图中,“+”和“-”代表的是两种不同的数据簇,而椭圆表示数据簇的外轮廓线,虚线表示其投影,红色实心圆●和红色实心三角形△分别代表的两类数据簇投影到 w w w方向上的中心点。
对于上面投影方向 y = w T x y=\mathbf{w^Tx} y=wTx,有博主认为描述的不够准确,书中并未提及关于 y y y的解释,但是对于 y y y其实是有所提及的。
但我认为,这里的 y y y,仅仅是为了体现投影的一个方向,将数据 x x x投影在方向为 w w w的直线上,而不是代表的这根投影直线为 y = w T x y=\mathbf{w^Tx} y=wTx,或许会被人误认为是投影后的值0。
—菜鸡理解(如有不对,请批评指正)
已知给定的数据集为
D = { ( x i , y i ) } i = 1 m , y i ∈ { 0 , 1 } D=\{(x_i,y_i)\}_{i=1}^{m},y_i\in \{0,1\} D={ (xi,yi)}i=1m,yi∈{ 0,1}
假设 X i 、 μ i 、 Σ i X_i、\mu_i、\Sigma_i Xi、μi、Σi分别表示第 i ∈ { 0 , 1 } i\in\{0,1\} i∈{ 0,1}类(注意:这里的 i i i 指代有多少个不同的类别数据集,图中只有两类,故为0和1)示例的集合、均值向量、协方差矩阵。
假如将所有的样本数据点都投影到直线 w w w上来,那么两类不同的样本数据的中心点在直线上的投影可表示为 w T μ 0 、 w T μ 1 w^{T}\mu_0、w^{T}\mu_1 wTμ0、wTμ1;同样,所有样本投影到直线上后,我们得到的两类样本的协方差分别为 w T Σ 0 w w^{T}\Sigma_0w wTΣ0w和 w T Σ 1 w w^{T}\Sigma_1w wTΣ1w.
由于我们只是在一维平面上的直线,故为一维空间,由此 w T μ 0 、 w T μ 1 、 w T Σ 0 w 、 w T Σ 1 w w^{T}\mu_0、w^{T}\mu_1、w^{T}\Sigma_0w、w^{T}\Sigma_1w wTμ0、wTμ1、wTΣ0w、wTΣ1w都是实数。
为什么说这里是一维空间呢?可以看上图,假设每个样本都是d维向量(上图为二维 x 1 、 x 2 x_1、x_2 x1、x2坐标系)。现在就简单一点,想用一条直线 w w w表示这些样本,称之为样本集合的一维表达。所以这里说的一维讲的是投影到一条直线上以后的数据,在直线上是属于一维空间表达的。
下面思考另一个问题,如何让同类的数据样本投影点尽可能的靠近,而使得不同样本投影点离得更远呢?
这里需要引入协方差的概念,小小复习一下协方差及样本方差的知识(因为本菜鸡数学基础差)
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
上面的 Σ 0 、 Σ 1 \Sigma_0、\Sigma_1 Σ0、Σ1因为是自协方差也就是代表方差(也即为样本方差)。方差:当数据分布比较分散(即数据在平均数附近波动较大)时,各个数据与平均数的差的平方和较大,方差就较大;当数据分布比较集中时,各个数据与平均数的差的平方和较小。
总的说来:方差越大,数据的波动越大;方差越小,数据的波动就越小。
协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
简而言之:两个变量之间差距越大,协方差就越小;相反,两个变量越相似变化趋势一致,则协方差越大。
复习完协方差、样本方差的知识后,解决上面的问题应该不难。
按照我们的需求,让同类的样本投影点尽可能的靠近,换句话说就是让同类样本投影的协方差尽可能的小(注意:这里由于是自协方差==样本方差,也就满足上面大字第一条),即 w T Σ 0 w + w T Σ 1 w w^{T}\Sigma_0 w+w^{T}\Sigma_1 w wTΣ0w+wTΣ1w尽可能的小,这样数据的波动就小,之间的距离就更小更靠近。
关于不同数据样本投影点之间的操作,使其更加的远离。我们可以通过不同数据集投影的中心点来判别,不同中心点之间的距离越大,那么表示他们之间离得更远,则 ∣ ∣ w T μ 0 + w T μ 1 ∣ ∣ 2 2 ||w^{T}\mu_0+w^{T}\mu_1||_2^2 ∣∣wTμ0+wTμ1∣∣22(欧式距离)更大。
好!现在我们同时考虑两者的情况,则可以使得得到最大化的目标,建立我们的模型:
J = ∥ w T μ 0 − w T μ 1 ∥ 2 2 w T Σ 0 w + w T Σ 1 w = w T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w w T ( Σ 0 + Σ 1 ) w \begin{aligned} J &=\frac{\left\|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\mu}_{0}-\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\mu}_{1}\right\|_{2}^{2}}{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\Sigma}_{0} \boldsymbol{w}+\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\Sigma}_{1} \boldsymbol{w}} \\ &=\frac{\boldsymbol{w}^{\mathrm{T}}\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}} \boldsymbol{w}}{\boldsymbol{w}^{\mathrm{T}}\left(\boldsymbol{\Sigma}_{0}+\boldsymbol{\Sigma}_{1}\right) \boldsymbol{w}} \end{aligned} J=wTΣ0w+wTΣ1w∥∥wTμ0−wTμ1∥∥22=wT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw
