基于深度学习的OCR技术简介
1.概述
本文简要介绍基于深度学习的OCR技术,主要分为整体框架流程介绍,文字检测CTPN,文字识别CRNN+CTC,基于windows平台的项目实战,以及遇到的一些问题和解决方案,最后展示一下胜利的果实!对于一些相关的概念介绍的深度,只满足于顺利地理解本文的程度。尽量的做到 深入浅出,如有不周,敬请谅解!文章参考深度学习在OCR中的应用-美团团队!
2.整体流程
我们假设能够读到本文的人,都知道OCR(把图像中的文字提取出来)是做什么的,在此不再赘述。其实OCR和图像分类是比较像的,只是难度会更大而已。问如何找到一副图像中的目标动物,第一步找到目标动物在哪儿,第二步判断其具体是哪种动物。OCR要找到图像中的文字,那也一样,第一步找到文字在哪儿,第二步判断具体是什么字。如下图所示,找到文字在哪儿就是文字检测,判断具体是什么字就是文字行识别。最后把结果输出就行了。
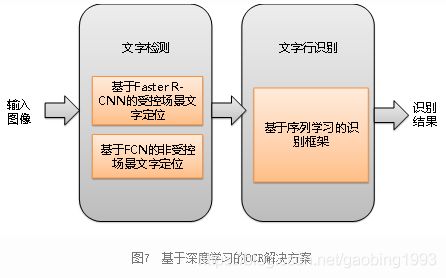
是不是很简单,大道至简,最高级的思想往往总是这么朴实无华。可是奈何人类总是千变万化,千奇百怪!难点在于文字表达形式和场景的复杂性、多样性,拿汉字来说,就有宋体、行书、楷书、手写体等等各种字体,广告牌、衣服、菜单等各种场景,这就给文字检测和识别带来了很大的困难!
所以直接使用原始的图像分类框架是不行的,但我们可以先使用其提取图像中的特征信息,然后使用RNN进行序列学习,对于RNN输出的序列我们再做一些处理就可以得到最终的结果了。这就是CRNN的思想。
3.文字检测CTPN(Connectionist Text Proposal Network)
3.1 整体介绍
我们来讨论一种比较流行的文字检测框架CTPN,其整体的流程如下所示。首先使用传统的VGG16进行特征提取,选取VGG16 conv5的输出(该层输出将原始图像缩小了16倍);然后使用3*3的滑动窗口进行提取,以max(W)作为序列长度,3*3*C作为每一时刻的长度输入到Bilstm;然后经过FC层,FC输出特征图的每一个点会预测10个anchor,最后使用RPN进行回归框的预测,就得到了b图。
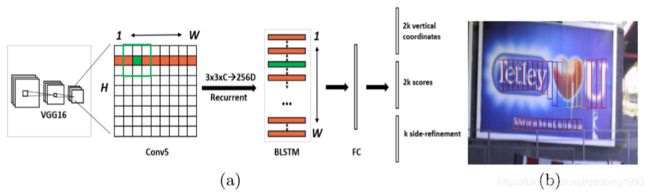
3.2 Vertical Anchor
与Faster Rcnn中的回归框预测不同的是,CTPN只预测anchor的中心点的Y坐标和anchor的高Y。anchor的宽统一设定为16(跟conv5对原图的缩小比例相同),anchor的高共10个比例(11...273,每个数为前一个数除以0.7)。因为对于文本来说,字与字之间水平方向的边界是难以区分的。所以最后进行nms抑制的时候其使用的也是只有垂直方向的IOU。
3.3 文本线构造算法
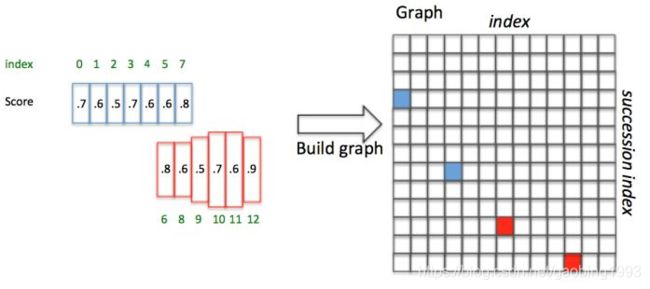
当预测出来了多个稠密的框,我们在将多个框合并为一个大的框。如下图所示,我们简单介绍一下合并的流程。总共分为三步:1.排序 2.找pair,生成graph矩阵 3 遍历graph合并。
1.排序: 按照已经提取出来的text proposals的水平位置进行排序
