数据可视化方向的毕业设计——基于Python爬虫的招聘信息及租房数据可视化分析系统
距离我本科答辩顺利通过已经过去十几天了,我决定把本科阶段最后的小成果做个总结分享给想做此方向项目的小伙伴们,希望能让你们想在动手实操时有项目可供参考,有实现思路可供学习,演示视频先呈现给大家。
一、研究目的及意义
(一)现状
- 应届毕业生关注重点难点:找工作+租房子
- 招聘网站繁杂:拉勾网、BOSS直聘、前程无忧等
- 各个大学的就业信息网站成熟
- 租房网站众多:链家网、我爱我家等
(二)缺点
- 仅提供信息,功能单一
- 信息分散,无法了解整体情况
- 文字、数字形式不直观
- 招聘与租房无关联
(三)改进
- 整合信息、统计数据
- 分区域数据可视化
- 丰富的图表呈现
- 集招聘租房于一体
因此,当下迫切需要一个能够把尽可能多的信息整合到一起的平台,且该平台需要具备强大的统计数据及数据可视化的功能,这样,用户就可以通过该平台来检索招聘信息及房源信息,并且可以通过图表可视化了解整体情况。对于每年日益增多的就业大军而言,可以从该系统中清楚了解到目前在一线城市、新一线城市、二线城市的互联网各行业及租房现状,有助于做出适合自身情况的选择。
二、实现思路与相关技术
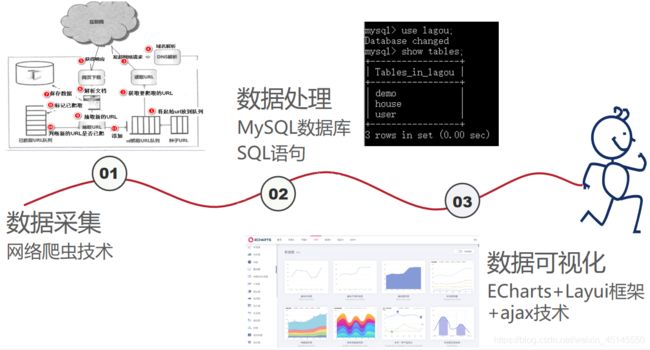
前后端数据交互的实现——ajax技术
通过ajax传递参数,它是用户和服务器之间的一个中间层,使得用户操作和服务器响应异步化,前端将需要传递的参数转化为JSON字符串(json.stringify)再通过get/post方式向服务器发送一个请求并将参数直接传递给后台,后台对前端请求作出反应,接收数据,将数据作为条件进行查询,返回json字符串格式的查询结果集给前端,前端接收到后台返回的数据进行条件判断并做出相应的页面展示。
get/post请求方式的区别
都是向服务器提交数据,都能从服务器获取数据。Get方式的请求,浏览器会把响应头和数据体一并发送出去,服务器响应200表示请求已成功,返回数据。Post方式的请求,浏览器会先发送响应头,服务器响应100后,浏览器再发送数据体,服务器响应200,请求成功,返回数据。Post方式安全性更好。
什么时候用get,什么时候用post请求方式?
登录注册、修改信息部分都使用post方式,数据概况展示、可视化展示部分都使用get方式。也就是数据查询用get方式,数据增加、删除、修改用post方式更加安全。
数据可视化图表展示——ECharts图表库(包含所有想要的图表生成代码,可支持在线调试代码,图表大气美观,此网站真的绝绝子,分享给大家)
网站:ECharts开源可视化图表库
三、系统整体功能框架
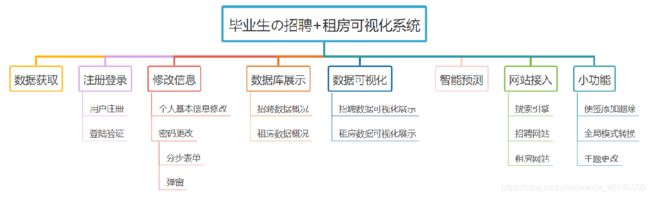
四、详细实现
(一)数据获取
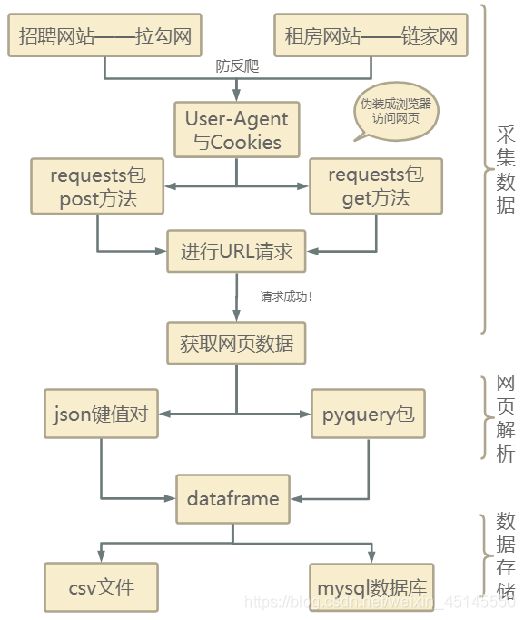
1、获取招聘信息
因为拉勾网具有较强的反爬机制,使用user-agent和cookies封装头部信息,将爬虫程序伪装成浏览器访问网页,通过requests包的post方法进行url请求,请求成功返回json格式字符串,并使用字典方法直接读取数据,即可拿到我们想要的python职位相关的信息,可以通过读取总职位数,通过总的职位数和每页能显示的职位数.我们可以计算出总共有多少页,然后使用循环按页爬取, 最后将职位信息汇总, 写入到CSV格式的文件以及本地mysql数据库中。
import requests
import math
import time
import pandas as pd
import pymysql
from sqlalchemy import create_engine
def get_json(url, num):
"""
从指定的url中通过requests请求携带请求头和请求体获取网页中的信息,
:return:
"""
url1 = 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest',
'Cookie':'user_trace_token=20210218203227-35e936a1-f40f-410d-8400-b87f9fb4be0f; _ga=GA1.2.331665492.1613651550; LGUID=20210218203230-39948353-de3f-4545-aa01-43d147708c69; LG_HAS_LOGIN=1; hasDeliver=0; privacyPolicyPopup=false; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; RECOMMEND_TIP=true; index_location_city=%E5%85%A8%E5%9B%BD; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1613651550,1613652253,1613806244,1614497914; _putrc=52ABCFBE36E5D0BD123F89F2B170EADC; gate_login_token=ea312e017beac7fe72547a32956420b07d6d5b1816bc766035dd0f325ba92b91; JSESSIONID=ABAAAECAAEBABII8D8278DB16CB050FD656DD1816247B43; login=true; unick=%E7%94%A8%E6%88%B72933; WEBTJ-ID=20210228%E4%B8%8B%E5%8D%883:38:37153837-177e7932b7f618-05a12d1b3d5e8c-53e356a-1296000-177e7932b8071; sensorsdata2015session=%7B%7D; _gid=GA1.2.1359196614.1614497918; __lg_stoken__=bb184dd5d959320e9e61d943e802ac98a8538d44699751621e807e93fe0ffea4c1a57e923c71c93a13c90e5abda7a51873c2e488a4b9d76e67e0533fe9e14020734016c0dcf2; X_MIDDLE_TOKEN=90b85c3630b92280c3ad7a96c881482e; LGSID=20210228161834-659d6267-94a3-4a5c-9857-aaea0d5ae2ed; TG-TRACK-CODE=index_navigation; SEARCH_ID=092c1fd19be24d7cafb501684c482047; X_HTTP_TOKEN=fdb10b04b25b767756070541617f658231fd72d78b; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2220600756%22%2C%22first_id%22%3A%22177b521c02a552-08c4a0f886d188-73e356b-1296000-177b521c02b467%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24os%22%3A%22Linux%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2288.0.4324.190%22%2C%22lagou_company_id%22%3A%22%22%7D%2C%22%24device_id%22%3A%22177b521c02a552-08c4a0f886d188-73e356b-1296000-177b521c02b467%22%7D; _gat=1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1614507066; LGRID=20210228181106-f2d71d85-74fe-4b43-b87e-d78a33c872ad'
}
data = {
'first': 'true',
'pn': num,
'kd': 'BI工程师'}
#得到Cookies信息
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
#添加请求参数以及headers、Cookies等信息进行url请求
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '\n\n')
return page_data
def get_page_num(count):
"""
计算要抓取的页数,通过在拉勾网输入关键字信息,可以发现最多显示30页信息,每页最多显示15个职位信息
:return:
"""
page_num = math.ceil(count / 15)
if page_num > 29:
return 29
else:
return page_num
def get_page_info(jobs_list):
"""
获取职位
:param jobs_list:
:return:
"""
page_info_list = []
for i in jobs_list: # 循环每一页所有职位信息
job_info = []
job_info.append(i['companyFullName'])
job_info.append(i['companyShortName'])
job_info.append(i['companySize'])
job_info.append(i['financeStage'])
job_info.append(i['district'])
job_info.append(i['positionName'])
job_info.append(i['workYear'])
job_info.append(i['education'])
job_info.append(i['salary'])
job_info.append(i['positionAdvantage'])
job_info.append(i['industryField'])
job_info.append(i['firstType'])
job_info.append(",".join(i['companyLabelList']))
