100道Python面试题总结
面试题
-
-
- 第1题:1行代码实现1到100的和?
- 第2题:如何使用Python输出一个[斐波那契数列]Fibonacci
- 第3题:列出几个python标准库
- 第4题:下面Python代码的运行结果是?
- 第5题:python实现列表去重的方法?
- 第6题:在Python中读取大文件
- 第7题:如何避免转义,给字符串加哪个字母表示原始字符串?
- 第8题:python中断言方法举例?
- 第9题:列出python中可变数据类型和不可变数据类型,并简述原理
- 第10题:你如何管理不同版本的代码?
- 第11题:python中生成随机整数、随机小数、0~1之间小数方法?
- 第12题:迭代器、可迭代对象、生成器?
- 第13题:单引号,双引号,三引号的区别?
- 第14题:Python是如何进行内存管理的?
- 第15题:写一个函数, 输入一个字符串, 返回倒序排列的结果?
- 第16题:列表和元组有什么不同?
- 第17题:什么是负索引?
- 第18题: 如何随机打乱列表中元素,要求不引用额外的内存空间?
- 第19题:解释 Python 中的 join() 和 split() 函数?
- 第20题:如何删除字符串中的前置空格?
- 第21题:Python 中的 pass 语句有什么作用?
- 第22题:Python里面如何实现tuple和list的转换?
- 第23题:Python里面search()和match()的区别?
- 第24题: 如何用Python删除一个文件?
- 第25题: is 和 == 的区别?
- 第26题:a=1, b=2, 不用中间变量交换a和b的值?
- 第27题:说说你对zen of python的理解,你有什么办法看到它?
- 第28题:字符串的拼接–如何高效的拼接两个字符串?
- 第29题: list = ['a','a','a',1,2,3,4,5,'A','B','C']提取出”12345”?
- 第30题: 什么是pickling和unpickling?
- 第31题: 说一说Python自省?
- 第32题:什么是python猴子补丁python monkey patch?
- 第33题:阅读下面的代码,默读出A0,A1至An的最终值。
- 第34题:如何提高python的运行效率?
- 第35题: Python字典有什么特点,从字典中取值,时间复杂度是多少?
- 第36题: 多线程、多进程?
- 第37题: 请尽可能列举python列表的成员方法,并给出以下列表操作的答案:
- 第38题:列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]。
- 第39题:设计一个函数返回给定文件名的后缀?
- 第40题: 这两个参数是什么意思:*args,**kwargs?我们为什么要使用它们?
- 第41题: 求出0~n的所有正整数中数字k(0~9)出现的次数。编程语言不限,Python优先。
- 第42题: 如何在python中使用三元运算符?
- 第43题: print 调用 Python 中底层的什么方法?
- 第44题:range 和 xrange 的区别?
- 第45题: 4G 内存怎么读取一个 5G 的数据?
- 第46题:在except中return后还会不会执行finally中的代码?怎么抛出自定义异常?介绍一下 except 的作用和用法?
- 第47题:在Python中输入某年某月某日,判断这一天是这一年的第几天?(可以用 Python 标准库)
- 第48题: docstring是什么?
- 第49题:PYTHONPATH变量是什么?
- 第50题: Python中的不可变集合(frozenset)是什么?
- 第51题:如何检查字符串中所有的字符都为字母数字?
- 第52题:什么是Python中的连接(concatenation)?
- 第53题:Python的不足之处
- 第54题: Python 中的 os 模块常见方法?
- 第55题: Python语言中的模块和包是什么?
- 第56题: 谈一下什么是解释性语言,什么是编译性语言?
- 第57题:如何提高Python 程序的运行性能?
- 第58题: Python 中的作用域?
- 第59题:如何理解 Python 中字符串中的\字符?
- 第60题:为什么函数名字可以当做参数用?
- 第61题: Python如何爬取 HTTPS 网站?
- 第62题: 函数参数传递,下面程序运行的结果是?
- 第63题: Python 里面如何拷贝一个对象?
- 第64题:Python 程序中中文乱码如何解决?
- 第65题: Python 列举出一些常用的设计模式?
- 第66题:将下面的Python代码简化?
- 第67题: 如何解决验证码的问题,用什么模块,听过哪些人工打码平台?
- 第68题: ip 被封了怎么解决,自己做过 ip 池么?
- 第69题: 在 Python 中,list,tuple,dict,set 有什么区别,主要应用在什么场景?
- 第70题: 请描述方法重载与方法重写?
- 第71题: 如何用 Python 来发送邮件?
- 第72题:是否了解线程的同步和异步?
- 第73题:是否了解网络的同步和异步?
- 第74题:你是否了解MySQL数据库的几种引擎?
- 第75题: 修改以下Python代码,使得下面的代码调用类A的show方法?
- 第76题:修改以下Python代码,使得代码能够运行
- 第77题: 下面这段代码的输出是什么?
- 第78题: 下面这段代码输出什么?
- 第79题:如何添加代码,使得没有定义的方法都调用myfunc方法?
- 第80题: python下多线程的限制以及多进程中传递参数的方式?
- 第81题:解释一下python的and-or语法
- 第82题: 请至少列举5个 PEP8 规范?
- 第83题: HTTPS和HTTP的区别:
- 第84题:简述Django的orm
- 第85题: Flask中的请求上下文和应用上下文是什么?
- 第86题:django中间件的使用?
- 第87题: django开发中数据做过什么优化?
- 第88题: 解释一下 Django 和 Tornado 的关系、差别?
- 第89题:什么是restful API ,谈谈你的理解?
- 第90题: 简述解释型和编译型编程语言?
- 第91题:Python解释器种类以及特点?
- 第92题: 位和字节的关系?
- 第93题: 字节码和机器码的区别?
- 第94题:Python3和Python2中 int 和 long的区别?
- 第95题:是否遇到过python的模块间循环引用的问题,如何避免它?
- 第96题:简单介绍一下python函数式编程?
- 第97题:python中函数装饰器有什么作用?
- 第98题: 按照要求完成编码?
- 第99题:如何理解 Django 被称为 MTV 模式?
- 第100题:解释下什么是 ORM 以及它的优缺点是什么?
- 第101题:Django 系统中如何配置数据库的长连接?
- 第102题: 请解释一下python的线程锁Lock和Rlock的区别,以及你曾经在项目中是如何使用的?
- 第103题:字典、列表查询时的时间复杂度是怎样的?
- 结尾给大家推荐一个非常好的学习教程,希望对你学习Python有帮助!
-
第1题:1行代码实现1到100的和?
分析:这题考察的是对Python内置函数的了解程度
Python常见的内置函数有

官方查询手册如下
https://docs.python.org/3/library/functions.html
图片中我框选的是比较常用的一些,你可能见过,这题考察的是sum也就是求和
具体的使用
sum(iterable[, start])
- iterable – 可迭代对象,如:列表、元组、集合。
- start – 指定相加的参数,如果没有设置这个值,默认为0。
例如
sum([1,2,3]) # 结果为6
sum([1,2,3],5) # 结果为11
python一行代码如何实现1~100的和
还要用到第二个内置函数 range()
range(start, stop[, step])
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
- stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
解答:
sum(range(1,101))
第2题:如何使用Python输出一个[斐波那契数列]Fibonacci
斐波那契数列(Fibonacci sequence),又称黄金分割数列、因数学家列昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”。
例子:1、1、2、3、5、8、13、21、34、……
解法1:
100以内的斐波那契数列
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
x=1
y=1
print(x,end=" ")
print(y,end=" ")
while(True):
z=x+y
x=y
y=z
if(z>100): #当z>100的时候,终止循环
break
print(z,end=" ")
解法2:
递归的办法,这个需要数学公式的记忆了
在数学上,斐波纳契数列以如下被以递归的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)
#递归
def fibo(n):
if n <= 1:
return n
else:
return (fibo(n - 1) + fibo(n - 2))
m = int(input("打印前多少项?"))
if m <= 0:
print("请输入正整数!")