观察上式目标函数,当我们的 J → M a x J\rightarrow Max J→Max则是我们想要的结果。式子太复杂,那我们再优化一下吧。
引入一下类内和间散度矩阵的知识:
- 类间散度矩阵用于表示各样本点围绕均值的散布情况。
- 类内散度矩阵用于表示样本点围绕均值的散步情况,关于特征选择和提取的结果,类内散布矩阵的积越小越好。
具体可参考这里,还有这里。
首先,我们来定义“类内散度矩阵”(within-class scatter matrix)
S w = Σ 0 + Σ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T + ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T \begin{aligned} \mathbf{S}_{w} &=\boldsymbol{\Sigma}_{0}+\boldsymbol{\Sigma}_{1} \\ &=\sum_{\boldsymbol{x} \in X_{0}}\left(\boldsymbol{x}-\boldsymbol{\mu}_{0}\right)\left(\boldsymbol{x}-\boldsymbol{\mu}_{0}\right)^{\mathrm{T}}+\sum_{\boldsymbol{x} \in X_{1}}\left(\boldsymbol{x}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{x}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}} \end{aligned} Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T
“类间散度矩阵”(between-class scatter matrix):
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T \mathbf{S}_{b}=\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}} Sb=(μ0−μ1)(μ0−μ1)T
然后我们的 J J J可以表示为
J = w T S b w w T S w w J=\frac{\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{b} \boldsymbol{w}}{\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}} J=wTSwwwTSbw
这样看起来简单多了,这就是我们的LDA想要最大化的目标函数,比较专业的说法为, S b S_b Sb和 S w S_w Sw的“广义瑞利商”(generalizad Rayleigh quotient)。
关于“广义瑞利商”(generalizad Rayleigh quotient)的解释,可以参考这里和这里。
瑞利商经常出现在降维和聚类任务中,因为降维聚类任务往往能导出最大化最小化瑞利熵的式子,进而通过特征值分解的方式找到降维空间。
大体内容如下:
下面开始构建我们的函数及约束条件。

首先得确定我们的 w w w,由于 J J J的分母分子都是关于 w w w的二项式子,则与 w w w的长度无关,且只与方向有关。故我们令 w T S w w = 1 \boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}=1 wTSww=1,则:
min w − w T S b w s.t. w T S w w = 1 \begin{array}{ll} \min _{\boldsymbol{w}} & -\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{b} \boldsymbol{w} \\ \text { s.t. } & \boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}=1 \end{array} minw s.t. −wTSbwwTSww=1
由拉格朗日乘数法(具体可参考CCA中Lagrange的应用)可得,
S b w = λ S w w (*) \boldsymbol{S_bw=\lambda S_w w}\tag{*} Sbw=λSww(*)
其中, λ \lambda λ为拉格朗日乘子。
由上“类间散度矩阵”可知, S b w \boldsymbol{S_bw} Sbw为 μ 0 − μ 1 \mu_0-\mu_1 μ0−μ1的平方,故 S b w \boldsymbol{S_bw} Sbw的方向则恒为 μ 0 − μ 1 \mu_0-\mu_1 μ0−μ1,向量的方向可以确定了,我们再令
S b w = λ ( μ 0 − μ 1 ) \boldsymbol{S_bw=\lambda (\mu_0-\mu_1)} Sbw=λ(μ0−μ1)
向量方向确定, λ \lambda λ只是代表方向向量的长度,所以 S b w \boldsymbol{S_bw} Sbw可由上式表达。可能会有人疑惑了,这里的 λ \lambda λ和(*)式的 λ \lambda λ是一个 λ \lambda λ吗?