job_info.append(i['secondType'])
job_info.append(i['city'])
page_info_list.append(job_info)
return page_info_list
def unique(old_list):
newList = []
for x in old_list:
if x not in newList :
newList.append(x)
return newList
def main():
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format("root", "123456", "localhost", "3366",
"lagou")
engine = create_engine(connect_info)
url = ' https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
first_page = get_json(url, 1)
total_page_count = first_page['content']['positionResult']['totalCount']
num = get_page_num(total_page_count)
total_info = []
time.sleep(10)
for num in range(1, num + 1):
# 获取每一页的职位相关的信息
page_data = get_json(url, num) # 获取响应json
jobs_list = page_data['content']['positionResult']['result'] # 获取每页的所有python相关的职位信息
page_info = get_page_info(jobs_list)
total_info += page_info
print('已经爬取到第{}页,职位总数为{}'.format(num, len(total_info)))
time.sleep(20)
#将总数据转化为data frame再输出,然后在写入到csv格式的文件中以及本地数据库中
df = pd.DataFrame(data=unique(total_info),
columns=['companyFullName', 'companyShortName', 'companySize', 'financeStage',
'district', 'positionName', 'workYear', 'education',
'salary', 'positionAdvantage', 'industryField',
'firstType', 'companyLabelList', 'secondType', 'city'])
df.to_csv('bi.csv', index=True)
print('职位信息已保存本地')
df.to_sql(name='demo', con=engine, if_exists='append', index=False)
print('职位信息已保存数据库')
if __name__ == '__main__':
main()
2、获取租房房源信息
使用user-agent和cookies封装头部信息将爬虫程序伪装成浏览器访问网页,通过requests包的get方法进行url请求获取网页数据,将经过pyquery包解析后网页数据按字段添加到dataframe中,再将dataframe存入csv文件及本地数据库中。
import requests
from pyquery import PyQuery as pq
from fake_useragent import UserAgent
import time
import pandas as pd
import random
import pymysql
from sqlalchemy import create_engine
UA = UserAgent()
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cookie': 'lianjia_uuid=6383a9ce-19b9-47af-82fb-e8ec386eb872; UM_distinctid=1777521dc541e1-09601796872657-53e3566-13c680-1777521dc5547a; _smt_uid=601dfc61.4fcfbc4b; _ga=GA1.2.894053512.1612577894; _jzqc=1; _jzqckmp=1; _gid=GA1.2.1480435812.1614959594; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1614049202,1614959743; csrfSecret=lqKM3_19PiKkYOfJSv6ldr_c; activity_ke_com=undefined; ljisid=6383a9ce-19b9-47af-82fb-e8ec386eb872; select_nation=1; crosSdkDT2019DeviceId=-kkiavn-2dq4ie-j9ekagryvmo7rd3-qjvjm0hxo; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1615004691; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221777521e37421a-0e1d8d530671de-53e3566-1296000-1777521e375321%22%2C%22%24device_id%22%3A%221777521e37421a-0e1d8d530671de-53e3566-1296000-1777521e375321%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_utm_source%22%3A%22guanwang%22%2C%22%24latest_utm_medium%22%3A%22pinzhuan%22%2C%22%24latest_utm_campaign%22%3A%22wybeijing%22%2C%22%24latest_utm_content%22%3A%22biaotimiaoshu%22%2C%22%24latest_utm_term%22%3A%22biaoti%22%7D%7D; lianjia_ssid=7a179929-0f9a-40a4-9537-d1ddc5164864; _jzqa=1.3310829580005876700.1612577889.1615003848.1615013370.6; _jzqy=1.1612577889.1615013370.2.jzqsr=baidu|jzqct=%E9%93%BE%E5%AE%B6.jzqsr=baidu; select_city=440300; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiZjdiNTI1Yjk4YjI3MGNhNjRjMGMzOWZkNDc4NjE4MWJkZjVjNTZiMWYxYTM4ZTJkNzMxN2I0Njc1MDEyY2FiOWMzNTIzZTE1ZjEyZTE3NjlkNTRkMTA2MWExZmIzMWM5YzQ3ZmQxM2M3NTM5YTQ1YzM5OWU0N2IyMmFjM2ZhZmExOGU3ZTc1YWU0NDQ4NTdjY2RiMjEwNTQyMDQzM2JiM2UxZDQwZWQwNzZjMWQ4OTRlMGRkNzdmYjExZDQwZTExNTg5NTFkODIxNWQzMzdmZTA4YmYyOTFhNWQ2OWQ1OWM4ZmFlNjc0OTQzYjA3NDBjNjNlNDYyNTZiOWNhZmM4ZDZlMDdhNzdlMTY1NmM0ZmM4ZGI4ZGNlZjg2OTE2MmU4M2MwYThhNTljMGNkODYxYjliNGYwNGM0NzJhNGM3MmVmZDUwMTJmNmEwZWMwZjBhMzBjNWE2OWFjNzEzMzM4M1wiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJhYWEyMjhiNVwifSIsInIiOiJodHRwczovL20ubGlhbmppYS5jb20vY2h1enUvc3ovenVmYW5nL3BnJTdCJTdELyIsIm9zIjoid2ViIiwidiI6IjAuMSJ9',
'Host': 'sz.lianjia.com',
'Referer': 'https://sz.lianjia.com/zufang/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36',
}
num_page = 2
class Lianjia_Crawer:
def __init__(self, txt_path):
super(Lianjia_Crawer, self).__init__()
self.file = str(txt_path)
self.df = pd.DataFrame(columns = ['title', 'district', 'area', 'orient', 'floor', 'price', 'city'])
def run(self):
'''启动脚本'''
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format("root", "123456", "localhost", "3366", "lagou")
engine = create_engine(connect_info)
for i in range(100):
url = "https://sz.lianjia.com/zufang/pg{}/".format(str(i))
self.parse_url(url)
time.sleep(random.randint(2, 5))
print('正在爬取的 url 为 {}'.format(url))
print('爬取完毕!!!!!!!!!!!!!!')
