关系型数据库[吐血整理],你还不快收藏吗
Oracle
概述
Oracle Database,又名Oracle RDBMS,或简称Oracle。是甲骨文公司的一款关系数据库管理系统。它是在数据库领域一直处于领先地位的产品。可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小微机环境。它是一种高效率的、可靠性好的、适应高吞吐量的数据库方案。
架构
体系结构
一个 Oracle 数据库服务器(database server)由一个数据库(database)以及至少一个数据库实例(database instance,通常简称实例)组成。正是由于实例和数据库之间的关系如此紧密,Oracle database 有时候同时表示实例和数据库。
数据库(Database):数据库代表磁盘上的一组文件,用于存储数据。这些文件可以独立于实例而存在。
数据库实例(Database instance):实例是一组内存结构,用于管理数据库文件。实例由一个称为系统全局区(SGA)的共享内存区域以及一组后台进程组成。实例可以独立于数据库文件而存在。
下图显示了一个数据库和它的实例。对于每个连接到实例的用户连接,客户端进程负责运行应用程序。每个客户端进程与自己的服务器进程关联。服务器进程拥有自己的私有会话内存,称为程序全局区(PGA)。

图中 SGA 包括数据库缓冲区高速缓存(Database Buffer Cache)、重做日志缓冲区(Redo Log Buffer)、共享池(Shared Pool)、大池(Large Pool)、固定 SGA(Fixed SGA)、Java 池(Java Pool)以及流池(Streams Pool)。SGA 右边是后台进程:PMON、SMON、RECO、MMON、MMNL 等。SGA 下边也是后台进程:DBWn、CKPT、LGWR、ARCn 以及 RVWR。再往下是 PGA 和服务器进程。服务器进程和客户端进程相互连接。客户端进程右边是数据库文件(数据文件、控制文件以及在线重做日志)、归档重做日志以及闪回日志。
虽然严格来说,一个 Oracle 数据库就是一组物理结构(文件和内存结构),应用程序可以与一个物理数据库中的多个逻辑数据库进行交互,也可以与跨越多个物理数据库的一个逻辑数据库进行交互。
内存结构

进程(process)是操作系统中能够执行一系列操作的机制。某些操作系统使用其他的术语,包括作业(job)、任务(task)或者线程(thread)。在本节内容中,线程等价于进程。一个 Oracle 数据库实例包含以下进程:
1、客户端进程
这些进程用于运行应用程序代码或者 Oracle 工具。通常客户端进程来自于多个不同的计算机。
2、后台进程
这些进程代替 Oracle 服务器进程完成各种数据库操作。后台进程异步地执行 I/O 操作,并且监控其他 Oracle 数据库进程,提供了更高的并发,获得了更好的性能和可靠性。
3、服务器进程
这些进程用于和客户端进程通信,并且和 Oracle 数据库进行交互,完成各种请求操作。
Oracle 进程包括服务器进程(server process)和后台进程(background process)。在大多数情况下,Oracle 进程和客户端进程运行在不同的计算机上。
物理存储结构
黄色的部分代表着Oracle的核心组成,分别是数据文件、控制文件以及重做日志文件。除此之外,物理存储结构还包括着一些其他文件,例如参数文件、密码文件以及归档日志文件等等。下面将主要介绍这些文件。
数据文件(Data files)
数据文件是指存储数据库中数据的文件,这些“xxxx.dbf”存储着系统数据、数据字典数据、索引数据以及用户存储的数据,所以这部分也是数据库最核心的部分。数据文件大小是灵活的,可以通过设置让它自动扩展,避免了数据量过大但是数据文件空间有限这种状况; 数据文件是专属于一个数据库的,也专属于一个表空间的,但是一个表空间却可以拥有多个数据文件。如果用户读取的数据不在缓冲区内,便会从数据文件中将相对应的数据放到缓冲区中,再进行读取。这部分内容会在之后详细分析。
控制文件(Control files)
控制文件是一个很小的二进制文件,这些“xxx.CTL”中存放的数据库的”物理结构信息”,这些物理结构信息包括: 数据库的名字、数据文件和联机日志文件的名字及位置.、创建数据库时的时间戳。数据库在启动的时候需要访问控制文件,从中读取数据文件、日志文件的信息;随着Oracle的运行,数据库将不断更新控制文件;相对应的一旦控制文件损坏,数据库便会发生运行故障。所以为了更好的保护数据库,我们可以镜像控制文件,特别是在数据库结构发生变化时,要对其进行备份,保持控制文件的一致性。
重做日志文件(Redo Log files)
重做日志文件用于记录数据库所有修改信息 的文件,小名叫做日志文件,这些“.log”文件既可以保证数据库的安全,又可以实现数据库的备份和恢复。为了防止数据出现意外丢失,oracle也允许镜像日志文件,一个日志与其镜像出来的文件构成一个日志文件组,但是镜像文件数量不能超过5个。正所谓所有的鸡蛋不要放在一个篮子里,同一组的文件最好保存在不同的磁盘中,防止物理损坏造成不必要的麻烦。
参数文件(Parameter file)
参数文件记录了Oracle数据库的基本参数信息,主要包括数据库名、控制文件所在路径等。参数文件包括文本参数文件(PFILE)和服务器参数文件(SPFILE),前者为init.ora,后者为spfile.ora或spfile.ora的二进制文件。在数据库启动的时候就会读取参数文件,然后根据参数文件中的参数来分配SGA并启动一系列的后台进程。
归档日志文件(Archived Log files)
归档日志文件用来对写满的日志文件进行保存复制。其目的是为了长期保存日志以便于恢复。
逻辑存储结构
在oracle数据库中,对数据库操作会涉及逻辑存储结构,它是从逻辑角度分析数据库的构成,描述的是数据库内部数据的组织与管理方式,与操作系统没有关系。
如图,可以明显的看出数据库逻辑结构主要包括表空间、段、区和数据块,所有的结构都是一对多的关系,一个数据库可以拥有多个表空间,一个表空间拥有多个段等等。
表空间
表空间是Oracle最大的逻辑存储结构,与物理上的数据文件相对应,但是一个表空间可以拥有多个数据文件,这里就不一一赘述了。
段
段是一组盘区,它是一个独立的逻辑存储结构,用于存储具有独立存储结构对象的全部数据。段一般是数据库终端用户处理最小的存储单位,当段的数据区已满,Oracle为其分配另一个数据区,段的数据区在磁盘上可能是不连续的。根据段所存储的特征,可将其分为5种类型:
1、数据段:用来存储表中所有数据;在Oracle中,每当用户创建一个表时,系统将自动在默认表空间里分配一个与表名称相同的数据段,方便存储该表的所有数据。
2、索引段:用来存储表中索引的所有数据;在Oracle中,每当用户创建索引时,系统将自动在默认表空间创建一个与索引名称相同的索引段,方便存储该索引的所有数据。
3、临时段: 用于存储表排序或汇总时产生的临时数据;
临时表空间进行Order by 进行排列或汇总时,系统在该用户的临时表空间自动创建一个临时段,在操作结束时自动消除。
4、LOB段:LOB用来存储表中大型数据对象,例如CLOB与BLOB
5、回退段:用于存储用户数据被修改之前的位置和值;当与要对用户的数据进行回退操作时,就要使用回退段。
区
区是Oracle存储分配的最小单位,它是由一个或多个数据块组成的。一个或多个区组成一个段,也就是说段的大小都是由区的个数来决定。当一个段的空间使用完之后,Oracle会自动为该字段分配成一个新的区。
块
块是用来管理存储空间的最基本的单位,也是最小的逻辑存储单位。块的大小由初始化参数db_block_size来决定,不同的Oracle版本的大小是不同的,但是数据库一旦创建,其大小便不可更改。虽然每个数据块可以存储不同类型的数据,但是每个数据块都具有一个相同的结构。
特性
完整的数据管理功能
1、数据的大量性
2、数据的保存的持久性
3、数据的共享性
4、数据的可靠性
完备关系的产品
1、信息准则---关系型DBMS的所有信息都应在逻辑上用一种方法,即表中的值显式地表示。
2、保证访问的准则。
3、视图更新准则---只要形成视图的表中的数据变化了,相应的视图中的数据同时变化。
4、数据物理性和逻辑性独立准则。
分布式处理功能
ORACLE数据库自第5版起就提供了分布式处理能力,到第7版就有比较完善的分布式数据库功能了,一个ORACLE分布式数据库由oraclerdbms、sql*Net、SQL*CONNECT和其他非ORACLE的关系型产品构成。
用ORACLE能轻松的实现数据仓库的操作。这是一个技术发展的趋势,不在这里讨论。
优点:
1、可用性强
2、可扩展性强
3、数据安全性强
4、稳定性强
使用场景
Oracle是一款大型数据库软件,支撑体系完善,强大。单库可支撑数据量大,安全性高。适用于服务器比较强大的单节点或者集群环境。
主要在传统行业的数据化业务中,比如:银行、金融这样的对可用性、健壮性、安全性、实时性要求极高的业务;零售、物流这样对海量数据存储分析要求很高的业务。此外,高新制造业如芯片厂也基本都离不开Oracle;电商也有很多使用者,如京东(正在投奔Oracle)、阿里巴巴(计划去Oracle化)。
局限性:管理维护麻烦;数据库崩溃后回复很麻烦,因为他把很多东西放在内存里,
数据库连接要慢些,最好用连接池;大对象不好用,vchar2字段太短,不够用;管理员的工作烦,且经验非常重要; 对硬件的要求很高;价格昂贵。
SQL Server
概述
SQL Server是由Microsoft开发和推广的关系数据库管理系统(DBMS),它最初是由Microsoft、Sybase和Ashton-Tate三家公司共同开发的,并于1988年推出了第一个OS/2版本。Microsoft SQL Server近年来不断更新版本,1996年,Microsoft 推出了SQL Server 6.5版本;1998年,SQL Server 7.0版本和用户见面;SQL Server 2000是Microsoft公司于2000年推出,目前最新版本是2019年份推出的SQL SERVER 2019。
架构
体系结构
Microsoft SQL Server 是微软公司开发的一款关系型数据库管理系统,支持 Windows、Linux 以及容器部署。Microsoft SQL Server 采用标准的客户端-服务器体系结构,客户端发送请求到服务端,服务端处理完成之后返回结果到客户端。
Microsoft SQL Server 服务由一个实例(Instance)和多个数据库(Databases)组成,实例包含了后台线程和占用的内存,默认的系统数据库包括 master、model、msdb、Resource 以及 tempdb。
Microsoft SQL Server 的整体系统结构如下:

