吴恩达机器学习总结(一)线性回归和梯度下降
吴恩达这个机器学习课程是值得像我这样的初窥人工智能领域的同学们来学习的,该课程涉及的数学公式较少,很多结论都是直接呈现在屏幕上了,所以在看视频学习的过程中是很容易理解Ng所讲的内容的。不过课后作业相比于视频就比较的深入了,很多时候需要自己写代码来构造算法。
整体课程大致分为三个部分:监督学习、无监督学习、以及如何优化机器学习系统。其中监督学习包括:线性回归、Logistics回归、神经网络和支持向量机(SVM);无监督学习包括K-Means算法、主成分分析(PCA)等;还有一些优化方法,例如梯度下降、正则化等。
首先,我们先要区分一下什么是监督学习,什么是无监督学习。训练数据中是否有标签,这是二者最根本的区别。监督学习的数据既有特征又有标签,而非监督学习的数据中只有特征而没有标签。监督学习是通过训练让机器自己找到特征和标签之间的联系,从而对只有特征而没有标签的新数据时,可以自我判断出新的数据属于哪个标签。监督学习可以分为两大类:回归和分类,回归和分类的区别在于回归分析针对的是连续型变量,而分类针对的是离散型的数据。非监督学习由于训练数据中只有特征没有标签,所以就需要机器自己对数据进行聚类分析(例如将具有相似特征的数据归为一类,另一些具有相似特征的数据再归为另一类),然后就可以通过聚类的方式从数据中提取一个特殊的结构。
这篇博客里主要总结一下,线性回归和其优化。
一、线性回归
对于线性回归,可以用一个例子来理解。下图是房价的数据集,房屋面积不同,价格不同,图中X为数据点。

而我们可以根据之前的数据,来预测面积和价格的关系,并对某一面积能给出相应的预测值。对于只有一个变量的数据(房价问题的变量只有面积),这种关系在图中所示,就是一条直线。
规范一下这个回归问题:
m m m:训练集中样本的数量
x x x:输入的变量(特征)
y y y:输出变量
( x , y ) (x,y) (x,y):训练集中的实例
( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)):第i个实例
h h h是假设函数,能根据输入x的值,输出y的值,是一个从x到y的函数映射。记这个假设函数的表达式为: h θ ( x ) = θ 0 + θ 1 x h_θ(x)=θ_0+θ_1x hθ(x)=θ0+θ1x
其中的 θ 0 θ_0 θ0, θ 1 θ_1 θ1是假设函数的参数,在房价问题上便是分别是这条直线在y轴上的截距和斜率,参数的选择能反应出直线对训练集的准确程度。因为只包含一个输入变量,因此又叫做单变量线性回归问题。
对于这个假设函数所预测是值与实际值之间的差距,我们称之为建模误差,如下图蓝线所示:
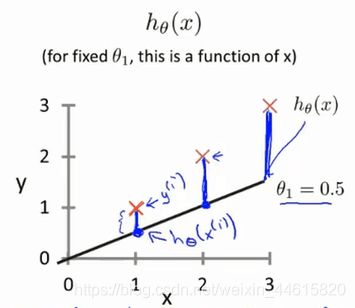
所以为了使得假设函数更加接近实际,我们要使得各数据点的建模误差和最小。蓝线的距离即预测值与真实值的差值,用公式表示为: ∣ ∣ h θ ( x ) − y ( i ) ∣ ∣ ||h_θ(x)-y^{(i)}|| ∣∣hθ(x)−y(i)∣∣。由于数据点是固定的,我们能做的只有调整直线的参数,使得其建模误差最小,对此,我们构造代价函数:
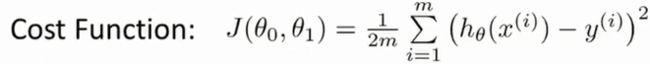
1/2m是为了方便计算,不影响最终结果。
我们的目的就是使得这个代价函数最小: m i n i m i z e J ( θ 0 , θ 1 ) minimize J(θ_0,θ_1) minimizeJ(θ0,θ1)
梯度下降
如何使得代价函数最小,采用了梯度下降的方法。梯度下降是一个用来求函数最小值的方法,不仅可以使用在线性回归中,在其他算法里也有使用,如Logistics回归。
梯度下降的大致流程是:
首先随机地选择一组参数 ( θ 0 , θ 1 ) (θ_0,θ_1) (θ0,θ1),然后计算代价函数 J ( θ 0 , θ 1 ) J(θ_0,θ_1) J(θ0,θ1),在一定的步长条件下,寻找下一个能让代价函数下降最多的参数组合,如此反复,直到代价函数下降到局部最小值(也可能是全局最小值)。步长也称学习率,记作 α α α,就像我们下山迈的步子,步长越大,下山的速度越快;越小,反之。
根据高中的数学知识,函数的极值点的导数为零。
下图是参数θ和代价函数的大致关系图:

