GPU服务器的上手使用-小试牛刀
1. 前言
深度学习、图像渲染、科学计算、挖矿这些复杂计算的场景都需要使用GPU进行大量计算,但是当你拿到一台GPU服务器以后,你应该如何入手学习呢,如何进行调试呢。本文主要讲解一些GPU相关的知识,从GPU简单介绍开始,进而到linux下如何查看GPU相关指标,最后讲解如何调试调用GPU,并使用GPU运行简单程序。
注:本文讲解使用的GPU是NVIDIA GPU。
2. GPU知识介绍
2.1 GPU简单介绍
GPU全称graphics processing unit,中文译名图形处理器,又称显示核心、视觉处理器、显示芯片。通常一般的程序任务直接是由CPU完成,但是对于密集型计算任务,就需要借助GPU来完成了。我们对CPU结构非常熟悉,一颗处理器其实由几个或几十个运算核心组合而成的,而GPU却拥有上百颗甚至上千个运算核心,所以GPU具有强大的计算能力。
2.2 CUDA简单介绍
要使用GPU进行计算,就需要有接口来调用GPU,CUDA就实现了完整的GPU调度方案。CUDA是NVIDIA公司推出的一种基于GPU的通用并行计算平台,提供了硬件的直接访问接口。CUDA采用C语言作为编程语言提供大量的高性能计算指令开发能力,使开发者能够在GPU的强大计算能力的基础上建立起一种效率更高的密集数据计算解决方案。
上面简要对GPU做了个介绍,下面直接进入实操部分吧。
3. linux的GPU查看
3.1 查看GPU硬件
查看GPU简略信息
[root@gpu-node ~]# lspci | grep -i vga | grep -i nvidia

可以看到服务器有8块NVIDIA的显卡
查看某一块显卡的具体详细信息
[root@gpu-node ~]# lspci -v -s 04:00.0
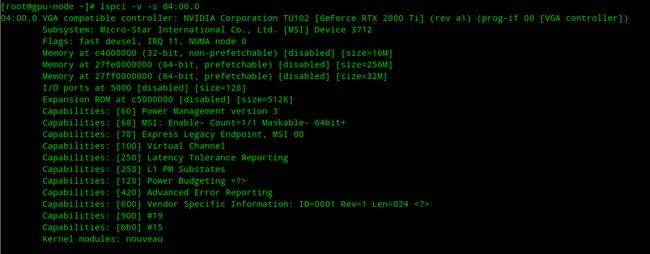
直接查看所有显卡详细信息-1
[root@gpu-node ~]# lspci -vnn | grep -i vga -A 12

直接查看所有显卡详细信息-2
[root@gpu-node ~]# lshw -C display

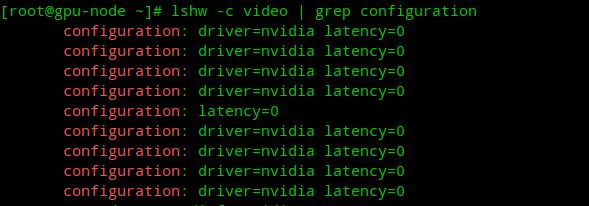
查看系统所使用的显卡驱动名称
[root@gpu-node ~]# lshw -c video | grep configuration
3.2 安装显卡驱动
禁用系统默认显卡驱动nouveau
nouveau是一个第三方开源的NVIDIA驱动,一般Linux系统安装的时候都会默认安装这个驱动,这个驱动会与NVIDIA官方的驱动冲突。
[root@gpu-node ~]# lsmod | grep nouveau
[root@gpu-node ~]# vim /usr/lib/modprobe.d/nvidia.conf
blacklist nouveau
options nouveau modeset=0
# Uncomment the following line to enable kernel modesetting support.
# There is NO graphical framebuffer (like OSS drivers) at the moment; this is
# only for Wayland. For Gnome, you also require an EGLStream build of Mutter.
# options nvidia-drm modeset=1
建立新的镜像
[root@gpu-node ~]# dracut /boot/initramfs-$(uname -r).img $(uname -r) --force
[root@gpu-node ~]# reboot
[root@gpu-node ~]# lsmod | grep nouveau
从NVIDIA官网:https://www.nvidia.com/Download/Find.aspx 下载对应显卡版本的驱动安装版本包。
[root@gpu-node ~]# wget https://us.download.nvidia.com/XFree86/Linux-x86_64/460.56/NVIDIA-Linux-x86_64-460.56.run
[root@gpu-node ~]# chmod +x NVIDIA-Linux-x86_64-460.56.run
安装系统对应的gcc和kernel-devel,驱动在安装过程种需要编译kernel module
[root@gpu-node ~]# yum install -y gcc kernel-devel-$(uname -r)
安装dkms,注册nvidia驱动到dkms中,通过dkms管理,当内核更新的时候,会自动build新的nvidia内核模块
[root@gpu-node ~]# yum install -y dkms
[root@gpu-node ~]# ./NVIDIA-Linux-x86_64-460.56.run --dkms --silent
--silent 静默安装,不弹出图形化UI界面
安装成功后可以执行 nvidia-smi
如果要卸载可以执行
[root@gpu-node ~]# ./NVIDIA-Linux-x86_64-460.56.run --uninstall --silent
查看是否有nvidia软件包,可以yum remove卸载干净
[root@gpu-node ~]# rpm -qa | grep -i nvidia
安装后验证
查看系统已安装的NVIDIA module
[root@gpu-node ~]# lsmod|grep nvidia