self.df.to_csv(self.file, encoding='utf-8')
print('租房信息已保存至本地')
self.df.to_sql(name='house', con=engine, if_exists='append', index=False)
print('租房信息已保存数据库')
def parse_url(self, url):
headers['User-Agent'] = UA.chrome
res = requests.get(url, headers=headers)
#声明pq对象
doc = pq(res.text)
for i in doc('.content__list--item .content__list--item--main'):
try:
pq_i = pq(i)
# 房屋标题
title = pq_i('.content__list--item--title a').text()
# 具体信息
houseinfo = pq_i('.content__list--item--des').text()
# 行政区
address = str(houseinfo).split('/')[0]
district = str(address).split('-')[0]
# 房屋面积
full_area = str(houseinfo).split('/')[1]
area = str(full_area)[:-1]
# 朝向
orient = str(houseinfo).split('/')[2]
# 楼层
floor = str(houseinfo).split('/')[-1]
# 价格
price = pq_i('.content__list--item-price').text()
#城市
city = '深圳'
data_dict = {
'title': title, 'district': district, 'area': area, 'orient': orient, 'floor': floor, 'price': price, 'city': city}
self.df = self.df.append(data_dict, ignore_index=True)
print([title, district, area, orient, floor, price, city])
except Exception as e:
print(e)
print("索引提取失败,请重试!!!!!!!!!!!!!")
if __name__ =="__main__":
txt_path = "zufang_shenzhen.csv"
Crawer = Lianjia_Crawer(txt_path)
Crawer.run() # 启动爬虫脚本
(二)数据库
需要创建三张数据库表分别用来存储招聘信息、房源信息、和用户信息。
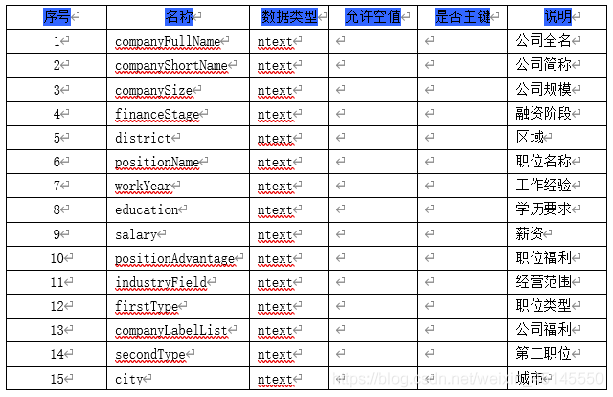
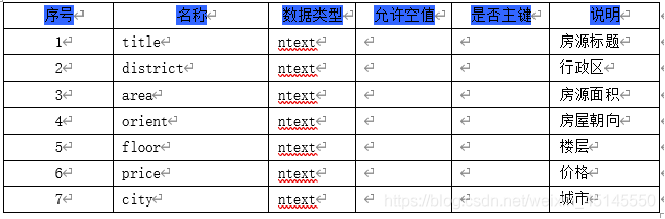
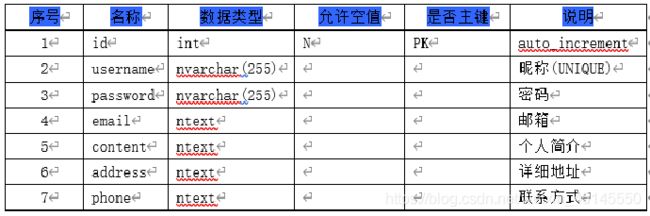
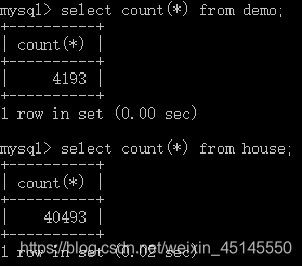
将爬取到的数据存入csv文件以及本地mysql数据库中,部分数据展示如下图所示:


数据库与后台进行连接
使用pymysql连接本地mysql数据库,首先通过pip安装pymysql并创建好数据库以及数据库表,导入pymysql包,打开数据库连接,使用cursor()方法创建一个游标对象,使用execute()方法执行SQL查询。
(三)注册登录
注册登录流程:

实现代码(后端响应):
#注册用户
@app.route('/addUser',methods=['POST'])
def addUser():
#服务器端获取json
get_json = request.get_json()
name = get_json['name']
password = get_json['password']
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("select count(*) from `user` where `username` = '" + name + "'")
count = cursor.fetchall()
#该昵称已存在
if (count[0][0]!= 0):
table_result = {
"code": 500, "msg": "该昵称已存在!"}
cursor.close()
else:
add = conn.cursor()
sql = "insert into `user`(username,password) values('"+name+"','"+password+"');"
add.execute(sql)
conn.commit()
table_result = {
"code": 200, "msg": "注册成功"}
add.close()
conn.close()
return jsonify(table_result)
#用户登录
@app.route('/loginByPassword',methods=['POST'])
def loginByPassword():
get_json = request.get_json()
name = get_json['name']
password = get_json['password']
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("select count(*) from `user` where `username` = '" + name +"' and password = '" + password+"';")
count = cursor.fetchall()
if(count[0][0] != 0):
table_result = {
"code": 200, "msg": name}
cursor.close()
else:
name_cursor = conn.cursor()
name_cursor.execute("select count(*) from `user` where `username` = '" + name +"';")
name_count = name_cursor.fetchall()
#print(name_count)
if(name_count[0][0] != 0):
table_result = {
"code":500, "msg": "密码错误!"}
else:
table_result = {
"code":500, "msg":"该用户不存在,请先注册!"}
name_cursor.close()
conn.close()
print(name)
return jsonify(table_result)
(四)首页功能
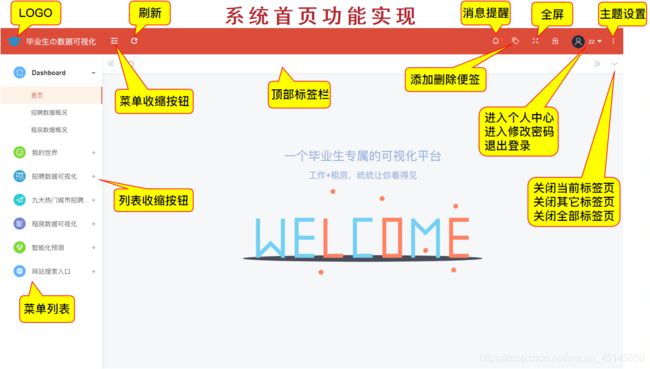
(五)修改个人信息
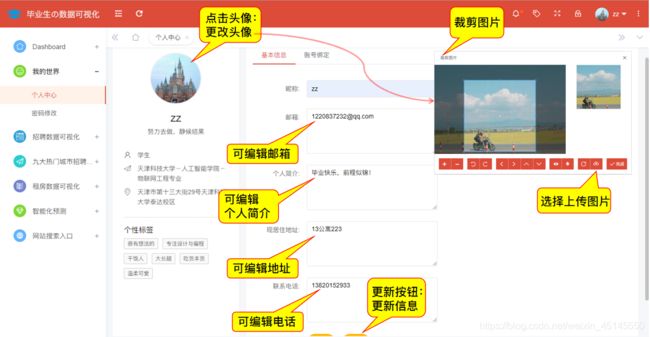
#个人信息修改
@app.route('/updateUserInfo',methods=['POST'])
def updateUserInfo():
get_json = request.get_json()
name = get_json['name']
print(name)
email = get_json['email']
content = get_json['content']
address = get_json['address']
phone = get_json['phone']
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("update `user` set email = '"+email+"',content = '"+content+"',address = '"+address+"',phone = '"+phone+"' where username = '"+ name +"';")
conn.commit()
table_result = {
"code": 200, "msg": "更新成功!","youxiang": email, "tel": phone}
cursor.close()
conn.close()
print(table_result)
return jsonify(table_result)
(六)修改密码
可以通过两种方式修改密码,均需要进行安全验证
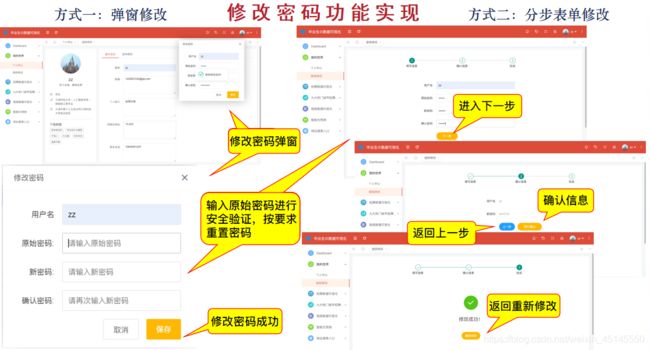
#密码修改
@app.route('/updatePass',methods=['POST'])
def updatePass():
get_json = request.get_json()
name = get_json['name']
oldPsw = get_json['oldPsw']
newPsw = get_json['newPsw']
rePsw = get_json['rePsw']
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("select count(*) from `user` where `username` = '" + name + "' and password = '" + oldPsw+"';")
count = cursor.fetchall()
print(count[0][0])
#确定昵称密码对应
if (count[0][0] == 0):
table_result = {
"code": 500, "msg": "原始密码错误!"}
cursor.close()
else:
updatepass = conn.cursor()
sql = "update `user` set password = '"+newPsw+"' where username = '"+ name +"';"
updatepass.execute(sql)
conn.commit()
table_result = {
"code": 200, "msg": "密码修改成功!", "username": name, "new_password": newPsw}
updatepass.close()
conn.close()
return jsonify(table_result)
(七)数据概况展示
注:仅研究互联网岗位招聘信息
以招聘数据概况为例:
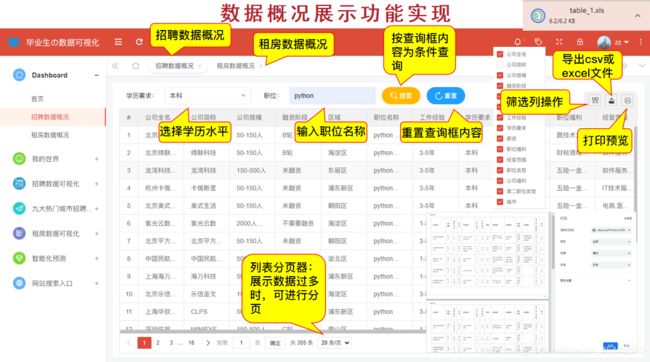
@app.route('/data',methods=['GET'])
def data():
limit = int(request.args['limit'])
page = int(request.args['page'])
page = (page-1)*limit
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',charset='utf8mb4')
cursor = conn.cursor()
if (len(request.args) == 2):
cursor.execute("select count(*) from demo")
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from demo limit "+str(page)+","+str(limit))
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
else:
education = str(request.args['education'])
positionName = str(request.args['positionName']).lower()
if(education=='不限'):
