【目标跟踪】Yolov5_DeepSort_Pytorch训练自己的数据
关于基本的配置,请看【目标跟踪】Yolov5_DeepSort_Pytorch复现
目录
1.环境
2.目标检测的数据准备
1)数据标注
2)分训练集与验证集
3)修改JPEGImages为images
4)xml转为txt与生成最后训练使用的train.txt与val.txt
5)修改训练配置(两处)
3.训练目标检测模型
4.准备分类/重识别数据(四处)
5.训练分类/重识别模型
6.测试跟踪(视频)
参考
好吧。似乎,写到很详细了,大家对于数据集还是有一些疑问。我大致说一说,目标检测的数据集,可以只做检测,划分为一类就可以。
然后将对应的数据抠取出来,然后,将其分别划分到哪些类。分类的数据也可以来自其他的对应于想要跟踪的几类。
对于流程进行说明一下。请大家多思考,仔细跟着博客走。
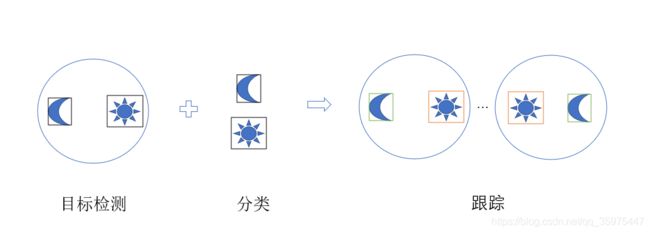
1.环境
ubuntu16.04
cuda10.1
cudnn7
python3.6
Cython
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3
scipy>=1.4.1
tensorboard>=2.2
torch>=1.7.0 (my 1.7.1)
torchvision>=0.8.1 (my 0.8.2)
tqdm>=4.41.0
seaborn>=0.11.0
easydict
thop
pycocotools>=2.02.目标检测的数据准备
1)数据标注
这里可以使用cvat标注,然后下载数据为VOC:
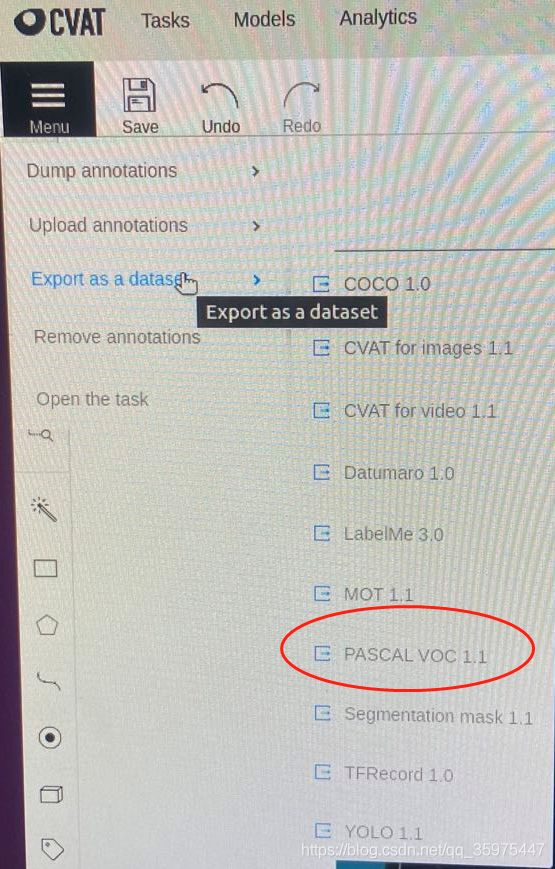
目录voc:

将数据放到Yolov5_DeepSort_Pytorch/yolov5/data目录下。
2)分训练集与验证集
实际上我只有train.txt与val.txt。
# -*- coding: UTF-8 -*-
'''
@author: gu
@contact: [email protected]
@time: 2021/3/4 上午11:52
@file: generate_txt.py
@desc: reference https://blog.csdn.net/qqyouhappy/article/details/110451619
'''
import os
import random
trainval_percent = 1
train_percent = 0.9
xmlfilepath = 'datasets/voc/Annotations'
txtsavepath = 'datasets/voc/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/voc/ImageSets/Main/trainval.txt', 'w')
ftest = open('data/voc/ImageSets/Main/test.txt', 'w')
ftrain = open('data/voc/ImageSets/Main/train.txt', 'w')
fval = open('data/voc/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
print(name)
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()train.txt里的文件名称,大概是这样:
003_000855
004_000146
002_000830
002_000720
002_002105
001_0008883)修改JPEGImages为images
修改JPEGImages为images。这个地方是因为yolov5默认读取images与labels。
4)xml转为txt与生成最后训练使用的train.txt与val.txt
# voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'val']
classes = ["***"] # your class
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/voc/Annotations/%s.xml' % (image_id))
out_file = open('data/voc/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
# difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/voc/labels/'):
os.makedirs('datasets/voc/labels/')
image_ids = open('data/voc/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('../data/voc/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/voc/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
print(image_id)
list_file.close()
训练的train.txt文件,大概是这样(在/data/voc/目录上):
data/voc/images/003_000855.jpg
data/voc/images/004_000146.jpg
data/voc/images/002_000830.jpg
data/voc/images/002_000720.jpg
此时的目录:
data
voc
Annotations
images
ImageSets
labels
train.txt
val.txt5)修改训练配置(两处)
----数据,在data目录下,复制coco.yaml,修改为如下:
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC/
# Train command: python train.py --data voc.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /VOC
# /yolov5
# download command/URL (optional)
#download: bash data/scripts/get_voc.sh
# train and = data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ./data/voc/train.txt # 16551 images
val: ./data/voc/val.txt # 4952 images
# number of clsses
nc: 1
# class names
names: [ '***'] # your class
----模型,在models目录下,修改对应想要训练的yolo模型yaml文件,这里以yolov5s为例(nc为类别总数):
# parameters
nc: 1 # number of classes只需要修改类别总数。
3.训练目标检测模型
1)在/Yolov5_DeepSort_Pytorch/yolov5目录下运行:
python train.py --data data/your_data_config_file.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device 0
将预训练的模型,放到下面的目录下。例如:yolov5s.pt。

