Tajima‘s D群体遗传
Tajima’s D 中性检测的指标
Tajima’s D是由日本研究员田田文雄(Fumio Tajima)创建的群体基因检验统计数据。D的计算方法是两种遗传多样性测量值之间的差异:成对差异的平均数量和分离位点的数量,每个都按比例调整,以便在中等规模的恒定大小的群体中预期它们是相同的。
Tajima’s D检验的目的是区分随机演变的DNA序列(“中性”)和在非随机过程中演化的DNA序列,包括定向选择或平衡选择,群体统计学扩展或收缩,遗传搭便车或渐渗。随机进化的DNA序列含有突变,对生物的适应性和存活率没有影响。随机演变的突变被称为“中性”,而选择下的突变是“非中性的”。例如,您可能会发现导致产前死亡或严重疾病的突变正在被选中。从整体上看群体群体时,我们说中性突变的群体频率是通过遗传漂移随机波动的(即突变群体中群体百分比从一代到下一代变化,这个百分比同样可能会发生变化来上升或下降)。
遗传漂移的强度取决于种群大小。如果群体具有恒定大小且具有恒定的突变率,则群体将达到基因频率的平衡。该平衡具有重要的性质,包括分离位点的数量S,以及取样对之间的核苷酸差异的数量(这些称为成对差异)。为了标准化成对差异,使用成对差异的平均值或“平均”数量。这只是成对差异除以对数的总和,通常用π表示。
Tajima测试的目的是在突变和遗传漂变之间的平衡中识别不符合中性理论模型的序列。为了对DNA序列或基因进行测试,您需要对至少3个个体的同源DNA进行测序。 Tajima的统计量计算了采样DNA中分离位点总数(这些是多态性的DNA位点)的标准化度量,以及成对样本之间的平均突变数。比较其值的两个参数是群体遗传参数theta的矩估计方法,因此期望等于相同的值。如果这两个数字的差别只是人们可以合理地预期的那么多,那么中立性的零假设就不能被拒绝。否则,拒绝中立的零假设。
科学解释
在中性理论模型下,对于平衡时恒定大小的群体:

在上式中,S是分离位点的数量,n是样本数,N是有效种群大小,μ是检查的基因组基因座的突变率,i是下标总和。 但选择、群体波动和其他违反中性模型的行为(包括利率异质性和渐渗)将改变S和π的期望值,因此它们不再是预期的相等值。 对这两个变量(可能是正面的或负面的)的期望差异是D检验统计量的关键。
D,通过获取群体遗传参数θ的两个估计值之间的差异来计算。 这种差异称为d,D的计算方法是将d除以其方差的平方根(其标准差,按定义)。
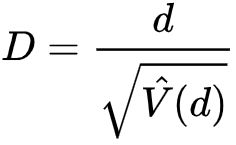
举例
假设您是一名研究未知基因的遗传学家。 作为研究的一部分,您可以从4四个随机的人(加上自己)中获取DNA样本。 为简单起见,您将序列标记为一串0,而对于其他四个人,当他们的DNA与您的DNA相同时,您将其置为标0,不同为1。
1 2
Position 12345 67890 12345 67890
Person Y 00000 00000 00000 00000
Person A 00100 00000 00100 00010
Person B 00000 00000 00100 00010
Person C 00000 01000 00000 00010
Person D 00000 01000 00100 00010
请注意4个多态位点(某人与您不同的位置,上面的3,7,13和19)。 现在比较每对序列并获得两个序列之间的平均多态性数。 需要进行“5选2”(共10对)比较。
个体Y是你!
You vs A: 3个多态
Person Y 00000 00000 00000 00000
Person A 00100 00000 00100 00010
You vs B: 2个多态
Person Y 00000 00000 00000 00000
Person B 00000 00000 00100 00010
You vs C: 2个多态
Person Y 00000 00000 00000 00000
Person C 00000 01000 00000 00010
You vs D: 3个多态
Person Y 00000 00000 00000 00000
Person D 00000 01000 00100 00010
A vs B: 1 polymorphism
Person A 00100 00000 00100 00010
Person B 00000 00000 00100 00010
A vs C: 3个多态
Person A 00100 00000 00100 00010
Person C 00000 01000 00000 00010
A vs D: 2个多态
Person A 00100 00000 00100 00010
Person D 00000 01000 00100 00010
B vs C: 2个多态
Person B 00000 00000 00100 00010
Person C 00000 01000 00000 00010
B vs D: 1 polymorphism
Person B 00000 00000 00100 00010
Person D 00000 01000 00100 00010
C vs D: 1 polymorphism
Person C 00000 01000 00000 00010
Person D 00000 01000 00100 00010
那么平均多态的个数是:(3+2+2+3+1+3+2+2+1+1)/10=2——参数1。
第二个估计是:M=S/a1
5个个体n=5,4个多态位点S=4,于是a1=1/1+1/2+1/3+1/4=2.08,M=4/2.08=1.92——参数2。
于是d=2-1.92=0.08。
Tajima’s D的意义
| D值 | 数学解释 | 生物学解释1 | 生物学解释2 |
|---|---|---|---|
| D=0 | Theta-Pi = Theta-k (Observed=Expected). 平均杂合度=多态位点的个数 | 观测变异类似于期望变异 | 群体根据突变-漂移平衡演变。 没有选择的证据 |
| D<0 | Theta-Pi < Theta-k (Observed| 稀有等位基因以高频率存在(超过稀有等位基因) |
最近的选择性清除,最近瓶颈后的群体扩张,与清除基因连锁 |
|
| D>0 | Theta-Pi > Theta-k (Observed>Expected). 单倍型数(更多平均杂合度)>多态位点的个数 | 稀有等位基因以低频率存在(缺少稀有等位基因) | 平衡选择,突然群体收缩 |