cursor.execute("select count(*) from demo where positionName like '%"+positionName+"%'")
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from demo where positionName like '%"+positionName+"%' limit " + str(page) + "," + str(limit))
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
else:
cursor.execute("select count(*) from demo where positionName like '%"+positionName+"%' and education = '"+education+"'")
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from demo where positionName like '%"+positionName+"%' and education = '"+education+"' limit " + str(page) + "," + str(limit))
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
table_result = {
"code": 0, "msg": None, "count": count[0], "data": data_dict}
cursor.close()
conn.close()
return jsonify(table_result)
(八)招聘数据可视化
从全国、一线城市、新一线城市、二线城市四个角度分区域分析。
举个栗子,全国范围内的企业情况分析如下图所示:
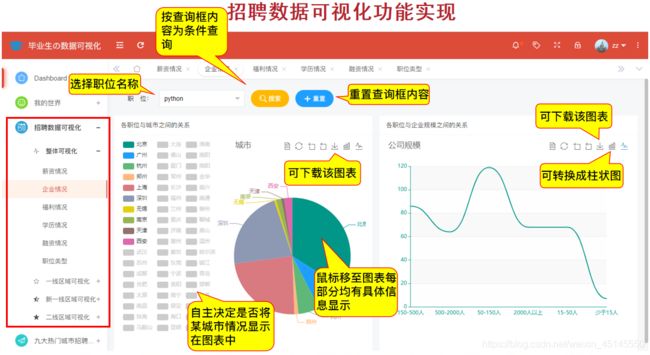
@app.route('/qiye',methods=['GET'])
def qiye():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(city) from demo")
result = cursor.fetchall()
city = []
city_result = []
companySize = []
companySizeResult = []
selected = {
}
# 获取到的城市
for field in result:
city.append(field[0])
if (len(request.args) == 0):
# 没有查询条件
# 获取到城市对应的个数
for i in city:
cursor.execute("SELECT count(*) from demo where city = '" + i + "'")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': i}
city_result.append(dict)
# 初始化最开始显示几个城市
for i in city[10:]:
selected[i] = False
# 获取到几种公司规模
cursor.execute("SELECT DISTINCT(companySize) from demo")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
# 每种公司规模对应的个数
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "'")
count = cursor.fetchall()
companySizeResult.append(count[0][0])
else:
positionName = str(request.args['positionName']).lower()
# 查询条件:某种职业
# 每个城市某种职业的个数
for i in city:
cursor.execute("SELECT count(*) from demo where city = '" + i + "' and positionName like '%"+positionName+"%'")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': i}
city_result.append(dict)
for i in city[10:]:
selected[i] = False
cursor.execute("SELECT DISTINCT(companySize) from demo")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and positionName like '%"+positionName+"%'")
count = cursor.fetchall()
companySizeResult.append(count[0][0])
result = {
"city": city, "city_result": city_result, "selected": selected, "companySize": companySize, "companySizeResult": companySizeResult}
cursor.close()
return jsonify(result)
一线城市的企业情况分析如下图所示:
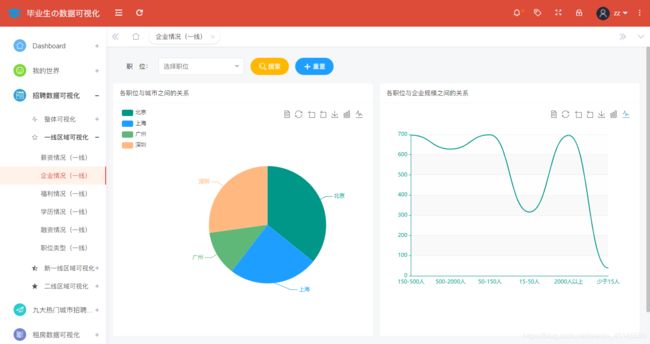
@app.route('/qiye_first',methods=['GET'])
def qiye_first():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
#cursor.execute("SELECT DISTINCT(city) from demo")
#result = cursor.fetchall()
city = ['北京', '上海', '广州', '深圳']
city_result = []
companySize = []
companySizeResult = []
selected = {
}
# 获取到的城市
#for field in result:
#city.append(field[0])
if (len(request.args) == 0):
# 没有查询条件
# 获取到城市对应的个数
for i in city:
cursor.execute("SELECT count(*) from demo where city = '" + i + "'")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': i}
city_result.append(dict)
# 初始化最开始显示几个城市
for i in city[4:]:
selected[i] = False
# 获取到几种公司规模
cursor.execute("SELECT DISTINCT(companySize) from demo where city in ('北京', '上海', '广州', '深圳');")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
# 每种公司规模对应的个数
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and city in ('北京', '上海', '广州', '深圳');")
count = cursor.fetchall()
companySizeResult.append(count[0][0])
else:
positionName = str(request.args['positionName']).lower()
# 查询条件:某种职业
# 每个城市某种职业的个数
for i in city:
cursor.execute("SELECT count(*) from demo where city = '" + i + "' and positionName like '%"+positionName+"%'")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': i}
city_result.append(dict)
for i in city[4:]:
selected[i] = False
cursor.execute("SELECT DISTINCT(companySize) from demo where city in ('北京', '上海', '广州', '深圳');")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and positionName like '%"+positionName+"%' and city in ('北京', '上海', '广州', '深圳');")
count = cursor.fetchall()
companySizeResult.append(count[0][0])
result = {
"city": city, "city_result": city_result, "selected": selected, "companySize": companySize, "companySizeResult": companySizeResult}
cursor.close()
return jsonify(result)
全国本科学历薪资情况分析展示如图所示:
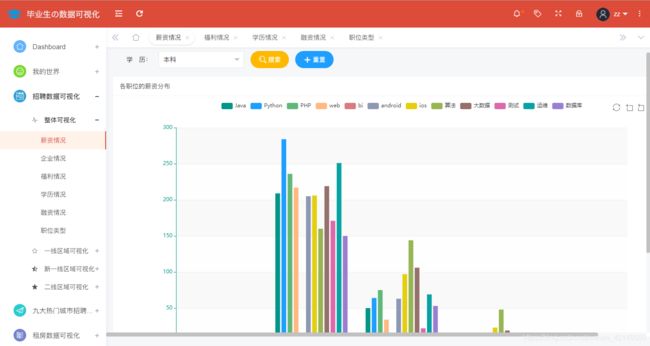
@app.route('/xinzi',methods=['GET'])
def xinzi():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
positionName = ['java', 'python', 'php', 'web', 'bi', 'android', 'ios', '算法', '大数据', '测试', '运维', '数据库']
#柱状图返回列表
zzt_list = []
zzt_list.append(['product', 'Java', 'Python', 'PHP', 'web', 'bi', 'android', 'ios', '算法', '大数据', '测试', '运维', '数据库'])
if (len(request.args) == 0 or str(request.args['education'])=='不限'):
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) like '%K%' and positionName like '%"+i+"%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['0—10K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 10 AND 20 and positionName like '%"+i+"%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['10—20K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 20 AND 30 and positionName like '%"+i+"%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['20—30K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 30 AND 40 and positionName like '%" + i + "%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['30—40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) > 40 and positionName like '%" + i + "%';")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['40以上', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