else:
print("fibo:")
for i in range(1,m):
print(fibo(i))
解法3:
迭代,用递归当数据大的时候,会出现效率问题
def fibo(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1 # 退出标识
for n in fibo(5):
print (n)
经过试验,比迭代速度快很多
time.clock()说明
cpu 的运行机制:cpu是多任务的,例如在多进程的执行过程中,一段时间内会有对各进程被处理。一个进程从从开始到结束其实是在这期间的一些列时间片断上断断续续执行的。所以这就引出了程序执行的cpu时间(该程序单纯在cpu上运行所需时间)和墙上时钟wall time。
time.time()是统计的wall time(即墙上时钟),也就是系统时钟的时间戳(1970纪元后经过的浮点秒数)。所以两次调用的时间差即为系统经过的总时间。
time.clock()是统计cpu时间 的工具,这在统计某一程序或函数的执行速度最为合适。两次调用time.clock()函数的插值即为程序运行的cpu时间。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import time
def fibo(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
t1 = time.clock()
for n in fibo(100):
print (n)
t2 = time.clock()
print(t2-t1)
解法4:
使用列表查看一下速度
import time
def fibo(n):
result_list = []
a, b = 0, 1
while n > 0:
result_list.append(b)
a, b = b, a + b
n -= 1
return result_list
t1 = time.clock()
print(fibo(1000))
t2 = time.clock()
print(t2-t1)
第3题:列出几个python标准库
你先明确的是什么是Python标准库
- Python标准库(standard library)。
- 标准库会随着Python解释器,一起安装在你的电脑中的。它是Python的一个组成部分。
- 这些标准库是Python为你准备好的利器,可以让编程事半功倍。
文档手册可以查阅 > https://docs.python.org/zh-cn/3.7/library/index.html
了解这个内容,这道题回答起来就非常简单了
- os模块
- re模块
- pickle 模块
- datetime模块
- time模块
- math模块
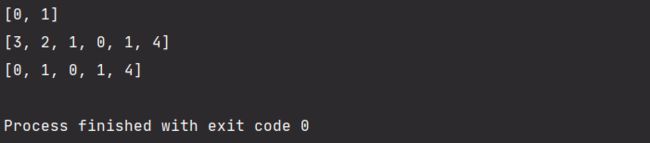
第4题:下面Python代码的运行结果是?
这种题目,考察的是代码默读能力
def f(x,l=[]):
for i in range(x):
l.append(i*i)
print(l)
f(2)
f(3,[3,2,1])
f(3)
f(2)
def f(2,l=[]):
for i in range(2): # i=0,1
l.append(i*i) # [0,1]
print(l)
f(3,[3,2,1])
def f(3,l=[3,2,1]):
for i in range(3): # i=0,1,2
l.append(i*i) # [3,2,1,0,1,4]
print(l)
f(3)
def f(3,l=[]):
for i in range(3): # i=0,1,2
l.append(i*i) # [0,1,4] ???对吗?
print(l)
这个地方,你需要避免踩坑,一定要注意列表是可变的,如果单独的写没有任何问题,但是函数调用的三行代码放在一起就有点意思了
f(3,[3,2,1]) 将l进行了重新赋值。但是第三次调用函数使用的依旧是第一次的l,所以避免踩坑哦~~~~
f(3)运行的正确结果是[0,1,0,1,4]
def f(x,l=[]):
for i in range(x):
l.append(i*i)
print(l)
f(2)
f(3,[3,2,1])
f(3)
结果:
第5题:python实现列表去重的方法?
简单直接的办法,集合里面的元素不可以重复
my_list = [1,1,2,2,3,3,5,6,7,88]
my_set = set(my_list)
my_list = [x for x in my_set]
my_list
循环判断去重
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
ids = [1,1,2,2,3,3,5,6,7,88]
news_ids = []
for id in ids:
if id not in news_ids:
news_ids.append(id)
print(news_ids)
字典的fromkeys方法实现
my_list=[1,1,2,2,3,3,5,6,7,88]
d = {
}.fromkeys(my_list)
print(d.keys())
第6题:在Python中读取大文件
- 利用生成器generator
def read_in_block(file_path):
BLOCK_SIZE = 1024
with open(file_path, "r") as f:
while True:
block = f.read(BLOCK_SIZE) # 每次读取固定长度到内存缓冲区
if block:
yield block
else:
return # 如果读取到文件末尾,则退出
def test3():
file_path = "/tmp/test.log"
for block in read_in_block(file_path):
print block
- 迭代器进行迭代遍历:for line in file
def test4():
with open("/tmp/test.log") as f:
for line in f:
print line
for line in f 这种用法是把文件对象f当作迭代对象, 系统将自动处理IO缓冲和内存管理, 这种方法是更加pythonic的方法。 比较简洁。
Pythonic追求的是对Python语法的充分发挥,写出的代码带Python味儿,而不是看着向C或JAVA
第7题:如何避免转义,给字符串加哪个字母表示原始字符串?
这个就面试题的要点是几个特殊Python3字符串前缀u、b、r
- 无前缀 & u前缀
字符串默认创建即以Unicode编码存储,可以存储中文。
string = 'a' 等效于 string = u'a'
Unicode中通常每个字符由2个字节表示
u'a' 即 u'\u0061' 实际内存中为 [0000 0000] [0110 0001]
- b前缀
字符串存储为Ascll码,无法存储中文。
- r前缀
与上述两种不是一样的东西了。
r前缀就相当于三引号,主要解决的是 转义字符,特殊字符 的问题,其中所有字符均视为普通字符。
所以这道题的正确答案是r前缀
第8题:python中断言方法举例?
assert 语句,在需要确保程序中的某个条件一定为真才能让程序运行的话就非常有用
下面做一些assert用法的语句供参考:
assert 1==1
assert 2+2==2*2
assert len(['my boy',12])<10
assert range(4)==[0,1,2,3]
这里介绍几个常用断言的使用方法,可以一定程度上帮助大家对预期结果进行判断。
- assertEqual
- assertNotEqual
- assertTrue
- assertFalse
- assertIsNone
- assertIsNotNone
assertEqual 和 assertNotEqual
- assertEqual:如两个值相等,则pass
- assertNotEqual:如两个值不相等,则pass
使用方法:
assertEqual(first,second,msg)其中first与second进行比较,如果相等则通过;
msg为失败时打印的信息,选填;
断言assertNotEqual反着用就可以了。
assertTrue和assertFalse
- assertTrue:判断bool值为True,则pass
- assertFalse:判断bool值为False,则Pass
使用方法:
assertTrue(expr,msg)其中express输入相应表达式,如果表达式为真,则pass;
msg选填;
断言assertFalse如果表达式为假,则pass
assertIsNone和assertIsNotNone
- assertIsNone:不存在,则pass
- assertIsNotNone:存在,则pass
使用方法:
assertIsNone(obj,msg)检查某个元素是否存在
第9题:列出python中可变数据类型和不可变数据类型,并简述原理
不可变数据类型:
数值型、字符串型string和元组tuple
不允许变量的值发生变化,如果改变了变量的值,相当于是新建了一个对象,而对于相同的值的对象,在内存中则只有一个对象(一个地址),如下图用id()方法可以打印对象的id.
可变数据类型:
列表list和字典dict
允许变量的值发生变化,即如果对变量进行append、+=等这种操作后,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化。
相同的值在内存中可能会存在不同的对象,即每个对象都有自己的地址,相当于内存中对于同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
第10题:你如何管理不同版本的代码?
git,svn两个都要说到,github,码云也要提及,面试官想要的就是版本管理工具,你只要选择一个你熟悉的,疯狂的说一通就可以了,最好说一下自己以前做过哪些开源的项目,放在上面,没有,就另当别论了。
第11题:python中生成随机整数、随机小数、0~1之间小数方法?
python中生成随机整数
import random
random.randint(1,10)
随机小数
看自己习惯,可以用random库,也可以用numpy库
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import random
random.random()
# 利用np.random.randn(5)生成5个随机小数
import numpy as np
np.random.randn(5)
0~1之间小数
random.random()
第12题:迭代器、可迭代对象、生成器?
第一步,你要知道什么是迭代
对list、tuple、str等类型的数据使用for...in...的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代。
从结果去分析原因,能被for循环的就是“可迭代的”,但是如果正着想,for怎么知道谁是可迭代的呢?