主要包含以下三个组件:
1、协议层(Protocol Layer),主要负责客户端的连接请求和数据通信。
2、关系引擎(Relational Engine),主要负责 SQL 语句的解析、优化和执行。
3、存储引擎(Storage Engine),主要负责数据和日志的存储和访问、内存和缓存管理、事务和锁管理。
协议层
客户端应用首先需要通过 SNI 网络接口(SQL Server Network Interface)与服务器建立连接,Microsoft SQL Server 提供了以下三种协议方式:
1、TCP/IP 协议;
2、共享内存(Shared Memory)协议;
3、命名管道(Named Pipes)协议。
关系引擎
Microsoft SQL Server 协议层接收到客户端的请求并处理之后,将语句传递给关系引擎进行处理。关系引擎也成为查询处理器(Query Processor)。关系引擎决定了查询需要执行的操作以及如何最好地实现该操作,负责请求存储引擎获取用户所需的数据并且对结果进行处理,然后通过协议层将结果返回给客户端。
关系引擎包含了以下三个主要部分:
1、命令解析器
命令解析器主要的作用是检查 T-SQL 语句的语法和语义错误,并创建一个内部的查询树(Query Tree)。
Microsoft SQL Server 和其他编程语言一样预定义了很多关键字,同时具有自己的语法格式。例如,SELECT、INSERT、UPDATE、CREATE、DROP 等都属于预定义的关键字。命令解析器首先对输入的语句进行语法检查,如果违反了语法规则,将会返回一个错误。例如:

其中,SELECT 错写成了 SELECR,所以返回了一个语法错误。
接下来是语义检查,包括表名和字段名是否存在,存在的话将其绑定(Binding)到该查询。如果查询涉及了视图,还会使用视图的定义进行语句替换。例如:

由于当前模式中不存在表 no\_table,查询返回了对象名无效的错误。
完成检查之后,命令解析器为 T-SQL 语句创建一个查询树,然后传递给查询优化器。
2、查询优化器
查询优化器的作用是创建一个执行计划,也就是执行查询语句的具体操作。需要注意的是,并非所有的查询都会进行优化。DML 命令(例如 SELECT、INSERT、DELETE 以及 UPDATE 等)会发送给优化器;DDL 命令(例如 CREATE、ALTER 等)不会进行优化,而是直接编译成内部格式。
查询优化器的输入包括查询语句、数据库模式(表和索引的定义)以及数据库统计信息。 查询优化器的输出称为“查询执行计划”,有时也称为“查询计划”或为“执行计划”。在优化单个 SELECT 语句期间查询优化器的输入和输出如下图中所示:

Microsoft SQL Server 查询优化器是基于成本的优化器,基于输入参数和各种因素,例如所需的 CPU 使用率、内存以及 I/O 等,对查询成本进行计算,然后找出最佳(而不是成本最低)的执行计划。执行计划包含了从每个表提取数据的方法(表扫描或者索引访问)、多个表的访问顺序、执行计算的方法以及对每个表中的数据进行筛选、聚合和排序的方法。
3、查询执行器
查询执行器负责调用存储引擎执行具体的计划。存储引擎提供了获取数据的访问方法(Access Method),查询执行器将存储引擎返回的数据处理成为结果集定义的格式后,通过协议层将结果集返回客户端。
存储引擎
存储引擎负责存储系统(例如磁盘或者 SAN)中的数据存储和检索。存储引擎包含了 3 个组件:
1、访问方法
访问方法是查询执行器和缓冲管理器/事务日志之间的一个接口。首先,它会判断查询的类型是 SELECT 语句还是 DDL/DML 语句;如果是 SELECT 语句,则将其传递给缓冲管理器进行处理;如果是 DDL 或者 DML 语句(例如 UPDATE),则将其传递给事务管理器进行处理。

2、缓冲管理器
缓冲管理器实现了以下核心功能模块:
- 执行计划缓存(Plan Cache);
- 数据解析(Data Parsing):缓冲区缓存(Buffer cache)和数据存储(Data storage);
- 脏页(Dirty Page)。
第一次生成查询计划时,如果计划比较复杂,缓冲管理器会将该查询和相应的执行计划存储到缓存中。缓存管理器对每次查询进行检查,如果服务器接收到相同的查询,可以重用缓存的查询计划和数据。
缓存管理器还提供了数据的访问操作。如果数据已经位于数据缓存(Data cache)中,直接通过缓存返回数据;这种方式减少了磁盘 I/O,提高了数据访问的性能,被称为数据的软解析(Soft Parsing)。

如果所需的数据不在数据缓存中,通过磁盘 I/O 访问数据存储设备中的文件,同时将数据存储到缓存中,这种方式被称为数据的硬解析(Hard Parsing)。

脏页是只内存中被修改过但还没有写入磁盘的数据,它由事务管理器产生,具体参考下文中的事务管理器部分。
3、事务管理器
如果查询属于修改对象或者数据的语句,需要调用事务管理器。事务管理器包括日志管理器(Log Manager)和锁管理器(Log Manager)。
日志管理器利用事务日志(Transaction Log)中的日志项记录了系统的所有更新操作,每条日志记录由一个日志序列号(LSN)标识,同时包含了事务 ID 和数据修改记录。 Microsoft SQL Server 使用预写日志 (Write-ahead Logging) ,可以确保在将相关日志记录写入磁盘后再将数据修改写入磁盘,维护了事务的 ACID 属性。如果系统出现故障,则可能需要使用事务日志将数据库恢复到一致状态。
锁管理器用于在事务处理期间管理事务对所依赖的资源(如行、页或表)上请求的锁。 锁可以阻止其他事务以某种可能会导致事务请求锁出错的方式修改资源,实现事务的隔离性和一致性。
数据库事务的处理流程如下:
- 日志管理器开始记录日志,同时锁定管理器锁定相关的数据。
- 在缓冲区缓存中维护数据的副本;
- 在日志缓冲区中记录被修改数据的前后镜像,并且更新数据缓冲区中的数据副本,此时也就产生了数据的脏页;
- 检查点线程(Checkpoint)定期将数据脏页和缓冲日志写入磁盘。
- SQL Server 通过 Lazy Writer 线程使用 LRU(Least recently Used)算法将数据脏页刷新到磁盘文件。
另外,Microsoft SQL Server 还提供了基于行版本控制的隔离,数据库引擎将会维护修改的每一行的版本。 应用程序可以指定事务使用行版本查看事务或查询开始时存在的数据,而不是使用锁保护所有读取。 通过使用行版本控制,读取操作阻止其他事务的可能性将大大降低。
存储结构
每个 SQL Server 数据库至少具有两个操作系统文件:一个数据文件和一个日志文件。 数据文件包含数据和对象,例如表、索引、存储过程和视图。 日志文件包含恢复数据库中的所有事务所需的信息。 为了便于分配和管理,可以将数据文件集合起来,放到文件组中。

SQL Server 数据库具有三种类型的文件:
1、主要数据文件(Primary file),包含数据库的启动信息,并指向数据库中的其他文件。 每个数据库有一个主要数据文件。主要数据文件的建议文件扩展名是.mdf。
2、辅助数据文件(Secondary file),用户定义的可选数据文件。 通过将每个文件放在不同的磁盘驱动器上,可将数据分散到多个磁盘中。次要数据文件的建议文件扩展名是.ndf。
3、事务日志文件(Log file),此日志包含用于恢复数据库的信息。 每个数据库必须至少有一个日志文件。 事务日志的建议文件扩展名是.ldf。
特性
1、真正的客户机/服务器体系结构。
2、图形化用户界面,使系统管理和数据库管理更加直观、简单。
3、丰富的编程接口工具,为用户进行程序设计提供了更大的选择余地。
4、SQL Server与Windows NT完全集成,利用了NT的许多功能,如发送和接受消息,管理登录安全性等。SQL Server也可以很好地与Microsoft BackOffice产品集成。
5、具有很好的伸缩性,可跨越从运行Windows 95/98的小型电脑到运行Windows 2000的大型多处理器等多种平台使用。
6、对Web技术的支持,使用户能够很容易地将数据库中的数据发布到Web页面上。
7、SQL Server提供数据仓库功能,这个功能只在Oracle和其他更昂贵的DBMS中才有。
SQL Server 2000与以前版本相比较,又具有以下新特性 :
1、支持XML(Extensive Markup Language,扩展标记语言)
2、强大的基于Web的分析
3、支持OLE DB和多种查询
4、支持分布式的分区视图
SQL Server 2019在新的功能上可以看到有几个重大方向的内容。
1、大数据群集
2、数据库引擎更多功能
3、新的工具Azure Data Studio
使用场景
SQL Server 是一款常用的关系型数据库,功能和mysql类似,性能也相当。主机操作系统为window,主要用于web网站的建设,承载中小型web后台数据。在租赁的虚拟主机中一般会预安装SQL Server作为数据库软件。
局限性:只能运行在微软的windows平台;并行实施和共存模型并不成熟,很难处理日益增多的用户数和数据卷,伸缩性有限;SQLServer当用户连接多时性能会变的很差,并且不够稳定;只支持C/S模式;SQL Server并没有获得相关机构的安全认证。
Sybase
概述
Sybase数据库是美国Sybase公司研制的一种关系型数据库系统,是一种典型的UNIX或WindowsNT平台上客户机/服务器环境下的大型数据库系统。 Sybase提供了一套应用程序编程接口和库,可以与非Sybase数据源及服务器集成,允许在多个数据库之间复制数据,适于创建多层应用。系统具有完备的触发器、存储过程、规则以及完整性定义,支持优化查询,具有较好的数据安全性。Sybase通常与SybaseSQLAnywhere用于客户机/服务器环境,前者作为服务器数据库,后者为客户机数据库,采用该公司研制的PowerBuilder为开发工具,在我国大中型系统中具有广泛的应用。
架构
Sybase数据库主要由以下三部分组成:
1、进行数据管理与维护的联机关系数据库管理系统Sybase SQL Server;
2、支持数据库应用系统的建立和开发的一组前端工具软件Sybase SQL Tools;
3、可把异构环境下其他厂商的应用软件和任何类型的数据连接在一起的接口软件Open Client/Open Server。
特性
一般的关系数据库都是基于主/从式的模型的。在主/从式的结构中,所有的应用都运行在一台机器上。用户只是通过终端发命令或简单地查看应用运行的结果。
而在客户/服务器结构中,应用被分在了多台机器上运行。一台机器是另一个系统的客户,或是另外一些机器的服务器。这些机器通过局域网或广域网联接起来。
客户/服务器模型的好处是:
● 支持共享资源且在多台设备间平衡负载
● 允许容纳多个主机的环境,充分利用了企业已有的各种系统
1、可编程数据库
通过提供存储过程,创建了一个可编程数据库。存储过程允许用户编写自己的数据库子例程。这些子例程是经过预编译的,因此不必为每次调用都进行编译、优化、生成查询规划,因而查询速度要快得多。
2、事件驱动的触发器
触发器是一种特殊的存储过程。通过触发器可以启动另一个存储过程,从而确保数据库的完整性。
3、多线索化
Sybase数据库的体系结构的另一个创新之处就是多线索化。一般的数据库都依靠操作系统来管理与数据库的连接。当有多个用户连接时,系统的性能会大幅度下降。Sybase数据库不让操作系统来管理进程,把与数据库的连接当作自己的一部分来管理。此外,Sybase的数据库引擎还代替操作系统来管理一部分硬件资源,如端口、内存、硬盘,绕过了操作系统这一环节,提高了性能。
使用场景
SYBASE ASE
Sybase ASE 的全称是 Adaptive Server Enterprise ,是企业及数据库服务器,适合用于企业级OLTP(在线联机事务处理),是功能强大的关系数据库管理系统。
SYBASE ASA
Sybase ASA 的全称是 Adaptive Server Anywhere,是轻量级数据库服务器,适合用于移动计算(PDA、带OS的手机等)、嵌入式计算(POS机、路由器等)、工作组级OLTP环境,特别是移动计算/嵌入式计算。
SYBASE IQ
Sybase IQ 是企业级数据仓库数据库服务器,适合于DSS环境中的企业级数据仓库和数据集市。
局限性:搜索引擎可查询到的相关技术文档稀少,学习维护成本很高。同时目前可查询到的应用案列也很少。
DB2
概述
IBM DB2 是美国IBM公司开发的一套关系型数据库管理系统,它主要的运行环境为UNIX(包括IBM自家的AIX)、Linux、IBM i(旧称OS/400)、z/OS,以及Windows服务器版本。
DB2主要应用于大型应用系统,具有较好的可伸缩性,可支持从大型机到单用户环境,应用于所有常见的服务器操作系统平台下。 DB2提供了高层次的数据利用性、完整性、安全性、可恢复性,以及小规模到大规模应用程序的执行能力,具有与平台无关的基本功能和SQL命令。DB2采用了数据分级技术,能够使大型机数据很方便地下载到LAN数据库服务器,使得客户机/服务器用户和基于LAN的应用程序可以访问大型机数据,并使数据库本地化及远程连接透明化。 DB2以拥有一个非常完备的查询优化器而著称,其外部连接改善了查询性能,并支持多任务并行查询。 DB2具有很好的网络支持能力,每个子系统可以连接十几万个分布式用户,可同时激活上千个活动线程,对大型分布式应用系统尤为适用。
DB2除了可以提供主流的OS/390和VM操作系统,以及中等规模的AS/400系统之外,IBM还提供了跨平台(包括基于UNIX的LINUX,HP-UX,SunSolaris,以及SCOUnixWare;还有用于个人电脑的OS/2操作系统,以及微软的Windows 2000和其早期的系统)的DB2产品。DB2数据库可以通过使用微软的开放数据库连接(ODBC)接口,Java数据库连接(JDBC)接口,或者CORBA接口代理被任何的应用程序访问。
架构
体系结构
在客户机端,本地或远程应用程序与 Db2 客户机库链接。本地客户机使用共享内存和信号进行通信;远程客户机使用协议(例如命名管道 (NPIPE) 或 TCP/IP)进行通信。在服务器端,活动由引擎可分派单元 (EDU) 控制。