else:
education = str(request.args['education'])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) like '%K%' and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['0—10K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 10 AND 20 and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['10—20K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 20 AND 30 and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['20—30K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 30 AND 40 and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['30—40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute(
"SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) > 40 and positionName like '%" + i + "%' and education = '"+education+"'")
count = cursor.fetchall()
temp_list += count[0]
zzt_list.append(['40以上', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5], temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
result = {
"zzt": zzt_list}
cursor.close()
return jsonify(result)
全国福利情况分析展示如图所示:
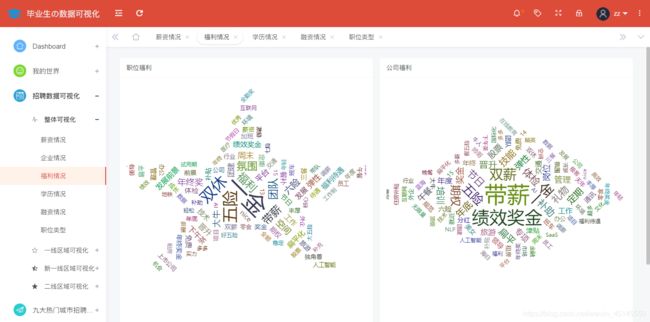
@app.route('/fuli',methods=['GET'])
def fuli():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select positionAdvantage from `demo`")
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['positionAdvantage'])
content = ''.join(data_dict)
positionAdvantage = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {
}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
positionAdvantage.append(mydict)
cursor.execute("select companyLabelList from `demo`")
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['companyLabelList'])
content = ''.join(data_dict)
companyLabelList = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {
}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
companyLabelList.append(mydict)
cursor.close()
return jsonify({
"zwfl": positionAdvantage, "gsfl": companyLabelList})
全国互联网岗位学历与工作经验要求情况分析展示如图所示:
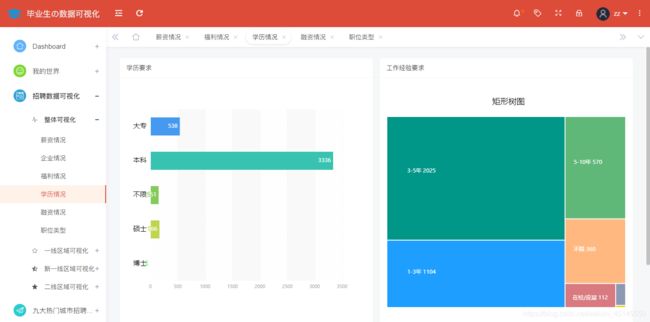
@app.route('/xueli',methods=['GET'])
def xueli():
#打开数据库连接
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
#创建一个游标对象cursor
cursor = conn.cursor()
#执行sql语句
cursor.execute("SELECT DISTINCT(education) from demo")
#获取所有记录列表
result = cursor.fetchall()
education = []
education_data = []
color_list = ['#459AF0', '#38C3B0', '#86CA5A', '#BFD44F', ' #90EE90']
#获取到学历的五种情况:不限、大专、本科、硕士、博士
for field in result:
education.append(field[0])
#获取到每种学历对应的个数
for i in range(len(education)):
cursor.execute("SELECT count(*) from demo where education = '" + education[i] + "'")
count = cursor.fetchall()
education_data.append({
'value': count[0][0], 'itemStyle': {
'color': color_list[i]}})
cursor.execute("SELECT DISTINCT(workYear) from demo")
result = cursor.fetchall()
workYear = []
workYear_data = []
#获取到的几种工作经验
for field in result:
workYear.append(field[0])
#获取到每种工作经验对应的个数
for i in workYear:
cursor.execute("SELECT count(*) from demo where workYear = '" + i + "'")
count = cursor.fetchall()
workYear_data.append({
'value': count[0][0], 'name': i})
cursor.close()
return jsonify({
"education":education, "education_data":education_data, "workYear_data":workYear_data})
全国互联网公司融资阶段分布情况分析如图所示:
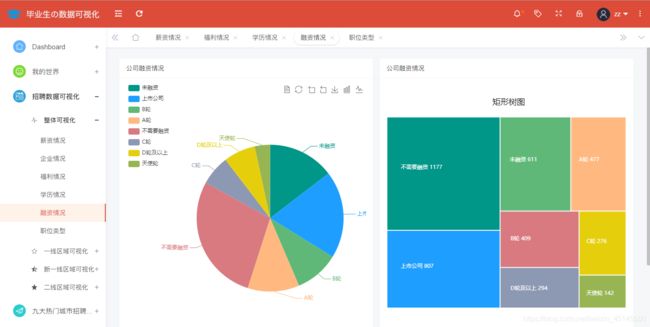
@app.route('/rongzi',methods=['GET'])
def rongzi():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(financeStage) from demo")
result = cursor.fetchall()
finance = []
finance_data = []
# 获取到融资的几种情况
for field in result:
finance.append(field[0])
# 获取到每种融资对应的个数
for i in range(len(finance)):
cursor.execute("SELECT count(*) from demo where financeStage = '" + finance[i] + "'")
count = cursor.fetchall()
finance_data.append({
'value': count[0][0], 'name': finance[i]})
cursor.close()
return jsonify({
"finance": finance, "finance_data": finance_data})
全国互联网公司职位类型分布情况分析展示如图所示:
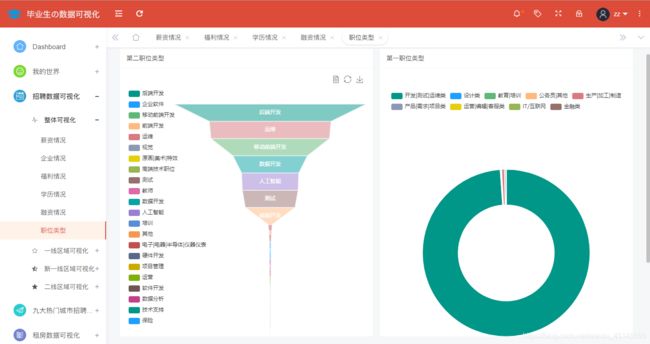
@app.route('/poststyle',methods=['GET'])
def poststyle():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(firstType) from demo")
result = cursor.fetchall()
firstType = []
firstType_data = []
# 获取到职位类型的几种情况
for field in result:
firstType.append(field[0])
# 获取到每种职位类型对应的个数
for i in range(len(firstType)):
cursor.execute("SELECT count(*) from demo where firstType = '" + firstType[i] + "'")
count = cursor.fetchall()
firstType_data.append({
'value': count[0][0], 'name': firstType[i]})
cursor.execute("SELECT DISTINCT(secondType) from demo")
second = cursor.fetchall()
secondType = []
secondType_data = []
# 获取到职位类型的几种情况
for field in second:
secondType.append(field[0])
# 获取到每种职位类型对应的个数
for i in range(len(secondType)):
cursor.execute("SELECT count(*) from demo where secondType = '" + secondType[i] + "'")
count = cursor.fetchall()
secondType_data.append({
'value': count[0][0], 'name': secondType[i]})
cursor.close()
return jsonify({
"firstType": firstType, "firstType_data": firstType_data, "secondType": secondType, "secondType_data": secondType_data})
(九)九大热门城市招聘对比
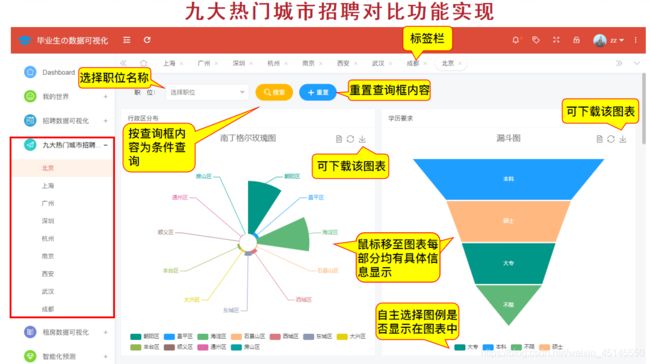
可以通过饼图纹理展示某城市互联网公司的规模情况,漏斗图展示某城市某职位的学历要求情况等
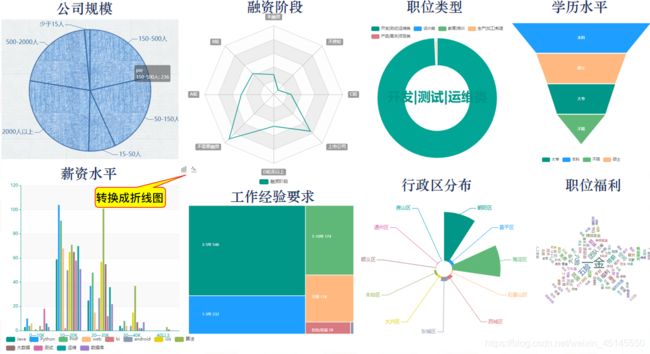
以北京为例:
@app.route('/beijing',methods=['GET'])
def beijing():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
