代理的使用场景
编写爬虫代码的程序员,永远绕不开就是使用代理,在编码过程中,你会碰到如下情形:
网络不好,需要代理;
目标站点国内访问不了,需要代理;
网站封杀了你的 IP,需要代理。
使用 HttpProxyMiddleware 中间件
本次的测试站点依旧使用 http://httpbin.org/,通过访问 http://httpbin.org/ip 可以获取当前请求的 IP 地址。
HttpProxyMiddleware 中间件默认是开启的,可以查看其源码重点为 process_request() 方法。
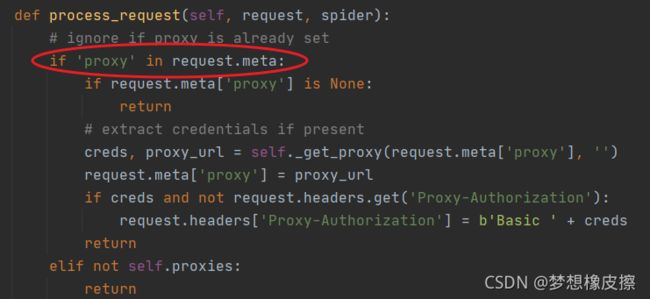
修改代理的方式非常简单,只需要在 Requests 请求创建的时候,增加 meta 参数即可。
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/ip']
def start_requests(self):
yield scrapy.Request(url=self.start_urls[0], meta={'proxy': 'http://202.5.116.49:8080'})
def parse(self, response):
print(response.text)
接下来通过获取一下 https://www.kuaidaili.com/free/ 网站的代理 IP,并测试其代理是否可用。
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
start_urls = ['https://www.kuaidaili.com/free/']
def parse(self, response):
IP = response.xpath('//td[@data-title="IP"]/text()').getall()
PORT = response.xpath('//td[@data-title="PORT"]/text()').getall()
url = 'http://httpbin.org/ip'
for ip, port in zip(IP, PORT):
proxy = f"http://{ip}:{port}"
meta = {
'proxy': proxy,
'dont_retry': True,
'download_timeout': 10,
}
yield scrapy.Request(url=url, callback=self.check_proxy, meta=meta, dont_filter=True)
def check_proxy(self, response):
print(response.text)
接下来将可用的代理 IP 保存到 JSON 文件中。
import scrapy
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
start_urls = ['https://www.kuaidaili.com/free/']
def parse(self, response):
IP = response.xpath('//td[@data-title="IP"]/text()').getall()
PORT = response.xpath('//td[@data-title="PORT"]/text()').getall()
url = 'http://httpbin.org/ip'
for ip, port in zip(IP, PORT):
proxy = f"http://{ip}:{port}"
meta = {
'proxy': proxy,
'dont_retry': True,
'download_timeout': 10,
'_proxy': proxy
}
yield scrapy.Request(url=url, callback=self.check_proxy, meta=meta, dont_filter=True)
def check_proxy(self, response):
proxy_ip = response.json()['origin']
if proxy_ip is not None:
yield {
'proxy': response.meta['_proxy']
}
同时修改 start_requests 方法,获取 10 页代理。
class PtSpider(scrapy.Spider):
name = 'pt'
allowed_domains = ['httpbin.org', 'kuaidaili.com']
url_format = 'https://www.kuaidaili.com/free/inha/{}/'
def start_requests(self):
for page in range(1, 11):
yield scrapy.Request(url=self.url_format.format(page))
实现一个自定义的代理中间件也比较容易,有两种办法,第一种继承 HttpProxyMiddleware,编写如下代码:
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from collections import defaultdict
import random
class RandomProxyMiddleware(HttpProxyMiddleware):
def __init__(self, auth_encoding='latin-1'):
self.auth_encoding = auth_encoding
self.proxies = defaultdict(list)
with open('./proxy.csv') as f:
proxy_list = f.readlines()
for proxy in proxy_list:
scheme = 'http'
url = proxy.strip()
self.proxies[scheme].append(self._get_proxy(url, scheme))
def _set_proxy(self, request, scheme):
creds, proxy = random.choice(self.proxies[scheme])
request.meta['proxy'] = proxy
if creds:
request.headers['Proxy-Authorization'] = b'Basic ' + creds
代码核心重写了 __init__ 构造方法,并重写了 _set_proxy 方法,在其中实现了随机代理获取。
同步修改 settings.py 文件中的代码。
DOWNLOADER_MIDDLEWARES = {
'proxy_text.middlewares.RandomProxyMiddleware': 543,
}
创建一个新的代理中间件类
class NRandomProxyMiddleware(object):
def __init__(self, settings):
# 从settings中读取代理配置 PROXIES
self.proxies = settings.getlist("PROXIES")
def process_request(self, request, spider):
request.meta["proxy"] = random.choice(self.proxies)
@classmethod
def from_crawler(cls, crawler):
if not crawler.settings.getbool("HTTPPROXY_ENABLED"):
raise NotConfigured
return cls(crawler.settings)
可以看到该类从 settings.py 文件中的 PROXIES 读取配置,所以修改对应配置如下所示:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': None,
'proxy_text.middlewares.NRandomProxyMiddleware': 543,
}
# 代码是前文代码采集的结果
PROXIES = ['http://140.249.48.241:6969',
'http://47.96.16.149:80',
'http://140.249.48.241:6969',
'http://47.100.14.22:9006',
'http://47.100.14.22:9006']
如果你想测试爬虫,可编写一个随机返回请求代理的函数,将其用到任意爬虫代码之上,完成本博客任务。
以上就是python爬虫框架scrapy代理中间件掌握学习教程的详细内容,更多关于scrapy框架代理中间件学习的资料请关注脚本之家其它相关文章!