2.找pair:正向寻找:当前框i向右找50个像素(1.76厘米,这就是一个定义的距离,因为横向为16所以就是3个proposals),找到IOU>0.7的(垂直IOU,可以保证尽量在同一行),取softmax score最大的一个框j(尽量使的一个pair组开头和结尾都是字);反向寻找:从框j位置向左找,条件和正向寻找一样,找到框k;判断:如果当前框i的softmax score大于反向找到的框k的softmax score,则graph(i,j)=True 是一个长连接,否则graph(i,j)=false,不是长连接(该连接包含在其它的连接里面);
这样可以尽量保证一个pair对的两端都是字,并且尽量在同一行。找到每一对,生成下面的graph矩阵(N*N 横纵坐标为anchor的数量)。
3.遍历graph 矩阵,将邻接的长连接再连起来
如下面蓝色1(0,3),蓝色2(3,7)(前面的y等于后面的x,就可以相连),没有以7为横坐标的框。则连成的大框就是(0,7)
最后将所有小的矩形连接起来就是大的矩形了。
3.4 文本行的side-refinement
因为预测anchor的时候固定宽度为16,所以多多少少会和真实框有一些差距。所以在最后要使用边界完善的方式,使回归框的x位置更加准确。
下图黄色为未调整之前,红色框为调整之后的框的。明显使用了微调之后会更加的准确一些。

表达式如下:Xside表示预测的边界x坐标,Cx表示anchor的中心点x,W表示宽度为16.
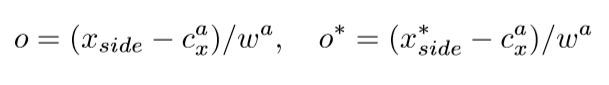
3.5 损失函数
如下图所示就是ctpn损失函数的表达式,分为三个部分:1.所有anchor二分类的损失 softmax_cross_entropy_loss,表示框中是否有字,其中Ns表示所有的anchor总数。2.和ground trunth IOU>0.5 的 anchor回归的损失,使用smooth_L1_loss,其中Nv表示anchor和ground trunth IOU>0.5的anchor数量 3.边界anchor水平位置回归损失,使用smooth_L1_loss No表示所有边界anchor的数量。lambda1和lambda2为多任务平衡参数,分别为1.0和2.0;
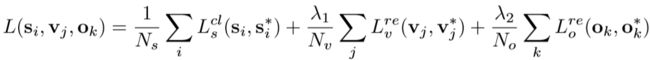
3.6 总结
我们介绍了一种流行的文字框检测框架,这个框架相当于对Faster Rcnn的改造。主要的特点有:1.稠密框检测,然后使用文本线构造算法进行合并 2.Vertival Anchor 每个anchor的宽度是固定的16,只进行高度和中心点y的预测。3.使用双向的LSTM学习序列的特征。缺点是这种框架比较适合水平方向的文字检测,不太适合文字方向旋转的文字框的识别。
4. 文字识别CRNN+CTC
下面我们介绍一种文字识别的框架,并且能较好的适应各种非受控文字场景。使用一个全卷积网络学习区域特征,使用深层Bi LSTM学习文字序列的先后关系,最后是一个CTC翻译层实现对文字序列信息的解码。
