k8s系列-白话Kubernetes架构
前言
随着kubernetes的生态不断完善,它的入门门槛也越来越低。越来越多的企业也开始进行容器化改造。作为容器化改造的主力,如果只是凭借已有的开源工具对其搭建部署使用,那是远远不够的。毕竟是应用于生产的架构,如果连运维人员自己都无法把控,那谁来为线上系统的稳定负责呢。所以,学习k8s不仅仅要知道怎么用好,还要懂得其运行原理,架构。出现问题时能够及时溯源,解决问题。
今天就跟大家分享一下我对k8s架构的理解,欢迎大家拍砖。
架构
kubernetes是用于容器集群管理的平台。既然是管理集群,那么就存在管理端与被管理端,在k8s体系架构中,我们称管理端为管理节点,整个集群由一个master负责管理和控制集群节点。被管理端称为计算节点。架构图如下(借用网上的图):
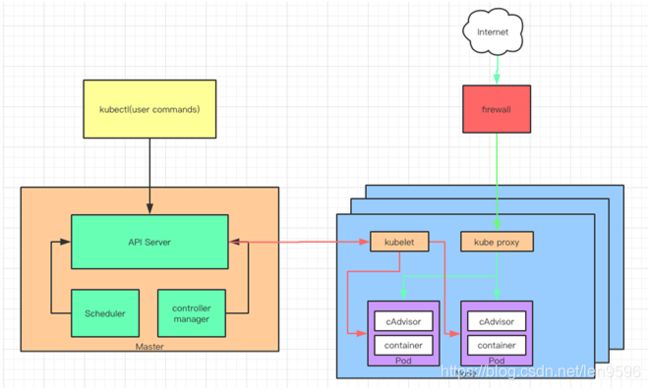
如图所示,我们通常通过kubectl对 k8s 进行操作,它通过apiserver去调用各个进程完成对Node的部署和控制。
简易流程说明
1、kubectl通过Apiserver 创建pod
2、Scheduler将调度的Pod绑定到Node,并将绑定信息写入etcd
3、Controller manager包含了8个Controller,分别对应副本,节点,资源,命名空间等。
4、Schduler调度到node 的pod由kubelet负责维护,kubelet进程也会在APIServer上注册Node信息,定期向Master汇报Node信息,并通过cAdvisor监控容器和节点资源。
API架构
APIServer的架构从上到下分为四层:
- API层:主要以REST方式提供各种api接口,针对k8s资源对象的CRUD和watch等主要API,还有健康检查,UI,日志,性能指标等运维监控相关的API。
- 访问控制层:负责身份鉴权,核准用户对资源的访问权限,设置访问逻辑(Admission Control)
- 注册表层:选择要访问的资源对象。PS:k8s把所有资源对象保存在注册表中
- etcd数据库:保存创建副本的信息,用来持久化k8s资源对象的Key-Value数据库

简易说明
1、kubectl用create命令建立pod时,是通过APIServer中的API层调用对应的RESTAPI方法
2、进入权限控制层,通过Authentication获取调用者身份,Authorization获取权限信息
3、Registry层从CoreRegistry资源中取出1个Pod作为要创建的k8s资源对象,然后将Node,pod和container信息保存到etcd中去。
…
一个完整的流程还需要有scheduler和controller manager接入,这个后续再做说明
…
k8s 接口监听机制
从上面知道,所有的部署信息都会写到etcd中保存。实际上etcd在存储部署信息的时候会发送create时间给APIServer,而APIServer会通过监听etcd发过来的事件。其他组件也会监听APIServer发过来的事件。
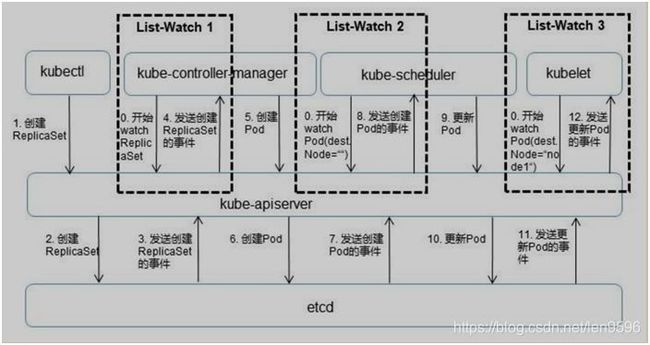
简易说明
这里一共三个List-Watch:kube-controller-manager,kube-scheduler,kubelet。当进程启动就会监听APIServer发出来的事件。
1、kubectl通过命令行,在APIServer上建立一个Pod副本,这个部署请求被记录到etcd中存储起来。当etcd接受创建pod信息以后,会发送一个Create事件给APIServer。
2、controller manager一直在监听APIServer中的事件,此时APIServer接受到create事件,又发送给controller manager。它接到Create事件以后,调用其中的Replication Controller来保证Node上面需要创建的副本数量。
3、在Controller Manager创建Pod副本以后,APIServer会在etcd中记录这个Pod的详细信息。同样的etcd会将创建Pod信息事件发送给APIServer。
4、由scheduler在监听APIServer,接收创建Pod事件,根据调度算法为其安排Node。
5、Node上的kubelet服务进程接管后继工作,负责Pod生命周期中的"下半生"。同样将Pod信息更新到etcd中,保存起来。etcd将更新成功的事发送到APIServer。
