《python深度学习》学习笔记与代码实现(第六章,6.2理解循环神经网络)
《python深度学习》第六章
6.2 理解循环神经网络
首先,用numpy自己写一个简单的神经网络来认识神经网络
import numpy as np
timesteps = 10
input_features = 32
output_features = 64
# 输入数据,随机噪声,仅作示例
inputs = np.random.random((timesteps,input_features))
# 输出数据,初始状态,全零向量
state_t = np.zeros((output_features,))
# 创建随机的权重矩阵
W = np.random.random((output_features,input_features))
U = np.random.random((output_features,output_features))
b = np.random.random((output_features,))
successive_outputs = []
for input_t in inputs:
output_t = np.tanh(np.dot(W,input_t) + np.dot(U,state_t) + b)
successive_outputs.append(output_t)
# 更新网络的状态,用于下一个时间步
state_t = output_t
final_output_sequence = np.stack(successive_outputs,axis = 0)
# print(final_output_sequence)
简单理解:本层的输入,与上一层的输出有关,还有之前的状态有关
6.2.1 keras中的循环层
# 6.2.1 keras中的循环层
from keras.layers import SimpleRNN
# SimpleRNN 不仅可以处理单个输入,也可以处理批量输入
# SimpleRNN 的输出有两种模式,一种是输出每一步的结果,一种是只输出最终结果,
from keras.models import Sequential
from keras.layers import Embedding,SimpleRNN
model = Sequential()
# 举一个例子,,只输出最终结果
model.add(Embedding(10000,32))
model.add(SimpleRNN(32))
model.summary()
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 32) 320000
_________________________________________________________________
simple_rnn_1 (SimpleRNN) (None, 32) 2080
=================================================================
Total params: 322,080
Trainable params: 322,080
Non-trainable params: 0
_________________________________________________________________
# 举一个例子,输出每一步的结果
model = Sequential()
model.add(Embedding(10000,32))
model.add(SimpleRNN(32,return_sequences = True))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, None, 32) 320000
_________________________________________________________________
simple_rnn_2 (SimpleRNN) (None, None, 32) 2080
=================================================================
Total params: 322,080
Trainable params: 322,080
Non-trainable params: 0
_________________________________________________________________
# 举一个例子,可以多个循环层堆叠使用,最后只输出最终结果
model = Sequential()
model.add(Embedding(10000,32))
model.add(SimpleRNN(32,return_sequences = True))
model.add(SimpleRNN(32,return_sequences = True))
model.add(SimpleRNN(32,return_sequences = True))
model.add(SimpleRNN(32))
model.summary()
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, None, 32) 320000
_________________________________________________________________
simple_rnn_3 (SimpleRNN) (None, None, 32) 2080
_________________________________________________________________
simple_rnn_4 (SimpleRNN) (None, None, 32) 2080
_________________________________________________________________
simple_rnn_5 (SimpleRNN) (None, None, 32) 2080
_________________________________________________________________
simple_rnn_6 (SimpleRNN) (None, 32) 2080
=================================================================
Total params: 328,320
Trainable params: 328,320
Non-trainable params: 0
_________________________________________________________________
# 接下来,我们将这个模型应用于IMDB电影评论分类问题
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 10000 # 作为特征的单词个数
maxlen = 500 # 在这么多单词之后截断文本(这些单词都属于前max_featurs个最常见的单词)
batch_size = 32
print('loading data......')
(input_train,y_train),(input_test,y_test) = imdb.load_data(num_words = max_features)
print(len(input_train),'train sequences')
print(len(input_test),'test sequences')
print('Pad sequences (samples x time)')
input_train = sequence.pad_sequences(input_train,maxlen = maxlen)
input_test = sequence.pad_sequences(input_test,maxlen = maxlen)
print('input_train shape:',input_train.shape)
print('input_test shape:',input_test.shape)
loading data......
