Hadoop——集群搭建(步骤图文超详细版)
目录
-
- 一、前置条件
- 二、安装Centos系统
- 三、配置Centos系统静态IP(很重要!)
- 三、解压jdk压缩包,配置环境变量
- 四、配置免密钥登录
-
- 修改主机名
- 增加ip映射关系
- 关闭防火墙
- **==我们继续来配置免密码登录!==**
- 验证免密码登录
- 五、Hadoop配置
- 六、集群启动并测试集群
一、前置条件
| 需要安装 | 下载方法 |
|---|---|
| Vmware Workstation | 官网下载链接 |
| Centos7系统 | 百度网盘下载 , 提取码:t6va |
| jdk1.8 | 官网下载链接 |
| MobaXterm | 百度网盘下载,提取码:f64v |
| hadoop(2.7.3版本) | 百度网盘下载,提取码:963t |
二、安装Centos系统
为了减少篇幅,我就把安装步骤放到另一篇博客,大家动动手指吧:安装教程
三、配置Centos系统静态IP(很重要!)
这里我之前的文章有写过,这里也不详细讲了,有需要的可以看看我这篇文章:配置教程
注意:不配置的话Centos系统无法连网!!!
三、解压jdk压缩包,配置环境变量
这一步每个主机节点都需要配置!!我这里只演示一台主机怎么配!!
1、我们第一步需要先用MobaXterm连接linux主机↓

2、为了统一管理,我们把所有的jdk包都放在~/software目录下
3、我们把从官网下载的jdk压缩包拖到这目录下
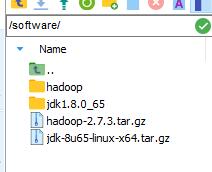
4、首先cd到/software目录下,命令:cd/software。然后解压缩jdk包,命令:tar -xzvf jdk-8u65-linux-x64.tar.gz
5、然后我们来配置环境变量,命令:vi /etc/profile,在末尾加上↓
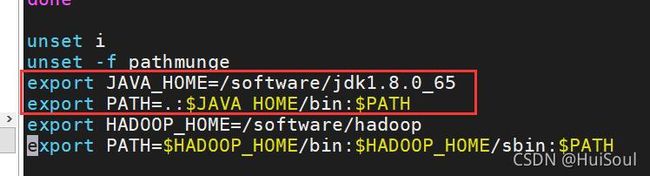
按下键盘 “i” 进入插入模式,紧接着在末尾加上:命令↓
export JAVA_HOME=/software/jdk1.8.0_65
export PATH=.:$JAVA_HOME/bin : $PATH
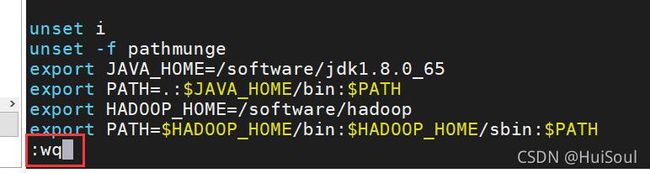
然后按 esc退出插入模式,再输入:wq(注意有冒号!!)保存退出
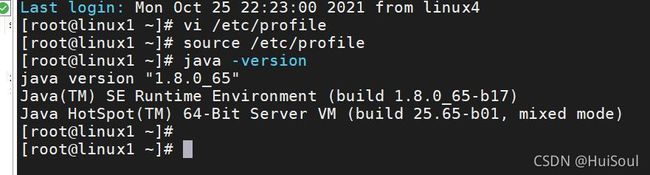
6、让系统刷新配置文件,并找到JAVA环境变量,命令:source /etc/profile。查看JAVA版本信息,命令:java -version
四、配置免密钥登录
配置免密钥登录,需要namenode和datanode结点一起配置才能生效,下面我演示一下如何配置一个datanode结点,大家根据这个规则给namenode结点和其他datanode结点配置就好了
我这里设置了三个结点,其中.110是主节点,其余为从节点
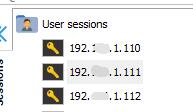
修改主机名
根据哪个是主节点,哪个是从结点给予名字,如:namenode、datanodeA、datanodeB等等
命令↓
vi /etc/hostname
更改后利用命令查看是否更改成功,命令↓
hostname
增加ip映射关系
利用MobaXterm打开需要配置免密钥登录的结点,cd 到 /etc目录,命令↓
cd /etc
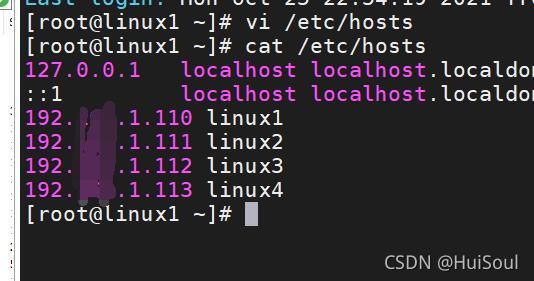
然后输入 vi hosts,修改host配置文件,添加映射关系:命令↓
vi hosts
按 i 进入插入模式,增加结点的ip地址
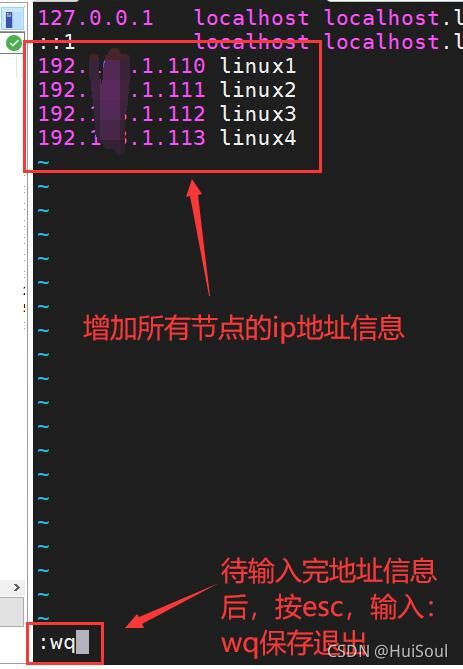
检查是否添加成功,命令:cat hosts
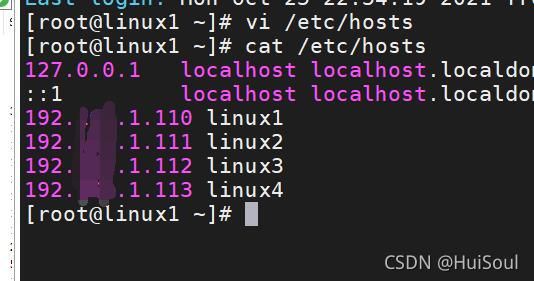
将配置文件“hosts”发送给集群中所有的主机,发送目标用户为结点ip地址或者节点主机名用户,发送目标路径为“/etc”,我这里只演示发送一个结点,如果要发送多个结点,只用复制命令,更改ip地址就好啦,接着输入要发送的结点的登录密码就完成发送了。
命令↓
scp -r /etc/hosts root@结点ip地址或者节点主机名:/etc
我这里因为配置好了免密登录所以就不需要输入密码了