2)模型测试可以使用下面命令:
python ./yolov5/detect.py --weights ./yolov5/weights/yolov5s.pt --source ./your_video.mp4 --save-txt3)模型精度验证:
cd yolov5
python ./test.py --weights ./weights/yolov5s.pt --data ./data/your_data_yaml_file.yaml --save-txt4)断开后接着训练,使用--resume
5)想使用tensorboard,注释model/yolo.py line 282-286
6)数据增强---data/hyp.scratch.yaml和data/hyp.finetune.yaml。
其中5,6参考:https://blog.csdn.net/weixin_41868104/article/details/114685071
4.准备分类/重识别数据(四处)
实际上要根据你自己的数据,写点处理数据的脚本,我这里就大致给出三个步骤吧。
---抠数据
可以将标注gt中的数据,抠出来,然后拿来训练模型。
# -*- coding: UTF-8 -*-
'''
@author: gu
@contact: [email protected]
@time: 2021/3/4 下午8:01
@file: crop_image.py
@desc: https://blog.csdn.net/qq_36249824/article/details/108428698
'''
import cv2
import xml.etree.ElementTree as ET
import numpy as np
import xml.dom.minidom
import os
import argparse
def main():
# JPG文件的地址
img_path = 'data/voc/images/'
# XML文件的地址
anno_path = 'data/voc/Annotations/'
# 存结果的文件夹
cut_path = 'data/voc/crops/'
if not os.path.exists(cut_path):
os.makedirs(cut_path)
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
# print(imagelist
for image in imagelist:
image_pre, ext = os.path.splitext(image)
img_file = img_path + image
img = cv2.imread(img_file)
xml_file = anno_path + image_pre + '.xml'
# DOMTree = xml.dom.minidom.parse(xml_file)
# collection = DOMTree.documentElement
# objects = collection.getElementsByTagName("object")
tree = ET.parse(xml_file)
root = tree.getroot()
# if root.find('object') == None:
# return
obj_i = 0
for obj in root.iter('object'):
obj_i += 1
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
b = [int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)),
int(float(xmlbox.find('ymax').text))]
img_cut = img[b[1]:b[3], b[0]:b[2], :]
path = os.path.join(cut_path, cls)
# 目录是否存在,不存在则创建
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(path)
cv2.imwrite(os.path.join(cut_path, cls, '{}_{:0>2d}.jpg'.format(image_pre, obj_i)), img_cut)
print("&&&&")
if __name__ == '__main__':
main()---使用预训练模型与标注,这个要自己去拿部分数据训练,然后不断重复(此处是用于帮助下面一步半自动标注用于分类的数据)。
---将数据分为train与test,目录中分别以类1,2,3,4或者其他的表示,这里是因为默认的读取方法,懒得改了。
目录大概是这样:
deep_sort_pytorch
deep_sort
deep
data
train
1
1_0001.jpg
...
1_nnnn.jpg
2
...
n
test
1
1_0001.jpg
...
1_nnnn.jpg
2
...
n---修改train.py中train dataset的预处理如下:
transform_train = torchvision.transforms.Compose([
torchvision.transforms.Resize((128, 64)),
torchvision.transforms.RandomCrop((128, 64), padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])5.训练分类/重识别模型
在Yolov5_DeepSort_Pytorch/deep_sort_pytorch/deep_sort/deep目录下运行:
python train.py --data-dir data/并修改model.py文件中的此处为自己的类别数(这一点很重要,很多人出现模型与推理类别不一样的问题,就是这里的设置):

6.测试跟踪(视频)
在/Yolov5_DeepSort_Pytorch目录下运行:
python track.py --weights ./yolov5/weights/yolov5s_our.pt --source your_video.mp4 --save-txt这里由于数据隐私,就不给图了。
如果有多个类别要跟踪的话,--classes中设置一下,如果类别数为2的话,就加个参数:
--classes 0 1 大概需要1G左右显存。
参考
1.yolov5训练自己的VOC数据集
2.【pytorch学习】 图片数据集的导入和预处理