district = []
district_result = []
companySize = []
companySizeResult = []
education = []
educationResult = []
workYear = []
workYear_data = []
firstType = []
firstType_data = []
finance = []
finance_data = []
leida_max_dict = []
# 获取到的行政区
cursor.execute("SELECT DISTINCT(district) from demo where city='北京';")
result = cursor.fetchall()
for field in result:
district.append(field[0])
if (len(request.args) == 0):
# 没有查询条件
# 获取到行政区对应的个数
for i in district:
cursor.execute("SELECT count(*) from demo where district = '" + i + "';")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': i}
district_result.append(dict)
# 获取到几种公司规模
cursor.execute("SELECT DISTINCT(companySize) from demo where city = '北京';")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
# 每种公司规模对应的个数
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and city = '北京';")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': field[0]}
companySizeResult.append(dict)
# 获取到几种学历要求
cursor.execute("SELECT DISTINCT(education) from demo where city = '北京';")
eduresult = cursor.fetchall()
for field in eduresult:
education.append(field[0])
# 每种学历要求对应的个数
cursor.execute("SELECT count(*) from demo where education = '" + field[0] + "' and city = '北京';")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': field[0]}
educationResult.append(dict)
cursor.execute("SELECT DISTINCT(workYear) from demo where city = '北京';")
workyear = cursor.fetchall()
# 获取到的几种工作经验
for field in workyear:
workYear.append(field[0])
# 获取到每种工作经验对应的个数
for i in workYear:
cursor.execute("SELECT count(*) from demo where workYear = '" + i + "' and city = '北京';")
count = cursor.fetchall()
workYear_data.append({
'value': count[0][0], 'name': i})
cursor.execute("SELECT DISTINCT(financeStage) from demo where city = '北京';")
result = cursor.fetchall()
# 获取到融资的几种情况
for field in result:
finance.append(field[0])
leida_max_dict.append({
'name': field[0], 'max': 300})
# 获取到每种融资对应的个数
for i in range(len(finance)):
cursor.execute("SELECT count(*) from demo where financeStage = '" + finance[i] + "' and city = '北京';")
count = cursor.fetchall()
finance_data.append(count[0][0])
# 职位福利
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select positionAdvantage from `demo` where city = '北京';")
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['positionAdvantage'])
content = ''.join(data_dict)
positionAdvantage = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {
}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
positionAdvantage.append(mydict)
# 职位类型
cursor.execute("SELECT DISTINCT(firstType) from demo where city = '北京';")
result = cursor.fetchall()
# 获取到职位类型的几种情况
for field in result:
for i in field.keys():
firstType.append(field[i])
# 获取到每种职位类型对应的个数
for i in range(len(firstType)):
cursor.execute("SELECT count(*) from demo where firstType = '" + firstType[i] + "' and city = '北京';")
count = cursor.fetchall()
for field in count:
for j in field.keys():
value = field[j]
firstType_data.append({
'value': value, 'name': firstType[i]})
#薪资待遇
positionName = ['java', 'python', 'php', 'web', 'bi', 'android', 'ios', '算法', '大数据', '测试', '运维', '数据库']
# 柱状图返回列表
zzt_list = []
zzt_list.append(
['product', 'Java', 'Python', 'PHP', 'web', 'bi', 'android', 'ios', '算法', '大数据', '测试', '运维', '数据库'])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) like '%k%' and positionName like '%" + i + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(
['0—10K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 10 AND 20 and positionName like '%" + i + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(['10—20K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 20 AND 30 and positionName like '%" + i + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(['20—30K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 30 AND 40 and positionName like '%" + i + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(['30—40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
temp_list = []
for i in positionName:
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) > 40 and positionName like '%" + i + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
temp_list.append(value)
zzt_list.append(['40以上', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
else:
positionName = str(request.args['positionName']).lower()
print(positionName)
# 查询条件:某种职业
# 行政区
for i in district:
cursor.execute("SELECT count(*) from demo where district = '" + i + "' and positionName like '%"+positionName+"%';")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': i}
district_result.append(dict)
# 公司规模
cursor.execute("SELECT DISTINCT(companySize) from demo where city = '北京';")
company = cursor.fetchall()
for field in company:
companySize.append(field[0])
cursor.execute("SELECT count(*) from demo where companySize = '" + field[0] + "' and positionName like '%"+positionName+"%' and city = '北京';")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': field[0]}
companySizeResult.append(dict)
# 学历要求
cursor.execute("SELECT DISTINCT(education) from demo where city = '北京';")
eduresult = cursor.fetchall()
for field in eduresult:
education.append(field[0])
cursor.execute("SELECT count(*) from demo where education = '" + field[0] + "' and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
dict = {
'value': count[0][0], 'name': field[0]}
educationResult.append(dict)
#工作经验