然后我们在接收结点的/etc/hosts文件里就可以看到原本的文件已经被覆盖成新文件了!
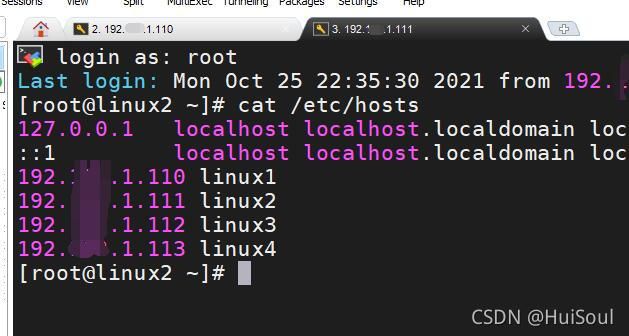
关闭防火墙
永久关闭防火墙命令↓
systemctl stop firewalld.service
禁止防火墙重启后自动启动命令↓
systemctl status firewalld
关闭防火墙后,看看防火墙状态是否关闭成功,命令↓
firewall-cmd --state
我们继续来配置免密码登录!
步骤↓
①cd到.ssh目录,命令↓
cd .ssh
有些同学在这一步可能找不到.ssh文件夹,我们可以使用命令:ssh localhost ,进入root用户,再cd .ssh就能找到这个文件夹了!
②利用 ls 命令查看目前目录存在的文件
③删除当前目录所有文件,命令:rm *,在提示是否删除后输入 y
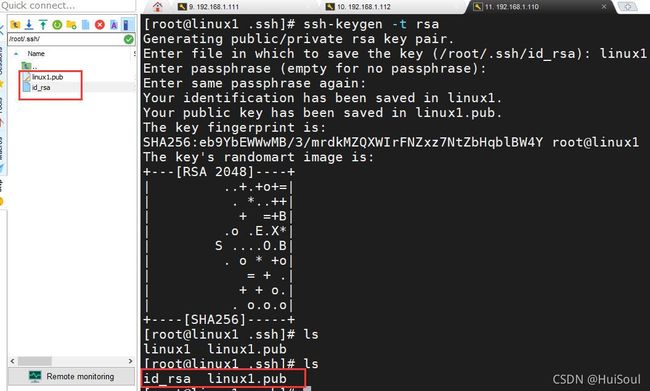
④生成公钥私钥文件,命令↓
ssh-keygen -t rsa
注意:这里不要一直回车!在第一次询问时,末尾加上能代表本结点的名字!
为了后面方便配置,我改变了一下公钥文件的名字↓
![]()