假如我们自己写了一个数据类型,希望这个数据类型里的东西也可以使用for被一个一个的取出来,那我们就必须满足for的要求— 这个要求就叫做 协议。
可以被迭代要满足的要求就叫做:可迭代协议。
可迭代协议的定义非常简单,就是内部实现了__iter()__方法
如果某个对象中有_ iter _()方法,这个对象就是可迭代对象 (Iterable)
if '__iter__' in dir(str)
通俗易懂 :可以被for循环迭代的对象就是可迭代对象。
从代码上面可以使用isinstance()判断一个对象是否是Iterable对象
from collections import Iterable
a = isinstance([], Iterable)
b = isinstance({
}, Iterable)
c = isinstance('abc', Iterable)
d = isinstance((x for x in range(10)), Iterable)
e = isinstance(100, Iterable)
print(a,b,c,d,e)
结论
True True True True False
只有最后的数字不是可迭代对象
可迭代对象的本质
我们分析对可迭代对象进行迭代使用的过程,发现每迭代一次(即在for…in…中每循环一次)都会返回对象中的下一条数据,一直向后读取数据直到迭代了所有数据后结束。
那么,在这个过程中就应该有一个“人”去记录每次访问到了第几条数据,以便每次迭代都可以返回下一条数据。
我们把这个能帮助我们进行数据迭代的“人”称为迭代器(Iterator)
可迭代对象的本质就是可以 向我们提供一个这样的中间“人”即迭代器 帮助我们对其进行迭代遍历使用。
可迭代对象通过__iter__方法向我们提供一个迭代器,在迭代一个可迭代对象的时候,实际上就是先获取该对象提供的一个迭代器,然后通过这个迭代器来依次获取对象中的每一个数据。
综上所述,一个具备了__iter__方法的对象,就是一个可迭代对象。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
class MyList(object):
def __init__(self):
self.container = []
def add(self, item):
self.container.append(item)
def __iter__(self):
"""返回一个迭代器"""
# 我们暂时忽略如何构造一个迭代器对象
pass
mylist = MyList()
from collections import Iterable
isinstance(mylist, Iterable)
iter()函数与next()函数
list、tuple等都是可迭代对象,我们可以通过iter()函数获取这些可迭代对象的迭代器。
然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。iter()函数实际上就是调用了可迭代对象的__iter__方法。
>>> i = iter('spam')
>>> next(i)
's'
>>> next(i)
'p'
>>> next(i)
'a'
>>> next(i)
'm'
>>> next(i)
Traceback (most recent call last):
File "" , line 1, in <module>
next(i)
StopIteration
>>>
当序列遍历完时,将抛出一个StopIteration异常。这将使迭代器与循环兼容,因为它们将捕获这个异常以停止循环。
要创建定制的迭代器,可以编写一个具有next方法的类。
迭代器Iterator
通过上面的分析,现在你应该已经知道了,迭代器是用来帮助我们记录每次迭代访问到的位置,当我们对迭代器使用next()函数的时候,迭代器会向我们返回它所记录位置的下一个位置的数据。
实际上,在使用next()函数的时候,调用的就是迭代器对象的__next__方法(Python3中是对象的__next__方法,Python2中是对象的next()方法)。
所以,我们要想构造一个迭代器,就要实现它的__next__方法。但这还不够,python要求迭代器本身也是可迭代的,所以我们还要为迭代器实现__iter__方法,而__iter__方法要返回一个迭代器,迭代器自身正是一个迭代器,所以迭代器的__iter__方法返回自身即可。
一个实现了__iter__方法和__next__方法的对象,就是迭代器。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
class MyList(object):
"""自定义的一个可迭代对象"""
def __init__(self):
self.items = []
def add(self, val):
self.items.append(val)
def __iter__(self):
myiterator = MyIterator(self)
return myiterator
class MyIterator(object):
"""自定义的供上面可迭代对象使用的一个迭代器"""
def __init__(self, mylist):
self.mylist = mylist
# current用来记录当前访问到的位置
self.current = 0
def __next__(self):
if self.current < len(self.mylist.items):
item = self.mylist.items[self.current]
self.current += 1
return item
else:
raise StopIteration
def __iter__(self):
return self
if __name__ == '__main__':
mylist = MyList()
mylist.add(1)
mylist.add(2)
mylist.add(3)
mylist.add(4)
mylist.add(5)
for num in mylist:
print(num)
可迭代对象与迭代器
- 可迭代对象包含迭代器。
- 如果一个对象拥有
__iter__方法,那么它是可迭代对象;如果一个对象拥有next方法,其是迭代器。 - 定义可迭代对象,必须实现
__iter__方法;定义迭代器,必须实现__iter__和next方法。
-
_iter_()
该方法返回的是当前对象的迭代器类的实例。因为可迭代对象与迭代器都要实现这个方法 -
next()
返回迭代的每一步,实现该方法时注意要最后超出边界要抛出StopIteration异常。
迭代器一定是可迭代对象,反过来则不一定成立。用iter()函数可以把list、dict、str等Iterable变成Iterator
生成器
- 生成器是一种特殊的迭代器,生成器自动实现了“迭代器协议”(即
__iter__和next方法),不需要再手动实现两方法。 - 生成器在迭代的过程中可以改变当前迭代值,而修改普通迭代器的当前迭代值往往会发生异常,影响程序的执行。
- 具有yield关键字的函数都是生成器,yield可以理解为return,返回后面的值给调用者。不同的是return返回后,函数会释放,而生成器则不会。在直接调用next方法或用for语句进行下一次迭代时,生成器会从yield下一句开始执行,直至遇到下一个yield。
第13题:单引号,双引号,三引号的区别?
- 单引号和双引号主要用来表示字符串
比如:
单引号:'python'
双引号:"python"
- 三引号
三单引号:’’‘python ‘’’,也可以表示字符串一般用来输入多行文本,或者用于大段的注释;
三双引号:""“python”"",一般用在类里面,用来注释类,这样省的写文档,直接用类的对象__doc__访问获得文档。
区别
若你的字符串里面本身包含单引号,必须用双引号
例子:“can’t find the log\n”
第14题:Python是如何进行内存管理的?
对象的引用计数机制
Python内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
总结一下对象会在一下情况下引用计数加1:
- 对象被创建:x=‘spam’
- 另外的别人被创建:y=x
- 被作为参数传递给函数:foo(x)
- 作为容器对象的一个元素:a=[1,x,‘33’]
引用计数减少情况
- 一个本地引用离开了它的作用域。比如上面的foo(x)函数结束时,x指向的对象引用减1。
- 对象的别名被显式的销毁:del x ;或者del y
- 对象的一个别名被赋值给其他对象:x=789
- 对象从一个窗口对象中移除:myList.remove(x)
- 窗口对象本身被销毁:del myList,或者窗口对象本身离开了作用域。
垃圾回收
-
当内存中有不再使用的部分时,垃圾收集器就会把他们清理掉。它会去检查那些引用计数为0的对象,然后清除其在内存的空间。当然除了引用计数为0的会被清除,还有一种情况也会被垃圾收集器清掉:当两个对象相互引用时,他们本身其他的引用已经为0了。
-
垃圾回收机制还有一个循环垃圾回收器, 确保释放循环引用对象(a引用b, b引用a, 导致其引用计数永远不为0)。
在Python中,许多时候申请的内存都是小块的内存,这些小块内存在申请后,很快又会被释放,由于这些内存的申请并不是为了创建对象,所以并没有对象一级的内存池机制。这就意味着Python在运行期间会大量地执行malloc和free的操作,频繁地在用户态和核心态之间进行切换,这将严重影响Python的执行效率。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
内存池机制
- Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统;
- Pymalloc机制:为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放;
- 对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
第15题:写一个函数, 输入一个字符串, 返回倒序排列的结果?
使用字符串本身的翻转
def order_by(str):
return str[::-1]
print(order_by('123456'))
输出:654321
把字符串变为列表,用列表的reverse函数
def reverse2(text='abcdef'):
new_text=list(text)
new_text.reverse()
return ''.join(new_text)
reverse2('abcdef')
新建一个列表,从后往前取
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def reverse3(text='abcdef'):
new_text=[]
for i in range(1,len(text)+1):
new_text.append(text[-i])
return ''.join(new_text)
reverse3('abcdef')
利用双向列表deque中的extendleft函数
from collections import deque
def reverse4(text='abcdef'):
d = deque()
d.extendleft(text)
return ''.join(d)
reverse4('abcdef')
第16题:列表和元组有什么不同?
列表和元组是Python中最常用的两种数据结构,字典是第三种。
相同点:
- 都是序列
- 都可以存储任何数据类型
- 可以通过索引访问
语法差异
使用方括号[]创建列表,而使用括号()创建元组。
是否可变
列表是可变的,而元组是不可变的,这标志着两者之间的关键差异。
重用与拷贝
元组无法复制。 因为元组是不可变的,所以运行tuple(tuple_name)将返回自己
内存开销
Python将低开销的较大的块分配给元组,因为它们是不可变的。
列表则分配小内存块。
与列表相比,元组的内存更小。
当你拥有大量元素时,元组比列表快。
列表的长度是可变的。
第17题:什么是负索引?
Python中的序列索引可以是正也可以是负
- 如果是正索引,0是序列中的第一个索引,1是第二个索引。
- 如果是负索引,-1是最后一个索引,-2是倒数第二个索引。
lst=[11,22,33,44,55]
全取列表
>>> lst[:]
[11, 22, 33, 44, 55]
取不到最后一个元素
>>> lst[:-1] # 注意这里不能输出55,因为切片操作都是左闭右开的
[11, 22, 33, 44]
列表倒序
>>> lst[::-1]
[55, 44, 33, 22, 11]
取最后一个
>>> lst[-1]
55
取第一个
>>> lst[0]
11
第18题: 如何随机打乱列表中元素,要求不引用额外的内存空间?