EDU 在所有平台上都作为线程实现。Db2 代理程序是最常见的 EDU 类型。这些代理程序代表应用程序执行大量 SQL 和 XQuery 处理。其他常见的 EDU 包括预取程序和页清除程序。
可以指定一组子代理程序来处理客户机应用程序请求。如果服务器所在的机器包含多个处理器或者是分区数据库环境的组成部分,那么可以指定多个子代理程序。例如,在对称多处理 (SMP) 环境中,多个 SMP 子代理程序可以利用多个处理器。
所有代理程序和子代理程序都由一个共享算法管理,该算法将最大程度地减少创建和破坏 EDU 的操作。
缓冲池是数据库服务器内存中的一个区域,用户数据页、索引数据页和目录数据页被临时地移至该区域,并可以在该处被修改。由于访问内存中的数据比访问磁盘中的数据快得多,因此缓冲池是数据库性能的重要决定因素。
缓冲池以及预取程序和页清除程序 EDU 的配置决定了应用程序能够多快地访问数据。
预取程序在应用程序需要数据之前从磁盘检索该数据,并将其移入缓冲池。例如,如果没有数据预取程序,那么需要扫描大量数据的应用程序将必须等待数据从磁盘移入缓冲池。应用程序的代理程序将异步预读取请求发送至公共预取队列。当预取程序可用时,它们使用大块或散射读取输入操作将请求的页从磁盘读入缓冲池,从而实现那些请求。如果使用多个磁盘来存储数据,那么可以采用条带分割技术将数据分布到那些磁盘上。条带分割技术使预取程序能够同时使用多个磁盘来检索数据。
页清除程序将数据从缓冲池移回到磁盘。页清除程序是独立于应用程序代理程序的后台 EDU。它们将查找已被修改的页,并将那些已更改的页写入磁盘。页清除程序确保缓冲池中有空间供预取程序正在检索的页使用。
如果没有独立的预取程序和页清除程序 EDU,那么应用程序代理程序将必须执行缓冲池与磁盘存储器之间的所有数据读取和写入操作。
处理模型
Db2 处理模型的知识可帮助您了解数据库管理器及其关联组件如何交互。此知识可帮助您诊断可能发生的问题。
所有 Db2 数据库服务器使用的处理模型都旨在简化数据库服务器与客户机之间的通信。它还确保数据库应用程序独立于数据库控制块和关键数据库文件之类的资源。
Db2 数据库服务器必须执行各种不同的任务,例如处理数据库应用程序请求,或者确保将日志记录写入磁盘。通常,每项任务都由一个独立的引擎可分派单元 (EDU) 执行。
采用多线程体系结构对于 Db2 数据库服务器而言有很多优点。由于同一进程内的所有线程可以共享一些操作系统资源,因此,新线程需要的内存和操作系统资源比进程要少。此外,在某些平台上,线程的上下文切换时间比进程短,这有助于提高性能。在所有平台上使用线程模型使得 Db2 数据库服务器更易于配置,因为这样更容易根据需要分配更多 EDU,并且可以动态分配必须由多个 EDU 共享的内存。
对于所访问的每个数据库,将启动不同的 EDU 以处理各种数据库任务,例如预取、通信和日志记录。数据库代理程序是一类特殊的 EDU,创建它们是为了处理应用程序对数据库的请求。
通常,您可以依靠 Db2 数据库服务器来管理 EDU 集合。但是,也可以通过一些 Db2 工具来管理 EDU。例如,可以使用带有 -edus 选项的 db2pd 命令来列示所有活动的 EDU 线程。
每个客户机应用程序连接都有一个对数据库执行操作的协调代理程序。协调代理程序代表应用程序工作,并根据需要使用专用内存、进程间通信 (IPC) 或远程通信协议与其他代理程序进行通信。
在 Db2 pureScale® 实例中,这些进程用于监视主机上运行的 Db2 成员和/或集群高速缓存工具 (CF) 的运行状况,以及将集群状态分发至实例中的所有 Db2 成员和 CF。
Db2 体系结构提供了一个防火墙,以使应用程序与 Db2 数据库服务器在不同的地址空间中运行。防火墙将数据库和数据库管理器与应用程序、存储过程和用户定义函数 (UDF) 隔开。此防火墙有助于维护数据库中数据的完整性,这是因为,它将阻止应用程序编程错误覆盖内部缓冲区或数据库管理器文件。此防火墙还提高了可靠性,原因是应用程序错误不会导致数据库管理器崩溃。