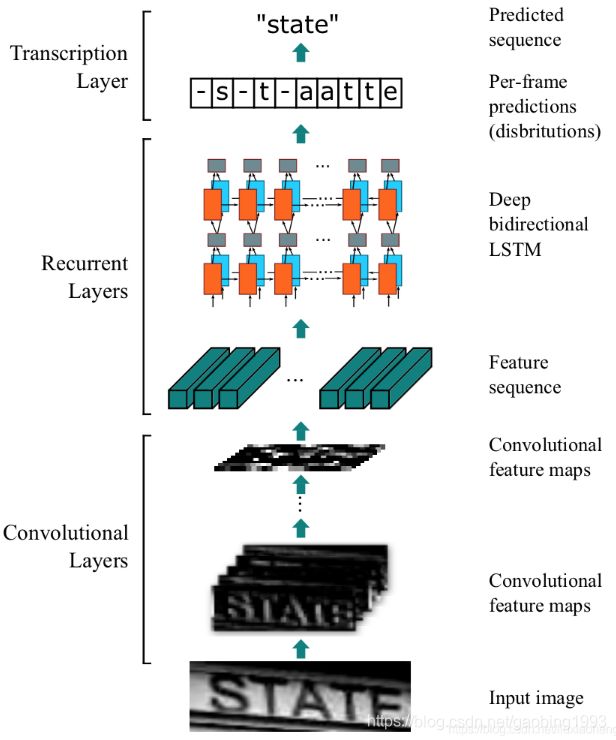
4.1 CTC(Connectionist Temporal Classification)翻译层
对于CNN和RNN的部分,我们不再赘述,重点我们聊聊最后的CTC翻译层。这里考虑到一个对齐的问题,因为RNN的输出无法和真实字符一 一对应(困难很大,得不偿失),这就造成了损失函数构建的问题,使用传统的多分类交叉熵损失函数无法确定模型的优劣。问题是创新最好的土壤,于是CTC这种不需要对齐的损失函数就应运而生。对于CTC的流程,一文读懂CRNN_CTC这篇文章中讲的挺详细的,我在这里只是进行简单的总结。
- 空白符号blank
我们知道原始的真实值没有办法直接用来计算损失,因为存在对齐的问题。所以在此加入了空白字符blank,表示当前的位置没有字符。我们将真实值的开始和结束位置,以及每个字符之间都加入blank,作为计算损失的真实标签![]() 。假如原始字符为STATE,转换以后就成为 _S_T_A_T_E_。
。假如原始字符为STATE,转换以后就成为 _S_T_A_T_E_。
- B转换
B转换就是,将连续的相同字符进行合并,并且去掉blank
比如B(__stta_t__e) = state。
- CTC概率计算公式
下面的公式有一点刺激, 表示真实路径,x表示LSTM层的输出。
表示真实路径,x表示LSTM层的输出。
公式一:输入x输出的概率,是输入x所有可能路径π出现的概率之和,其中π ![]() 表示 π是经过B转换之后为的序列。
表示 π是经过B转换之后为的序列。
公式二:路径π出现的概率,是路径中每个字符在对应的时刻出现的概率之积(可以从LSTM的输出y中得到)。
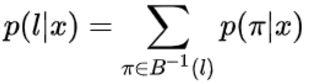
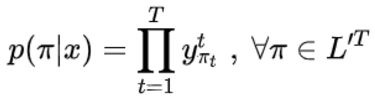
- 定义梯度
为了进行参数的更新,我们首先要求出最终总概率函数对于LSTM输出![]() (t表示时刻,k表示真实路径中当前时刻的值)的梯度。我们定义所有经过B变换之后结果为,并且在t时刻值为
(t表示时刻,k表示真实路径中当前时刻的值)的梯度。我们定义所有经过B变换之后结果为,并且在t时刻值为 的所有可能路径π的集合为{π π∈
的所有可能路径π的集合为{π π∈![]() ,π
,π![]() }。公式一表示最终概率对参数
}。公式一表示最终概率对参数![]() 的偏导,即t时刻是k的路径和t时刻不是k的路径之和。但对于求偏导来说,后面的一部分是没有用的,所以就有了公式二。
的偏导,即t时刻是k的路径和t时刻不是k的路径之和。但对于求偏导来说,后面的一部分是没有用的,所以就有了公式二。
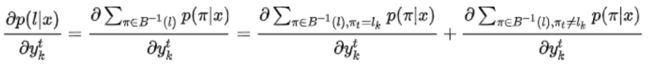
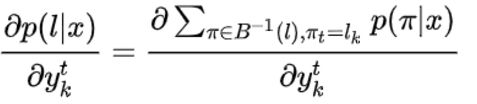
- 向前向后算法