用 random 包中的 shuffle() 函数来实现
import random
random.shuffle(你的列表)
# 举个例子:
L1 = [1, 3, 5, 7]
random.shuffle(L1)
第19题:解释 Python 中的 join() 和 split() 函数?
join() 函数可以将指定的字符添加到字符串中
‘1,2,3,4,5’
a=','.join('123456')
print(a)
print(type(a))
#1,2,3,4,5,6
#split() 函数可以用指定的字符分割字符串
[‘1’, ‘2’, ‘3’, ‘4’, ‘5’]
a='1,2,3,4,5,6'.split(',')
print(a)
print(type(a))
#['1', '2', '3', '4', '5', '6']
#第20题:如何删除字符串中的前置空格?
- strip():把头和尾的空格去掉
- lstrip():把左边的空格去掉
- rstrip():把右边的空格去掉
- replace(‘c1’,‘c2’):把字符串里的c1替换成c2。故可以用replace(’ ‘,’’)来去掉字符串里的所有空格
- split():通过指定分隔符对字符串进行切片,如果参数num 有指定值,则仅分隔 num 个子字符串
- re.split(r’\s+’, ‘a b c’) # 使用正则表达式
第21题:Python 中的 pass 语句有什么作用?
在编写代码时只写框架思路,具体实现还未编写就可以用 pass 进行占位,使程序不报错,不会进行任何操作。
比如:
while False:
pass
pass通常用来创建一个最简单的类:
class MyEmptyClass:
pass
pass在软件设计阶段也经常用来作为TODO,提醒实现相应的实现,比如:
def readtxt(*args):
pass # to do list
第22题:解释 Python 中的成员运算符?
成员运算符
- in 是判断是否包含
通过成员运算符‘in’ 和 ‘not in’,确认一个值是否是另一个值的成员。
print('me' in 'disappointment')#True
print('us' in 'disappointment')#False
身份运算符
is 是判断内存地址
- is 是判断两个标识符是不是引用自一个对象
- is not 是判断两个标识符是不是引用自不同对象
tops: in 的 not 在前,is 的 not 在后
第22题:Python里面如何实现tuple和list的转换?
函数tuple(seq)可以把所有可迭代的(iterable)序列转换成一个tuple, 元素不变,排序也不变
list转为tuple:
temp_list = [1,2,3,4,5]
将temp_list进行强制转换:tuple(temp_list)
确定是否转换成功:print(type(temp_list))
函数list(seq)可以把所有的序列和可迭代的对象转换成一个list,元素不变,排序也不变
tuple 转为list:
temp_tuple = (1,2,3,4,5)
方法类似,也是进行强制转换即可:list(temp_tuple)
确定是否转换成功:print(type(temp_tuple))
第23题:Python里面search()和match()的区别?
它们两个都在re模块中
- match()函数是在string的开始位置匹配,如果不匹配,则返回None;
- search()会扫描整个string查找匹配;
match()
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
>>> import re
>>> print(re.match('hello','helloworld').span()) # 开头匹配到
(0, 5)
>>> print(re.match('hello','nicehelloworld').span()) # 开头没有匹配到
Traceback (most recent call last):
File "" , line 1, in <module>
print(re.match('hello','nicehelloworld').span())
AttributeError: 'NoneType' object has no attribute 'span'
>>>
search()
>>> print(re.search('a','abc'))
<_sre.SRE_Match object; span=(0, 1), match='a'>
>>> print(re.search('a','bac').span())
(1, 2)
>>>
结论:match() 使用限制更多
第24题: 如何用Python删除一个文件?
- os模块的使用
os.remove(path)
删除文件 path,删除时候如果path是一个目录, 抛出 OSError错误。如果要删除目录,请使用rmdir()。
remove() 同 unlink() 的功能是一样的
os.remove('a.txt')
- os.removedirs(path)
递归地删除目录。类似于rmdir(), 如果子目录被成功删除, removedirs() 将会删除父目录;但子目录没有成功删除,将抛出错误。
例如, os.removedirs(“a/b/c”) 将首先删除c目录,然后再删除b和a, 如果他们是空的话,则子目录不能成功删除,将抛出 OSError异常
- os.rmdir(path)
删除目录 path,要求path必须是个空目录,否则抛出OSError错误
第25题: is 和 == 的区别?
hon中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)
id 身份标识,就是在内存中的地址
完整的举例
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
>>> a = 'hello'
>>> b = 'hello'
>>> print(a is b)
True
>>> print(a==b)
True
>>> a = 'hello world'
>>> b = 'hello world'
>>> print(a is b)
False
>>> print(a == b)
True
>>> a = [1,2,3]
>>> b = [1,2,3]
>>> print(a is b)
False
>>> print(a == b)
True
>>> a = [1,2,3]
>>> b = a
>>> print(a is b)
True
>>> print(a == b)
True
>>>
- ==是python标准操作符中的比较操作符,用来比较判断两个对象的value(值)是否相等
- is也被叫做同一性运算符(对象标示符),这个运算符比较判断的是对象间的唯一身份标识,也就是id(内存中的地址)是否相同
我们在检查 a is b的时候,其实相当于检查id(a) == id(b)。而检查 a == b的时候,实际是调用了对象 a 的 __eq()__方法,a == b相当于 a.__eq__(b)。
这里还有一个问题,为什么 a 和 b 都是 “hello” 的时候,a is b 返回True,而 a 和 b都是 “hello world” 的时候,a is b 返回False呢?
这是因为前一种情况下Python的字符串驻留机制起了作用。对于较小的字符串,为了提高系统性能Python会保留其值的一个副本,当创建新的字符串的时候直接指向该副本即可。
所以 “hello” 在内存中只有一个副本,a 和 b 的 id 值相同,而 “hello world” 是长字符串,不驻留内存,Python中各自创建了对象来表示 a 和 b,所以他们的值相同但 id 值不同。
试一下当a=247,b=247时它们的id还是否会相等。事实上Python 为了优化速度,使用了小整数对象池,避免为整数频繁申请和销毁内存空间。而Python 对小整数的定义是 [-5, 257),只有数字在-5到256之间它们的id才会相等,超过了这个范围就不行了。
>>> a = 247
>>> b = 247
>>> print(a is b)
True
>>> a = 258
>>> b = 258
>>> print(a is b)
False
>>>
is 是检查两个对象是否指向同一块内存空间,而==是检查他们的值是否相等。is比==更加严格
第26题:a=1, b=2, 不用中间变量交换a和b的值?
方法一
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
>>> a = 5
>>> b = 6
>>> a = a+b
>>> b = a-b
>>> a = a-b
方法二
>>> a = a^b
>>> b = b^a
>>> a = a^b
方法三
a,b = b,a
第27题:说说你对zen of python的理解,你有什么办法看到它?
Python之禅
import this
python彩蛋
知道就知道了,不知道你现在已经知道了,搜索一下去吧
第28题:字符串的拼接–如何高效的拼接两个字符串?
字符串拼接的几种方法
- 加号
- 逗号
- 直接连接
- 格式化
- join
- 多行字符串拼接()
加号
print('Python' + 'Plus')
逗号
print("Hello", "Python")
直接连接
print("Hello" "Python")
格式化
print('%s %s'%('Python', 'PLUS'))
join
str_list = ['Python', 'Plus']
a = ''
print(a.join(str_list))
多行字符串拼接()
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
sql = ('select *'
'from users'
'where id=666')
print(sql)
一般情况,大家比较喜欢用“+”拼接字符串,但是这个方法并不是高效的,因为如果需要拼接的字符串有很多(n个)的情况下,使用”+”的话,python解释器会申请n-1次内存空间,然后进行拷贝,因为字符串在python中是不可变的,所以当进行拼接的时候,会需要申请一个新的内存空间。
所以,正确答案是,使用.join(list),因为它只使用了一次内存空间
第29题: list = [‘a’,‘a’,‘a’,1,2,3,4,5,‘A’,‘B’,‘C’]提取出”12345”?
这个考点考了python的解压赋值的知识点,即 a,b,c,*middle,d,e,f = list, *middle = [1,2,3,4,5]。
注意,解压赋值提取出来的是列表
list = ['a','a','a',1,2,3,4,5,'A','B','C']
a,b,c,*middle,d,e,f = list
print(middle)
print(type(middle))
第30题: 什么是pickling和unpickling?
为了让用户在平常的编程和测试时保存复杂的数据类型,python提供了标准模块,称为pickle。
这个模块可以将几乎任何的python对象(甚至是python的代码),转换为字符串表示,这个过程称为pickling。
从存储的字符串中检索原始Python对象的过程称为unpickling。
第31题: 说一说Python自省?