客户机程序
客户机程序可以是远程程序,也可以是在数据库服务器所在机器上运行的本地程序。客户机程序首先通过通信侦听器与数据库联系。
侦听器
通信侦听器在 Db2 数据库服务器启动时启动。每种已配置的通信协议都有一个侦听器,本地客户机程序使用进程间通信 (IPC) 侦听器 (db2ipccm)。侦听器包括:
(1)db2ipccm,用于本地客户机连接
(2)db2tcpcm,用于 TCP/IP 连接
(3)db2tcpdm,用于 TCP/IP 发现工具请求
代理程序
将为所有来自本地或远程客户机程序(应用程序)的连接请求分配相应的协调代理程序 (db2agent)。创建协调代理程序之后,它将代表该应用程序执行所有数据库请求。
在分区数据库环境或者已启用查询内并行性的系统中,协调代理程序会将数据库请求分发给子代理程序(db2agntp 和 db2agnts)。与应用程序相关联但当前处于空闲状态的子代理程序名为 db2agnta。
协调代理程序可能:
(1) 已通过别名连接到数据库;例如,db2agent (DATA1) 将连接到数据库别名 DATA1。
(2)已连接到实例;例如 db2agent (user1) 将连接到实例 user1。
Db2 数据库服务器还会将其他类型的代理程序(例如独立的协调代理程序或子协调代理程序)实例化,以便执行特定的操作。例如,独立的协调代理程序 db2agnti 用于运行事件监视器,而子协调代理程序 db2agnsc 用于在异常关闭后以并行方式执行数据库重新启动操作。
网关代理程序 (db2agentg) 是一个与远程数据库相关联的代理程序。它提供用于允许客户机访问主机数据库的间接连接。
空闲代理程序驻留在代理程序池中。这些代理程序可用于处理来自代表客户机程序运行的协调代理程序或来自代表现有协调代理程序运行的子代理程序的请求。当存在大量应用程序工作负载时,配备大小适当的空闲代理程序池有助于提高性能。在这种情况下,可以根据需要立即使用空闲代理程序,而不需要为每个应用程序连接分配新的代理程序,后一种情况涉及创建线程以及分配并初始化内存和其他资源。Db2 数据库服务器自动管理空闲代理池的大小。
可将合用代理程序关联到远程数据库或本地数据库。 在远程数据库上合用的代理程序称为合用网关代理程序 (db2agntgp)。在本地数据库上合用的代理程序称为合用数据库代理程序 (db2agntdp)。
1、db2fmp
受保护方式进程负责在防火墙外执行受防护的存储过程和用户定义函数。db2fmp 进程始终是独立的进程,但可能是多线程进程,这取决于它执行的例程的类型。
2、db2vend
db2vend 进程代表 EDU 执行供应商代码;例如,执行用户出口程序以进行日志归档(仅适用于 UNIX)。
1) 数据库 EDU
以下列表包括每个数据库使用的一些重要 EDU:
- db2cmpd,用于压缩守护程序执行与压缩相关的任务。在分区数据库环境中,db2cmpd EDU 在每个分区上独立运行。
- db2dlock,用于死锁检测。在分区数据库环境中,使用另一个线程 (db2glock) 来协调 db2dlock EDU 从每个分区中收集的信息;db2glock 仅对目录分区运行。在 Db2 pureScale 环境中,db2glock EDU 用于协调 db2dlock EDU 在每个成员上收集的信息。db2glock EDU 在每个成员上启动,但只有一个 EDU 处于活动状态。
- db2fw,事件监视器快速写程序;用于对表、文件或管道进行事件监视器数据的大量、并行写入。
- db2fwx,事件监视器快速写程序线程,其中“x”标识线程号。在数据库激活期间,Db2 引擎会将 db2fwx 线程数目设置为一个值,该值对于事件监视器性能最佳,而且可以避免在运行不同类型的工作负载时发生潜在的性能问题。db2fwx 线程数目等于系统上逻辑 CPU 的数目(对于多核心 CPU,每个核心看作一个逻辑 CPU)。对于 DPF 实例,衍生的 db2fwx 线程数目等于每个数据库的每个成员的逻辑 CPU 数目除以主机上的本地分区数目。
- db2hadrp,高可用性灾难恢复 (HADR) 主服务器线程
- db2hadrs,HADR 备用服务器线程
- db2lfr,用于处理各个日志文件的日志文件阅读器
- db2loggp,用于定期日志工作,例如,确定恢复窗口
- db2loggr,用于处理日志文件以处理事务处理和恢复
- db2loggw,用于将日志记录写入日志文件
- db2loggx,用于高级日志空间管理涉及到的日志抽取。
- db2logmgr,用于日志管理器。管理可恢复数据库的日志文件。
- db2logts,用于跟踪哪些表空间在哪些日志文件中有日志记录。此信息记录在数据库目录中的 DB2TSCHG.HIS 文件中。
- db2lused,用于更新对象用途
- db2mcd,用于管理用于表元数据的内存
- db2pclnr,用于缓冲池页清除程序
- db2pcsd,用于程序包高速缓存的自动清除
- db2pfchr,用于缓冲池预取程序
- db2pkgrb,用于自动重新绑定无效程序包。在数据库目录节点启动期间,db2pkgrb 尝试一次重新绑定每个无效程序包。如果未禁用自动重新验证(即,auto\_reval 数据库配置参数未设置为 DISABLED),那么 db2pkgrb 还将尝试重新绑定每个不可用程序包。之后,它将关闭,直到下次启动。在它即将终止之前,如果它已完成对列表的处理,那么会在 INF 级别将一条摘要消息写入 diag.log。如果这是升级之后第一次尝试重新绑定,那么任何失败重新绑定的详细消息都将在 INF 级别写入 diag.log。对于所有其他启动,只会生成摘要消息。
- db2redom,用于重做主进程。在恢复期间,它处理重做日志记录并将日志记录指定给重做工作程序来进行处理。
- db2redow,用于重做工作程序。在恢复期间,它按照重做主进程的请求来处理重做日志记录。
- db2shred,用于处理日志页中的各个日志记录。
- db2stmm,用于自调整内存管理功能。
- db2taskd,用于分发后台数据库任务。这些任务由名为 db2taskp 的线程执行。
- db2wlmd,用于自动收集工作负载管理统计信息
- 事件监视器线程的标识方式如下:
db2evm%1%2 (%3),其中,%1 可以是:
- g - 全局文件事件监视器
- gp - 全局管道事件监视器
- l - 本地文件事件监视器
- lp - 本地管道事件监视器
- t - 表事件监视器
%2 可以是:
- i - 协调程序
- p - 不是协调程序
- 而 %3 是事件监视器名称
- 备份和复原线程的标识方式如下:
db2bm.%1.%2(备份和复原缓冲区操纵程序)和 db2med.%1.%2(备份和复原介质控制器),其中:
- %1 是用于控制备份或复原会话的代理程序的 EDU 标识
- %2 是用于区分属于特定备份或复原会话的线程(可能有许多个)的顺序值
例如:db2bm.13579.2 标识具有 EDU 标识为 13579 的 db2agent 线程控制的第二个 db2bm 线程。
- 以下数据库 EDU 用于在 Db2 pureScale 环境中锁定:
db2LLMn1,用于处理全局锁定管理器发送的信息;每个成员上有其中两个 EDU;一个用于主 CF,另一个用于辅助 CF
- db2LLMn2,用于处理全局锁定管理器为数据库激活和取消激活期间使用的特别锁定类型发送的信息;每个成员上有其中两个 EDU,一个用于主 CF,另一个用于辅助 CF
- db2LLMng,用于确保此成员挂起的锁定及时释放(如果其他成员在等待这些锁定)
- db2LLMrl,用于处理全局锁定管理器的锁定的释放
- db2LLMrc,用于处理数据库恢复操作及 CF 恢复期间发生的处理
1) 数据库服务器线程和进程
系统控制器(在 UNIX 上为 db2sysc,在 Windows 操作系统上为 db2syscs.exe)必须存在,这样数据库服务器才能工作。以下线程和进程执行各种任务:
- db2acd,用于主管运行状况监视器、自动维护实用程序和管理任务调度程序的自主计算守护程序。此进程以前称为 db2hmon。
- db2aiothr,用于管理数据库分区的异步 I/O 请求(仅适用于 UNIX)
- db2alarm,用于在他们请求的计时器到期时通知 EDU(仅适用于 UNIX)
- db2disp,客户机连接集中器分派器
- db2fcms,快速通信管理器发送方守护程序
- db2fcmr,快速通信管理器接收方守护程序
- db2fmd,故障监视器守护程序
- db2iperiodic,任务调度程序线程。这些任务由名为 db2iperiodicWatch
- db2licc,管理已安装的 Db2 许可证
- db2panic,应急启动代理程序,用于在达到代理程序限制后处理紧急请求。
- db2pdbc,并行系统控制器,用来处理来自远程数据库分区的并行请求(用于分区数据库环境和 Db2 pureScale 环境)
- db2resync,扫描全局再同步列表的再同步代理进程
- db2rocm 和 db2rocme,在 Db2 pureScale 实例中,这些进程监视每台主机上运行的 Db2 成员和集群高速缓存工具 (CF) 的操作状态,并将集群状态信息分发至该实例中的所有 Db2 成员和 CF。
- db2sysc,主系统控制器 EDU;它处理重要的 Db2 服务器事件
- db2sysc(空闲),Db2 空闲进程,它们允许在主机上快速轻量级重新启动访客成员,而不必与常驻成员竞争资源。
- db2thcln,在 EDU 终止时重新启动资源(仅适用于 UNIX)
- db2wdog,在 UNIX 和 Linux® 操作系统上处理异常终止的看守程序。
- db2wlmt,WLM 分派器调度线程
db2wlmtm,WLM 分派器计时器线程
特性
1、具有很好的并行性(DB2把数据库管理扩充到了并行的,多节点的环境;数据库分区是数据库的一部分,包含自己的数据,索引,配置文件和事务日志;数据库分区有时被称为节点)。
2、获得最高认证级别的ISO标准认证。
3、性能较高,适用于数据仓库和在线事物处理。
4、跨平台,多层结构,支持ODBC,JDBC等客户。
5、操作简单,同时提供GUI和命令行,在windowsNT和unix下的操作相同。
6、在巨型企业得到广泛的运用,向下兼容性好,风险小。
7、能够在所有主流平台上运行,最适于海量数据处理。
使用场景
性能较高适用于数据仓库和在线事物处理。DB2 超大型数据库,与ORACLE类似 ,数据仓库和数据挖掘相当的不错,特别是集群技术可以使DB2的可扩性能达到极致。
Access
概述
Microsoft Office Access是由微软发布的关系数据库管理系统。它结合了 MicrosoftJet Database Engine 和 图形用户界面两项特点,是 Microsoft Office 的系统程序之一。
Microsoft Office Access是微软把数据库引擎的图形用户界面和软件开发工具结合在一起的一个数据库管理系统。它是微软OFFICE的一个成员, 在包括专业版和更高版本的office版本里面被单独出售。2018年9月25日,最新的微软Office Access 2019在微软Office 2019里发布。
MS ACCESS以它自己的格式将数据存储在基于Access Jet的数据库引擎里。它还可以直接导入或者链接数据(这些数据存储在其他应用程序和数据库)。
架构
逻辑结构设计阶段的主要工作是将概念模型转换为数据库的一种逻辑模式,即某种特定DBMS所支持的逻辑数据模式。如果采用基于E-R模型的数据库设计方法,该阶段的任务就是将概念结构设计阶段得到的E-R图,转换为与选用的DBMS产品所支持的数据模型相符合的逻辑结构。
通常,E-R模型向关系模型转换是数据库逻辑结构设计的主要步骤。数据库逻辑结构设计的关键是如何构造合适的数据模式。因此,关系数据库逻辑设计的主要任务就是按照规则,将概念设计阶段设计好的独立于具体的DBMS的概念模型,转换为RDBMS产品所支持的一组关系模式,并利用关系数据库理论对这组关系模式进行规范化设计和优化处理,从而得到满足所有数据要求的关系模型。
首先将概念结构转换为一般数据模型;然后将一般数据模型转换为特定DBMS支持下的数据模型;最后对数据模型进行优化。所谓数据模型的优化,就是对得到的初步数据模型进行适当的修改,调整数据模型的结构,以进一步提高数据库应用系统的性能。目前的DBMS产品多是关系型的,对于关系数据库逻辑结构设计的主要步骤就是将E-R图转换为关系模式,然后利用规范化理论对这组关系模式进行修正和优化,相关内容将在第4章和第5章中介绍。

优化数据模型的方法是,首先确定数据依赖,按照需求分析阶段所得到的语义,分别写出每个关系模式内部各属性之间的数据依赖,以及不同关系模式属性之间的数据依赖;接着消除冗余的联系;之后确定每个关系模式所属的范式;最后按照需求分析阶段得到的数据处理要求,分析关系模式是否适合系统的应用环境,如果不适合,还需要对关系模式做进一步分解。
特性
存储方式单一
access管理的对象有表、查询、窗体、报表、页、宏和模块,以上对象都存放在后缀为(.mdb)的数据库文件种,便于用户的操作和管理。
面向对象
access是一个面向对象的开发工具。它将一个应用系统当作是由一系列对象组成的,通过对象的方法、属性完成数据库的操作和管理,极大地简化了开发工作。同时,这种基于面
向对象的开发方式,使得开发应用程序更为简便。
界面友好、易操作
access是一个可视化工具,用户想要生成对象并应用,只要使用鼠标进行拖放即可,非常直观方便。系统还提供了表生成器、查询生成器、报表设计器以及数据库向导、表向导、查询向导、窗体向导、报表向导等工具,使得操作简便,容易使用和掌握。
access可以在一个数据表中嵌入位图、声音、excel表格、word文档,还可以建立动态的数据库报表和窗体等。access还可以将程序应用于网络,并与网络上的动态数据相联接,轻松生成网页。
使用场景
ACCESS,一般做小型网站用,性能一般。ASP+ACCESS最常见的小型网站组合,方便快速。
适合数据量少的应用,在处理少量数据和单机访问的数据库时是很好的,效率也很高。
局限性:access是小型数据库,access数据库不支持并发处理、数据库易被下载存在安全隐患、数据存储量相对较小等。而且在以下几种情况下数据库基本上会吃不消:
1、数据库过大,一般access数据库达到100m左右的时候性能会急剧下降。
2、网站访问频繁,经常达到100人左右的在线。
3、记录数过多,一般记录数达到10万条左右的时候性能就会急剧下降。
Mysql
概述
MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),使用最常用的数据库管理语言--结构化查询语言(SQL)进行数据库管理。MySQL是开放源代码的,因此任何人都可以在General Public License的许可下下载并根据个性化的需要对其进行修改。MySQL因为其速度、可靠性和适应性而备受关注。大多数人都认为在不需要事务化处理的情况下,MySQL是管理内容最好的选择。
架构
体系结构