通过上面的介绍我们知道,将所有可能的序列组合π出现的概率相乘就可以得到输入x输出真实路径的概率。简单的想法往往很可爱,但是不切实际。想要穷举所有可能路径π是一项非常困难的工作,并且随着时刻T的增加,复杂度是指数级的,直到程序瘫痪。所以为了简化算法,对于列举所有可能组合的问题,我们通常会使用动态规划的思想。我们在HMM中介绍过前向后向算法,就是一种动态规划的算法。在此我们将向前向后两种算法结合,来学习所有可能组合的序列,本质上是一种以时间换空间的做法。下面来详细介绍一下。
如果路径π经过B变换之后为真实路径,那么它肯定符合下面几个约束条件:1.第一个字符只能为blank或的第一个字符 2.最后一个字符只能为blank或的最后一个字符 3.在π中里连续的相同的字符必须要加blank 4.在π中里连续的不相同的字符之间可以有blank,但是不可以有其它字符。
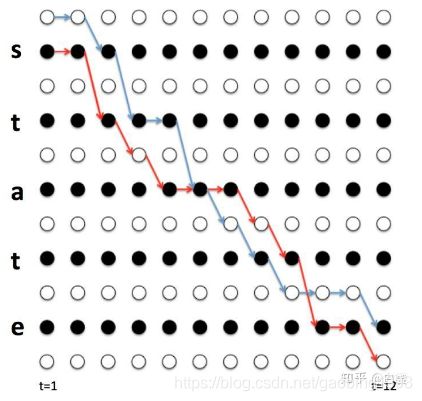
根据动态规划的思想我们知道,要求某一个条路径的概率,一般会先得到第一个时刻的概率,然后需要得到从前往后两个时刻之间的递推关系,这样可以通过第一个时刻递推得到每一个时刻的概率。因为现在的问题是要求某个时刻经过某个点,并且符合约束条件的所有路径的概率,我们称为总概率。那么我们以这个时刻为分界线,首先得到第一个时刻的概率和最后一时刻的概率,然后得到从前往后的递推关系和从后往前的递推关系。将向前和向后递推到当前时刻的总概率相乘,就可以得到t时刻经过某个点的概率了。
第一个时刻
我们定义向前的递推概率和:![]()
根据约束条件可以知道,第一个时刻只可以为 或者blank。所以我们通过计算
或者blank。所以我们通过计算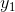 时刻blank和的概率之积的可以得到
时刻blank和的概率之积的可以得到 的值。
的值。
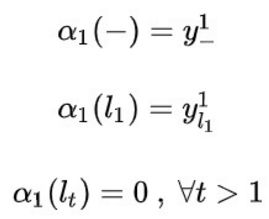
前向递推关系
同样根据约束条件可以得到,假如t时刻的字符k已经确定,那么前一个时刻的字符就只有三种情况:![]() 。所以我们得到前向递推关系:当前时刻为k总概率 = (前一时刻为k总概率+前一时刻为k-1总概率+前一时刻为blank总概率)*当前时刻为k概率。
。所以我们得到前向递推关系:当前时刻为k总概率 = (前一时刻为k总概率+前一时刻为k-1总概率+前一时刻为blank总概率)*当前时刻为k概率。
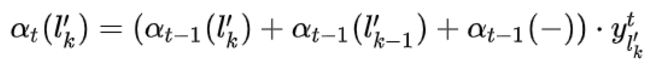
最后一个时刻
我们定义向后递推的概率和:![]()
根据约束条件,最后一个时刻T只能为blank或者中最后一个单词。跟向前算法一样,我们通过计算y最后时刻blank和最后一个单词的概率之积的可以得到![]() 的值。
的值。
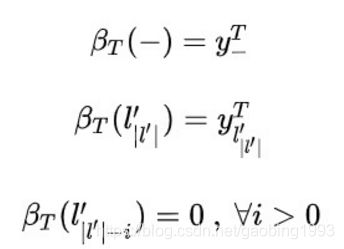
后向递推关系
根据约束条件,已知当前时刻值k,下一个时刻的值只能为![]() 。于是就有了下面的递推公式。
。于是就有了下面的递推公式。
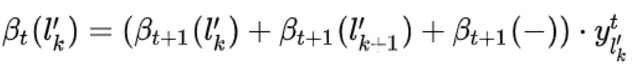
最终公式
将前向和后向概率和相乘,得到了下面的表达式,因为t时刻被计算了两次所以需要单独拎出来一个![]() 。注意真实路径和加入了blank的路径