再次注意!!
我们改完公钥文件名字之后需要把生成的私钥名字改回id_rsa,因为系统只能识别id_rsa为本机私钥,若没有改回来免密登录不会成功的!!
方法:只要在MobaXterm左边目录对着私钥文件右键Rename就可以了↓
⑤将公钥文件加入认证文件authorized_keys中,命令↓
cat id_rsa.pub >> authorized_keys;
一定要注意认证文件的名字要对,错误了系统是识别不到认证文件的

----------------------------一定要三个节点都完成上述步骤后才能进行下面的步骤---------------------------------------------
然后我们把该结点的公钥文件 传送给另外两个节点的.ssh目录下,命令↓
scp 公钥文件名.pub root@节点主机名:~/.ssh/
从linux1节点往其他linux2和linux3节点传送公钥文件↓
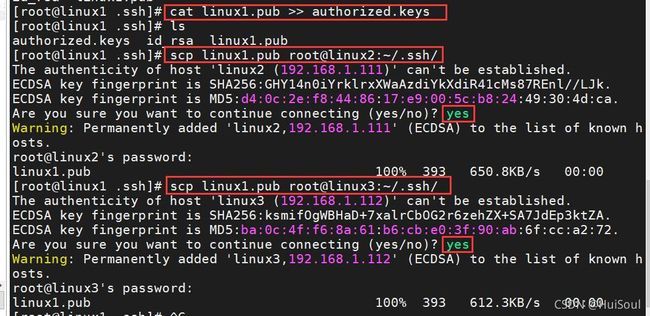
三个节点都要进行上面互相传送公钥文件的操作!
互相传送后的结果截图↓
![]()
往每台主机的认证文件中加上另外两个节点的公钥

查看认证文件中是否有三个节点的公钥文件
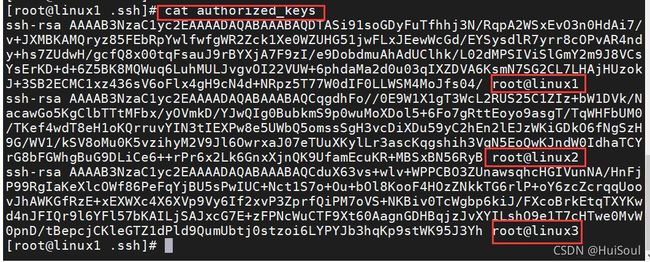
验证免密码登录
刚刚我们在每个结点的认证文件中都加上了公钥文件,也就是现在开始从任何结点都可以免密码登录至其他结点了,我们来试试看↓
因为我们之前增加了ip映射关系,我们这里测试直接使用ssh+主机名就能进行登录了

免密登录已经配置成功了!
五、Hadoop配置
①将下载的hadoop压缩包放到 /software 目录下
②进行解压hadoop压缩包,命令:tar -xzvf hadoop-2.7.3.tar.gz
③将解压后的hadoop文件名修改成hadoop,方便后续操作
注意:这里有一个小技巧!我们这里只用将压缩包解压在主节点下就好了,因为我们可以在配置完后用 scp 命令将hadoop整个文件传送到其余节点下
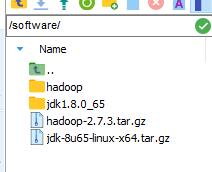
修改全局配置文件路径,命令:vi /etc/profile,在末尾加上:
export HADOOP_HOME=/software/hadoop
export PATH=$HADOOP_HOME/bin: $HADOOP_HOME/sbin: $PATH
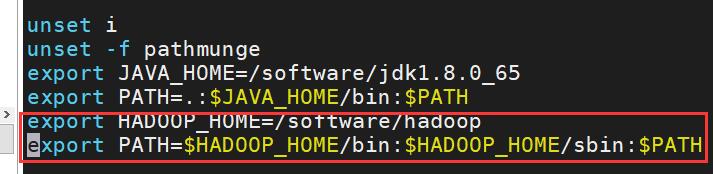
进入/software/hadoop 目录下,创建dfs和tmp两个空白文件夹,用于后续运行文件存储
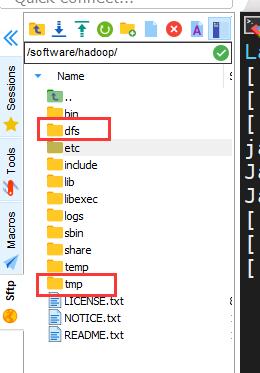
进入/software/hadoop/dfs 目录下,创建data和name两个空白文件夹,用于后续运行文件存储
进入/software/hadoop/目录下
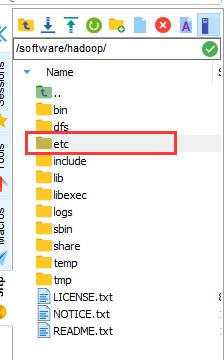
再进入 /software/hadoop/etc/hadoop目录下,接下来配置/software/hadoop/etc/hadoop/目录下的七个文件↓
slaves
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
hadoop-env.sh
yarn-env.sh