由图,可以看出MySQL最上层是连接组件。下面服务器是由连接池、管理工具和服务、SQL接口、解析器、优化器、缓存、存储引擎、文件系统组成。
1、连接池:由于每次建立建立需要消耗很多时间,连接池的作用就是将这些连接缓存下来,下次可以直接用已经建立好的连接,提升服务器性能。
2、管理工具和服务:系统管理和控制工具,例如备份恢复、Mysql复制、集群等。
3、SQL接口:接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface。
4、解析器: SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本, 主要功能:将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的。如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的。
5、优化器:查询优化器,SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。用一个例子就可以理解:select uid,name from user where gender = 1。首先,这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤;然后,这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤;最后,将这两个查询条件联接起来生成最终查询结果
6、缓存器: 查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。通过LRU算法将数据的冷端溢出,未来得及时刷新到磁盘的数据页,叫脏页。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等。
存储结构
MySQL的数据存储结构主要分两个方面:物理存储结构与内存存储结构,作为数据库,所有的数据最后一定要落到磁盘上,才能完成持久化的存储。内存结构为了实现提升数据库整体性能,主要用于存储临时数据和日志的缓冲。本文主要讲MySQL的物理结构,以及MySQL的内存结构,对于存储引擎也主要以InnoDB为主。

上图的 On-Disk Structures 主要是InnoDB存储引擎的磁盘结构,对于MySQL数据库来说,还包括一些文件、日志、表结构存储结构等。
文件主要包括参数文件、日志文件、表结构文件、存储引擎文件等,存储引擎文件主要包括表空间文件、redo log等。
参数文件指的是MySQL实例启动时,会先去读取的参数配置文件,配置内容包含各种文件的位置,一些初始化参数,这些参数定义了某种内存结构的大小设置,还包括一些其他配置,如:主从配置等。
日志文件记录了MySQL数据库的各种类型活动,这些日志都是在Server层实现的,是各种存储引擎都会有的日志文件。包括错误日志、binlog、慢查询日志、查询日志:
错误日志主要用于查看MySQL出现错误时,用来排查问题使用,是DBA出问题时,首要关注的日志。
慢查询日志是用来记录低于阈值的SQL语句,这个阈值通过long\_query\_time设置,默认是10秒,通过查询慢查询日志,也可以得到一些关于数据库需要优化的信息,比如需要某个语句执行扫描了全表,没有走到索引。开发人员可以结合场景去优化SQL语句或者优化索引的设置等。
查询日志记录了所有对MySQL数据库请求的信息,不论这些请求是否得到了正确的执行。
binlog是server层维护的一种二进制日志,与后面要说的InnoDB存储引擎层的redo log不同,主要用来记录对MySQL数据更新或潜在发生更新的SQL语句,不包括Select和Show这类操作。binlog默认是不开启的,测试表明开启确实会影响MySQL的性能。不过通过binlog可以实现数据的备份同步和数据恢复,同这么强大的作用比起来,损失这点性能也是值得的,所以建议开启。
当使用支持事务的存储引擎时,未提交事务的binlog会存储到binlog\_cache中,而提交的事务,要根据参数来确定从缓冲刷到磁盘的时间。
内存结构
InnoDB存储引擎使用Buffer Pool在内存中缓存表数据和索引,处理数据时可以直接操作缓冲池的数据,提升InnoDB的处理速度。缓冲池的数据一般按照页格式,每个页包含多行数据,缓冲池可以看成是页面链表,并且使用LRU(last recent used)算法,来管理缓冲池的数据列表。当需要新空间将新页面加到缓冲池时,将会淘汰最近最少使用的数据。
MySQL提供了多个关于缓冲池的配置参数:
innodb\_buffer\_pool\_instances与innodb\_buffer\_pool\_size 配置缓冲池的实例和缓冲池大小:通过配置多个缓冲池可以减少不同线程的竞争,提升并发度。通常在专用服务器上,80%的物理内存会分配给Buffer Pool。
1、innodb\_buffer\_pool\_chunk\_size配置缓冲池的块大小:当增加或减少innodb\_buffer\_pool\_size时,操作以块形式执行,块大小由此参数决定,默认为128M。
2、innodb\_max\_dirty\_pages\_pct 配置脏页比例:根据设置的缓冲池中脏页比例,来触发将脏页刷盘的时机。另外,InnoDB也根据redo log的生成速度和刷新频率,来触发刷盘时机。
3、innodb\_read\_ahead\_threshold 与 innodb\_random\_read\_ahead 预读参数配置:预读是指一次I/O请求磁盘中某页中的数据时,会同时同步取出相邻页面的数据,缓存到缓冲池。因为,InnoDB认为这些页面的数据大概率也将会被读取,从而来提升I/O性能。包括线性预读和随机预读。
Change Buffer
用来缓存不在缓冲池中的辅助索引页(非唯一索引)的变更。这些缓存的的变更,可能由INSERT、UPDATE或DELETE操作产生,当读操作将这些变更的页从磁盘载入缓冲池时,InnoDB引擎会将change buffer中缓存的变更跟载入的辅助索引页合并。
不像聚簇索引,辅助索引通常不是唯一的,并且辅助索引的插入顺序是相对随机的。若不用change buffer,那么每有一个页产生变更,都要进行I/O操作来合并变更。使用change buffer可以先将辅助索引页的变更缓存起来,当这些变更的页被其他操作载入缓冲池时再执行merge操作,这样可以减少大量的随机I/O。change buffer可能缓存了一个页内的多条记录的变更,这样可以将多次I/O操作减少至一次。
在内存中,change buffer占据缓冲池的一部分。在磁盘上,change buffer是系统表空间的一部分,以便数据库重启后缓存的索引变更可以继续被缓存
自适应哈希索引
自适应哈希索引是InnoDB表通过在内存中构造一个哈希索引来加速查询的优化技术,此优化只针对使用 '=' 和 'IN' 运算符的查询。MySQL会监视InnoDB表的索引查找,若能通过构造哈希索引来提高效率,那么InnoDB会自动为经常访问的辅助索引页建立哈希索引。
这个哈希索引总是基于辅助索引(B+树结构)来构造。MySQL通过索引键的任意长度的前缀和索引的访问模式来构造哈希索引。InnoDB只为某些热点页构建哈希索引。
Log Buffe
Log Buffer用来缓存要写入磁盘日志文件的内存缓冲区域,该区域大小由 innodb\_log\_buffer\_size 参数定义,默认16MB。
Doublewrite Buffer
位于系统表空间中的存储区域,其工作原理是:在将缓冲池中的页写入磁盘上对应位置之前,先将缓冲池中的页copy到内存中的doublewrite buffer,之后再分两次,每次1M,顺序地将内存中doublewrite buffer中的页写入系统表空间中的doublewrite区域,然后立即调用系统fsync函数,同步数据到磁盘文件中,避免缓冲写带来的问题。在完成doublewrite页的写入之后,再将内存上doublewrite buffer中的页写入到自己的表空间文件。如果当页面写入磁盘时,发生了数据库宕机,会导致“写失效”,重启之后,可以通过Doublewrite Buffer来恢复故障前要写的Page数据。

InnoDB存储引擎支持事务、MVCC、故障恢复等特性,要理解InnoDB的存储结构,关键点如下:
1、磁盘I/O,磁盘的读写是操作系统实现的,结合磁盘存取数据的过程,来看InnoDB的逻辑存储结构,在磁盘和内存中都以页(Page)为操作的基本单元,页内元素才是基本的行结构数据;
2、基于B+ Tree结构来组织数据的存储,叶节点和非叶节点存储数据和索引,并且通过主键构建整个树结构,便于通过主键索引遍历数据;
3、二阶段提交、undo log等机制完善InnoDB事务的特性;
4、缓冲池、索引等机制的引入提升MySQL性能;
5、由redo log、binlog、错误日志来实现数据库故障恢复、备份和异常情况的记录。
特性
1、使用核心线程的完全多线程。这意味着它能很容易地利用多CPU(如果有)。
2、支持C、C++、Eiffel、Java、Perl、PHP、Python、和TCL API等客户工具和API。
3、可运行在不同操作系统平台上。
4、支持多种列类型:1、2、3、4、和 8 字节长度的有符号/无符号整数、FLOAT、DOUBLE、CHAR、VARCHAR、TEXT、BLOB、DATE、TIME、DATETIME、 TIMESTAMP、YEAR、SET和ENUM类型。
5、利用一个优化的一遍扫描多重联结(one-sweep multi-join)非常快速地进行联结(join)。
6、在查询的SELECT和WHERE部分支持全部运算符和函数,例如:
mysql> SELECT CONCAT(first\_name, " ", last\_name) FROM tbl\_name
WHERE income/dependents > 10000 AND age > 30;
7、通过一个高度优化的类库实现SQL函数库并且像他们能达到的一样快速,通常在查询初始化后不应该有任何内存分配。
8、全面支持SQL的GROUP BY和ORDER BY子句,支持聚合函数( COUNT()、COUNT(DISTINCT)、AVG()、STD()、SUM()、MAX()和MIN() )。
9、支持ANSI SQL的LEFT OUTER JOIN和ODBC语法,你可以在同一查询中混用来自不同数据库的表。
10、一个非常灵活且安全的权限和口令系统,并且它允许基于主机的认证。口令是安全的,因为当与一个服务器连接时,所有的口令传送被加密。
11、ODBC for Windiws 95。所有的 ODBC 2 . 5 函数和其他许多函数。例如,你可以用Access连接你的 MySQL服务器,具备索引压缩的快速B树磁盘表。
12、每个表允许有16个索引。每个索引可以由1~16个列或列的一部分组成。最大索引长度是 256个字节(在编译MySQL时,它可以改变)。一个索引可以使用一个CHAR或VARCHAR字段的前缀。
13、定长和变长记录。用作临时表的内存散列表。
14、大数据库处理。我们正在对某些包含50,000,000个记录的数据库使用MySQL。
15、所有列都有缺省值,你可以用INSERT插入一个表列的子集,那些没用明确给定值的列设置为他们的缺省值。为了可移植性使用GNU Automake , Autoconf 和libtool。
16、用C和C++编写,并用大量不同的编译器测试,一个非常快速的基于线程的内存分配系统。
17、全面支持ISO-8859-1 Latin-1字符集。例如,斯堪的纳维亚的字符 @ringaccent{a}, @"a and @"o 在表和列名字被允许。
18、表和列的别名符合SQL92标准。
19、函数名不会与表或列名冲突。例如ABS是一个有效的列名字。
20客户端使用TCP/IP 连接或Unix套接字(socket)或NT下的命名管道连接MySQL。
21、MySQL特有的SHOW命令可用来检索数据库、表和索引的信息,EXPLAIN命令可用来确定优化器如何解决一个查询。
使用场景
Web网站系统
Web 网站开发者是 MySQL 最大的客户群,也是 MySQL 发展史上最为重要的支撑力量。
日志记录系统
MySQL 数据库的插入和查询性能都非常的高效,如果设计的好,在使用 MyISAM 存储引擎的时候,两者可以做到互不锁定,达到很高的并发性能。所以,对需要大量的插入和查询日志记录的系统来说,MySQL 是非常不错的选择。比如处理用户的登录日志,操作日志等,都是非常适合的应用场景。
数据仓库系统
由于mysql高效的查询性能和可操作性,因此在数据仓库的建立当中,mysql往往继续充当上层应用的数据库接口,用来存储经过层层筛选和统计后的数据。
嵌入式系统
嵌入式环境对软件系统最大的限制是硬件资源非常有限,在嵌入式环境下运行的软件系统,必须是轻量级低消耗的软件。MySQL 在资源的使用方面的伸缩性非常大,可以在资源非常充裕的环境下运行,也可以在资源非常少的环境下正常运行。它对于嵌入式环境来说,是一种非常合适的数据库系统,而且 MySQL 有专门针对于嵌入式环境的版本。
局限性:缺乏一些存储程序的功能,比如MyISAM引擎联支持交换功能; 使用缺省的ip端口,但是有时候这些ip也会被一些黑客闯入;使用myisam配置,如果你不慎损坏数据库,结果可能会导致所有的数据丢失。
MariaDB
概述
MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。在存储引擎方面,使用XtraDB(英语:XtraDB)来代替MySQL的InnoDB。 MariaDB由MySQL的创始人Michael Widenius(英语:Michael Widenius)主导开发,他早前曾以10亿美元的价格,将自己创建的公司MySQL AB卖给了SUN,此后,随着SUN被甲骨文收购,MySQL的所有权也落入Oracle的手中。MariaDB名称来自Michael Widenius的女儿Maria的名字。
架构

