paddleocr文本识别模型的训练
1、准备数据
训练自己的模型首先要有数据集,在我写的《paddleocr文本检测模型的训练》这篇文章的时候我已经提供了一份数据集,里面包含了文本检测和识别的数据集,由于那篇文章是文本检测的训练,所以只用到了文本检测的数据集,这里我用的是文本识别的数据集,有需要数据的可以去那篇文章里面找数据。文章链接。让我们来直观的感受一下数据集,数据集照片的图片如下所示:
数据的标签如下图所示,就是每行的前面是图片的路径,后面为该图片的标签内容。

这里要注意的是: txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
2、准备字典
使模型在训练时,可以将所有出现的字符映射为字典的索引。因此字典需要包含所有希望被正确识别的字符,{word_dict_name}.txt需要写成如下格式,并以 utf-8 编码格式保存。这个字典的作用就是,我们神经网络识别出来的是一个数字,这个数字就要找到对应文本中的字,因此,如果是训练自己的数据集的话,可以用官方自带的比较大的字典,里面包含了各种常用和生僻的字。如下图所示,paddleocr开源项目中包含了大量的字典。而字典的形式就是每一行一个字或者符号,这样更容易去将识别的结果映射出来。而本本所将的实验就是利用icdar2015这个数据集,该数据集只有字母和数字。


3、 训练自己的数据集
3.1、预训练模型的下载
下载预训练模型。首先文本识别有几个算法内置到paddleocr中,百度官方也做了大量的实验来验证其效果。如下图所示,算法模型有Rosetta、CRNN、StarNet、RARE、SRN。而骨干网络基本只有两个MobileNetV3、Resnet34_vd这个两个网络骨干,可以明显的看出,Resnet34_vd网络骨架的参数比MobileNetV3在相同算法模型下要好,但是相应的模型的大小也会大一些。所以要根据自己的需求来。
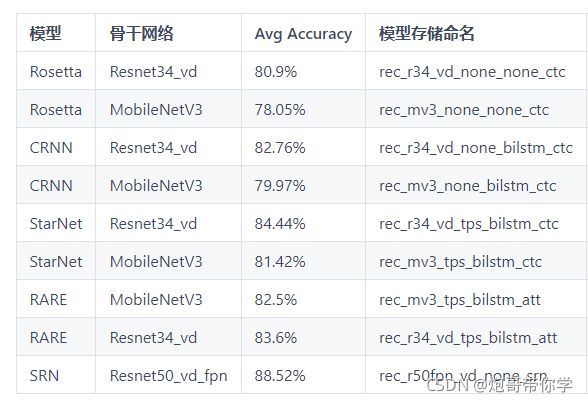
对应的backbone预训练模型可以从PaddleClas repo 主页中找到下载链接下载。本文章实验采用的是CRNN算法模型,Resnet34_vd网络骨架。
3.2、修改yml文件
由于本文利用的是CRNN算法模型,网络骨架为Resnet34_vd,因此要找到相应的yml文件才好,找到图中的rec_r34_vd_none_bilstm_ctc.yml这个yml文件来复制一份,并改名,这里改名为our.yml,这里复制粘贴一份新的是我个人的习惯,为了在改完yml文件之后还可以对比原来的文件,并不会破坏文件的原始性。

yml文件中的含义如链接所示。这里我讲一下我自己修改的一些地方。首先这里我添加了自己的预训练权重的地址,但是这里的预训练权重的后缀名不需要写上,否则会出错。然后填写了字典的地址,这里用的是开源项目中自带的字典。如果是训练自己的数据集,有自己的字典的话,可以换成自己的字典的地址。

如下图所示,将数据标注LMDBDataSet格式改为SimpleDataSet格式,因为paddlecor自己的标注工具标注出来的都是SimpleDataSet格式。然后再加上一行label_file_list:,这是用来填写数据集标签的地址的,这里最好是填写绝对路径。验证集改动和上述相同。

填写数据集和标签地址的时候有个坑要说一下:
我在训练的时候报错是找不到我的图片,仔细检查才发现,是路径中多了一个train/这样的路径,后面我打开标签文件我才知道其中的问题所在。

因为我填写的图片的路径为D:/PycharmProjects/PaddleOCR/PaddleOCR-release-2.2/data/train/,然后读取标签文件的时候,先将标签文件的照片的路径取出和上面数据集的路径整合到一起,指向该照片的路径,然后再去后面的标签。这样就变成了一个照片一个路径,再对应一个标签。然后我将数据集的路径改为D:/PycharmProjects/PaddleOCR/PaddleOCR-release-2.2/data/,不要忘记后面的/,就可以了。验证集也是同理。

然后在模型验证阶段,又出现了找不到数据的报错,仔细看了一下,这个路径中间是有空格的,当然是读取不到的。不符合我们上述的数据集的格式。txt文件中默认请将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。

将验证集的标签文件打开后发现,的确标注中出现了大量的空格。利用如下的脚本将标签文件中的空格去除掉。

# 输入输出文件的地址
IN_PATH = r'test_label.txt'
OUT_PATH = r'test_label1.txt'
# 将文中的空格去除
new = []
f = open(IN_PATH, "r", encoding='utf-8')
f.readline()
for line in f:
line = line.replace(' ', '')
new.append(line)
print(new)
# 以写的方式打开文件,如果文件不存在,就会自动创建,如果存在就会覆盖原文件
file_write_obj = open(OUT_PATH, 'w')
for var in new:
file_write_obj.writelines(var)
file_write_obj.close()
利用如上的脚本后就可以将标签文件改正过来了。如下图可示:
![]()
如下图所示,由于电脑的配置不同,所以输入网络的批次大小不一样,我的是3060,6GB的显卡,我输入网络的批次为64,核心数为4,根据的自己的显卡调整该大小,要不然会报错显存溢出,或者直接训练不了。这里的训练和验证的送入批次都需要修改。

3.3 、开始训练模型
打开pycharm的终端。输入如下的命令。可以根据自己的yml文件来修改路径和名字。
python tools/train.py -c configs/rec/our.yml

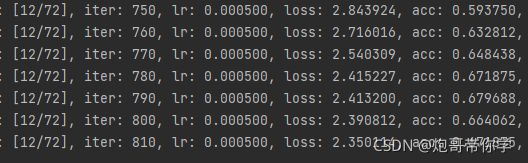
出现下图的显示就表示训练已经开始了,一开始的精确度为0,训练几轮之后就好了。
这是训练了12轮后的效果。可以看到精确度已经达到了65左右了。足以说明Resnet34_vd的效果的确是很不错的。
训练结束以后,会在如下的目录中生成如下的权重文件。
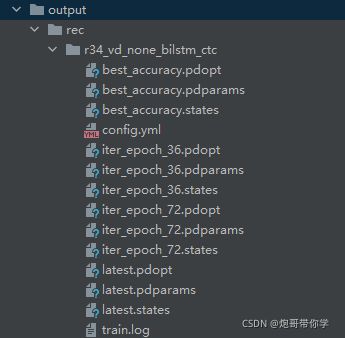
利用生成最好的权重文件对图中文字进行检测,利用如下的命令。
python tools/infer_rec.py -c output/rec/r34_vd_none_bilstm_ctc/config.yml -o Global.pretrained_model=output/rec/r34_vd_none_bilstm_ctc/best_accuracy Global.load_static_weights=f
alse Global.infer_img=data/test/
在pycharm终端中输入上面的命令,-c后面的是你的yml文件的地址,-o是你的训练好的权重的地址,但是后缀不要加,Global.infer_img为推理图片的文件夹位置。我的推理效果如下所示,可以看到,效果还是不错的。