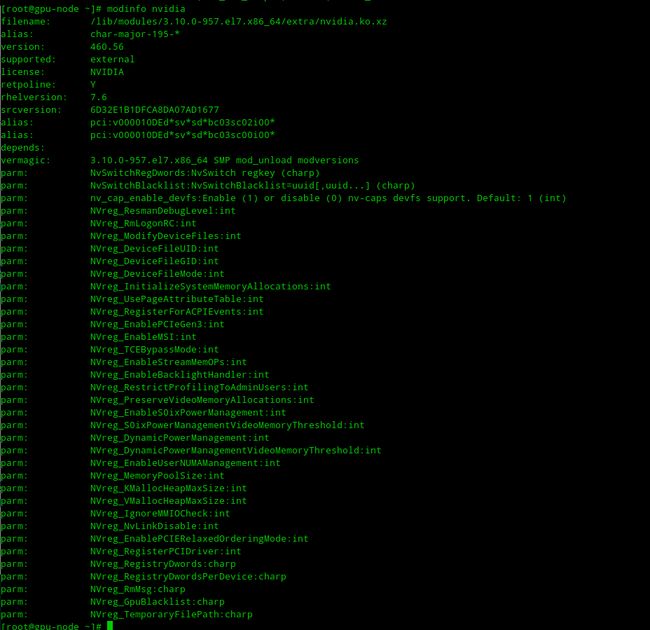
查看nvidia的路径与版本等信息
[root@gpu-node ~]# modinfo nvidia
3.3 nvidia-smi的使用
nvidia-smi可以直接查看GPU当前使用情况
[root@gpu-node ~]# nvidia-smi

输出解释:
GPU:表示显卡编号,从0开始;
Fan:表示风扇转速,数值在0到100%之间,是计算机期望的风扇转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是N/A;
Name:表示显卡名称;
Temp:表示显卡内部的温度,单位是摄氏度,GPU温度过高会导致GPU频率下降;
Perf:表示性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能;
Pwr:表示能耗,上方的Persistence-M表示是持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态;
Bus-Id:表示GPU总线的相关信息,domain:bus:device.function;
Disp.A:即Display Active,表示GPU的显示是否初始化;
Memory Usage:表示显存使用率;
Volatile GPU-Util:浮动的GPU利用率;
ECC:是否开启错误检查和纠正技术,0/DISABLED, 1/ENABLED;
Compute M:计算模式0/DEFAULT,1/EXCLUSIVE_PROCESS,2/PROHIBITED;
最下边一栏的Processes表示每块GPU上每个进程所使用的显存情况,其中Type 有C和G,C表示计算的进程,G表示图像处理的进程。显卡占用和GPU占用是两个不一样的东西,显卡是由GPU和显卡等组成的,显卡和GPU的关系有点类似于内存和CPU的关系,两个指标的占用率不一定是互相对应的。
结合watch命令动态监控GPU使用情况
[root@gpu-node ~]# watch -n 1 nvidia-smi
3.4 安装cuda
cuda下载地址:https://developer.nvidia.com/cuda-toolkit-archive
[root@gpu-node ~]# wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda-repo-rhel7-11-2-local-11.2.0_460.27.04-1.x86_64.rpm
[root@gpu-node ~]# rpm -ivh cuda-repo-rhel7-11-2-local-11.2.0_460.27.04-1.x86_64.rpm
[root@gpu-node ~]# yum install -y cuda
查看安装信息
[root@gpu-node ~]# /usr/local/cuda/bin/nvcc -V