当Mariadb接受到Sql语句时,其详细的执行过程如下:
1、当客户端连接到 mariadb 的时候,会认证客户端的主机名,用户,密码,认证功能可以做成插件。
2、如果登录成功,客户端发送 sql 命令到服务端。
3、由解析器解析 sql 语句。
4、服务端检查客户端是否有权限去获取它想要的资源。
5、如果查询已经存储在 query cache 当中,那么结果立即返回。
6、优化器将会找出最快的执行策略,或者是执行计划,也就是说优化器可以决定什么表将会被读,以及哪些索引会被访问,哪些临时表会被使用,一个好的策略能够减少大量的磁盘访问和排序操作等。
7、存储引擎读写数据和索引文件,cache 用来加速这些操作,其他的诸如事物和外键特性,都是在存储引擎层处理的。
特性
MariaDB可用于GPL,LGPL和BSD。它包括广泛的存储引擎选择,包括高性能存储引擎,用于与其他关系数据库管理系统(RDBMS)数据源一起工作。它使用标准和流行的查询语言。MariaDB在许多操作系统上运行,并支持各种编程语言。MariaDB还提供了很多在MySQL中不可用的操作和命令,并消除、取代了对性能产生负面影响的功能。其他功能还包括多源复制,融合IO 优化,表发现和联机更改表。
MariaDB拥有大量新功能,这使得它在性能和用户导向方面更加出色。以下是Mysql和MariaDB之间的一些重要差异:
1、MariaDB针对性能进行了优化,性能比MySQL强大得多。
2、MariaDB保存了和Mysql相同的数据结构,从其他数据库系统可以很方便的迁移到MariaDB数据库。
3、MariaDB通过引入微妙级精度和扩展用户统计数据提供更好的监控。
4、MariaDB为与磁盘访问,连接诶操作,子查询,派生表和视图,执行控制甚至解释语句相关的查询应用了许多查询优化。
5、MariaDB是完全开源的,而不是MySQL使用的双重授权模式。一些仅适用于Mysql Enterprise客户的插件在MariaDB中具有等效的开源实现。
6、MariaDB支持更多的引擎(SphinxSE,Aria,FederatedX,TokuDB,Spider,ScaleDB等)。
7、MariaDB提供了一个用于商业用途的集群数据库,同时也支持多主复制。任何人都可以自由使用它,并且不需要依赖MySQL Enterprise系统。
使用场景
MariaDB可以应用到所有mysql数据库可应用到的场景。详情可参照mysql使用场景。
局限性:从版本5.5.36开始,MariaDB无法迁移回Mysql.对于MariaDB的新版本,相应的库(用于Debian)不会及时部署,由于依赖关系,这将导致必须升级到较新的版本。MariaDB的集群版本不是很稳定。
Vfp
概述
Visual FoxPro简称VFP,是Microsoft公司推出的数据库开发软件,用它来开发数据库,既简单又方便。Visual FoxPro源于美国Fox Software公司推出的数据库产品FoxBase,在DOS上运行,与xBase系列相容。FoxPro原来是FoxBase的加强版,最高版本曾出过2.6。之后,Fox Software被微软收购,加以发展, 使其可以在 Windows 上运行, 并且更名为 Visual FoxPro。
特性
具有程序设计功能与数据库管理功能
VFP为用户提供了程序设计语言功能,与数据库操作命令相结合。可用于大量数据的分类、计算、组合及其他处理。并且本身即有功能齐全的宿主语言,可用于设计开发数据库应用系统软件或者其它计算机科学计算程序。
支持可视化程序设计
为用户提供了可视化程序设计功能,应用系统提供的各种导向、设计器、生成器、菜单、对话框、控件等工具,即可方便制作程序界面,设计出Windows风格的应用程序。
支持面向对象的程序设计
VFP提供面向对象程序设计架构,支持Define Class定义类的方法,利用表单、类设计器能够直观地实现类及其派生对象的设计、存储、调用。能够很好的实现对象的集成与封装。
具有丰富的数据库连接功能
VFP提供远程视图功能,SQL pass through 技术、Cursor adapter类,应用这些功能,可以与大型数据库,如:SQL Server,Oracle建立连接,从而设计基于C/S 模式的数据库应用系统。
支持Web Service技术
VFP提供了将数据文件讲过XSL样式语言转换为能够在浏览器上显示的XML文档的功能,从而提供丰富的Web服务。
使用场景
VFP数据库是一款相对较老的数据库系统,无论从可操作性,稳定性,可扩展性还是对数据的查询上都无法和当今主流的关系型数据库相聘美。在当前的各个行业中已经很少有人使用。其主要应用于以前老式的单机桌面程序和C/S(客户机/服务器)型的网络程序。
局限性:已经不适合当前发展较快的互联网行业以及传统行业对数据存储管理的需求。
Ingres
概述
Ingres是比较早的数据库系统,开始于加利福尼亚大学柏克莱分校的一个研究项目,该项目开始于 70 年代早期,在 80 年代早期结束。像柏克莱大学的其他研究项目一样,它的代码使用BSD 许可证。从 80 年代中期,在Ingres 基础上产生了很多商业数据库软件,包括 Sybase, Microsoft SQL Server, NonStop SQL, Informix 和许多其他的系统。在 80 年代中期启动的后继项目 Postgres ,产生了 PostgreSQL, Illustra,无论从任何意义上来说,Ingres 都是历史上最有影响的计算机研究项目之一。
特性
高可用性
Ingres r3包含集群软件,当集群配置中的一个数据库或服务器节点出现故障时,仍能保证服务的不中断性。在预防系统故障的同时,Ingres r3还提供“缩放自如”的功能,让用户把众多低成本的服务器连结起来. 以强化信息处理的性能。
可扩展性和可靠性
Ingres通过并行查询处理将单个查询细分为多个组件,利用所有现有资源并行处理 这些组件,从而提供可伸缩性能。同时,Ingres支持Oracle Cluster File System(OCFS)for Linux 和IBM Distributed Lock Manager(OpenDLM ),为用户提供全新的群集功能,获得所需的可扩展性和可靠性。
技术与性能
Ingres是第一个以Zope RDBMS Persistence引擎为基础的初始数据库(Initial Database),其表分区和索引功能满足超大型数据库部署的需求。
集成性
Ingres可以在异构环境中与其它应用程序和数据进行无缝集成。随着Linux在 企业IT环境中的渐趋流行,这一集成功能尤为重要。其易于集成的特点使它能够与多种应用开发工具一起使用。此外,Ingres使用行业标准的连接选件,支 持开发人员在J2EE框架、.NET环境,或者同时在两个环境下工作,特别适用于嵌入式应用。
服务
CA 公司将为Ingres r3提供支持和保障服务, 同时CA技术服务中心还提供多种可定制的培训课程和服务,包括现场培训或远程培训,这些培训和服务可以帮助客户更加有效地利用Ingres r3的特性。
使用场景
Ingres数据库是很多商业关系数据库发展的前身。为后来的数据库发展提供了借鉴,但是其在商业化的发展道路上并没有走很远。逐渐被其他数据库软件所取代。目前市场上几乎看不到该数据库的使用,Ingres数据库只是早期数据库发展探索过程中的奠基石。
PostGreSQL
概述
PostgreSQL是一种特性非常齐全的自由软件的对象-关系型数据库管理系统(ORDBMS),是以加州大学计算机系开发的POSTGRES 4.2版本为基础的对象关系型数据库管理系统。POSTGRES的许多领先概念只是在比较迟的时候才出现在商业网站数据库中。PostgreSQL支持大部分的SQL标准并且提供了很多其他现代特性,如复杂查询、外键、触发器、视图、事务完整性、多版本并发控制等。同样,PostgreSQL也可以用许多方法扩展,例如通过增加新的数据类型、函数、操作符、聚集函数、索引方法、过程语言等。另外,因为许可证的灵活,任何人都可以以任何目的免费使用、修改和分发PostgreSQL。
架构
体系结构
PostgreSQL数据库由连接管理系统(系统控制器)、编译执行系统、存储管理系统、事务系统、系统表五大部分组成,其组成结构和关系如图所示。

连接管理系统接受外部操作对系统的请求,对操作请求进行预处理和分发,起系统逻辑控制作用;
编译执行系统由查询编译器、查询执行器组成,完成操作请求在数据库中的分析处理和转化工作,最终实现物理存储介质中数据的操作;
存储管理系统由索引管理器、内存管理器、外存管理器组成,负责存储和管理物理数据,提供对编译查询系统的支持;
事务系统由事务管理器、日志管理器、并发控制、锁管理器组成,日志管理器和事务管理器完成对操作请求处理的事务一致性支持,锁管理器和并发控制提供对并发访问数据的一致性支持;
系统表是PostgreSQL数据库的元信息管理中心,包括数据库对象信息和数据库管理控制信息。系统表管理元数据信息,将PostgreSQL数据库的各个模块有机地连接在一起,形成一个高效的数据管理系统。
存储结构
数据库的文件默认保存在initdb时创建的数据库目录中。
| 目录 | 用途 |
|---|---|
| base | 包含每个数据库对应的子目录的子目录 |
| 文件 | 用途 |
| PG\_VERSION | Postgresql主版本号文件 |
| pg\_hba.conf | 客户端认证控制文件 |
| postgresql.conf | 参数文件 |
数据库本身也是数据库对象,一个数据库集簇可以包含多个Database、多个User。每个Database以及Database中的所有对象都有他们的所有者即user。

