中国大学MOOC-人工智能实践:Tensorflow笔记-课程笔记 Chapter7 卷积网络基础
本篇博客为学习中国大学MOOC-人工智能实践:Tensorflow笔记课程时的个人笔记记录。具体课程情况可以点击链接查看。(这里推一波中国大学MOOC,很好的学习平台,质量高,种类全,想要学习的话很有用的)
本篇是第七章的学习笔记,前面的六章笔记可以翻看我的博客.
Chapter 7 卷积网络基础
7.1 卷积神经网络
原始图片 -> 特征提取 ->全连接网络
卷积可以认为是一种有效的提取图像特征的方法.
一般会使用一个正方形卷积核,遍历图片上的每个点.图片区域内,相对应的每一个像素值,乘以卷积核内相应位置的权重,求和,再加上偏置.
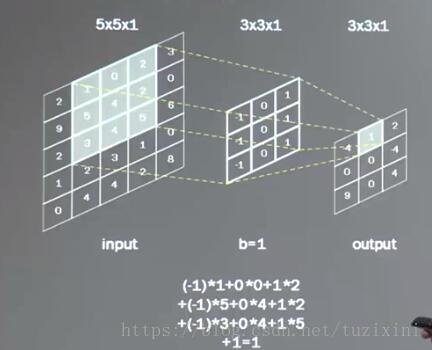
输出图片边长= (输入图片边长-卷积核边长+1)/步长
pading输入图片周围进行全0填充
padding = 'SAME' 或 padding = 'VALID'tf.nn.conv2d(输入描述[batch,行分辨率,列分辨率,通道数],卷积核描述[行分辨率,列分辨率,卷积核通道数,核个数(输出通道数)],核滑动步长[1,行步长,列步长,1],padding='SAME'或者'VALID')
# 输入图像是单色灰度图
tf.nn.conv2d([batch,5,5,1],[3,3,1,16],[1,1,1,1],padding='VALID')
# 输入图像是彩色RGB图
tf.nn.conv2d([batch,5,5,3],[3,3,3,16],[1,1,1,1],padding='SAME')
# padding 选择SAME 会是的输出的分辨率和输入一致,自动加padding池化
池化用于减少特征数量,
最大池化可以提取图片纹理,均值池化可以保留背景特征

max_pool = tf.nn.max_pool(输入描述[batch,行分辨率,列分辨率,通道数],池化核描述[1,行分辨率,列分辨率,1],池化核滑动步长[1,行步长,列步长,1],padding='SAME'或'VALID')
avg_pool = tf.nn.avg_pool(输入描述[batch,行分辨率,列分辨率,通道数],池化核描述[1,行分辨率,列分辨率,1],池化核滑动步长[1,行步长,列步长,1],padding='SAME'或'VALID')Dropout
在神经网络的训练过程中,将一部分神经元按照一定概率从神经网络中暂时舍弃,使用神经网络的时候被舍弃的神经元恢复连接.
作用:减轻过拟合,加快训练速度

tf.nn.dropout(上层输出,暂时舍弃的概率)
if train: 输出 = tf.nn.dropout(上层输出,暂时舍弃的概率)卷积神经网络:
借助卷积核(kernel)提取特征后,送入全连接网络
CNN模型的主要模块:

Lenet-5 -> AlexNet -> VGGNet -> GoogleNet -> ResNet……
7.2 Lenet-5 代码讲解
Lenet-5 的结构

