GTC大会飞桨专家演讲内容实录:飞桨推理引擎性能优化
点击左上方蓝字关注我们

GTC 大会是英伟达每年最重要的发布平台之一,广纳当今计算领域最热门话题的相关培训和见解,并为广大开发者创造与顶级专家交流的机会。12月15日-19日,GTC中国大会首次以线上大会的形式与开发者相见,共组织265场技术演讲,演讲者分别来自百度、阿里、腾讯、字节跳动等众多知名企业,以及清华大学、中科院计算所等知名高校。百度飞桨也贡献了四个主题演讲,现在为您带来飞桨推理引擎性能优化的演讲实录。
课程链接:
https://nvidia.gtcevent.cn/forum/watch?session_id=CNS20191
AI Studio链接:
https://aistudio.baidu.com/aistudio/education/group/info/2099
在一小时的演讲中,来自飞桨团队的资深研发工程师商智洲老师介绍了飞桨原生推理引擎,以及该引擎中针对 GPU 推理所做的优化工作。飞桨推理引擎是飞桨模型推理部署的重要基础之一,已在百度内部各核心业务线和众多 ToB 交付的AI服务中经过充分验证。
商智洲介绍,飞桨在不同的推理场景下,都有相应的推理部署方案:
飞桨框架的原生推理引擎Paddle Inference,侧重低延迟、高吞吐,主要目标是X86和英伟达的GPU上的模型推理;
模型服务化部署工具Paddle Serving,侧重线上模型管理,弹性服务,A/B测试;
面向Mobile&IoT的压缩工具PaddleSlim 和飞桨端侧推理引擎Paddle Lite,侧重高性能,低资源使用,部署体积小;
Paddle.js支持浏览器场景的推理部署。
飞桨框架的原生推理引擎Paddle Inference有如下特点:
通用性:Paddle Inference复用了训练框架的前向代码,可以完全支持飞桨训练出来的模型的推理。
多硬件支持:包括X86、英伟达的Tesla GPU和Jetson GPU。
深度优化:支持显存和内存的优化;支持OP的融合;X86和英伟达GPU架构下的高性能计算kernel;通过子图的方式集成TensorRT,支持混合精度推理。
接口简单:十几行代码即可完成C++、Python的推理过程。另外有Go语言和R语言的API接口。
商智洲进一步介绍了Paddle Inference的性能优化方法:
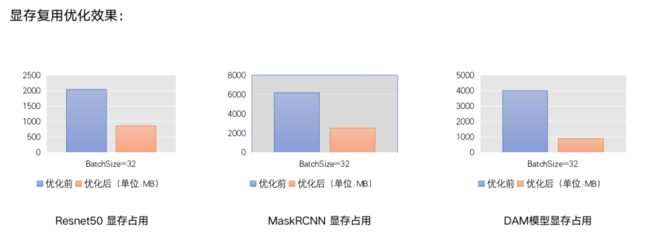
1. 显存优化
在模型推理时,显存占用主要有模型参数、OP输出tensor和OP内临时显存占用三个方面。我们分别针对这三个方面进行优化,从而减小显存的占用:
首先,我们支持了参数共享。推理过程需要的参数是只读的,没有修改需求,因此创建多个predictor做并行推理时,参数只用保留一份实际存储,以降低显存占用。
其次,我们对OP输出Tensor进行空间复用:
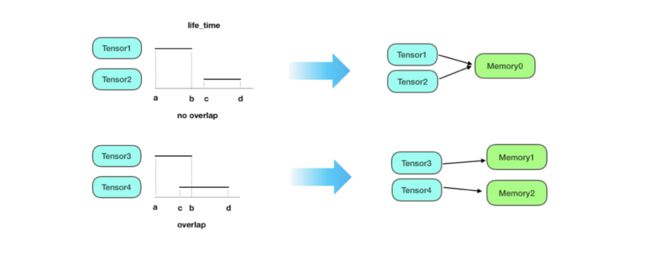
如图所示,对OP输出Tensor进行生命周期分析,对生命周期无重合的Tensor进行空间复用,可以降低临时空间的使用。
同时,我们对临时显存,开辟显存池,统一分配和管理。我们以一个例子来说明飞桨推理引擎使用的显存分配策略原理。假设显存共8GB,参数fraction_of_gpu_memory设置为0.2,初始化的时候会开辟第一个bucket,大小是8GB * 0.2 = 1.6GB。如果在bucket的剩余空间大小范围之内申请显存,就会直接分配。释放的时候,显存也会直接释放到bucket里面,然后左右相邻的碎片连接到一起,并不会释放回系统。
而当申请的显存大小超过bucket剩余空间大小的时候,会开辟一个新的bucket,其大小是用fraction_of_gpu_memory乘以显卡上剩余的显存,例如当前我们的8GB已经使用了1.6GB,下一个bucket大小为 6.4GB * 0.2 = 1.28GB。
值得注意的是,当申请的显存大小超过一个bucket的时候,会直接调用cudaMalloc()和cudaFree(),对推理的性能有比较严重的影响,因此相关参数一定要根据实际环境合理配置。
OP的融合