答案是肯定的。
将上式代入(*)式,可得关于 S w \boldsymbol{S_w} Sw的式子:
w = S w − 1 ( μ 0 − μ 1 ) \boldsymbol{w=S_w^{-1}(\mu_0-\mu_1)} w=Sw−1(μ0−μ1)
这里需要对 S w \boldsymbol{S_w} Sw求逆,考虑到数值解的稳定性,常规实践操作中,需要对 S w \boldsymbol{S_w} Sw进行奇异值分解(也就是我们在矩阵理论中学到的SVD方法),原理很简单,此处,即为 S w = U Σ V T \boldsymbol{S_w=U\Sigma V^{T}} Sw=UΣVT,其中 Σ \Sigma Σ是一个实对角矩阵,对角线上的元素也就是所谓的“迹”是 S w \boldsymbol{S_w} Sw的奇异值。我们需要求解的是 S w \boldsymbol{S_w} Sw的逆,故式子变为了这样,
S w − 1 = V Σ − 1 U T \boldsymbol{S_w^{-1}=V\Sigma^{-1} U^{T}} Sw−1=VΣ−1UT
至此,我们得到了 S w − 1 \boldsymbol{S_w^{-1}} Sw−1,从而可求得直线向量 w w w,找到使得 J J J 最大的 w w w.
LDA还可从贝叶斯决策理论的角度来描述(关于贝叶斯可参考这里),可证明,当两类数据同先验、满足高斯分布(正态分布)且协方差相等时,LDA可以达到最优的分类效果。
上述讲了这么多都是二分类问题,那么关于多分类任务。
LDA推广(多分类任务)
将LDA推广到多维多分类任务,起初我们只有两类,现在我们假设有 N N N类,其中第 i i i类则表示为 m i , i ∈ ( 1 , N ) m_i,i\in(1,N) mi,i∈(1,N)。
我们定义“全局散度矩阵”:
S t = S b + S w = ∑ i = 1 m ( x i − μ ) ( x i − μ ) T \begin{aligned} \mathbf{S}_{t} &=\mathbf{S}_{b}+\mathbf{S}_{w} \\ &=\sum_{i=1}^{m}\left(\boldsymbol{x}_{i}-\boldsymbol{\mu}\right)\left(\boldsymbol{x}_{i}-\boldsymbol{\mu}\right)^{\mathrm{T}} \end{aligned} St=Sb+Sw=i=1∑m(xi−μ)(xi−μ)T
其中, μ \mu μ代表所有示例的均值向量。
将二分类的类内散度矩阵 S w \boldsymbol{S_w} Sw重新定义为每个类别的散度矩阵之和,因为现在是对多分类任务操作,也就是将每一类的 S w i \boldsymbol{S_{wi}} Swi加起来变为一个 S w \boldsymbol{S_w} Sw,
S w = ∑ i = 1 N S w i \mathbf{S}_{w}=\sum_{i=1}^{N} \mathbf{S}_{w_{i}} Sw=i=1∑NSwi
其中,
S w i = ∑ x ∈ X i ( x − μ i ) ( x − μ i ) T \mathbf{S}_{w_{i}}=\sum_{\boldsymbol{x} \in X_{i}}\left(\boldsymbol{x}-\boldsymbol{\mu}_{i}\right)\left(\boldsymbol{x}-\boldsymbol{\mu}_{i}\right)^{\mathrm{T}} Swi=x∈Xi∑(x−μi)(x−μi)T
同理,这里的 μ i \mu _i μi也代表每一类的均值向量。
由上式可得到,
S b = S t − S w = ∑ i = 1 N m i ( μ i − μ ) ( μ i − μ ) T \begin{aligned} \mathbf{S}_{b} &=\mathbf{S}_{t}-\mathbf{S}_{w} \\ &=\sum_{i=1}^{N} m_{i}\left(\boldsymbol{\mu}_{i}-\boldsymbol{\mu}\right)\left(\boldsymbol{\mu}_{i}-\boldsymbol{\mu}\right)^{\mathrm{T}} \end{aligned} Sb=St−Sw=i=1∑Nmi(μi−μ)(μi−μ)T