25000 train sequences
25000 test sequences
Pad sequences (samples x time)
input_train shape: (25000, 500)
input_test shape: (25000, 500)
from keras.layers import Dense
model = Sequential()
model.add(Embedding(10000,32))
model.add(SimpleRNN(32))
model.add(Dense(1,activation = 'sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
Epoch 1/10
20000/20000 [==============================] - 49s 2ms/step - loss: 0.6428 - acc: 0.6134 - val_loss: 0.5584 - val_acc: 0.7274
Epoch 2/10
20000/20000 [==============================] - 40s 2ms/step - loss: 0.4147 - acc: 0.8239 - val_loss: 0.4158 - val_acc: 0.81620.4157 - acc: 0
Epoch 3/10
20000/20000 [==============================] - 32s 2ms/step - loss: 0.3018 - acc: 0.8789 - val_loss: 0.3776 - val_acc: 0.8370
Epoch 4/10
20000/20000 [==============================] - 31s 2ms/step - loss: 0.2277 - acc: 0.9137 - val_loss: 0.3646 - val_acc: 0.8654
Epoch 5/10
20000/20000 [==============================] - 31s 2ms/step - loss: 0.1697 - acc: 0.9390 - val_loss: 0.3740 - val_acc: 0.8666
Epoch 6/10
20000/20000 [==============================] - 30s 2ms/step - loss: 0.1205 - acc: 0.9579 - val_loss: 0.4340 - val_acc: 0.8380
Epoch 7/10
20000/20000 [==============================] - 30s 2ms/step - loss: 0.0810 - acc: 0.9739 - val_loss: 0.4696 - val_acc: 0.8396
Epoch 8/10
20000/20000 [==============================] - 31s 2ms/step - loss: 0.0461 - acc: 0.9857 - val_loss: 0.5436 - val_acc: 0.8164
Epoch 9/10
20000/20000 [==============================] - 31s 2ms/step - loss: 0.0343 - acc: 0.9900 - val_loss: 0.6100 - val_acc: 0.8038
Epoch 10/10
20000/20000 [==============================] - 33s 2ms/step - loss: 0.0228 - acc: 0.9931 - val_loss: 0.6399 - val_acc: 0.8122
1
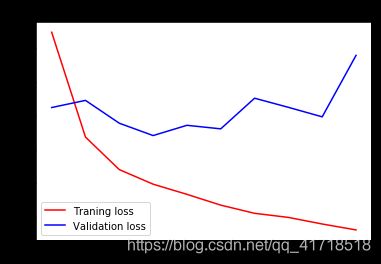
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc) + 1)
plt.plot(epochs,acc,'r',label = 'Traning acc')
plt.plot(epochs,val_acc,'b',label = 'Validation acc')
plt.title('training and validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'r',label = 'Traning loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title('training and validation loss')
plt.legend()
plt.show()

理解LSTM(长短期记忆)和GRU层
LSTM的作用:允许过去的信息稍后重新输入,从而解决梯度消失的问题
现在让我们转到更实际的问题:我们将使用LSTM层建立模型并将其训练到IMDB数据上。这是网络,类似于我们刚才提出的SimulnNN网络。我们只指定LSTM层的输出维度,并将每个其他参数(有很多)留给KERAS默认值。Keras有很好的缺省值,无需手动调参,模型也能正常运行
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features,32))
model.add(LSTM(32))
model.add(Dense(1,activation = 'sigmoid'))
model.compile(optimizer = 'rmsprop',loss = 'binary_crossentropy',metrics = ['acc'])
history = model.fit(input_train,y_train,epochs = 10,batch_size = 32 ,validation_split = 0.2)
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
20000/20000 [==============================] - 503s 25ms/step - loss: 0.4237 - acc: 0.8098 - val_loss: 0.3122 - val_acc: 0.8678
Epoch 2/10
20000/20000 [==============================] - 550s 27ms/step - loss: 0.2684 - acc: 0.8980 - val_loss: 0.3228 - val_acc: 0.8656
Epoch 3/10
20000/20000 [==============================] - 539s 27ms/step - loss: 0.2202 - acc: 0.9171 - val_loss: 0.2890 - val_acc: 0.8856
Epoch 4/10
20000/20000 [==============================] - 516s 26ms/step - loss: 0.1987 - acc: 0.9273 - val_loss: 0.2707 - val_acc: 0.8926
Epoch 5/10
20000/20000 [==============================] - 507s 25ms/step - loss: 0.1836 - acc: 0.9337 - val_loss: 0.2859 - val_acc: 0.8944
Epoch 6/10
20000/20000 [==============================] - 503s 25ms/step - loss: 0.1676 - acc: 0.9406 - val_loss: 0.2806 - val_acc: 0.8826
Epoch 7/10
20000/20000 [==============================] - 487s 24ms/step - loss: 0.1555 - acc: 0.9444 - val_loss: 0.3260 - val_acc: 0.8870
Epoch 8/10
20000/20000 [==============================] - 500s 25ms/step - loss: 0.1494 - acc: 0.9483 - val_loss: 0.3125 - val_acc: 0.8874
Epoch 9/10
20000/20000 [==============================] - 503s 25ms/step - loss: 0.1397 - acc: 0.9527 - val_loss: 0.2984 - val_acc: 0.8918
Epoch 10/10
20000/20000 [==============================] - 487s 24ms/step - loss: 0.1309 - acc: 0.9552 - val_loss: 0.3894 - val_acc: 0.8742
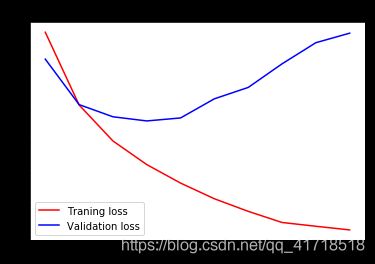
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc) + 1)
plt.plot(epochs,acc,'r',label = 'Traning acc')
plt.plot(epochs,val_acc,'b',label = 'Validation acc')
plt.title('training and validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'r',label = 'Traning loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title('training and validation loss')
plt.legend()
plt.show()