根据OP的具体计算逻辑,可以把相邻的两个和多个OP融合成一个大的融合OP。以这里的Conv和BatchNorm为例,通过把图示的几个公式代入到一起,就得到最下面化简之后的形式。
通过融合,首先参数的数量可以减少,这样的好处是可以减小显存/内存的使用,同样也会减小显存和内存的访问。参数数量的减小,同样也意味着计算量的减小,通过降低冗余的计算量,可以显著提升推理的性能。同时由于融合带来的OP数量减少,可以减少CUDA Kernel Launch次数,降低调度开销。
2. CUDA Kernel优化
我们对CUDA的kernel也进行了相关优化,首先是访存优化:
连续线程访问连续数据,形成数据合并访问;连续线程写入连续数据,避免数据分区冲突。
尽量使同一个warp内连续线程访问连续的数据,以充分例行Global Memory读写的并行性。具体需要对齐的字节数跟设备的架构相关,比如算力6.0以上的设备上并行访问以32字节对齐。
尽量使用Shared Memory, 避免Bank Conflict。
Shared Memory是性能最接近寄存器的存储类型,由多个大小相等的Bank组成,不同的Bank之间可以并行访问,访问同一个Bank的线程要顺序执行。因此在使用Shared Memory时要尽量分散线程对数据的访问,防止Bank访问冲突。
其次是计算优化,首先考虑从算法上优化,使用更优的实现,减少计算量;根据CUDA架构,合理安排block和thread的数量分配,增加计算并行性和计算单元的空间利用率;多使用快速指令,例如在满足精度要求的情况下,使用CUDA提供的低精度数学库函数替换单精度浮点的版本等。
3. TensorRT集成
TensorRT是英伟达推出的一个高性能的深度学习推理SDK,包括一个推理优化器和一个运行时环境,可以显著地提高在英伟达GPU上的推理性能。和Paddle Inference类似,TensorRT也会做一些层的融合,显存的复用等优化措施,还支持FP32、FP16、INT8的混合精度预测。TensorRT提供了C++和Python的组网API,这样就可以嵌入到自己的工程中去使用,这也是飞桨的使用方式。Paddle Inference的执行流程主要分为两步,第一步是初始化,加载模型进行各种的优化操作,第二步就是预测。TensorRT也有类似的两个步骤,一是推理优化器,对应网络的构建、优化阶段;二是运行时环境。这两个阶段使得Paddle Inference和TensorRT可以很方便地集成到一起。
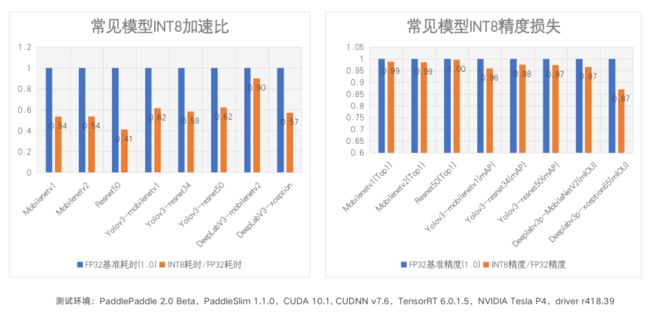
4. PaddleSlim量化
我们针对飞桨模型压缩工具PaddleSlim也进行了相关优化,首先是训练侧,训练中统计OP的输出 scale并存储在属性中,带权重的OP插入fake quant OP、fake dequant OP并统计weight scale。
然后是推理侧,获取TRT子图中所有OP输入、输出的scale,以及有权重OP的weight scale,但由于TRT不支持fake quant和fake dequant OP,需要将其在计算图中删除。最后,在TRT engine中设置获取到的scale。
最后商智洲介绍了Paddle Inference对ERNIE模型优化的例子,首先采用OP融合,将标准ERNIE模型的OP数量降低到原来的20%,且核心的融合OP都提供了FP16精度的实现,在英伟达T4上ERNIE模型运行耗时从224ms降至41.90ms(batch=32, layers=12, head_num=12, size_per_head=64)。然后通过对ERNIE模型变长输入的支持,进一步提升了ERNIE模型的推理性能。在Tesla T4上ERNIE模型的推理性能从905 sentences/s提升到2237 sentences/s(飞桨框架2.0RC1, CUDA10.1,cuDNN 7.6,TensorRT 6.0,OSS 7.2.1;模型ernie-base-2.0;QNLI数据集,Batchsize 32)。
加入我们
欢迎大家加入飞桨推理部署QQ群,我们为大家解决Paddle Inference、Paddle Serving、Paddle lite等各平台推理部署相关问题。也欢迎有相关从业经验或者有志于研究深度学习框架,性能优化等方向的小伙伴入群自荐简历。Paddle Inference部署交流群QQ群号:959308808
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
·飞桨PaddlePaddle项目地址·
GitHub:
https://github.com/PaddlePaddle/PaddlePaddle
Gitee:
https://Gitee.com/PaddlePaddle/PaddlePaddle
·飞桨官网地址·
https://www.paddlepaddle.org.cn/

微信号 : PaddleOpenSource
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。