cursor.execute("SELECT DISTINCT(workYear) from demo where city = '北京';")
workyear = cursor.fetchall()
for field in workyear:
workYear.append(field[0])
cursor.execute("SELECT count(*) from demo where workYear = '" + field[0] + "' and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
workYear_data.append({
'value': count[0][0], 'name': field[0]})
# 融资阶段
cursor.execute("SELECT DISTINCT(financeStage) from demo where city = '北京';")
result = cursor.fetchall()
# 获取到融资的几种情况
for field in result:
finance.append(field[0])
leida_max_dict.append({
'name': field[0], 'max': 300})
# 获取到每种融资对应的个数
for i in range(len(finance)):
cursor.execute("SELECT count(*) from demo where financeStage = '" + finance[i] + "' and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
finance_data.append(count[0][0])
# 职位类型
cursor.execute("SELECT DISTINCT(firstType) from demo where city = '北京';")
result = cursor.fetchall()
# 获取到职位类型的几种情况
for field in result:
firstType.append(field[0])
# 获取到每种职位类型对应的个数
for i in range(len(firstType)):
cursor.execute("SELECT count(*) from demo where firstType = '" + firstType[i] + "' and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
firstType_data.append({
'value': count[0][0], 'name': firstType[i]})
# 职位福利
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select positionAdvantage from `demo` where city = '北京' and positionName like '%" + positionName + "%' ;")
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field['positionAdvantage'])
content = ''.join(data_dict)
positionAdvantage = []
jieba.analyse.set_stop_words('./stopwords.txt')
tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True)
for v, n in tags:
mydict = {
}
mydict["name"] = v
mydict["value"] = str(int(n * 10000))
positionAdvantage.append(mydict)
# 薪资待遇
positionName_sample = ['java', 'python', 'php', 'web', 'bi', 'android', 'ios', '算法', '大数据', '测试', '运维', '数据库']
# 柱状图返回列表
zzt_list = []
zzt_list.append(['product', 'Java', 'Python', 'PHP', 'Web', 'BI', 'Android', 'ios', '算法', '大数据', '测试', '运维', '数据库'])
# <10k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) like '%k%' and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
#print(count)
for i in count[0].keys():
value = count[0][i]
print(value)
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
# print(temp_list)
# temp_list.append(value)
zzt_list.append(['0—10K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
# 10-20k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 10 AND 20 and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
# temp_list.append(value)
zzt_list.append(['10—20K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
# 20-30k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 20 AND 30 and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
#temp_list.append(value)
zzt_list.append(['20—30K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
# 30-40k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) BETWEEN 30 AND 40 and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
#temp_list.append(value)
zzt_list.append(['30—40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
# >40k
temp_list = []
cursor.execute("SELECT COUNT(*) FROM demo WHERE SUBSTR(salary,1,2) > 40 and positionName like '%" + positionName + "%' and city = '北京';")
count = cursor.fetchall()
for i in count[0].keys():
value = count[0][i]
for num in range(len(positionName_sample)):
if positionName == positionName_sample[num]:
temp_list.append(value)
else:
temp_list.append(0)
#temp_list.append(value)
zzt_list.append(['>40K', temp_list[0], temp_list[1], temp_list[2], temp_list[3], temp_list[4], temp_list[5],temp_list[6], temp_list[7], temp_list[8], temp_list[9], temp_list[10], temp_list[11]])
print(zzt_list)
result = {
"district": district, "district_result": district_result, "companySize": companySize, "companySizeResult": companySizeResult, "education": education, "educationResult": educationResult, "workYear_data":workYear_data, "firstType": firstType, "firstType_data": firstType_data, "leida_max_dict":leida_max_dict, "cyt": positionAdvantage, "finance": finance, "finance_data": finance_data, "zzt": zzt_list}
cursor.close()
return jsonify(result)
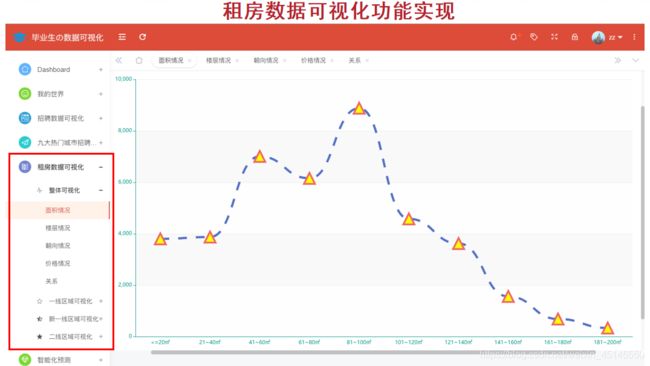
(十)租房数据可视化
从全国、一线城市、新一线城市、二线城市四个角度分区域分析。
举个栗子,全国范围内的租房房屋面积情况分析如下图所示:
@app.route('/area',methods=['GET'])
def area():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
area_kind = ['<=20㎡', '21~40㎡', '41~60㎡', '61~80㎡', '81~100㎡', '101~120㎡', '121~140㎡', '141~160㎡', '161~180㎡', '181~200㎡']
area_data = []
# 获取到每种面积类别对应的个数
#<=20㎡
cursor.execute("SELECT count(*) from house where area between 0 and 20;")
count = cursor.fetchall()
area_data.append(count[0][0])
#21~40㎡
cursor.execute("SELECT count(*) from house where area between 21 and 40;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 41~60㎡
cursor.execute("SELECT count(*) from house where area between 41 and 60;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 61~80㎡
cursor.execute("SELECT count(*) from house where area between 61 and 80;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 81~100㎡
cursor.execute("SELECT count(*) from house where area between 81 and 100;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 101~120㎡
cursor.execute("SELECT count(*) from house where area between 101 and 120;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 121~140㎡