在python中,检查某些事物以确定它是什么、它知道什么以及它能做什么。
自省向程序员提供了极大的灵活性和控制力。
说的更简单直白一点:自省就是面向对象的语言所写的程序在运行时,能够知道对象的类型。简单一句就是,运行时能够获知对象的类型。
例如python, buby, object-C, c++都有自省的能力,这里面的c++的自省的能力最弱,只能够知道是什么类型,而像python可以知道是什么类型,还有什么属性。
Python中比较常见的自省(introspection)机制(函数用法)有: dir(),type(), hasattr(), isinstance(),通过这些函数,我们能够在程序运行时得知对象的类型,判断对象是否存在某个属性,访问对象的属性。
- dir() 函数是 Python 自省机制中最著名的部分了。它返回传递给它的任何对象的属性名称经过排序的列表。如果不指定对象,则 dir() 返回当前作用域中的名称。
- type() 函数有助于我们确定对象是字符串还是整数,或是其它类型的对象。
- 对象拥有属性,并且 dir() 函数会返回这些属性的列表。但是,有时我们只想测试一个或多个属性是否存在。如果对象具有我们正在考虑的属性,那么通常希望只检索该属性。这个任务可以由 hasattr() 和 getattr() 函数来完成。
- isinstance() 函数测试对象,以确定它是否是某个特定类型或定制类的实例。
第32题:什么是python猴子补丁python monkey patch?
monkey patch (猴子补丁)
用来在运行时动态修改已有的代码,而不需要修改原始代码。
在Python中,术语monkey补丁仅指run-time上的类或模块的动态修改
>>> class A:
def func(self):
print("Hi")
>>> def monkey(self):
print("Hi, monkey")
>>> m.A.func = monkey
>>> a = m.A()
>>> a.func()
Hi, monkey
第33题:阅读下面的代码,默读出A0,A1至An的最终值。
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
A0 = dict(zip(('a','b','c','d','e'),(1,2,3,4,5)))
A1 = range(10)
A2 = [i for i in A1 if i in A0]
A3 = [A0[s] for s in A0]
A4 = [i for i in A1 if i in A3]
A5 = {
i:i*i for i in A1}
A6 = [[i,i*i] for i in A1]
默读代码类的题目,相对来说是比较简单的。重点去研究列表解析,之后你就可以轻松的回答这些问题喽~
A0 = {
'a': 1, 'c': 3, 'b': 2, 'e': 5, 'd': 4}
A1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
A2 = []
A3 = [1, 3, 2, 5, 4]
A4 = [1, 2, 3, 4, 5]
A5 = {
0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
A6 = [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36], [7, 49], [8, 64], [9, 81]]
第34题:如何提高python的运行效率?
- 数据结构一定要选对
- 能用字典就不用列表:字典在索引查找和排序方面远远高于列表。
- 多用python中封装好的模块库
- 关键代码使用外部功能包(Cython,pylnlne,pypy,pyrex)
- 使用生成器
- 针对循环的优化
- 尽量避免在循环中访问变量的属性
- 使用较新的Python版本
第35题: Python字典有什么特点,从字典中取值,时间复杂度是多少?
dict(中文叫字典)是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号{}中
字典的特性
- 查找速度快
无论dict有10个元素还是10万个元素,查找速度都一样。而list的查找速度随着元素增加而逐渐下降。
不过dict的查找速度快不是没有代价的,dict的缺点是占用内存大,还会浪费很多内容,list正好相反,占用内存小,但是查找速度慢。 - 字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行。
不允许同一个键出现两次。
键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行。 - dict的第二个特点就是存储的key-value序对是没有顺序的!这和list不一样。
从字典中取值,时间复杂度是多少
O(1),字典是hash table实现
第36题: 多线程、多进程?
1. 线程
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。一个线程是一个execution context(执行上下文),即一个cpu执行时所需要的一串指令。
2. 进程
一个程序的执行实例就是一个进程。每一个进程提供执行程序所需的所有资源。(进程本质上是资源的集合)
一个进程有一个虚拟的地址空间、可执行的代码、操作系统的接口、安全的上下文(记录启动该进程的用户和权限等等)、唯一的进程ID、环境变量、优先级类、最小和最大的工作空间(内存空间),还要有至少一个线程。
每一个进程启动时都会最先产生一个线程,即主线程 然后主线程会再创建其他的子线程。
进程与线程区别
- 同一个进程中的线程共享同一内存空间,但是进程之间是独立的。
- 同一个进程中的所有线程的数据是共享的(进程通讯),进程之间的数据是独立的。
- 对主线程的修改可能会影响其他线程的行为,但是父进程的修改(除了删除以外)不会影响其他子进程。
- 线程是一个上下文的执行指令,而进程则是与运算相关的一簇资源。
- 同一个进程的线程之间可以直接通信,但是进程之间的交流需要借助中间代理来实现。
- 创建新的线程很容易,但是创建新的进程需要对父进程做一次复制。
- 一个线程可以操作同一进程的其他线程,但是进程只能操作其子进程。
- 线程启动速度快,进程启动速度慢(但是两者运行速度没有可比性)。
第37题: 请尽可能列举python列表的成员方法,并给出以下列表操作的答案:
1.a=[1, 2, 3, 4, 5], a[::2]=?, a[-2:] = ?
a[::2] = [1, 3, 5], a[-2:] = [4, 5]
2.一行代码实现对列表a中的偶数位置的元素进行加3后求和?
from functools import reduce
a = [1, 2, 3, 4, 5]
print(reduce(lambda x, y: x+y, [(x+3*((a.index(x)+1)%2)) for x in a])) # a中元素均不相同
# 或
print(reduce(lambda x, y: x+y, [a[x]+(x+1)%2*3 for x in range(0, 5)])) # 只适用于a中元素有5个情况
3.将列表a的元素顺序打乱,再对a进行排序得到列表b,然后把a和b按元素顺序构造一个字典d。
from random import shuffle
a = [1, 2, 3, 4, 5]
# 打乱列表a的元素顺序
shuffle(a)
# 对a进行排序得到列表b
b = sorted(a, reverse=True)
# zip 并行迭代,将两个序列“压缩”到一起,然后返回一个元组列表,最后,转化为字典类型。
d = dict(zip(a, b))
print(d)
第38题:列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]。
map是python高阶用法,字面意义是映射,它的作用就是把一个数据结构映射成另外一种数据结构。
map用法比较绕,最好是对基础数据结构很熟悉了再使用,比如列表,字典,序列化这些。
map的基本语法如下:
map(函数, 序列1, 序列2, ...)
- Python 2.x 返回列表。
- Python 3.x 返回迭代器。
list = [1,2,3,4,5]
def fn(x):
return x ** 2
res = map(fn,list)
res = [i for i in res]
print(res)
res = [i for i in res if i > 10]
print(res)
第39题:设计一个函数返回给定文件名的后缀?