。注意真实路径和加入了blank的路径![]() 对应字符的位置下标正好是1/2的关系。
对应字符的位置下标正好是1/2的关系。
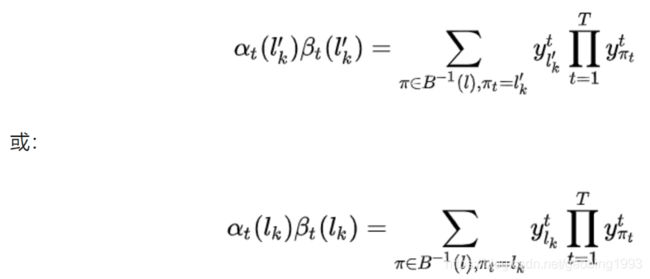
跟前面的![]() 表达式对比一下,我们就得到了前后向递推公式和
表达式对比一下,我们就得到了前后向递推公式和![]() 的表达式,如图二所示。其实前后向表达式中本来就多乘了当前时刻
的表达式,如图二所示。其实前后向表达式中本来就多乘了当前时刻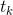 ,再给除掉就是当前时刻的总概率,把所有时刻加起来就是输出真实序列的总概率。
,再给除掉就是当前时刻的总概率,把所有时刻加起来就是输出真实序列的总概率。
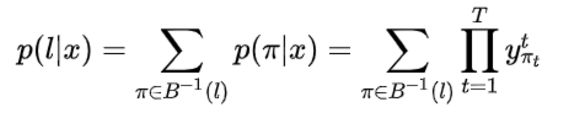
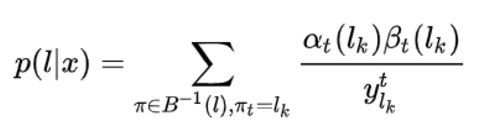
- 求梯度
忙了这么久,就是为了求出最终的梯度。公式如下,用总概率表达式对![]() 求偏导即可。
求偏导即可。![]() 是LSTM的输出,这样就可以进行最终的反向传播了。因为
是LSTM的输出,这样就可以进行最终的反向传播了。因为![]() 是从第一和最后一个时刻递推得到的,所以难度和复杂度会大大降低。
是从第一和最后一个时刻递推得到的,所以难度和复杂度会大大降低。

4.2 总结
本节我们介绍了文字识别框架CRNN+CTC,CRNN就是CNN+RNN,CNN负责提取特征,RNN学习序列信息。我们重点介绍了一下CTC翻译层,因为是第一次接触,也是一个创新的点。这是一个不需要对齐的损失,大大降低了人工标注的难度。其核心的思想就是给真实序列前后和字符间加上blank,其T时刻的所有可能序列的总概率就是最终预测的概率。为了降低复杂度,我们采用前后向递推式,得到了每个时刻的总概率的递推关系,将所有时刻加起来就得到了序列的总概率的递推关系式。然后对LSTM对应时刻的输出求偏导,就可以进行的反向传播,更新对应的参数。另外,CTC在推理的时候只扮演解码器的角色。
5.项目实战
5.1 ctpn文字检测
项目地址:https://github.com/xiaofengShi/CHINESE-OCR
参考文章:window10环境进行进行文字检测
下载完代码,然后参考上面的文章使之能够在windows系统正常的运行起来。
看这张照片,收获的季节到了,这是劳动人民最快乐的时候。

相关问题:
1.tensorflow和keras版本不匹配 参考:https://www.cnblogs.com/carle-09/p/11661261.html
2.UnicodeDecodeError: 'gbk' codec can't decode byte 0xa3 in position 389: illegal multibyte sequence
使用open函数读配置文件的时候,如果配置文件中有中文,要加编码格式encoding='UTF-8'
3.ValueError: Buffer dtype mismatch, expected 'int_t' but got 'long long'