cursor.execute("SELECT count(*) from house where area between 121 and 140;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 141~160㎡
cursor.execute("SELECT count(*) from house where area between 141 and 160;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 161~180㎡
cursor.execute("SELECT count(*) from house where area between 161 and 180;")
count = cursor.fetchall()
area_data.append(count[0][0])
# 181~200㎡
cursor.execute("SELECT count(*) from house where area between 181 and 200;")
count = cursor.fetchall()
area_data.append(count[0][0])
cursor.close()
print(area_data)
return jsonify({
"area_kind": area_kind, "area_data": area_data})
全国范围内租房房屋楼层情况分析展示如图所示:
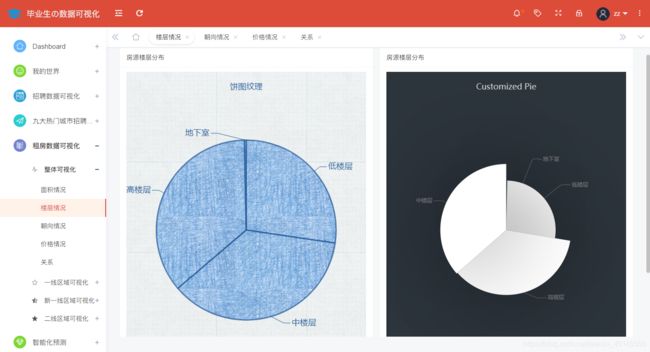
@app.route('/floor',methods=['GET'])
def floor():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(floor) from house;")
result = cursor.fetchall()
floor_kind = []
floor_data = []
# 获取到楼层的几种情况
for field in result:
floor_kind.append(field[0])
# 获取到每种楼层类型对应的个数
for i in range(len(floor_kind)):
cursor.execute("SELECT count(*) from house where floor = '" + floor_kind[i] + "'")
count = cursor.fetchall()
floor_data.append({
'value': count[0][0], 'name': floor_kind[i]})
cursor.close()
return jsonify({
"floor_kind": floor_kind, "floor_data": floor_data})
全国范围内租房房屋朝向情况分析展示如图所示:
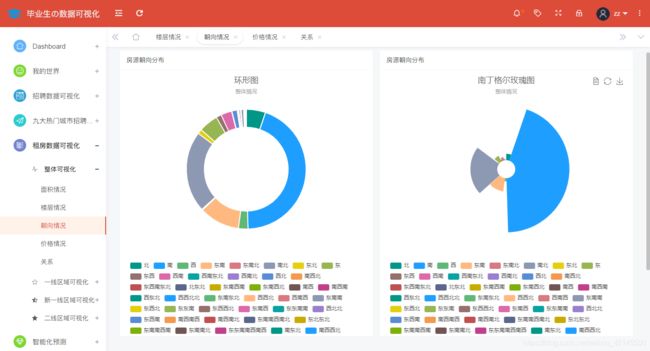
@app.route('/orient',methods=['GET'])
def orient():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
cursor.execute("SELECT DISTINCT(orient) from house;")
result = cursor.fetchall()
orient_kind = []
orient_data = []
# 获取到朝向的几种情况
for field in result:
orient_kind.append(field[0])
# 获取到每种朝向类型对应的个数
for i in range(len(orient_kind)):
cursor.execute("SELECT count(*) from house where orient = '" + orient_kind[i] + "'")
count = cursor.fetchall()
orient_data.append({
'value': count[0][0], 'name': orient_kind[i]})
cursor.close()
print(orient_data)
return jsonify({
"orient_kind": orient_kind, "orient_data": orient_data})
全国范围内租房房屋价格情况分析展示如图所示:
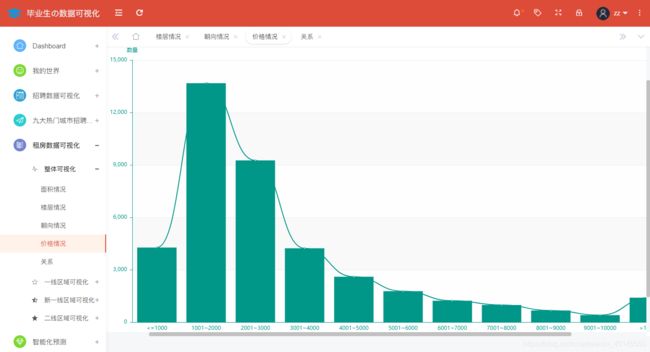
@app.route('/price',methods=['GET'])
def price():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
price_kind = ['<=1000', '1001~2000', '2001~3000', '3001~4000', '4001~5000', '5001~6000', '6001~7000', '7001~8000', '8001~9000', '9001~10000', '>10000']
price_data = []
# 获取到每种价格类别对应的个数
# <=1000
cursor.execute("SELECT count(*) from house where price between 0 and 1000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 1001~2000
cursor.execute("SELECT count(*) from house where price between 1001 and 2000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 2001~3000
cursor.execute("SELECT count(*) from house where price between 2001 and 3000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 3001~4000
cursor.execute("SELECT count(*) from house where price between 3001 and 4000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 4001~5000
cursor.execute("SELECT count(*) from house where price between 4001 and 5000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 5001~6000
cursor.execute("SELECT count(*) from house where price between 5001 and 6000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 6001~7000
cursor.execute("SELECT count(*) from house where price between 6001 and 7000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 7001~8000
cursor.execute("SELECT count(*) from house where price between 7001 and 8000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 8001~9000
cursor.execute("SELECT count(*) from house where price between 8001 and 9000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# 9001~10000
cursor.execute("SELECT count(*) from house where price between 9001 and 10000;")
count = cursor.fetchall()
price_data.append(count[0][0])
# >10000
cursor.execute("SELECT count(*) from house where price >10000;")
count = cursor.fetchall()
price_data.append(count[0][0])
cursor.close()
print(price_data)
return jsonify({
"price_kind": price_kind, "price_data": price_data})
全国范围内租房房屋价格与房屋面积关系情况分析展示如图所示:
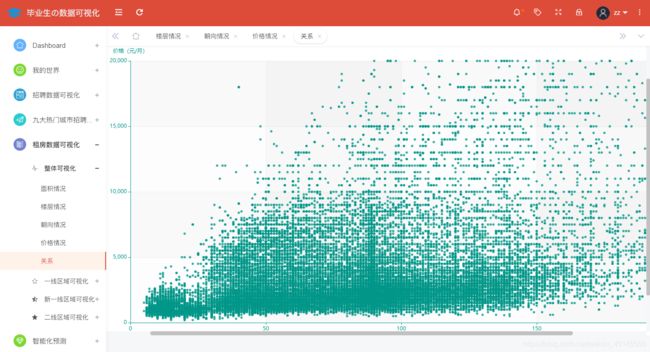
@app.route('/relation',methods=['GET'])
def relation():
conn = pymysql.connect(host='localhost', user='root', password='123456', port=3366, db='lagou',
charset='utf8mb4')
cursor = conn.cursor()
relation_data = []
cursor.execute("select count(*) from house;")
count = cursor.fetchall()
#print(count[0][0])
cursor.execute("SELECT area,price from house;")
result = cursor.fetchall()
for i in range(count[0][0]):
relation_data.append(list(result[i]))
#print(relation_data)
cursor.close()
return jsonify({
"relation_data": relation_data})
(十一)智能预测
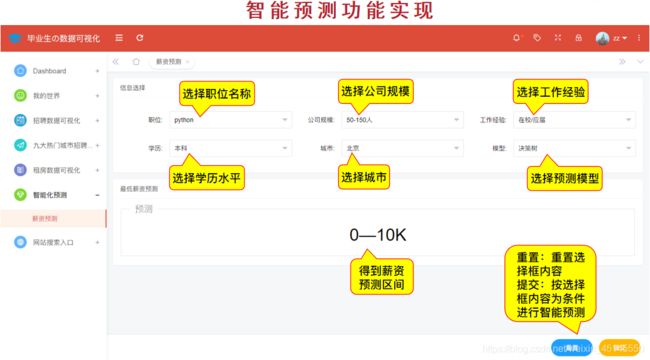
@app.route('/predict',methods=['GET'])
def predict():
y_data = ['0—10K', '10—20K', '20—30K', '30—40K', '40K以上']
positionName = str(request.args['positionName']).lower()
model = str(request.args['model'])
with open(positionName+'_'+model+'.model', 'rb') as fr:
selected_model = pickle.load(fr)
companySize = int(request.args['companySize'])
workYear = int(request.args['workYear'])
education = int(request.args['education'])
city = int(request.args['city'])
x = [companySize, workYear, education, city]
x = np.array(x)
y = selected_model.predict(x.reshape(1, -1))
return jsonify(y_data[y[0]])
(十二)网站接入
项目也存在着一些不足之处:
1.招聘数据库中职位信息较少,爬取网站种类单一,只研究了互联网岗位
2.本系统通过网络爬虫技术抓取招聘信息和租房信息只能进行手动输入网址爬取
3.本系统的岗位信息和租房信息尚未实现交集,若能根据公司地址智能推荐附近房源会更好