Selenium+超级鹰进行识别滑动操作
在日常爬虫过程中会遇到登录时进行图片识别和滑动识别验证,针对这种情况该如何进行呢,在这里和大家分享下我的方法,希望对大家有所帮助。
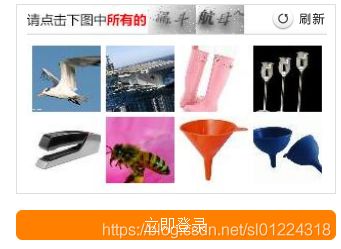
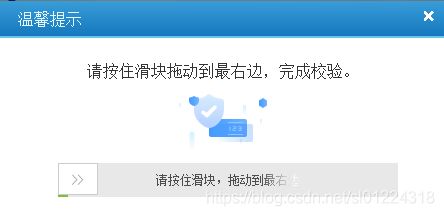
我的思路是先进行图片验证码识别,然后识别成功后,进入滑动识别界面,使用selenium中的方法来模拟鼠标进行滑动并进行登录,具体流程如下:
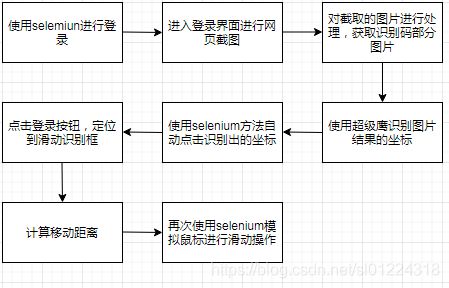
思路明确之后,就是进行代码编写,以下是具体代码:
#-*- coding:utf-8 -*-
from selenium import webdriver
import requests
from time import sleep
from PIL import Image
from selenium.webdriver import ActionChains
from selenium使用.chaojiying import *
#driver = webdriver.Firefox()
driver = webdriver.Chrome()
driver.maximize_window() #屏幕最大化
driver.get('https://kyfw.12306.cn/otn/resources/login.html')
#切换到密码登录界面
sleep(1)
driver.find_element_by_xpath('//li/a[text()="账号登录"]').click()
sleep(2) #等待验证码图片加载出来
driver.save_screenshot('./login.jpg')
#将验证码的图片抠取出来
code_img_ele = driver.find_element_by_xpath('//div[@id="J-loginImgArea"]/img')
location = code_img_ele.location #获取验证码图片左上角的坐标x,y
size = code_img_ele.size #获取验证码图片的尺寸大小
print('location:%s'%location)
print('size:%s'%size)
#获取验证码左上角和右下角的坐标位置
rangle = (
int(location['x']),int(location['y']),int(location['x'] + size['width']),int(location['y'] + size['height']))
print(rangle)
#至此验证码图片区域位置就获取下来了,然后通过PIL中的Image方法来截取验证码图片
i = Image.open('./login.jpg')
code_img_name = './code.png'
#crop根据指定区域进行裁剪
frame = i.crop(rangle)
frame.save(code_img_name) #注意保存的图片类型不能是jpg格式的,要保存成png格式的
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID') #用户中心>>软件ID 生成一个替换 96001
im = open('./code.png', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
result= chaojiying.PostPic(im, 9004)['pic_str'] #9004返回识别的结果坐标
print('result:%s'%result)
#超级鹰返回的格式,32,75|252,149
#对超级鹰识别出来的列表进行处理,处理格式为[[1,2],[3,4],[4,5]],然后使用for循环有几个列表就进行几次点击
all_list = [] #存储将要被点击的坐标位置
if '|' in result:
list_1 = result.split('|') #返回的是list
count_1 = len(list_1)
for i in range(count_1):
xy_list = []
x = list_1[i].split(',')[0]
y = list_1[i].split(',')[1]
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
else:
xy_list = []
x = result.split(',')[0]
y = result.split(',')[1]
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
print(all_list)
#遍历列表,使用动作链对每一个元素对应的x,y指定的位置进行点击操作
for l in all_list:
x = l[0]
y = l[1]
ActionChains(driver).move_to_element_with_offset(code_img_ele,x,y).click().perform() #找到参照物位置并以参照物中的坐标进行点击
sleep(1)
#进行登录
driver.find_element_by_xpath('//input[@id="J-userName"]').send_keys('用户名')#用户名输入
sleep(0.5)
driver.find_element_by_xpath('//input[@id="J-password"]').send_keys('密码')#用户密码输入
sleep(0.5)
driver.find_element_by_xpath('//a[@id="J-login"]').click() #进行点击登录
sleep(3)
huadong = driver.find_element_by_xpath('//div[@id="login_slide_box"]/div[2]/div/div[3]/div/div/div[2]/span') #定位到滑动块
button = driver.find_element_by_xpath('//div[@id="login_slide_box"]/div[2]/div/div[3]/div/div[1]/span') #定位到按钮
huadong_location = huadong.location #获取验证码图片左上角的坐标x,y
huadong_size = huadong.size #获取验证码图片的尺寸大小
print('huadong_location:%s'%huadong_location)
print('huadong_size:%s'%huadong_size)
button_location = button.location #获取验证码图片左上角的坐标x,y
button_size = button.size #获取验证码图片的尺寸大小
#print('button_location:%s'%button_location)
#print('button_size:%s'%button_size)
def get_move_track(gap):
track = [] # 移动轨迹
current = 0 # 当前位移
# 减速阈值
mid = gap * 4 / 5 # 前4/5段加速 后1/5段减速
t = 0.2 # 计算间隔
v = 0 # 初速度
while current < gap:
if current < mid:
a = 5 # 加速度为+5
else:
a = -5 # 加速度为-5
v0 = v # 初速度v0
v = v0 + a * t # 当前速度
move = v0 * t + 1 / 2 * a * t * t # 移动距离
current += move # 当前位移
track.append(round(move)) # 加入轨迹
return track
def move_slider(track):
ActionChains(driver).click_and_hold(button).perform()
for x in track: # 只有水平方向有运动 按轨迹移动
ActionChains(driver).move_by_offset(xoffset=x, yoffset=0).perform()
sleep(0.2)
sleep(1)
ActionChains(driver).release().perform() # 松开鼠标
gap = huadong_size['width'] - button_size['width']
#gap = gap - 6
track = get_move_track(gap)
print('track"%s' %track)
move_slider(track)
在代码部分有些方法可以写成函数,这样会更方便些,这里我只对部分方法写成了函数,有兴趣的各位可以自己整理写成函数的方法。代码完成后就可以进行运行,并能进行滑动识别。目前有些高级网站会进行一个监测,即如果被后台监控出操作是软件进行自动控制的话,会对本次操作进行阻止,像12306网站就是,所以如果更高级的网站,还需要进行其他“欺骗”。