【机器学习】贝叶斯网络实现一个简单的拼写检查
如果需要完整代码可以关注下方公众号,后台回复“代码”即可获取,阿光期待着您的光临~
文章目录
- 代码实践
2021人工智能领域新星创作者,带你从入门到精通,该博客每天更新,逐渐完善各个知识体系的文章,帮助大家更高效学习。
请用贝叶斯网络实现一个简单的拼写检查
算法步骤:
1)建立一个足够大的文本库
2)对文本库的每一个单词统计其出现频率
3)根据用户输入的单词,得到其所有可能的拼写相近的形式
4)比较所有拼写相近的词在文本库的出现频率。频率最高的那个词,就是正确的拼法
- 首先自己建立文本库(外文文献)
- 计算先验概率
- 计算似然
- 返回最大条件概率的单词
为了简单没有考虑不同特征之间的联合概率,如果是联合概率需要使用图计算,基于概率图(贝叶斯网络),这里仅仅考虑各特征之间独立分布。


代码实践
"""
* Created with PyCharm
* 作者: Laura
* 日期: 2021/11/6
* 时间: 18:30
* 描述: 贝叶斯网络实现一个简单的拼写检查
"""
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import pandas as pd
import jieba
import re
import collections
class Bayes():
def __init__(self,):
self.dic={
}
def cut_word(self):
string=''
with open('text', 'r', encoding='utf-8') as file:
for line in file.readlines():
string+=line
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"')
string = re.sub(pattern, '', string)
seg_list_exact = jieba.cut(string, cut_all = False)
object_list = []
remove_words = [u',',u'.',u"'",u' ',u'!',u'It',u'The',u'like',u'//',u'So',u'is',u'are',u'it',u'/'
,u'a',u'b',u'c',u'd',u'e',u'f',u'g',u'h',u'i',u'j',u'k',u'l',u'm',u'n',u'o',u'p',u'q',u'r',u's',u't',u'u',u'v',u'w',u'x',u'y',u'z'
,u'A',u'B',u'C',u'D',u'E',u'F',u'G',u'H',u'I',u'J',u'K',u'L',u'M',u'N',u'O',u'P',u'Q',u'R',u'S',u'T',u'U',u'V',u'W',u'X',u'Y',u'Z'
,u'0',u'1',u'2',u'3',u'4',u'5',u'6',u'7',u'8',u'9',u'10']
for word in seg_list_exact:
if word not in remove_words:
object_list.append(word)
words=[]
for word in object_list:
words.append(word)
word_counts = collections.Counter(object_list)
word_counts_top10 = word_counts.most_common(100)
dic=dict()
for val in word_counts_top10:
dic[val[0]]=val[1]
self.dic=dic
def calculate_frequency(self):
frequency_ = 0.
for value in self.dic.values():
frequency_ += value
self.dic = dict(map(lambda x:[x, [self.dic[x] / frequency_]],self.dic))
def calculate_p_r_c(self,word):
for key in self.dic.keys():
count=0.
len_word=len(word)
len_key=len(key)
for num in range(min(len_word,len_key)):
if key[num]==word[num]:
count+=1
self.dic[key].append(count)
def run(self,word):
self.cut_word()
self.calculate_frequency()
self.calculate_p_r_c(word)
print(sorted(dict(map(lambda x:[x, self.dic[x][0]*self.dic[x][1]],self.dic)).items(), key=lambda item:item[1],reverse=True)[0][0])
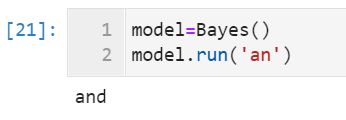
model=Bayes()
model.run('appl')