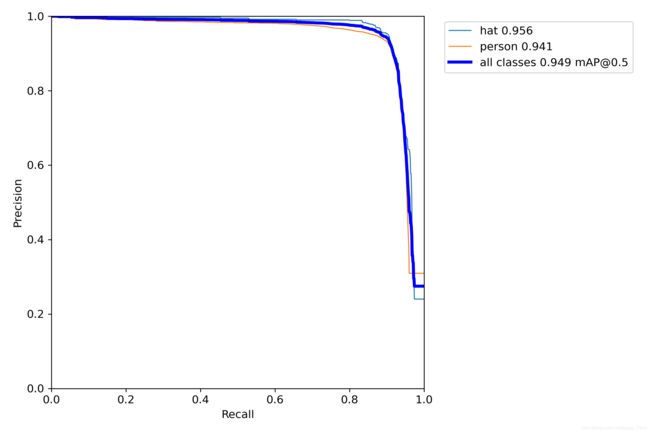
在安全帽佩戴检测数据集训练YOLOv5--训练过程记录
在安全帽佩戴检测数据集训练YOLOv5--训练过程记录
-
- 参考链接
- 数据集
- 安装依赖包
- 修改配置文件
- tensorboard
- 训练
参考链接
SafetyHelmetWearing-Dataset(安全帽佩戴检测数据集)
Train Custom Data(YOLOv5 训练自定义数据集)
yolov5汉化版
数据集
BaiduDrive
GoogleDrive
在安全帽佩戴检测数据集训练YOLOv5–数据集处理
安装依赖包
挂载谷歌云端硬盘:
from google.colab import drive
drive.mount("/gdrive")
%cd "/gdrive/My Drive/YOLOv5"
安装依赖:
%cd yolov5
%pip install -qr requirements.txt # install dependencies
import torch
from IPython.display import Image, clear_output # to display images
clear_output()
print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))
Setup complete. Using torch 1.7.0+cu101 _CudaDeviceProperties(name='Tesla T4', major=7, minor=5, total_memory=15079MB, multi_processor_count=40)
修改配置文件
我习惯cp个新的文件,也可以直接在原文件上面改:
- 修改数据配置文件
!cp data/coco128.yaml ../SHWD/custom_SHWD.yaml
nc是类别,这里names只有两类hat和person,也就是戴安全帽和没戴安全帽。
%%writefile ../SHWD/custom_SHWD.yaml
train: ../SHWD/images/train
val: ../SHWD/images/val
# number of classes
nc: 2
# class names
names: ['hat', 'person']
- 修改模型配置文件
!cp ./models/yolov5s.yaml ../SHWD/yolov5s.yaml
将nc改为2类:
%%writefile ../SHWD/yolov5s.yaml
# parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
这是最小的模型的配置文件。
你也可以试试其他更大的模型:

tensorboard
运行tensorboard可以看到训练过程:
%load_ext tensorboard
%tensorboard --logdir runs
训练
!python train.py --img 640 --batch 64 --epochs 100 --data ../SHWD/custom_SHWD.yaml --cfg ../SHWD/yolov5s.yaml --weights yolov5s.pt
–batch-size:如果显存不够16G建议设置32的batch-size,如果还不够,在适当调整
–cache:因为每次训练的时候都会执行Scanning images,速度还很慢,所以建议加上
Scanning images很慢的问题已经解决
有参:
--weights (☆)指定权重,如果不加此参数会默认使用COCO预训的yolov5s.pt,--weights ''则会随机初始化权重
--cfg (☆)指定模型文件
--data (☆)指定数据文件
--hyp指定超参数文件
--epochs (☆)指定epoch数,默认300
--batch-size (☆)指定batch大小,默认16,官方推荐越大越好,用你GPU能承受最大的batch size,可简写为--batch
--img-size 指定训练图片大小,默认640,可简写为--img
--name 指定结果文件名,默认result.txt
--device (☆)指定训练设备,如--device 0,1,2,3
--local_rank 分布式训练参数,不要自己修改!
--logdir 指定训练过程存储路径,默认./runs
--workers 指定dataloader的workers数量,默认8
无参:
--rect矩形训练
--resume 继续训练,默认从最后一次训练继续
--nosave 训练中途不存储模型,只存最后一个checkpoint
--notest 训练中途不在验证集上测试,训练完毕再测试
--noautoanchor 关闭自动锚点检测
--evolve超参数演变
--bucket使用gsutil bucket
--cache-images 使用缓存图片训练,速度更快
--image-weights 训练中对图片加权重
--multi-scale 训练图片大小+/-50%变换
--single-cls 单类训练
--adam 使用torch.optim.Adam()优化器
--sync-bn 使用SyncBatchNorm,只在分布式训练可用