多元线性回归——加利福尼亚房屋预测
- 导入需要的模块和库
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
from sklearn import linear_model #导入线性模型模块
model=linear_model.LinearRegression() #创建线性回归模型
from sklearn.datasets import fetch_california_housing as fch #加利福尼亚房屋价值数据集
from sklearn.model_selection import train_test_split #用于划分训练测试集数目
2.实例化
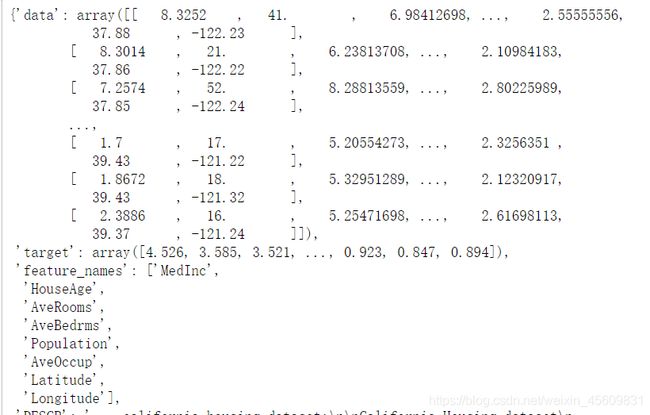
housevalue =fch() #实例化 会需要下载,大家可以提前运行试试看
housevalue
结果:
3.导入数据,探索数据
x=pd.DataFrame(housevalue.data) #放入DataFrame中便于查看
y=housevalue.target
4.给x加列名
x.columns=housevalue.feature_names #加列名
x

5.区分 测试和训练的数据
#区分 测试和训练的数据(随机)
#x_train,x_test,y_train,y_test 顺序不能变
#x(特征), y(标签), test_size=0.3测试集所占的比例(0.2、0.3), random_state=420(不是必须的,这是固定随机出来的数,伪随机)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=420)
6.恢复索引
for i in [x_train,x_test]:
i.index=range(i.shape[0])
7.数据标准化
x_train=(x_train -x_train.mean())/x_train.std()
x_test=(x_test - x_test.mean())/x_test.std()
x_test
8.建模
#拟合
model.fit(x_train,y_train)
#预测
y_hat=model.predict(x_test) #预测的x的测试结果
y_hat
9.探索建好的模型
model.coef_ #斜率

[*zip(x_train.columns,model.coef_)] #将系数与对应名称组合起来

'''
MedInc:该街区住户的收入中位数
HouseAge:该街区房屋使用年代的中位数
AveRooms:该街区平局的房间数目
AveBedrms:该街区平局卧室数目
Population:该街区人口数
AveOccup:平均入住率
Latitude:街区的纬度
Longitude:街区的经度
'''
回归模型的评估
MSE
#MSE用来检测模型的预测值和真实值之间的偏差,值越大,表明预测效果越差
from sklearn.metrics import mean_squared_error as MSE #均方误差
MSE(y_hat,y_test) #y_hat对x_test的预测
R2
from sklearn.metrics import r2_score #r2_score表示的是在总变变量中模式解释的百分比
r2_score(y_test,y_hat) #回归的决定系数
r2=model.score(x_test,y_test)
r2 # r2 越接近于1,表示回归的效果越好
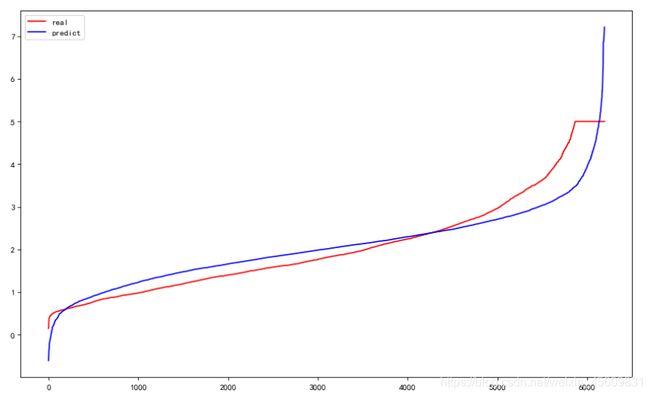
plt.figure(figsize=(13,8),dpi=80)
plt.plot(range(len(y_test)),sorted(y_test),c="red",label="real")
plt.plot(range(len(y_hat)),sorted(y_hat),c="blue",label="predict")
plt.legend()
plt.show()