4. 程序调用GPU
下面讲解如何使用python程序调用GPU
4.1 pycuda安装
pycuda是一个可以访问NVIDIA的CUDA的python库
[root@gpu-node ~]# pip3 install pycuda==2018.1.1 -i https://pypi.mirrors.ustc.edu.cn/simple/
可能会出现如下错误信息:
gcc -pthread -Wno-unused-result -Wsign-compare -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -D_GNU_SOURCE -fPIC -fwrapv -O3 -DNDEBUG -fPIC -DBOOST_ALL_NO_LIB=1 -DBOOST_THREAD_BUILD_DLL=1 -DBOOST_MULTI_INDEX_DISABLE_SERIALIZATION=1 -DBOOST_PYTHON_SOURCE=1 -Dboost=pycudaboost -DBOOST_THREAD_DONT_USE_CHRONO=1 -DPYGPU_PACKAGE=pycuda -DPYGPU_PYCUDA=1 -DHAVE_CURAND=1 -Isrc/cpp -Ibpl-subset/bpl_subset -I/usr/local/lib64/python3.6/site-packages/numpy/core/include -I/usr/include/python3.6m -c src/cpp/cuda.cpp -o build/temp.linux-x86_64-3.6/src/cpp/cuda.o
In file included from src/cpp/cuda.cpp:4:0:
src/cpp/cuda.hpp:14:18: fatal error: cuda.h: No such file or directory
#include
^
编译中断。
error: command 'gcc' failed with exit status 1
----------------------------------------
Command "/usr/bin/python3 -u -c "import setuptools, tokenize;__file__='/tmp/pip-build-slw8h082/pycuda/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /tmp/pip-ig9vl5ig-record/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /tmp/pip-build-slw8h082/pycuda/

出现上面报错是因为cuda的相关的命令没有加入到环境变量
添加环境变量即可
[root@gpu-node ~]# export PATH=/usr/local/cuda-11.2/bin:/usr/local/cuda/bin:$PATH
4.2 程序调用
我的第一个GPU调用程序小例子
vim gpu.py
import pycuda.autoinit
from pycuda.compiler import SourceModule
import time
mod = SourceModule("""
#include
__global__ void work()
{
printf("Manage GPU success!\\n");
}
""")
func = mod.get_function("work")
func(block=(1,1,1))
time.sleep(30)
执行python gpu.py
使用 nvidia-smi 查看可以发现Process里面有进程使用GPU显卡,说明我们的程序调用GPU成功

默认是使用第0个GPU,如果要使用其他GPU:
1.可以使用CUDA_VISIBLE_DEVICES=1 python3 gpu.py表示使用第一个1块显卡;
2.可以使用CUDA_DEVICE=0,1,2 python3 gpu.py表示使用第0块、1块、2块显卡,当第0块显卡显存使用完毕后,会自动使用第1块,以此类推;
3.或者直接将调用的设置写在程序里
import time,os
os.environ[“CUDA_VISIBLE_DEVICES”] = “2”
注意必须写在 import pycuda.autoinit 前面
进化版:同时使用多个GPU
work.py
import time,os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3,4,5,6,7"
import pycuda.autoinit
from pycuda.compiler import SourceModule
mod = SourceModule("""
#include
__global__ void work()
{
printf("Manage GPU success!\\n");
}
""")
func = mod.get_function("work")
func(block=(1,1,1))
time.sleep(60)
mul_gpu.py
import os,threading
cmd = "export PATH=/usr/local/cuda-11.2/bin:/usr/local/cuda/bin:$PATH;/usr/bin/python3 /root/mul_gpu.py"
threads = []
def test():
os.system(cmd)
for i in range(80):
t = threading.Thread(target=test,args=())
t.start()
threads.append(t)
for i in threads:
i.join()
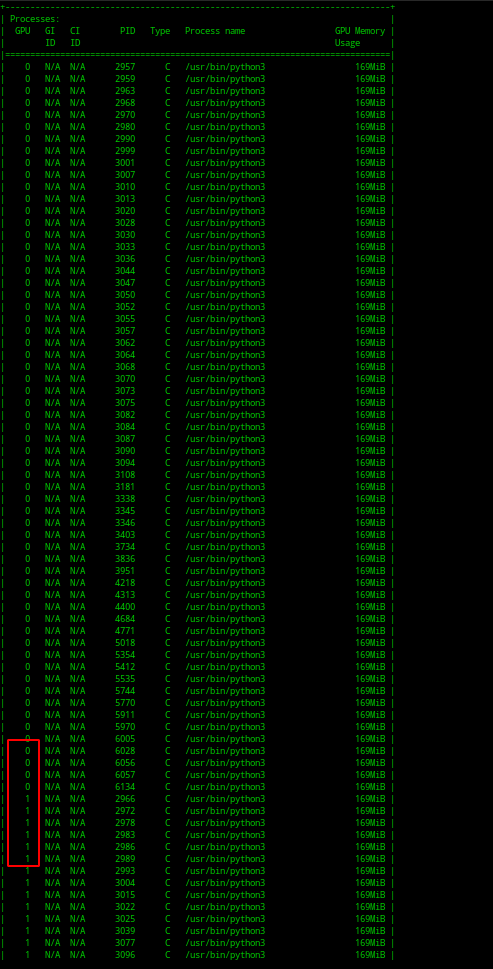
运行 python3 mul_gpu.py
可以看到跑多个任务时,第0块GPU跑满后,会接着调度第1块GPU。