考察字符串操作
rfind() # 右侧字符出现的位置
注意下面的0 if … else用法 下面是具体的示例: 案例来源互联网搜索,都书写一遍即可掌握 举例 解答思路: 统计数字 1 在 [1,10,11,12]出现的次数这非常像Python中统计字符串a在字符串b中出现的次数: 所以我们将把数字转为字符串来做统计。 python中没有其他语言中的三元表达式,不过有类似的实现方法 句法: 三元操作符语法如下, 例: 如果x print print() 用 上述代码你应该可以总结一下。 input Python3中的input() 用 sys.stdin.readline() 实现。 首先我们看看range: xrange的用法与range相同,即 两者用法相同,不同的是 range 返回的结果是一个列表,而 xrange 的结果是一个生成器,前者是 注意: 方法一 可以通过生成器,分多次读取,每次读取数量相对少的数据(比如 500MB)进行处理,处理结束后在读取后面的 500MB 的数据。 方法二 可以通过 linux 命令 split 切割成小文件,然后再对数据进行处理,此方法效率比较高。可以按照行数切割,可以按照文件大小切割。 会继续处理 finally 中的代码;用 raise 方法可以抛出自定义异常 方法一 互联网找到了几个解法 方法二 方法三 docstring是一种文档字符串,用于解释构造的作用。我们在函数、类或方法中将它放在首位来描述其作用。我们用三个单引号或双引号来声明docstring。 要想获取一个函数的docstring,我们使用它的 PYTHONPATH是Python中一个重要的环境变量,用于在导入模块的时候搜索路径.可以通过如下方式访问: 集合分为两种类型: 首先,我们讨论一下什么是集合。集合就是一系列数据项的合集,不存在任何副本。另外,集合是无序的。 这就意味着我们无法索引它 TypeError:‘set’不支持索引。 对于这个问题,我们可以使用isalnum()方法。 其他内容 Python中的连接就是将两个序列连在一起,我们使用+运算符完成 Python有以下缺陷: os 属于 python内置模块,所以细节在官网有详细的说明,本道面试题考察的是基础能力了,所以把你知道的都告诉面试官吧 官网地址 https://docs.python.org/3/library/os.html os模块包含了很多操作文件和目录的函数 os对象方法 python模块(Module) 表现形式为:写的代码保存为文件。这个文件就是一个模块。abc.py 其中文件名abc为模块名字。 有四种代码类型的模块: python包(Package) 包(Package)就是包含模块文件的目录,目录名称就是包名称,目录中可以包含目录,子目录也是包,但包名称应该包含上一级目录的名称。 Python引入了按目录来组织模块是为了避免模块名冲突,不同包中的模块名可以相同。 注意,每一个包目录下面都会有一个 计算机不能直接理解高级语言,只能直接理解机器语言 简记为 LEGB Python 中一切皆对象,函数名是函数在内存中的空间,也是一个对象。 这类问题属于简单类问题 copy() 函数 浅拷贝 你可以继续去搜索一下python中copy和deepcopy的区别 这种设计模式的题,一般不要深究,说一下设计模式的名字即可 创建型 结构型 行为型 简化后的代码 PIL、pytesser、tesseract模块 平台的话有:(打码平台特殊,不保证时效性) 关于 ip 可以通过 ip 代理池来解决问题 ip 代理池相关的可以在 github 上搜索 ip proxy 自己选一个 区别 应用场景 方法重载 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。 方法重写 子类不想原封不动地继承父类的方法,而是想作一定的修改,这就需要采用方法的重写。方法重写又称方法覆盖。 smtplib 标准库 线程同步:多个线程同时访问同一资源,等待资源访问结束,浪费时间,效率低 线程异步:在访问资源时在空闲等待时同时访问其他资源,实现多线程机制 这个答案比较发散,可以重点说下面两种 InnoDB InnoDB是一个健壮的事务型存储引擎,这种存储引擎已经被很多互联网公司使用,为用户操作非常大的数据存储提供了一个强大的解决方案。 在以下场合下,使用InnoDB是最理想的选择: 一般来说,如果需要事务支持,并且有较高的并发读取频率,InnoDB是不错的选择。 MEMORY 使用MySQL Memory存储引擎的出发点是速度。为得到最快的响应时间,采用的逻辑存储介质是系统内存。 虽然在内存中存储表数据确实会提供很高的性能,但当mysqld守护进程崩溃时,所有的Memory数据都会丢失。 获得速度的同时也带来了一些缺陷。 一般在以下几种情况下使用Memory存储引擎: 原始代码 面试要点: 类继承,只要通过 修改代码 原始代码 面试要点: 是方法对象,为了能让对象实例能被直接调用,需要实现 修改代码 原始代码 这个运行需要对代码比较熟悉了 结果如下 原始代码 全局变量和局部变量。 num 不是个全局变量,所以每个函数都得到了自己的 num 拷贝,如果你想修改 num ,则必须用 global 关键字声明 原始代码 修改代码 考点 python的默认方法, 只有当没有定义的方法调用时,才会调用方法 当 fn1 方法传入参数时,我们可以给 myfunc方法增加一个 python多线程有个全局解释器锁(global interpreter lock),简称GIL,这个GIL并不是python的特性,他是只在Cpython解释器里引入的一个概念,而在其他的语言编写的解释器里就没有这个GIL例如:Jython。 这个锁的意思是任一时间只能有一个线程运用解释器,跟单cpu跑多个程序一个意思,我们都是轮着用的,这叫“并发”,不是“并行”。 为什么会有GIL? 多核CPU的出现,充分利用多核,采用多线程编程慢慢普及,难点就是线程之间数据的一致性和状态同步 说到GIL解释器锁,我们容易想到在多线程中共享全局变量的时候会有线程对全局变量进行的资源竞争,会对全局变量的修改产生不是我们想要的结果,而那个时候我们用到的是python中线程模块里面的互斥锁,哪样的话每次对全局变量进行操作的时候,只有一个线程能够拿到这个全局变量;看下面的代码: 接下来加入互斥锁 哪些情况适合用多线程呢: 只要在进行耗时的IO操作的时候,能释放GIL,所以只要在IO密集型的代码里,用多线程就很合适 哪些情况适合用多进程呢: 用于计算密集型,比如计算某一个文件夹的大小 多进程间同享数据 多进程间同享数据,能够运用multiprocession.Value和multiprocessing.Array bool and a or b 相当于bool? a: b 上述内容你应该可以理解,但是还存在一个问题,请看下面的代码 因为 a 是一个空串,空串在一个布尔环境中被Python看成假值,这个表达式将“失败”,且返回 b 的值。 如果你不将它想象成象 bool ? a : b 一样的语法,而把它看成纯粹的布尔逻辑,这样的话就会得到正确的理解。 1 是真,a 是假,所以 1 and a 是假。假 or b 是b。 应该将 and-or 技巧封装成一个函数: 因为 [a] 是一个非空列表,它永远不会为假。甚至 a 是 0 或 ” 或其它假值,列表[a]为真,因为它有一个元素。 PEP8 规范 官方文档: 这个在于平时的积累的了 ORM,全拼Object-Relation Mapping,意为对象-关系映射 实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要修改代码只需要面向对象编程 ORM操作本质上会根据对接的数据库引擎,翻译成对应的sql语句,所有使用Django开发的项目无需关心程序底层使用的是MySql、Oracle、SQLite…,如果数据库迁移,只需要更换Django的数据库引擎即可。 在Flask中处理请求时,就会产生一个 “请求上下文” 对象,整个请求的处理过程,都会在这个上下文对象中进行。 “应用上下文” 也是一个上下文对象,可以使用with语句构造一个上下文环境,它也实现了push、pop等方法。 django在中间件中预设了6个方法,这6个方法区别在于不同的阶段执行,对输入或输出进行干预,方法如下: Django Django源自一个在线新闻 Web站点,于 2005 年以开源的形式被释放出来。 Django 框架的核心组件有: 用于创建模型的对象关系映射为最终用户设计的完美管理界面一流的 URL 设计设计者友好的模板语言缓存系统等等 它鼓励快速开发,并遵循MVC设计。 Django遵守 BSD版权,最新发行版本是Django1.4,于2012年03月23日发布.Django的主要目的是简便、快速的开发数据库驱动的网站。它强调代码复用,多个组件可以很方便的以“插件”形式服务于整个框架,Django有许多功能强大的第三方插件,你甚至可以很方便的开发出自己的工具包。这使得Django具有很强的可扩展性。它还强调快速开发和DRY(Do Not RepeatYourself)原则。 Tornado Tornado是 FriendFeed使用的可扩展的非阻塞式 web 服务器及其相关工具的开源版本。这个 Web 框架看起来有些像 web.py 或者 Google 的 webapp,不过为了能有效利用非阻塞式服务器环境,这个 Web 框架还包含了一些相关的有用工具和优化。 Tornado 和现在的主流 Web 服务器框架(包括大多数Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快。得利于其 非阻塞的方式和对epoll的运用,Tornado 每秒可以处理数以千计的连接,这意味着对于实时 Web服务来说,Tornado 是一个理想的 Web 框架。我们开发这个 Web 服务器的主要目的就是为了处理 FriendFeed 的实时功能 ——在 FriendFeed 的应用里每一个活动用户都会保持着一个服务器连接。(关于如何扩容 服务器,以处理数以千计的客户端的连接的问题。 REST 的特点 RESTful 架构 解释型语言编写的程序不需要编译,在执行的时候,专门有一个解释器能够将VB语言翻译成机器语言,每个语句都是执行的时候才翻译。这样解释型语言每执行一次就要翻译一次,效率比较低。 用编译型语言写的程序执行之前,需要一个专门的编译过程,通过编译系统,把源高级程序编译成为机器语言文件,翻译只做了一次,运行时不需要翻译,所以编译型语言的程序执行效率高,但也不能一概而论, 部分解释型语言的解释器通过在运行时动态优化代码,甚至能够使解释型语言的性能超过编译型语言。 Python 当 从Python官方网站下载并安装好Python2.7后,就直接获得了一个官方版本的解释器:Cpython,这个解释器是用C语言开发的,所以叫 CPython,在命名行下运行python,就是启动CPython解释器,CPython是使用最广的Python解释器。 IPython IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的,好比很多国产浏览器虽然外观不同,但内核其实是调用了IE。 PyPy PyPy是另一个Python解释器,它的目标是执行速度,PyPy采用JIT技术,对Python代码进行动态编译,所以可以显著提高Python代码的执行速度。 Jython Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。 IronPython IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。 在Python的解释器中,使用广泛的是CPython,对于Python的编译,除了可以采用以上解释器进行编译外,技术高超的开发者还可以按照自己的需求自行编写Python解释器来执行Python代码,十分的方便! 