对于正导数,正导数x步长还是正数,所以θ会朝着减小的方向进行更新,直到θ的值不变;负导数同理。所以 参数θ的更新规则如下

所以只要求出当前θ下,J(θ)的导数,即可更新θ
在单变量线性回归中,求导后所得结果如下图所示:

需要注意的是, θ 0 , θ 1 θ_0,θ_1 θ0,θ1需要同时更新,直到函数收敛。还有需要注意的是α的取值,若学习率α取的太小,则函数收敛需要的次数将非常多;若α的取值太大,在每次迭代的下降过程中,可能会越过极小值点,而导致无法收敛的问题。通常可以尝试如下学习率:
α = 0.01 , 0.03 , 0.1 , 0.3 , 1 , 3 , 10 α=0.01,0.03,0.1,0.3,1,3,10 α=0.01,0.03,0.1,0.3,1,3,10
多变量线性回归
多变量线性回归和单变量一样,只在变量数上增多,算法的优化过程也和单变量类似。
对于多变量,其假设函数为: h θ ( x ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_θ(x)=θ_0x_0+θ_1x_1+θ_2x_2+...+θ_nx_n hθ(x)=θ0x0+θ1x1+θ2x2+...+θnxn,这里有n+1个参数θ,和n+1个变量,要注意的是 x 0 = 1 x_0=1 x0=1。
我们可以把多项式的假设函数看成向量相乘的形式,即 h θ ( x ) = θ T X = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_θ(x)=θ^TX=θ_0x_0+θ_1x_1+θ_2x_2+...+θ_nx_n hθ(x)=θTX=θ0x0+θ1x1+θ2x2+...+θnxn
代价函数为:
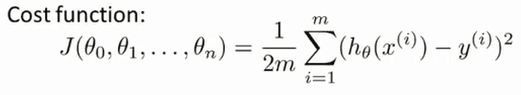
对于多变量线性回归,我们的目标和单变量一样,要找到一组参数θ,使得代价函数最小。
多变量线性回归的批量梯度下降算法为:

同时更新 θ 0 , θ 1 , θ 2 . . . θ n θ_0,θ_1,θ_2...θ_n θ0,θ1,θ2...θn直到函数收敛。
在进行多变量线性回归时要注意,若各个变量之间的值差距较大,例如 1 ≤ x 1 ≤ 10 1≤x_1≤10 1≤x1≤10, 1000 ≤ x 2 ≤ 100000 1000≤x_2≤100000 1000≤x2≤100000, x 3 x_3 x3…,这种情况下需要采取特征缩放来保证所有的特征都出于相同的尺度下,使得函数能更快地收敛,最简单的办法是令 x n = x n − μ n s n x_n=\frac{x_n-μ_n}{s_n} xn=snxn−μn
μ n μ_n μn是平均值, s n s_n sn是标准差(max-min)
正规方程
对于某些线性回归函数来说,除了梯度下降法来选择参数外,还可以使用正规方程来找出向量θ
假设训练集的特征矩阵为X,输出值为向量y,利用正规方程就可以一步到位地得到向量θ: θ = ( X T X ) − 1 X T y θ=(X^TX)^{-1}X^Ty θ=(XTX)−1XTy
若训练集的特征小于10000,正规方程的计算了还是可以接受的,若n>10000,这时用梯度下降也可以很好地适用。