爬虫神器----Scrapy
“ Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。”
01—srcapy架构
Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。 尽管Scrapy原本是设计用来屏幕抓取(更精确的说,是网络抓取),但它也可以用来访问API来提取数据。
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
02—如何构造一个爬虫
老样子,我们还是用IDE Pycharm来实现一个爬虫,大概分为以下几个步骤:
1、python 安装scrapy,因为我使用的interpreter是anaconda3的库,所以我这边在Anaconda Prompt输入pip install scrapy

2、新建一个目录,比如在D盘新建目录mySpider,然后在pycharm的terminal命令行界面输入scrapy startscrapy wulianquanzhan

3、然后进入到相应的目录可以看到已经创建了一个工程wulianquanzhan,通过Pycharm导入整个工程就可以开始用IDE来进行爬虫构建了
4、terminal命令行界面输入scrapy genspider scrapyname example.com,
03—某小说网站小说爬取实例
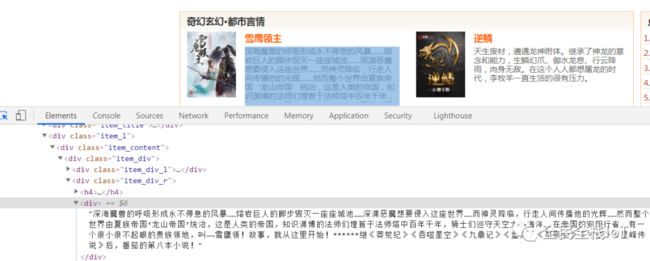
这里我们演示爬取一个小说网站的小说内容。小说网站qxs.la,所以我们terminal命令行界面输入scrapy genspider qxs qxs.la,在工程目录spiders中会出现一个qxs.py的文件内容如下所示:
class QxsSpider(scrapy.Spider):
name = 'qxs'
allowed_domains = ['qxs.la']
start_urls = ['http://qxs.la/']
def parse(self, response):
pass
接下来我们需要完善这里面的内容,需要根据网站的实际情况进行数据提取,主要是通过浏览器检查功能,查找小说内容所在,当然小说内容是比较分散的,需要分类去爬取,所有的小说具体内容都需要翻页跳转来进行爬取
class QxsSpider(scrapy.Spider):
name = 'qxs'
allowed_domains = ['qxs.la']
start_urls = ['http://qxs.la/']
def parse(self, response):
item = {}
url_list_r = response.xpath("//div[@class='item_div_r']")
url_list_ul = response.xpath("//div[@class='item_content']//ul")
for url in url_list_r:
item['novel_name'] = url.xpath('.//h4//a//text()').extract_first()
item['novel_url'] = url.xpath('.//h4//a//@href').extract_first()
next_url = "https://qxs.la"+item['novel_url']
yield scrapy.Request(next_url, callback=self.parse_content_url, meta={"item": deepcopy(item)})
for url in url_list_ul:
item['novel_name'] = url.xpath('.//li//a//text()').extract_first()
item['novel_url'] = url.xpath('.//li//a//@href').extract_first()
next_url = "https://qxs.la" + item['novel_url']
yield scrapy.Request(next_url, callback=self.parse_content_url, meta={"item": deepcopy(item)})
def parse_content_url(self,response):
url_list = response.xpath("//div[@class='chapter']")
item = response.meta['item']
for url in url_list:
response.meta['item']['novel_chapter_url'] = url.xpath('.//a//@href').extract_first()
response.meta['item']['novel_chapter_name'] = url.xpath('.//a//text()').extract_first()
if response.meta['item']['novel_chapter_url']:
next_url = "https://qxs.la" + response.meta['item']['novel_chapter_url']
response.meta['item']['complete_url'] = next_url
yield scrapy.Request(next_url, callback=self.parse_content, meta={"item": deepcopy(item)})
# yield response.meta['item']
def parse_content(self,response):
content = response.xpath("//div[@id='content']//text()")[7:-7].extract()
for con in content:
response.meta['item']['content'] = con.replace(u'\u3000',u'').strip()
yield response.meta['item']
有兴趣的同学可以打开网页去实际去研究下,基本都是用xpath来提取内容,分两步走:
1、提取小说目录的url_list
2、根据每部小说的url进行跳转,在对应的网页检查中找出每一部小说的章节内容进行提取url
3、根据每一部小说的每一个章节的内容进行xpath内容提取
4、章节内容保存,scrapy有个item pipline的功能,只需要在将章节内容传递到这个pipline中,然后在pipline进行内容的保存
class MyspiderPipeline:
def process_item(self, item, spider):
if spider.name == 'qxs':
logger.warning(item)
novel_folder_path = os.path.join(novel_folder_base,item['novel_name'])
if not os.path.exists(novel_folder_path):
os.makedirs(novel_folder_path)
file_path = os.path.join(novel_folder_path,item['novel_chapter_name'])
if 'content' in item.keys():
with open(file_path+".txt","a") as f:
f.write(str(item['content'])+'\n')
return item
有两个配置的问题需要注意:
1、在settings文件中配置好piplines,不然item_pipeline功能无法使用
ITEM_PIPELINES = {
'mySpider.pipelines.MyspiderPipeline': 300,
}
2、修改User-Agent为一个正常的值
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.87 Safari/537.36 Edg/88.0.705.45'
04—Scrapy Redis的使用
大家在初入Scrapy进行内容爬取的时候,如果爬取的内容很多,可能短时间爬不完,有可能电脑就中断了,或者想把爬虫分布在不同的IP上来躲避反爬虫。这个时候用redis来进行断点续爬就是一个很好的方法了,在scrapy框架中使用redis也是非常的方便,在需在settings文件中配置如下即可:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
REDIS_URL = "redis://127.0.0.1:6379"
当然piplines也是需要配置的
ITEM_PIPELINES = {
'mySpider.pipelines.MyspiderPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
配置好后,就可以在terminal输入scrapy crawl qxs是内容爬取了,ctl+c打断,重新爬取的时候也是从断开的url开始爬取。
喜欢的朋友可以关注公众号,更多好文不定时更新