更改后适用于mnist数据集的Lenet-5

和之前的课程类似,适用的代码主要有
mnist_lenet5_forward.py
mnist_lenet5_backward.py
mnist_lenet5_test.py
三个文件
其实思路上和之前使用全连接层进行训练时候是一致的,只不过这里使用的是卷积层罢了.
分别的代码如下:
注意:老师上课PPT中展示的代码并不是完全正确的,不能够直接跑通,助教笔记中的代码应该是可以跑通的,不过自己数据模型啥的放的位置肯定是需要调节的,我这里给的代码是我自己debug之后得到的可以跑通的代码,肯定数据位置啥的都是我自己使用的位置.
mnist_lenet5_forward.py
#coding:utf-8
import tensorflow as tf
IMAGE_SIZE = 28
NUM_CHANNELS = 1
CONV1_SIZE = 5
CONV1_KERNEL_SIZE = 32
CONV2_SIZE = 5
CONV2_KERNEL_SIZE = 64
FC_SIZE = 512
OPTPUT_NODE = 10
def get_weight(shape, regularizer):
w = tf.Variable(tf.truncated_normal(shape,stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w
def get_bias(shape):
b = tf.Variable(tf.zeros(shape))
return b
def conv2d(x,w):
return tf.nn.conv2d(x, w, strides=[1,1,1,1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
def forward(x, train, regularizer):
conv1_w = get_weight([CONV1_SIZE, CONV1_SIZE, NUM_CHANNELS, CONV1_KERNEL_SIZE], regularizer)
conv1_b = get_bias([CONV1_KERNEL_SIZE])
conv1 = conv2d(x, conv1_w)
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_b))
pool1 = max_pool_2x2(relu1)
conv2_w = get_weight([CONV2_SIZE, CONV2_SIZE, CONV1_KERNEL_SIZE, CONV2_KERNEL_SIZE], regularizer)
conv2_b = get_bias([CONV2_KERNEL_SIZE])
conv2 = conv2d(pool1, conv2_w)
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_b))
pool2 = max_pool_2x2(relu2)
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
reshaped = tf.reshape(pool2, [pool_shape[0], nodes])
fc1_w = get_weight([nodes, FC_SIZE], regularizer)
fc1_b = get_bias([FC_SIZE])
fc1 = tf.nn.relu(tf.matmul(reshaped,fc1_w) + fc1_b)
if train: fc1 = tf.nn.dropout(fc1, 0.5)
fc2_w = get_weight([FC_SIZE, OPTPUT_NODE], regularizer)
fc2_b = get_bias([OPTPUT_NODE])
y = tf.matmul(fc1, fc2_w) + fc2_b
return ymnist_lenet5_backward.py
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_lenet5_forward
import os
import numpy as np
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.005
LEARNING_RATE_DECAY = 0.99
REGULARIZER = 0.0001
STEPS = 50000
MOVING_AVERAGE_DECAY = 0.99
MODEL_SAVE_PATH = 'G:/model/mnist_lenet/' #这里是我选择放置训练好的model的路径,根据自己的需要进行修改
MODEL_NAME = 'mnist_lenet_model'
DATA_PATH = 'G:/datasets/mnist' #这里是我放置dataset的路径,根据自己的需要进行修改
def backward(mnist):
x = tf.placeholder(tf.float32,[BATCH_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OPTPUT_NODE])
y = mnist_lenet5_forward.forward(x, True, REGULARIZER)
global_step = tf.Variable(0, trainable=False)
ce = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_, 1))
cem = tf.reduce_mean(ce)
loss = cem + tf.add_n(tf.get_collection('losses'))
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,mnist.train.num_examples / BATCH_SIZE,LEARNING_RATE_DECAY,staircase = True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
ema_op = ema.apply(tf.trainable_variables())
with tf.control_dependencies([train_step, ema_op]):
train_op = tf.no_op(name = 'train')
saver = tf.train.Saver()
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 加入断点续训功能
ckpt = tf.train.get_checkpoint_state(MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
for i in range(STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
reshaped_xs = np.reshape(xs,(BATCH_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS))
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: reshaped_xs, y_: ys})
if i % 100 == 0:
print("After %d training steps, loss on training batch is %g." % (step, loss_value))
saver.save(sess, os.path.join(MODEL_SAVE_PATH,MODEL_NAME),global_step=global_step)
def main():
mnist = input_data.read_data_sets(DATA_PATH, one_hot = True)
backward(mnist)
if __name__ == '__main__':
main()mnist_lenet5_test.py
#coding:utf-8
import time
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_lenet5_backward
import mnist_lenet5_forward
import numpy as np
TEST_INTERVAL_SECS = 5
DATA_PATH = 'G:/datasets/mnist' #这里是我放置dataset的路径,根据自己的需要进行修改
def test(mnist):
with tf.Graph().as_default() as g:
x = tf.placeholder(tf.float32,[mnist.test.num_examples, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS])
y_ = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.OPTPUT_NODE])
y = mnist_lenet5_forward.forward(x, False, None)
ema = tf.train.ExponentialMovingAverage(mnist_lenet5_backward.MOVING_AVERAGE_DECAY)
ema_restore = ema.variables_to_restore()
saver = tf.train.Saver(ema_restore)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
while True:
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_lenet5_backward.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
global_step = ckpt.model_checkpoint_path.split('/')[-1].split('-')[-1]
reshaped_xs = np.reshape(mnist.test.images,(mnist.test.num_examples, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS))
accuracy_score = sess.run(accuracy, feed_dict={x: reshaped_xs, y_: mnist.test.labels})
print("After %s training steps, test accuracy = %g" % (global_step, accuracy_score))
else:
print("No checkpoint file found!")
return
time.sleep(TEST_INTERVAL_SECS)
def main():
mnist = input_data.read_data_sets(DATA_PATH, one_hot=True)
test(mnist)
if __name__ == '__main__':
main()训练测试效果:

最后我还在之前课的基础上自行修改得到了一个mnist_lenet5_app.py文件,类似于之前的mnist_app.py文件,这个代码直接读取实际的手写照片作为输入,然后输出检测出的手写数字值.
mnist_lenet5_app.py
#coding:utf-8
import tensorflow as tf
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import mnist_lenet5_backward
import mnist_lenet5_forward
def restore_model(testPicArr):
with tf.Graph().as_default() as tg:
x = tf.placeholder(tf.float32, [1, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS])
y = mnist_lenet5_forward.forward(x, False, None)
preValue = tf.arg_max(y, 1)
variable_averages = tf.train.ExponentialMovingAverage(mnist_lenet5_backward.MOVING_AVERAGE_DECAY)
variables_to_restore = variable_averages.variables_to_restore()
saver = tf.train.Saver(variables_to_restore)
with tf.Session() as sess:
ckpt = tf.train.get_checkpoint_state(mnist_lenet5_backward.MODEL_SAVE_PATH)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path)
preValue = sess.run(preValue, feed_dict={x:testPicArr})
return preValue
else:
print("No checkpoint file found")
return -1
def pre_pic(picName):
img = Image.open(picName)
reIm = img.resize((28,28), Image.ANTIALIAS)
im_arr = np.array(reIm.convert('L'))
threshold = 80
for i in range(28):
for j in range(28):
im_arr[i][j] = 255-im_arr[i][j]
if (im_arr[i][j]0
else: im_arr[i][j] = 255
plt.figure("figure")
plt.imshow(im_arr)
plt.show()
nm_arr = im_arr.reshape([1, 28, 28, 1])
nm_arr = nm_arr.astype(np.float32)
img_ready = np.multiply(nm_arr, 1.0/255.0)
return img_ready
def application():
for i in range(10):
imName = 'pic/'+str(i)+'.jpg'
print("ImageName is:", imName)
testPicArr = pre_pic(imName)
preValue = restore_model(testPicArr)
print("The prediction number is:", preValue)
def main():
application()
if __name__ == '__main__':
main() 这里记录一个遇到的bug:
输入的数据应该是[1,28,28,1]格式的矩阵,但是怎么都提示”Failed to convert object of type
x = tf.placeholder(tf.float32, [1, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS])这句代码上,我一开始是照着fc的那个app的代码写的,第二个参数的第一个值我用的是None,也就是这个样子
x = tf.placeholder(tf.float32, [None, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.IMAGE_SIZE, mnist_lenet5_forward.NUM_CHANNELS])结果程序就一直不能正常运行,后来我尝试着把它换成1,然后就好了,其实我最后也没弄懂为什么不能用None,按理说要是这里不能用None的话,之前的fc应该也是不能用None才对的(如果是因为1不能使用None代替的话),但是之前的程序是好好的没毛病.
最后使用Lenet5 检测的结果如下图所示:

可以看到这个0 和7 还是识别出错了,估计是我写的太丑了哈哈.
不过我使用的这个modle也不是跑完训练的结果,是中途训练结束得到的结果,好像只运行了3000STEPS左右,这玩意跑起来太占用CPU了,电脑会卡,我就没有接着让它跑.
需要使用我制作的这几个测试图片的朋友可以从以下地址下载,
https://download.csdn.net/download/tuzixini/10560123
下载解压后将所有图片放在pic文件夹下即可,pic文件夹需要和代码文件在同一文件夹下.