创建一个Database时会为这个Database创建一个名为public的默认Schema。每个Database可以有多个Schema。 可以将schema理解为名称空间。不同的schema可以有相同的Table、index、view等。
特性
PostgreSQL 是世界上可以获得的最先进的开放源码的数据库系统,它提供了多版本并行控制,支持几乎所有SQL构件(包括子查询、事务和用户定义类型和函数),并且可以获得非常广阔范围的(开发)语言绑定(包括 C、C++、Java、perl、tcl和python)。具体的优点特性如下:
1、PostgreSQL 的特性覆盖了 SQL-2/SQL-92 和 SQL-3/SQL-99,是目前世界上支持最丰富的数据类型的数据库。
2、PostgreSQL 是全功能的自由软件数据库,PostgreSQL 是唯一支持事务、子查询、多版本并行控制系统、数据完整性检查等特性的唯一的一种自由软件的数据库管理系统。
3、PostgreSQL 采用的是比较经典的 C/S (client/server)结构,也就是一个客户端对应一个服务器端守护进程的模式,这个守护进程分析客户端来的查询请求,生成规划树,进行数据检索并最终把结果格式化输出后返回给客户端。
4、PostgreSQL 对接口的支持也是非常丰富的,几乎支持所有类型的数据库客户端接口。
使用场景
1.企业数据库
如 ERP、交易系统、财务系统涉及资金、客户等信息,数据不能丢失且业务逻辑复杂,选择 PostgreSQL 作为数据底层存储,一是可以帮助您在数据一致性前提下提供高可用性,二是可以用简单的编程实现复杂的业务逻辑。
2.含 LBS 的应用
大型游戏、O2O 等应用需要支持世界地图、附近的商家,两个点的距离等能力,PostGIS 增加了对地理对象的支持,允许您以 SQL 运行位置查询,而不需要复杂的编码,帮助您更轻松理顺逻辑,更便捷的实现 LBS,提高用户粘性。
3.数据仓库和大数据
PostgreSQL 更多数据类型和强大的计算能力,能够帮助您更简单搭建数据库仓库或大数据分析平台,为企业运营加分。
4.建站或 App
PostgreSQL 良好的性能和强大的功能,可以有效的提高网站性能,降低开发难度。
Kingbase es(金仓)
概述
KingbaseES 是北京人大金仓信息技术股份有限公司研发的,具有自主知识产权的通用数据库产品。该产品面向事务处理类应用,兼顾各类数据分析类应用,可用做管理信息系统、业务及生产系统、决策支持系统、多维数据分析、全文检索、地理信息系统、图片搜索等的承载数据库。
KingbaseES 汇集了人大金仓在数据库领域近二十年的技术积累,包括公司在国家“核高基”重大专项数据库课题的研究成果,是唯一入选国家自主创新产品目录的数据库产品,已广泛适用于电子政务、军工、电力、金融、电信、教育及交通等行业,是国家级、省部级项目中应用最广泛的国产数据库产品。
架构
体系结构

最底层是存储管理层,主要实现数据存储管理、数据复制、数据完整性保护、封锁、并发控制、 事务管理、缓存管理、日志空间管理等;存储层之上是SQL处理层,主要负责SQL接口底层(函 数、索引、数据字典、存储过程、触发器)的实现、解析、优化、执行和缓存处理等SQL处理层 之上是传输层,主要实现基于SSL的可信传输。传输层之上为接口层, (ODBC/JDBC/ESQL/PERL/PHP/MYBATIS/HIBERNATE/.NET/EF6)及其驱动程序实现;最上面是工具层,提供给管理员大量便捷高效的数据库管理工具和开发工具。KingbaseES的安全防护手段和策略贯穿以上各个层次,提供特权分立、访问控制、存储加密等 多种安全组件和功能,为数据库管理系统提供内核级的层层安全防护。
逻辑功能架构如下所示。
在数据库术语里,KingbaseES使用客户端/服务器的模型。一次KingbaseES会话由下列相关的 进程组成:一个服务器进程,它管理数据库文件、接受来自客户端应用与数据库的联接并且代表客户端在 数据库上执行操作。该数据库服务器程序叫做kingbase。那些需要执行数据库操作的用户的客户端(前端)应用。客户端应用可能本身就是多种多样的:可以是一个面向文本的工具,也可以是一个图形界面的应用,或者是一个通过访问数据库 来显示网页的网页服务器,或者是一个特制的数据库管理工具。一些客户端应用是和 KingbaseES发布一起提供的,但绝大部分是用户开发的。和典型的客户端/服务器应用(C/S应用)一样,这些客户端和服务器可以在不同的主机上。这时 它们通过 TCP/IP 网络连接通讯。请注意,在客户机上可以访问的文件未必能够在数据库服务器 机器上访问(或者只能用不同的文件名进行访问)。 KingbaseES服务器可以处理来自客户端的多个并发请求。因此,它为每个连接启动("forks")一个新的进程。从这个时候开始,客户端和新服务器进程就不再经过最初的 kingbase进程的干 涉进行通讯。因此,主服务器进程总是在运行并等待着客户端联接, 而客户端和相关联的服务器 进程则是起起停停。
实例结构
KingbaseES 数据库管理系统,由数据库文件和 KingbaseES 实例组成。
数据库文件
数据库文件为存储用户数据以及元数据的一组磁盘文件。 元数据为描述数据库结构、配置和控制有关的信息。
KingbaseES实例
包含若干对存储的数据进行操作的数据库服务进程,还包括分配和管理内存,统计各种信息, 以及实现各种协调工作的后台进程。一台设备上,可以同时运行多个实例。
实例注册成实例服务后,会有唯一的名字标志一个实例。
一个 KingbaseES实例在操作系统上表现为一个KingbaseES进程,它可以由控制器启动,也可以单独用命令行启动。
一个 KingbaseES实例管理多个逻辑上的数据库。启动一个 KingbaseES 实例后,使用客户端可以访问到这个实例管理的任意一个数据库。
KingbaseES 实例的结构以及和数据库文件的关系可以表示为:
以下是 KingbaseES 实例的详细介绍。
数据库服务进程的多进程结构:
KingbaseES 数据库服务进程,称该进程为一个“KingbaseES 数据库实例”。 在一个数据目录只能同时启动一个实例,不同的数据目录可以同时以不同的端口,手动启动为 不同的实例。 KingbaseES 实例采用多进程架构,因此一个实例中会包含多个进程。这些进程按照功能的不 同可以分为后台进程和服务进程两类:
1、后台进程
(1)KingbaseES主进程
主进程负责统一管理各服务进程和其他后台进程。 该进程负责启动服务进程和其他后台进程,并且在子进程退出的时候做清理工作。 该进程负责分发来自操作系统的信号到各子进程。系统退出时,主进程负责发送信号通 知各子进程退出,然后再停止自己。
(2)后台写进程
在这个进程中,共享缓冲池上的脏页会逐渐定期地写入持久存储(例如HDD、SSD)。
(3)检查点进程
用来执行检查点过程。
(4)自动vacuum进程
会定期地在服务器上执行vacuum。
(5)WAL日志写进程
这个进程周期性地将WAL缓冲区上的WAL数据写入和刷新到持久存储。
(6)统计进程
在此进程中,会收集sys\_stat\_activity和sys\_stat\_database等统计信息。
(7)日志写进程
写日志线程负责将日志缓冲区中的日志页面写出到日志文件中。
(8)归档进程
归档进程负责将日志文件归档到指定的位置。
2、服务进程
对于每个客户端的连接,KingbaseES主进程接收到客户端连接后,会为其创建一个新的服务进程。
该进程负责实际处理客户端的数据库请求,连接断开时退出。
存储结构
在传统上,数据库集簇所使用的配置和数据文件都被一起存储在集簇的数据目录里,一个常用的目录名为 data。由不同数据库实例所管理的多个集簇可以在同一台机器上共存。 data目录包含几个子目录以及一些控制文件,如下表所示。除了这些必要的东西之外,kingbase.conf、sys\_hba.conf和sys\_ident.conf通常都存储在data中,不过可以把它们放在别的地方。
特性
作为 KingbaseES 产品系列最新一代版本,KingbaseES V8R2 在系统的可靠性、可用性、性能和兼容性等方面进行了重大改进,它包括以下主要技术特性:
高度容错,稳定可靠
针对企业级关键业务应用的可持续服务需求,KingbaseES V8R2 提供可在电力、金融、电信等核心业务系统中久经考验的容错功能体系,通过如数据备份、恢复、同步复制、多数据副本等高可用技术,确保数据库 7×24 小时不间断服务,实现 99.999%的系统可用性。
应用迁移,简单高效
针对从异构数据库将应用迁移到 KingbaseES 的场景,KingbaseES V8R2 一方面通过智能便捷的数据迁移工具,实现无损、快速数据迁移;另一方面,KingbaseES V8R2 还提供高度符合标准(如 SQL、ODBC、JDBC 等)、并兼容主流数据库(如 Oracle、SQL Server、MySQL等)语法的服务器端、客户端应用开发接口,可最大限度地降低迁移成本。
人性设计,简单易用
KingbaseES V8R2 版本提供了全新设计的集成开发环境(IDE)和集成管理平台,能有效降低数据库开发人员和管理人员的使用成本,提高开发和管理效率。
性能强劲,扩展性强
针对企业业务增长带来的数据库并发处理压力,该版本提供了包括并行计算、索引覆盖等技术在内的多种性能优化手段,此外提供了基于读写分离的负载均衡技术,让企业能从容应对高负载大并发的业务。
使用场景
人大金仓数据库作为另一款成熟的国产数据库产品,目前已经广泛应用到了很多政府,通信和金融行业。例如中共中央办公厅,网信办,发改委,审计署,海洋局,卫生部,国家电网,中国电信,光大银行等机构部门。
DM(达梦)
概述
达梦数据库管理系统是达梦公司推出的具有完全自主知识产权的高性能数据库管理系统,简称DM。达梦数据库管理系统的最新版本是8.0版本,简称DM8。
DM8是达梦公司在总结DM系列产品研发与应用经验的基础上,坚持开放创新、简洁实用的理念,历经五年匠心打磨,推出的新一代自研数据库。
DM8吸收借鉴当前先进新技术思想与主流数据库产品的优点,融合了分布式、弹性计算与云计算的优势,对灵活性、易用性、可靠性、高安全性等方面进行了大规模改进,多样化架构充分满足不同场景需求,支持超大规模并发事务处理和事务-分析混合型业务处理,动态分配计算资源,实现更精细化的资源利用、更低成本的投入。一个数据库,满足用户多种需求,让用户能更加专注于业务发展。
架构
体系结构
达梦数据库体系结构有数据库和实例组成。
1、数据库
DM 数据库指的是磁盘上存放在DM 数据库中的数据的集合
2、实例
实例一般是由一组正在运行的DM 后台进程/线程以及一个大型的共享内存组成
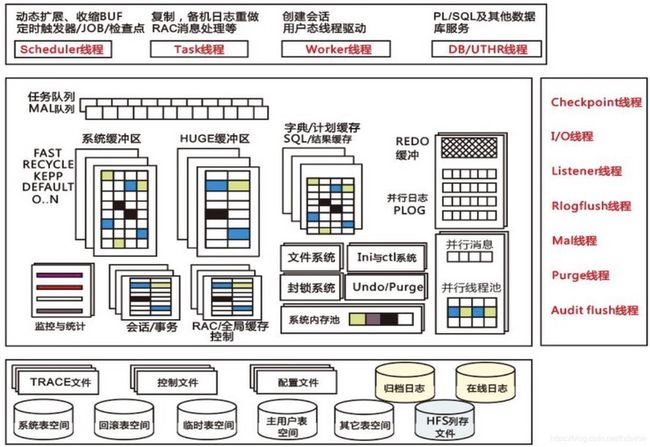
存储结构

