Deep Learning:大白话pytorch基本知识点及语法+项目实战:2021-08-26
大白话pytorch基本知识点及语法+项目实战
相关链接:
实战项目——基于pytorch的深度学习花朵种类识别项目完整教程(内涵完整文件和代码)
超详细CNN卷积神经网络教程(零基础到实战)
文章目录
- 大白话pytorch基本知识点及语法+项目实战
-
- 知识点:
- 上code:
- 矩阵:
-
- 创建矩阵(tensor格式):
- tensor:
- view改变矩阵维度:
- tensor矩阵格式转化为numpy的array矩阵格式:
- pytorch基本语法:
- 一个线性回归模型(用GPU):
- 迁移学习:
- hub模块(调用别人训练好得网络架构):
知识点:
特征提取,神经元逐层判断
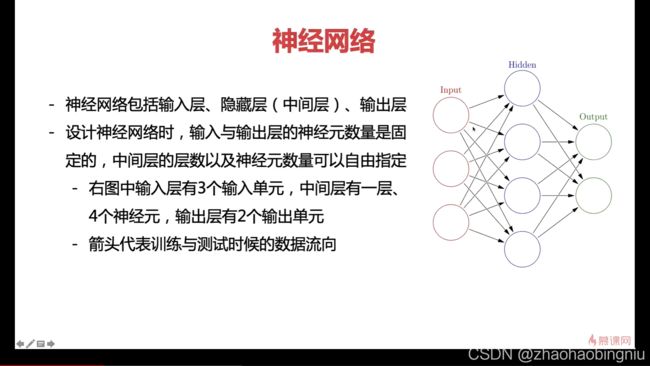
中间层(隐藏层)越多越厉害

学习权值、神经元进行运算
返向传递:将输出值与正确答案进行比较,将误差传递回输出层回去(叫梯度,pytorch自动完成),从而计算每个权值的最优值,去进行更改。
Pytorch核心:Autograd包(完成自动梯度计算及返向传递)

训练一个模型的时候需要返向传递,用的时候不需要
TensorFlow:
定义运算符、定义运算、定义梯度、开启对话框、注入数据、进行运算。
Pytorch:
初始化、进行运算(变调式便运算)
上code:
import torch
#定义向量
vector = torch.tensor([1,2,3,4])
print("Vector:",vector)
print("Vector Shape:",vector.shape)
#定义矩阵
matrix = torch.tensor([[1,2],[3,4]])
print("matrix:",matrix)
print("matrix Shape:",matrix.shape)
#定义张量
tensor = torch.tensor([[1,2,],[3,4],[5,6]])
print("tensor:",tensor)
print("tensor Shape:",tensor.shape)
#
Vector: tensor([1, 2, 3, 4])
Vector Shape: torch.Size([4])
matrix: tensor([[1, 2],
[3, 4]])
matrix Shape: torch.Size([2, 2])
tensor: tensor([[1, 2],
[3, 4],
[5, 6]])
tensor Shape: torch.Size([3, 2])
矩阵:
创建矩阵(tensor格式):
#这里矩阵是tensor格式,numpy中是array格式
#运算的时候都要用tensor格式,运算完展示的时候用numpy格式
#python中利用numpy创建矩阵a = np.ones(5)
#创建一个5行3列的随机数矩阵,后面加上一个参数的意思是后面可以求偏导计算梯度值了
x = torch.rand(5, 3,requires_grad=True)
#初始化一个5行3列的全零的矩阵
x = torch.zeros(5, 3, dtype=torch.long)
#初始化一个一行五列的单位矩阵
a = torch.ones(5)
#直接传入数据,结果是:tensor([5.0000, 3.0000])
x = torch.tensor([5, 3])
#展开矩阵看是几行几列的
x.size()
tensor:
import torch
from torch import tensor
x = tensor(42.)
#得42.0
v = tensor([1.5, -0.5, 3.0])
#得【1.5,-0.5,3.0】
M = tensor([[1., 2.], [3., 4.]])
#得矩阵
#【1.,2】
#【3.,4】
view改变矩阵维度:
#创建一个4*4随机矩阵
x = torch.randn(4, 4)
#改变成一个一行16个元素的矩阵
y = x.view(16)
#(行,列)(-1代表自动计算,有8列)
z = x.view(-1, 8)
print(x.size(), y.size(), z.size())
tensor矩阵格式转化为numpy的array矩阵格式:
a = torch.ones(5)
b = a.numpy()
b
pytorch基本语法:
import torch
t = x + b
y = t.sum()
#反向传播
y.backward(retain_graph=True)#如果不清空会累加起来
#反向传播中b的梯度值
b.grad
一个线性回归模型(用GPU):
其实线性回归就是一个不加激活函数的全连接层
import torch
import torch.nn as nn
#定义一个 y=2*x+1 函数
x_values = [i for i in range(11)]
x_train = np.array(x_values, dtype=np.float32)
x_train = x_train.reshape(-1, 1) #把数据都转化成矩阵的格式
x_train.shape
y_values = [2*i + 1 for i in x_values]
y_train = np.array(y_values, dtype=np.float32)
y_train = y_train.reshape(-1, 1)
y_train.shape
#构建网络模型
#模型都是定义一个类,(nn.Module)调用一个模块,下面直接写调用第几层就行了
class LinearRegressionModel(nn.Module):
#构造函数:写明用了哪个层
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
#nn.全连接层(输入数据维度,输出数据维度),这里都是1
self.linear = nn.Linear(input_dim, output_dim)
#前向传播,写明各个层是怎么走的
def forward(self, x):
#这里只写了一个全连接层(y=kx+b)
out = self.linear(x)
#输出结果
return out
#定义输入输出维度,因为是y=kx+b,这里都是1
input_dim = 1
output_dim = 1
#输出model
model = LinearRegressionModel(input_dim, output_dim)
#指定使用GPU跑模型,需要把数据和模型传入到cuda里面
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#定义相关参数和函数
#训练次数
epochs = 1000
#指定学习率
learning_rate = 0.01
#指定优化器,选SGD(所有需要优化的参数,学习率)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
#定义损失函数
criterion = nn.MSELoss()
#训练模型
#迭代100次
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor,tenser才能做运算,同时需要把数据和模型传入到cuda里面
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
#预测模型结果,再转化为numpy格式
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
predicted
#模型的保存(权重参数,‘名字’)
torch.save(model.state_dict(), 'model.pkl')
#模型读取
model.load_state_dict(torch.load('model.pkl'))
迁移学习:
用相似的模型的权重初始化
全连接层需要改变
hub模块(调用别人训练好得网络架构):
GITHUB:https://github.com/pytorch/hub
模型:https://pytorch.org/hub/research-models

关注博主,分享学习教程,一起HappyCodeing