注意:Hadoop版本2和3此目录下的文件会有所不同!!建议大家使用Hadoop2.7.3版本!!
(最上面我已经更新了hadoop2.7.3版本的下载方法!)
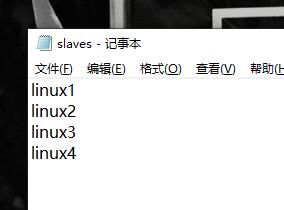
slaves文件↓将原本的localhost删掉,加上所有结点的主机名
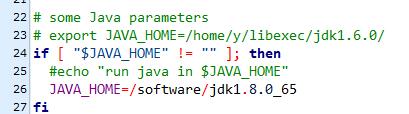
hadoop-env.sh↓,第25行加上java的jdk路径↓

yarn-env.sh↓,第26行加上java的jdk路径↓
--------------------------------------------以下均在配置文件中的configuration标签内添加-------------------------------------------
core-site.xml↓
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://主节点名:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/software/hadoop/tmp</value>
</property>
</configuration>
hdfs-site.xml↓
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/software/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/software/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<!-- 从结点数 -->
<value>3</value>
</property>
<property>
<name>dfs.http.address</name>
<value>主节点名:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>主节点名:50090</value>
</property>
</configuration>
mapred-site.xml↓
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>主节点名:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>主节点名:19888</value>
</property>
</configuration>
yarn-site↓
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>主节点名:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>主节点名:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>主节点名:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>主节点名:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>主节点名:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
用 scp 命令将主节点下已经配置好的hadoop文件整个传送至其余结点的~/software目录下↓
scp -r /software/hadoop root@linux2:~/software/
scp -r /software/hadoop root@linux3:~/software/
六、集群启动并测试集群
以下操作均需所有节点主机在开启状态中
在主节点主机操作:cd /software/hadoop
修改Hadoop目录权限,命令:chown -R hadoop:hadoop /software/hadoop
格式化NameNode,命令:bin/hdfs namenode -format
后续若要重新格式化步骤:
(1)停止所有节点上的NameNode和DataNode进程,命令:stop-all.sh(任何目录下都能运行)
(2)删除所有节点的data和logs文件夹(hadoop.tmp.dir)
(3)格式化NameNode
启动集群,命令:start-all.sh(任何目录下都能运行)
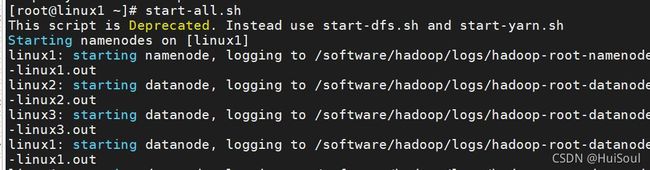
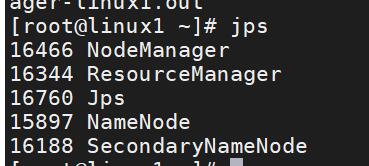
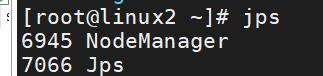
在主从节点中输入命令:jps,就能看到节点信息

在windows浏览器输入:http://主节点ip:50070/
就能访问HDFS页面啦!↓

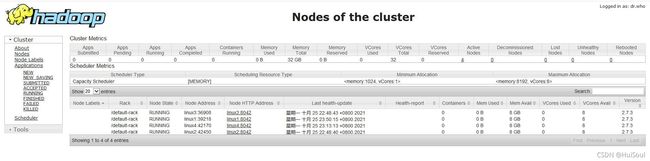
在windows浏览器输入:http://主节点ip:8088/
就能看到yarn页面啦!↓
本次分享到此结束,谢谢大家阅读!!