1、物理结构

2、逻辑结构
一个表空间中包括一个或多个数据文件,一个数据文件仅于一个表空间。段存在于表空间,段由簇的集合构成,簇是数据块的集合,数据块会映射到磁盘块。

内存结构
共用内存池
不依赖于操作系统的内存管理,主要用于:
1、维护系统内部内存空间的分配与释放
2、减少对操作系统内存的系统调用
3、其大小由MEMORY\_POOL参数确定
系统缓冲区

字典缓冲区
1、快速访问表,视图等对象的描述
2、系统表到内存对象的映射
3、仅保留活动的数据库对象
4、采用LRU算法淘汰
5、大小由DICT\_BUF\_SIZE参数决定
日志缓冲区
日志缓存区存放重做日志的内存缓冲区。
1、大小由LOG\_BUF\_SIZE参数决定
2、单位为页数量,默认为256页
3、大小必须为2 的N 次方
排序/散列缓冲区
1、排序缓冲区,数据排序的内存缓冲区。大小由SORT\_BUF\_SIZE参数决定。
2、散列缓冲区,哈希连接的内存缓冲区。大小由HJ\_BUF\_SIZE参数决定。
3、SQL缓冲区,缓存执行计划、SQL语句、SQL结果集。USE\_PLN\_POOL参数为1或2时启用,大小由CACHE\_POOL\_SIZE参数决定。
特性
高性能
DM8采用多趟扫描、代价估算的优化策略,支持查询计划的HINT功能,可供经验丰富的DBA对特定查询进行优化改进,进一步提高查询的效率和灵活性。
DM8提供查询计划的重用,可以减少重复分析操作,有效提升语句的执行效率。DM8采用参数化常量方法,使得常量值不同的查询语句,同样可以重用查询计划。
DM8提供查询结果集缓存策略,在服务器端实现结果集缓存,可以在提升查询速度的同时,保证缓存结果的实时性和正确性。
DM8采用更加有效的异步检查点机制,相对原有检查点长时间占用缓冲区的策略相比,逻辑更加简单,速度更快,对整体系统运行影响更小。
DM8采用多版本并发控制技术,使得查询与更新操作间互不干扰,有效提高了高并发应用场景中的执行效率。
DM8中实现了数据字典缓存技术,执行期间不必封锁整个数据字典,可以有效降低DDL操作对整体系统并发执行的影响。
DM8为具有多个处理器 (CPU) 的计算机提供了并行查询,以优化查询执行和索引操作。并行查询其优势就是可以通过多个线程来处理查询作业,从而提高查询的效率。
DM8数据压缩采用智能压缩策略,自动选择最合适的压缩算法进行数据压缩,可以显著提升数据的压缩比,进一步减少系统的空间资源开销。
DM8同时支持行存储引擎与列存储引擎,可实现事务内对行存储表与列存储表的同时访问,可同时适用于联机事务和分析处理。
DM8提供 OLAP 函数,用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以直观易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业的经营状况,了解被服务对象的需求,制定正确的方案。
DM8采用完全对等无共享(share-nothing)的MPP架构,支持SQL并行处理,可自动化分区数据和并行查询,无I/O冲突。DM8 MPP为新一代数据仓库所需的大规模数据和复杂查询提供了先进的软件级解决方案,具有业界先进的架构和高度的可靠性。
高可用性
DM8可以提供数据库或整个服务器的冷/热备份以及对应的还原功能,达到数据库数据保护和迁移。支持的备份类型包括物理备份、逻辑备份,可实现全库、表空间、B树3个级别的备份。支持增量备份,支持以检查点进行还原。
DM8提供事务级的同步复制和异步复制功能。DM8数据复制功能支持一到多、多到一、级联复制、多主多从复制、环形复制、对称复制以及大数据对象复制。
主备系统是DM8提高容灾能力的重要手段。系统由一台主机与一或多台备机构成。主机提供正常的数据处理服务,备机则时刻保持与主机的数据同步。一旦主机发生故障,备机中的一台立刻可以切换成为新的主机,继续提供服务。
高安全性
DM8是具有自主知识产权的高安全数据库管理系统,已通过公安部安全四级评测。是安全等级最高的商业数据库之一。同时DM8还通过了中国信息安全测评中心的EAL4级评测。
DM8提供基于用户口令和用户数字证书相结合的用户身份鉴别功能,还支持基于操作系统的身份认证、基于LDAP集中式的第三方认证。
DM8提供数据库审计功能,审计类别包括:系统级审计、语句级审计、对象级审计。DM8提供审计分析功能,通过审计分析工具Analyzer实现对审计记录的分析。提供强大的实时侵害检测功能,用于实时分析当前用户的操作,并查找与该操作相匹配的审计分析规则。
DM8提供了系统权限和对象权限管理功能,并支持基于角色的权限管理,方便数据库管理员对用户访问权限进行灵活配置。
DM8提供强制访问控制功能,强制访问控制的范围涉及到数据库内所有的主客体,避免了管理权限全部由数据库管理员一人负责的局面,可以有效防止敏感信息的泄露与篡改,增强系统的安全性。
DM8支持基于SSL协议的通讯加密,对传输在客户端和服务器端的数据进行非对称的安全加密,保证数据在传输过程中的保密性、完整性、抗抵赖性。
DM8实现了对存储数据的透明存储加密、半透明存储加密和非透明存储加密。每种模式均可自由配置加密算法。用户可以根据自己的需要自主选择采用何种加密模式。
兼容性
为保障用户现有应用系统上的投资,降低系统迁移到DM8的难度,DM8提供了许多与其他数据库系统兼容的特性,尤其针对Oracle,DM8提供了全方位的兼容,以降低用户学习成本,迁移成本。
体系结构方面,DM8兼容oracle的单库单实例式结构、表空间-数据文件机制、回滚机制、多版本并发控制、闪回。
应用开发接口兼容,兼容PL/SQL常用语法90%、OCI、OOCI、OO4O接口兼容、系统包机制。
维护管理方式兼容,兼容大量V$动态视图、AWR性能分析报告、10053等事件。
通用性
DM8兼容多种硬件体系,可运行于X86、SPARC、POWER等硬件体系之上。DM8各种平台上的数据存储结构和消息通信结构完全一致,使得DM8各种组件在不同的硬件平台上具有一致的使用特性。
DM8实现了平台无关性,支持Windows系列、各版本Linux(2.4及2.4以上内核)、Unix、NeoKylin、AIX、Solaris等各种主流操作系统。DM8的服务器、接口程序和管理工具均可在32位/64 位版本操作系统上使用。
DM8支持多种主流集成开发环境,包括PowerBuilder、Delphi、Visual Studio、.NET、C++Builder、Qt、JBuilder、Eclipse、Zend Studio等;
DM8支持各种开发框架技术,主要有Spring、Struts、Hibernate、iBATIS SQLMap、EntityFramework、ZendFramework等;
DM8支持主流系统中间件,包括WebLogic、WebSphere、Tomcat、Jboss、东方通TongWeb、金蝶Apusic、中创InfoWeb等。
DM8提供对SQL92的特性支持以及SQL99的核心级别支持;支持多种数据库开发接口,包括OLE DB、ADO、ODBC、OCI、JDBC、Hibernate、PHP、PDO、DB Express以及.Net DataProvider等。
DM8支持多种网络协议,包括IPV4协议、IPV6协议等。
DM8完全支持Unicode、GBK18030等常用字符集。
DM8提供了国际化支持,服务器和客户端工具均支持简体中文和英文来显示输出结果和错误信息。
使用场景
达梦数据库是一款完全国产化的数据库产品。减少了对国外相同产品的依赖。目前已经在制造业,电子政务,金融领域都有相当的使用比例。
局限性:目前没有得到广泛应用,可能存在某些未知的风险。
数据库对比
| Oracle | MySQL | DB2 | SqlServer | PostgreSQL | |
|---|---|---|---|---|---|
| 用户群体 | 政府 | 互联网 | 金融 | 财务 | 各行各业 |
| 特色 | 丰富高效 | 免费轻巧 | 稳定悠久 | 简单集成 | 免费丰富 |
| 战略 | 大而全 | 小而稳 | 结合自家服务器稳 | 完美集成Excel等 | 稳而全 |
| 最大缺点 | 复杂 | 资源利用 | 保守/怠慢 | 多用户/并发 | 不专一/积极性差 |
| 适用场景 | OLTP | OLTP | 混合型 | OLAP | OLAP |
| 规模 | 大型 | 轻量 | 巨型 | 中度 | 中度 |
| 跨平台 | 所有平台 | 所有平台 | 所有平台 | Windows | 所有平台 |
| 功能 | 丰富 | 简单 | 中等 | 简单 | 中等 |
| 事务并发 | 高 | 高 | 中 | 低 | 中 |
| 进程并行 | 高 | 低 | 高 | 低 | 中 |
| 锁级别 | 行级 | 行级 | 行级 | 页级 | 行级 |
| 安全性 | 高 | 低 | 高 | 低 | 中 |
| 综合费用 | 中 | 免费 | 高 | 低 | 免费 |
| 集群性能 | 高 | 中 | 中 | 不支持 | 低 |
| 操作复杂度 | 高 | 低 | 中 | 低 | 低 |
| 向下兼容度 | 高 | 中 | 高 | 不兼容 | 低 |
参考文献
https://blog.csdn.net/qq_3624...
https://cloud.tencent.com/dev...
https://blog.csdn.net/junshi6...
https://www.yht7.com/news/36141
https://blog.csdn.net/ever_jw...
http://www.dameng.com/prod_vi...
https://www.kingbase.com.cn/i...
https://baike.baidu.com/item/...
https://www.sohu.com/a/226133...
http://www.360doc.com/content...
https://baike.baidu.com/item/...
https://www.cnblogs.com/atree...