由此,多分类LDA可有多种实现方法,使用 S b 、 S t 、 S w \boldsymbol{S_b、S_t、S_w} Sb、St、Sw其中的任意两个即可实现目标优化。
常规采用 S b 、 S w \boldsymbol{S_b、S_w} Sb、Sw来实现,将我们的目标进行优化,
max W tr ( W T S b W ) tr ( W T S w W ) \max _{\mathbf{W}} \frac{\operatorname{tr}\left(\mathbf{W}^{\mathrm{T}} \mathbf{S}_{b} \mathbf{W}\right)}{\operatorname{tr}\left(\mathbf{W}^{\mathrm{T}} \mathbf{S}_{w} \mathbf{W}\right)} Wmaxtr(WTSwW)tr(WTSbW)
其中, W ∈ R d × ( N − 1 ) \mathbf{W} \in \mathbb{R}^{d \times(N-1)} W∈Rd×(N−1),tr(·)则表示的是矩阵的“迹”。
上式可由如下的广义特征值问题求解:
S b W = λ S w W \boldsymbol{S_bW=\lambda S_w W} SbW=λSwW
注意:这里的 W W W和上面二分类问题时的 w w w相同, W W W则是多类问题下的投影直线。故我们需要找到这样在多个类下使得满足第一部分的约束条件的直线 W W W。
和二分类一样通过奇异值分解来需求解 S b w \boldsymbol{S_bw} Sbw的值,从而得到使得优化的目标函数实现最大的 W W W,在多维中,我们可将 W W W视为一个投影矩阵。
W W W的闭式解为 S w − 1 S b S_w^{-1}S_b Sw−1Sb的 d ′ d' d′个最大非零广义特征值所对应的特征向量组成的矩阵, d ′ ≤ N − 1 d' \le N-1 d′≤N−1.
在故障诊断中LDA也多用于对原始数据进行预处理----降维,多分类LDA将数据样本投影到 d ′ d' d′维空间中,而 d ′ d' d′往往远小于 d d d维。
故可通过LDA的投影方式来降低数据的维度达到降维效果。
有一个LDA和PCA很好区分的图,附上一下:
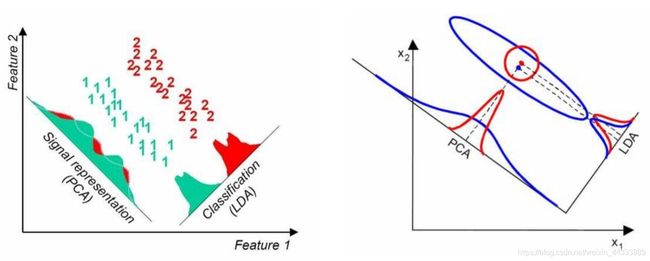
从上图中可容易理解PCA和LDA。可看出PCA多满足高斯分布,投影了最具代表性的主成分分量;而LDA如上所述,投影下来使其更容易区分出各类别之间的最佳方向。
References
- 《机器学习》-周志华著
- https://hyper.ai/wiki/3654
- https://hyper.ai/wiki/9942
- https://baike.baidu.com/item/%E6%96%B9%E5%B7%AE/3108412
- https://baike.baidu.com/item/%E5%8D%8F%E6%96%B9%E5%B7%AE
- https://zhuanlan.zhihu.com/p/78077834
- https://zhuanlan.zhihu.com/p/301277905
- https://www.zhihu.com/topic/20687704/hot
- https://www.zhihu.com/question/27670909
❤坚持读Paper,坚持做笔记,坚持学习❤!!!
⚡To Be No.1⚡⚡哈哈哈哈
⚡创作不易⚡,过路能❤关注、收藏、点个赞❤三连就最好不过了
ღ( ´・ᴗ・` )
❤
『
To the time to life, rather than to life in time to the time to life, rather than to life in time.
』