6、在Node上的kubelet通过List-Watch的方式监听APIServer发送的Pod更新的事件。并执行。
组件
Master
Apiserver
apiserver的核心功能是对核心对象的增删改查操作,同时也是集群内模块之间数据交换的枢纽。它包含了常用的API,访问(权限)控制,注册,信息存储(etcd)等功能。
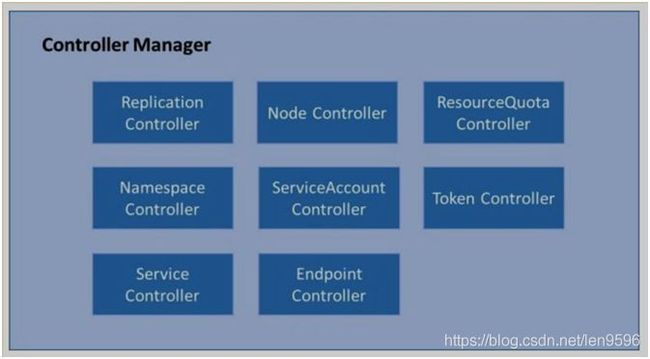
Controler-manager
Controller Manager 是 Kubernetes 资源的管理者,是运维自动化的核心。它分为 8 个 Controller,上面我们介绍了 Replication Controller,这里我们把其他几个都列出来,就不展开描述了。
Scheduler-manager
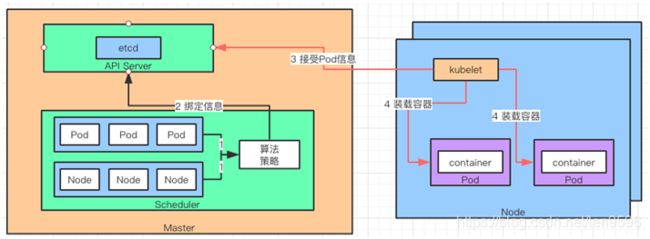
Scheduler 的作用是,将待调度的 Pod 按照算法和策略绑定到 Node 上,同时将信息保存在 etcd 中。如果把 Scheduler 比作调度室,那么这三件事就是它需要关注的,待调度的 Pod、可用的 Node,调度算法和策略。
简单地说,就是通过调度算法/策略把 Pod 放到合适的 Node 中去。此时 Node 上的 kubelet 通过 APIServer 监听到 Scheduler 产生的 Pod 绑定事件,然后通过 Pod 的描述装载镜像文件,并且启动容器。
也就是说 Scheduler 负责思考,Pod 放在哪个 Node,然后将决策告诉 kubelet,kubelet 完成 Pod 在 Node 的加载工作。
说白了,Scheduler 是 boss,kubelet 是干活的工人,他们都通过 APIServer 进行信息交换。
Node
kubelet
kubelet有几种方式获取自身Node上所需要运行的Pod清单。但本文只讨论通过API Server监听etcd目录,同步Pod列表的方式。
kubelet通过API Server Client使用WatchAndList的方式监听etcd中/registry/nodes/${当前节点名称}和/registry/pods的目录,将获取的信息同步到本地缓存中。
kubelet监听etcd,执行对Pod的操作,对容器的操作则是通过Docker Client执行。
kubelet创建和修改Pod流程
1、为该Pod创建一个数据目录。
2、从API Server读取该Pod清单。
3、为该Pod挂载外部卷(External Volume)
4、下载Pod用到的Secret。
5、检查运行的Pod,执行Pod中未完成的任务。
6、先创建一个Pause容器,该容器接管Pod的网络,再创建其他容器。
7、Pod中容器的处理流程:
1)比较容器hash值并做相应处理。
2)如果容器被终止了且没有指定重启策略,则不做任何处理。
3)调用Docker Client下载容器镜像,调用Docker Client运行容器。
kube-proxy
每台机器上都运行一个 kube-proxy 服务,它监听 API server 中 service 和 endpoint 的变化情况,并通过 iptables 等来为服务配置负载均衡(仅支持 TCP 和 UDP)。
kube-proxy 可以直接运行在物理机上,也可以以 static pod 或者 daemonset 的方式运行。
kube-proxy 当前支持以下几种实现
userspace:最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过 iptables 转发到这个端口,然后在其内部负载均衡到实际的 Pod。该方式最主要的问题是效率低,有明显的性能瓶颈。
iptables:目前推荐的方案,完全以 iptables 规则的方式来实现 service 负载均衡。该方式最主要的问题是在服务多的时候产生太多的 iptables 规则,非增量式更新会引入一定的时延,大规模情况下有明显的性能问题
ipvs:为解决 iptables 模式的性能问题,v1.11 新增了 ipvs 模式(v1.8 开始支持测试版,并在 v1.11 GA),采用增量式更新,并可以保证 service 更新期间连接保持不断开
winuserspace:同 userspace,但仅工作在 windows 节点上