修改cpython_nms.pyx 重新编译
27行为 cdef np.ndarray[np.int64_t, ndim=1] order = scores.argsort()[::-1]
30行为 cdef np.ndarray[np.int_t, ndim=1] suppressed = \
80行为 cdef np.ndarray[np.long, ndim=1] order = scores.argsort()[::-1]
83行为 cdef np.ndarray[np.long, ndim=1] suppressed = \
4.demo.py第22行回写图像的时候
如果指定一张图片测试可用原来代码的,如果遍历文件夹下*.*的图片测试改为image_file.split('\\')
5.2 CRNN+CTC文字识别
项目地址:https://github.com/chineseocr/chineseocr
该项目采用YoloV3进行底层特征提取。
好处是项目本身就提供了可视化界面操作,并且可以检测多种场景,多种角度的文字。
麻烦的是迁移到windows系统比较困难,因为很烦,所以我试了cpu版本的。gpu尝试失败之后,我就对它没有什么耐心了。反正是抱着学习的心态,什么版本也就都一样了。

相关问题:
1.Invalid argument: You must feed a value for placeholder tensor 'Placeholder_367' with dtype float and shape
启动的时候可能会报这个错,这说明某个库版本不对,需要严格的按照配置中的进行。
6.总结
本篇介绍了使用深度学习进行OCR检测的基本流程,并且介绍了文字检测框架ctpn和文字识别框架Crnn+CTC。总体上来讲,基于深度学习的算法要比传统的OCR更强大一些。并且OCR相当于是把CV和NLP的知识点给综合了起来,还是值得好好研究一下。
7.Battle Without Honor or Humanity
Without Humanity 没人性,不一定就是不好的,因为人性不一定都是好的。人性贪婪、自私、软弱。那么没有人性的要么就是魔鬼,要么就是神仙。鬼仙都离我太远,那么说说人吧!在我看来,我所认识的每一个人都是一个世界。就好像内存中的指针一样,不论我喜欢他们,或者是不喜欢他们,在他们的世界里面都会有一个引用对象指向我这个本体。这在一定意义上来说就是平行世界了。一个人流入另外一个人的世界,形式是多种多样的。普通的人像是队列,先进来的,也先出去了。那种热爱的,深爱的人像是栈,越早进来留的时间越长。我知道一个真相就是,不论我费劲心机的想要在你的世界停留多久,终究还是会消失的,这一个引用就被回收了。 最后,当所有的引用都被回收,没有任何一个指针指向我这个本体的时候,我就真的死掉了。所以我努力的认识很多人,交很多的朋友。可是最终才发现,一个人的内存原来是有限的,我用了很大的空间去装你,结果就装不下别人了 out of memory!
《杀死比尔》经典主题曲片段-Battle Without Honor or Humanity