如何配置yolov5并训练自己的模型
提前准备
- Pycharm
- python3.8
- yolov5源码 官网链接
1. 环境搭建并运行官方案例
-
下载yolov5源码,推荐使用最新版,如下图,直接下载master分支即可

-
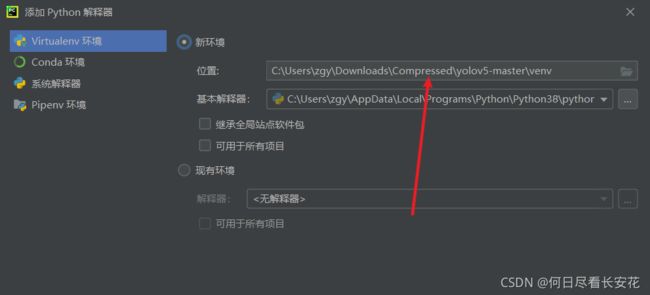
解压下载的zip文件,使用pycharm打开项目,接着添加解释器

-
这里使用新环境,没有用anaconda,因为使用pycharm自带的python环境可以让虚拟环境跟随项目,在其他电脑运行时候就不用重新配置环境了。

- 使用pycharm的终端安装requirements.txt中需要的环境,直接在终端
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
- 使用国内源可以下载快些。
- 提前下载yolov5s.pt预训练权重GitHub链接,(也可以不下载,运行detect.py的时候会自动下载,但是容易下载出错,因为GitHub网络问题),下载好后放在yolov5-master文件夹里面


- 右键运行detect.py文件,如果出现下图即表示环境搭建成功(运行的是自带的模型,识别人,汽车等),此时生成run文件夹,结果存放在yolov5-master/run/detect/exp文件内



- 没有使用cuda进行加速,因为有些小伙伴可能没有N卡,所以使用的CPU版本,想使用GPU加速只需要安装GPU版本的pytorch即可,但是要看看自己显卡支持的cuda版本,参考这篇博文https://blog.csdn.net/didiaopao/article/details/119787139 链接直达
2. 创建并划分数据集
参考下面博文即可
https://blog.csdn.net/didiaopao/article/details/120022845链接直达
- VOC标签格式转yolo格式并划分训练集和测试集
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["hat", "person"] # 自定义类
TRAIN_RATIO = 80 # 8:2 训练集和验证集比率
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
- 需要注意划分的代码和数据集应在同一目录下

3. 训练自己的数据集
- 参考下面博文 https://blog.csdn.net/didiaopao/article/details/119954291 链接直达
- 上面博文中复制出来的hat.yaml与我下载yolov5中新版voc.yaml的不一样,推荐使用新版(新版还有一个download,删除即可,它是下载voc数据集)
# YOLOv5 by Ultralytics, GPL-3.0 license
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC
# Example usage: python train.py --data VOC.yaml
# parent
# ├── yolov5
# └── datasets
# └── VOC ← downloads here
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: C:/Users/zgy/Downloads/Compressed/yolov5-master/VOCdevkit
train: # train images (relative to 'path') 16551 images
- images/train
val: # val images (relative to 'path') 4952 images
- images/val
test: # test images (optional)
# Classes
nc: 2 # number of classes
names: ['hat', 'person'] # class names
- 新版voc.yaml如下
# YOLOv5 by Ultralytics, GPL-3.0 license
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC
# Example usage: python train.py --data VOC.yaml
# parent
# ├── yolov5
# └── datasets
# └── VOC ← downloads here
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/VOC
train: # train images (relative to 'path') 16551 images
- images/train2012
- images/train2007
- images/val2012
- images/val2007
val: # val images (relative to 'path') 4952 images
- images/test2007
test: # test images (optional)
- images/test2007
# Classes
nc: 20 # number of classes
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names
# Download script/URL (optional) ---------------------------------------------------------------------------------------
download: |
import xml.etree.ElementTree as ET
from tqdm import tqdm
from utils.general import download, Path
def convert_label(path, lb_path, year, image_id):
def convert_box(size, box):
dw, dh = 1. / size[0], 1. / size[1]
x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
return x * dw, y * dh, w * dw, h * dh
in_file = open(path / f'VOC{
year}/Annotations/{
image_id}.xml')
out_file = open(lb_path, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls in yaml['names'] and not int(obj.find('difficult').text) == 1:
xmlbox = obj.find('bndbox')
bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
cls_id = yaml['names'].index(cls) # class id
out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
# Download
dir = Path(yaml['path']) # dataset root dir
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
urls = [url + 'VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
url + 'VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
url + 'VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
download(urls, dir=dir / 'images', delete=False)
# Convert
path = dir / f'images/VOCdevkit'
for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
imgs_path = dir / 'images' / f'{
image_set}{
year}'
lbs_path = dir / 'labels' / f'{
image_set}{
year}'
imgs_path.mkdir(exist_ok=True, parents=True)
lbs_path.mkdir(exist_ok=True, parents=True)
image_ids = open(path / f'VOC{
year}/ImageSets/Main/{
image_set}.txt').read().strip().split()
for id in tqdm(image_ids, desc=f'{
image_set}{
year}'):
f = path / f'VOC{
year}/JPEGImages/{
id}.jpg' # old img path
lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
f.rename(imgs_path / f.name) # move image
convert_label(path, lb_path, year, id) # convert labels to YOLO format