1byte=8bit 1byte就是1B 一个字符=2字节 1KB=1024B 字节就是Byte,也是B 位就是bit也是b 转换关系如下: 机器码(machine code) 机器码(machine code),学名机器语言指令,有时也被称为原生码(Native Code),是电脑的CPU可直接解读的数据。 通常意义上来理解的话,机器码就是计算机可以直接执行,并且执行速度最快的代码。 用机器语言编写程序,编程人员要首先熟记所用计算机的全部指令代码和代码的涵义。 机器语言是微处理器理解和使用的,用于控制它的操作二进制代码。 8086到Pentium的机器语言指令长度可以从1字节到13字节。 尽管机器语言好像是很复杂的,然而它是有规律的。 存在着多至100000种机器语言的指令。这意味着不能把这些种类全部列出来。 总结:机器码是电脑CPU直接读取运行的机器指令,运行速度最快,但是非常晦涩难懂,也比较难编写,一般从业人员接触不到。 字节码(Bytecode) 字节码(Bytecode)是一种包含执行程序、由一序列 op 代码/数据对 组成的二进制文件。字节码是一种中间码,它比机器码更抽象,需要直译器转译后才能成为机器码的中间代码。 通常情况下它是已经经过编译,但与特定机器码无关。字节码通常不像源码一样可以让人阅读,而是编码后的数值常量、引用、指令等构成的序列。 字节码主要为了实现特定软件运行和软件环境、与硬件环境无关。字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。字节码的典型应用为Java bytecode。 字节码在运行时通过JVM(JAVA虚拟机)做一次转换生成机器指令,因此能够更好的跨平台运行。 总结:字节码是一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。 Python 2有为非浮点数准备的int和long类型。 在Python 3里,只有一种整数类型int,大多数情况下,它很像Python 2里的长整型。 这是代码结构设计的问题,模块依赖和类依赖 如果老是觉得碰到循环引用可能的原因有几点: 总之微观代码规范可能并不能帮到太多,重要的是更宏观的划分模块的经验技巧,推荐uml,脑图,白板等等图形化的工具先梳理清楚整个系统的总体结构和职责分工 采取办法,从设计模式上来规避这个问题,比如: 在函数式编程中,函数是基本单位,变量只是一个名称,而不是一个存储单元。 除了匿名函数外,Python还使用 装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。 它经常用于有切面需求的场景,比如: 有了装饰器,就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。 写一个函数,将两个dict(key是数字,value是string)进行合并,函数返回合并后的dict。 规则如下:如果一个key仅仅存在于其中一个dict中,则直接加入合并后的dict; 如果一个key在两个dict中都存在,那么给定一个choice值,choice可以是任何string,如果choice是任一个dict中的value,则写入,否则不写入。 代码如下 这个题就是面向对象设计和设计模式的开始。 你可能比较熟悉的模式叫做: MVC。说是 Model View Controller,而在 Django 中因为 Template 来处理视图展现,所以称为:MTV。 接下里会问到的就是分层的概念,有句话叫:“没有什么问题是不能通过增加一层解决的,如果有,那就再加一层。”当然还会有设计模式的一些原则等着你,比如开-闭原则、单一职责原则等。 ORM:Object Relational Mapping(对象关系映射),它做的事就是帮我们封装一下对数据库的操作,避免我们来写不太好维护的 SQL 代码。 说到性能损耗,可以接着聊的是 Django 中的 raw sql,也就是说 Model.objects.raw 这个方法的使用,它的作用、原理、性能提升等。还可以继续聊另外一个老生常谈的问题:N+1 的问题。 这涉及到 Django 如何处理数据库连接细节的问题。默认情况下对于每一个请求 Django 都会建立一个新的数据库连接。这意味着当请求量过大时就会出现数据库(MySQL)的 Too many connection 的问题,对于这个问题,在其他的语言框架中有连接池这样的东西来减少数据库的连接数,来提升连接的使用效率。而在 Django中,为了处理这一问题,增加了一个配置: 但是需要注意的是,这跟数据库连接池的概念还不太一样。 从原理上来说:在同一线程内,对RLock进行多次acquire()操作,程序不会阻塞。 资源总是有限的,程序运行如果对同一个对象进行操作,则有可能造成资源的争用,甚至导致死锁 也可能导致读写混乱 列表是序列,可以理解为数据结构中的数组,字典可以理解为数据结构中的hashmap,python中list对象的存储结构采用的是线性表,因此其查询复杂度为O(n)。 而dict对象的存储结构采用的是散列表(hash表),其在最优情况下查询复杂度为O(1)。 dict的占用内存稍比list大,会在1.5倍左右。 1.Python基础入门教程推荐:更多Python视频教程-关注B站:Python学习者 【Python教程】全网最容易听懂的1000集python系统学习教程(答疑在最后四期,满满干货) 2.Python爬虫案例教程推荐:更多Python视频教程-关注B站:Python学习者 2021年Python最新最全100个爬虫完整案例教程,数据分析,数据可视化,记得收藏哦def get_suffix(filename, has_dot=False):
"""
获取文件名的后缀名
:param filename: 文件名
:param has_dot: 返回的后缀名是否需要带点
:return: 文件的后缀名
"""
pos = filename.rfind('.')
if 0 < pos < len(filename) - 1:
index = pos if has_dot else pos + 1
return filename[index:]
else:
return ''
第40题: 这两个参数是什么意思:*args,**kwargs?我们为什么要使用它们?
*args;**kwargs。*tom和**jarry,但是这样显的不专业。'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def f(*args,**kwargs):
print(args, kwargs)
l = [1,2,3]
t = (4,5,6)
d = {
'a':7,'b':8,'c':9}
f()
f(1,2,3) # (1, 2, 3) {}
f(1,2,3,"groovy") # (1, 2, 3, 'groovy') {}
f(a=1,b=2,c=3) # () {'a': 1, 'c': 3, 'b': 2}
f(a=1,b=2,c=3,zzz="hi") # () {'a': 1, 'c': 3, 'b': 2, 'zzz': 'hi'}
f(1,2,3,a=1,b=2,c=3) # (1, 2, 3) {'a': 1, 'c': 3, 'b': 2}
f(*l,**d) # (1, 2, 3) {'a': 7, 'c': 9, 'b': 8}
f(*t,**d) # (4, 5, 6) {'a': 7, 'c': 9, 'b': 8}
f(1,2,*t) # (1, 2, 4, 5, 6) {}
f(q="winning",**d) # () {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
f(1,2,*t,q="winning",**d) # (1, 2, 4, 5, 6) {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
def f2(arg1,arg2,*args,**kwargs):
print(arg1,arg2, args, kwargs)
f2(1,2,3) # 1 2 (3,) {}
f2(1,2,3,"groovy") # 1 2 (3, 'groovy') {}
f2(arg1=1,arg2=2,c=3) # 1 2 () {'c': 3}
f2(arg1=1,arg2=2,c=3,zzz="hi") # 1 2 () {'c': 3, 'zzz': 'hi'}
f2(1,2,3,a=1,b=2,c=3) # 1 2 (3,) {'a': 1, 'c': 3, 'b': 2}
f2(*l,**d) # 1 2 (3,) {'a': 7, 'c': 9, 'b': 8}
f2(*t,**d) # 4 5 (6,) {'a': 7, 'c': 9, 'b': 8}
f2(1,2,*t) # 1 2 (4, 5, 6) {}
f2(1,1,q="winning",**d) # 1 1 () {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
f2(1,2,*t,q="winning",**d) # 1 2 (4, 5, 6) {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
第41题: 求出0n的所有正整数中数字k(09)出现的次数。编程语言不限,Python优先。
b.count(a)
def digit_count(k,n):
listn = []
count = 0
for i in range(0,n+1):
count += str(i).count(str(k))
if str(k) in str(i):
listn.append(str(i))
return count,listn
c,ls = digit_count(1,12)
print(c,ls)
第42题: 如何在python中使用三元运算符?
[on_true] if [expression] else [on_false]
x,y = 15,22
big = x if x < y else y
第43题: print 调用 Python 中底层的什么方法?
sys.stdout.write()实现import sys
print('hello')
sys.stdout.write('hello')
print('world')
# 结果:
# hello
# helloworld
import sys
a = sys.stdin.readline()
print(a, len(a))
b = input()
print(b, len(b))
# 结果:
# hello
# hello
# 6
# hello
# hello 5
第44题:range 和 xrange 的区别?
range([start,] stop[, step]),根据start与stop指定的范围以及step设定的步长,生成一个序列。注意这里是生成一个序列。xrange([start,] stop[, step])根据start与stop指定的范围以及step设定的步长,它所不同的是xrange并不是生成序列,而是作为一个生成器。即她的数据生成一个取出一个。
直接开辟一块内存空间来保存列表,后者是边循环边使用,只有使用时才会开辟内存空间,所以相对来说,xrange比range性能优化很多,因为他不需要一下子开辟一块很大的内存,特别是数据量比较大的时候。
第45题: 4G 内存怎么读取一个 5G 的数据?
def get_lines(): # 生成器
with open('big.data', 'r') as f:
while True:
data = f.readlines(100)
if data:
yield data
else:
break
f = get_lines() # 迭代器对象
print(next(f))
print(next(f))
print(next(f))
第46题:在except中return后还会不会执行finally中的代码?怎么抛出自定义异常?介绍一下 except 的作用和用法?
