机器学习实战(一)k-近邻kNN(k-Nearest Neighbor)
目录
0. 前言
1. k-近邻算法kNN(k-Nearest Neighbor)
2. 实战案例
2.1. 简单案例
2.2. 约会网站案例
2.3. 手写识别案例
学习完机器学习实战的k-近邻算法,简单的做个笔记。文中部分描述属于个人消化后的理解,仅供参考。
所有代码和数据可以访问 我的 github
如果这篇文章对你有一点小小的帮助,请给个关注喔~我会非常开心的~
0. 前言
k-近邻算法kNN(k-Nearest Neighbor)是一种监督学习的分类算法,算法思想是通过判断向量之间的距离,决定所属的类别。
- 优点:精度高、对异常值不敏感
- 缺点:计算复杂度高、空间复杂度高
- 适用数据类型:数值型和标称型
1. k-近邻算法kNN(k-Nearest Neighbor)
算法流程可描述如下:
- 已知待测试样本
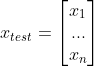 ,训练集合
,训练集合 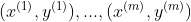
- 计算待测试样本与训练集合中每一个样本的欧式距离
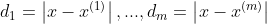
- 对
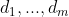 从小到大排序
从小到大排序 - 选择前
 个距离最短的样本,其中出现次数最多的类别,就是待测试样本的分类结果
个距离最短的样本,其中出现次数最多的类别,就是待测试样本的分类结果
其中, 与
与 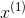 的欧式距离表示为:
的欧式距离表示为:
![]()
注:kNN算法必须保存所有的样本数据集,并且每一个测试样本,都要计算其与所有样本数据的距离,所以时间复杂度和空间复杂度都很高。
2. 实战案例
以下将展示书中的三个案例的代码段,所有代码和数据可以在github中下载:
2.1. 简单案例
# coding:utf-8
from numpy import *
import operator
"""
简单案例
"""
# 创建数据集和标签
def createDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
# 分类算法
def classify0(intX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
# tile():
# 在行方向上重复 intX,dataSetSize 次
# 在列方向上重复 intX,1 次
diffMat = tile(intX, (dataSetSize, 1)) - dataSet
# ** 表示平方
sqDiffMat = diffMat ** 2
# sum(axis=0) 表示每一列相加
# sum(axis=1) 表示每一行相加
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
# argsort():
# 按照数值从小到大,对数字的索引进行排序
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
# {}.get(voteIlabel, 0):
# 查找键值 voteIlabel,如果键值不存在则返回 0
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# key=operator.itemgetter(1)
# 获取对象第 1 个域的值
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
if __name__ == '__main__':
group, labels = createDataSet()
intX = [0, 0]
k = 3
clasifierResult = classify0(intX, group, labels, k)
print(clasifierResult)
2.2. 约会网站案例
# coding:utf-8
from numpy import *
import matplotlib.pyplot as plt
import operator
"""
约会网站案例
"""
# 将txt文中中的数据转换为矩阵
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
# strip():
# 移除字符串头尾的指定字符
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
# 均值归一化
def autoNorm(dataSet):
# min(a):
# a=0 每列的最小值
# a=1 每行的最小值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
meanVals = dataSet.mean(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(meanVals, (m, 1))
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, meanVals
# 分类算法
def classify0(intX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
# tile():
# 在行方向上重复 intX,dataSetSize 次
# 在列方向上重复 intX,1 次
diffMat = tile(intX, (dataSetSize, 1)) - dataSet
# ** 表示平方
sqDiffMat = diffMat ** 2
# sum(axis=0) 表示每一列相加
# sum(axis=1) 表示每一行相加
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
# argsort():
# 按照数值从小到大,对数字的索引进行排序
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
# {}.get(voteIlabel, 0):
# 查找键值 voteIlabel,如果键值不存在则返回 0
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# key=operator.itemgetter(1)
# 获取对象第 1 个域的值
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 测试分类算法
def datingClassTest():
hoRatio = 0.1
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, meanVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
correctCount = 0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :],
datingLabels[numTestVecs:m], 3)
print('the classifier came back with: %d, the real answer is: %d'
% (classifierResult, datingLabels[i]))
if classifierResult == datingLabels[i]:
correctCount += 1.0
print('the total accuracy is: %f' % (correctCount / float(numTestVecs)))
if __name__ == '__main__':
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
fig = plt.figure()
# add_subplot(321):
# 将画图分割成 3 行 2 列,现在这个在从左到右从上到下第 1 个
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2],
15.0 * array(datingLabels), 15.0 * array(datingLabels))
plt.show()
datingClassTest()
2.3. 手写识别案例
# coding:utf-8
from numpy import *
import operator
from os import listdir
"""
手写识别案例
"""
# 将01文本表示的图像转换为向量
def img2vector(filename):
returnVect = zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
# 分类算法
def classify0(intX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
# tile():
# 在行方向上重复 intX,dataSetSize 次
# 在列方向上重复 intX,1 次
diffMat = tile(intX, (dataSetSize, 1)) - dataSet
# ** 表示平方
sqDiffMat = diffMat ** 2
# sum(axis=0) 表示每一列相加
# sum(axis=1) 表示每一行相加
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
# argsort():
# 按照数值从小到大,对数字的索引进行排序
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
# {}.get(voteIlabel, 0):
# 查找键值 voteIlabel,如果键值不存在则返回 0
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# key=operator.itemgetter(1)
# 获取对象第 1 个域的值
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 测试分类算法
def handwritingClassTest():
hwLabels = []
# 读取目录下文件列表
trainingFileList = listdir('trainingDigits')
m = len(trainingFileList)
trainingMat = zeros((m, 1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i, :] = img2vector('trainingDigits/%s' % (fileNameStr))
testFileList = listdir('testDigits')
correctCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % (fileNameStr))
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print('the classifier came back with: %d, the real answer is: %d'
% (classifierResult, classNumStr))
if classifierResult == classNumStr:
correctCount += 1.0
print('the total accuracy is: %f' % (correctCount / float(mTest)))
if __name__ == '__main__':
handwritingClassTest()
如果这篇文章对你有一点小小的帮助,请给个关注喔~我会非常开心的~