第47题:在Python中输入某年某月某日,判断这一天是这一年的第几天?(可以用 Python 标准库)
year = int(input('请输入4位数字的年份:')) #获取年份
month = int(input('请输入月份:')) #获取月份
day = int(input('请输入是哪一天:')) #获取日
if month == 1:
count = day
elif month == 2:
count = 31 + day
elif (month >= 3) and ((year % 4 == 0 and year % 100 != 0) or year % 400 == 0):
if month == 3:
count = 31 + 29 + day
if month == 4:
count = 31 + 29 + 31 + day
if month == 5:
count = 31 + 29 + 31 + 30 + day
if month == 6:
count = 31 + 29 + 31 + 30 + 31 + day
if month == 7:
count = 31 + 29 + 31 + 30 + 31 + 30 + day
if month == 8:
count = 31 + 29 + 31 + 30 + 31 + 30 + 31 + day
if month == 9:
count = 31 + 29 + 31 + 30 + 31 + 30 + 31 + 31 + day
if month == 10:
count = 31 + 29 + 31 + 30 + 31 + 30 + 31 + 31 + 30 + day
if month == 11:
count = 31 + 29 + 31 + 30 + 31 + 30 + 31 + 31 + 30 + 31 + day
if month == 12:
count = 31 + 29 + 31 + 30 + 31 + 30 + 31 + 31 + 30 + 31 + 30 + day
else:
if month == 3:
count = 31 + 28 + day
if month == 4:
count = 31 + 28 + 31 + day
if month == 5:
count = 31 + 28 + 31 + 30 + day
if month == 6:
count = 31 + 28 + 31 + 30 + 31 + day
if month == 7:
count = 31 + 28 + 31 + 30 + 31 + 30 + day
if month == 8:
count = 31 + 28 + 31 + 30 + 31 + 30 + 31 + day
if month == 9:
count = 31 + 28 + 31 + 30 + 31 + 30 + 31 + 31 + day
if month == 10:
count = 31 + 28 + 31 + 30 + 31 + 30 + 31 + 31 + 30 + day
if month == 11:
count = 31 + 28 + 31 + 30 + 31 + 30 + 31 + 31 + 30 + 31 + day
if month == 12:
count = 31 + 28 + 31 + 30 + 31 + 30 + 31 + 31 + 30 + 31 + 30 + day
print('第' + str(count) + '天')
import datetime
y = int(input('请输入4位数字的年份:')) # 获取年份
m = int(input('请输入月份:')) # 获取月份
d = int(input('请输入是哪一天:')) # 获取“日”
targetDay = datetime.date(y, m, d) # 将输入的日期格式化成标准的日期
dayCount = targetDay - datetime.date(targetDay.year - 1, 12, 31) # 减去上一年最后一天
print('%s是%s年的第%s天。' % (targetDay, y, dayCount.days))
import datetime
dtime = input("请输入求天数的日期(20191111):")
tnum = datetime.datetime.strptime(dtime,'%Y%m%d').strftime("%j")
print(dtime + "在一年中的天数是: " + tnum + "天。")
第48题: docstring是什么?
>>> def say():
"""
这是docstring
"""
print("docstring")
>>> say()
docstring
>>>
_doc_属性第49题:PYTHONPATH变量是什么?

sys.path.append(),sys.path.insert()等方法来改变,这种方法当重新启动解释器的时候,原来的设置会失效.第50题: Python中的不可变集合(frozenset)是什么?
>>> myset={
1,3,2,2}
>>> myset
{
1, 2, 3}
>>> myset={
1,3,2,2}
>>> myset
{
1, 2, 3}
>>> myset[0]
Traceback (most recent call last):
File "
集合是可变的。而不可变集合却不可变,这意味着我们无法改变它的值,从而也使其无法作为字典的键值。>>> myset=frozenset([1,3,2,2])
>>> myset
frozenset({
1, 2, 3})
>>> type(myset)
<class 'frozenset'>
>>>
第51题:如何检查字符串中所有的字符都为字母数字?
第52题:什么是Python中的连接(concatenation)?
第53题:Python的不足之处
第54题: Python 中的 os 模块常见方法?
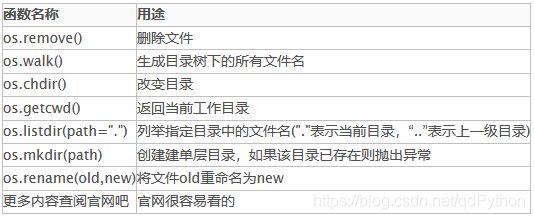
第55题: Python语言中的模块和包是什么?
__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是包名。第56题: 谈一下什么是解释性语言,什么是编译性语言?
所以必须要把高级语言翻译成机器语言
计算机才能执行高级语言编写的程序。
第57题:如何提高Python 程序的运行性能?
第58题: Python 中的作用域?
第59题:如何理解 Python 中字符串中的\字符?
第60题:为什么函数名字可以当做参数用?
第61题: Python如何爬取 HTTPS 网站?
requests.packages.urllib3.disable_warnings()。import ssl
ssl._create_default_https_context = ssl._create_unverified_context
第62题: 函数参数传递,下面程序运行的结果是?
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def add(a,my_list=[]):
my_list.append(a)
return my_list
print(add('a'))
print(add('b'))
print(add('c'))
第63题: Python 里面如何拷贝一个对象?
list2 =["2","3","4"]
q=list2.copy()
print(q)
第64题:Python 程序中中文乱码如何解决?
#coding:utf-8
sys.setdefaultencoding('utf-8')
第65题: Python 列举出一些常用的设计模式?
第66题:将下面的Python代码简化?
my_list = []
for i in range(10):
my_list.append(i**2)
print(my_list)
print([x**2 for x in range(10)])
第67题: 如何解决验证码的问题,用什么模块,听过哪些人工打码平台?
第68题: ip 被封了怎么解决,自己做过 ip 池么?
去说 https://github.com/awolfly9/IPProxyTool 提供大体思路:
第69题: 在 Python 中,list,tuple,dict,set 有什么区别,主要应用在什么场景?
第70题: 请描述方法重载与方法重写?
重载是让类以统一的方式处理不同类型数据的一种手段。第71题: 如何用 Python 来发送邮件?
第72题:是否了解线程的同步和异步?
例子:你说完,我再说。
例子:你喊朋友吃饭,朋友说知道了,待会忙完去找你 ,你就去做别的了。第73题:是否了解网络的同步和异步?
第74题:你是否了解MySQL数据库的几种引擎?
AUTO_INCREMENT属性。
max_heap_table_size控制Memory表的大小,设置此参数,就可以限制Memory表的最大大小。第75题: 修改以下Python代码,使得下面的代码调用类A的show方法?
class A(object):
def run(self):
print("基础 run 方法")
class B(A):
def run(self):
print("衍生 run 方法 ")
obj = B()
obj.run()
__class__ 方法指定类对象就可以了。class A(object):
def run(self):
print("基础 run 方法")
class B(A):
def run(self):
print("衍生 run 方法 ")
obj = B()
obj.__class__ = A
obj.run()
第76题:修改以下Python代码,使得代码能够运行
class A(object):
def __init__(self,a,b):
self.__a = a
self.__b = b
def show(self):
print("a=",self.__a,"b=",self.__b)
a = A(5,10)
a.show()
a(20)
__call__方法class A(object):
def __init__(self,a,b):
self.__a = a
self.__b = b
def show(self):
print("a=",self.__a,"b=",self.__b)
def __call__(self, num):
print("call:",num + self.__a)
a = A(5,10)
a.show()
a(20)
第77题: 下面这段代码的输出是什么?
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
class B(object):
def __init__(self):
print("B init")
def run(self):
print("B run func")
class A(object):
def run(self):
print("A run func")
def __new__(cls, a):
print("new",a)
if a>10:
return super(A,cls).__new__(cls)
return B()
def __init__(self,a):
print("init",a)
a1 = A(5)
a1.run()
a2 = A(20)
# a1 = A(5)
new 5
B init
# a1.run()
new 5
B init
B run func
# a2 = A(20)
new 5
B init
B run func
new 20
init 20
第78题: 下面这段代码输出什么?
num = 9
def fn1():
num = 20
def fn2():
print(num)
fn2() # 9
fn1() # 啥都没有
fn2() # 9
第79题:如何添加代码,使得没有定义的方法都调用myfunc方法?
class A(object):
def __init__(self,a,b):
self.a1 = a
self.b1 = b
print("初始化方法")
def myfunc(self):
print("myfunc")
a1 = A(10,20)
a1.fn1()
a1.fn2()
a1.fn3()
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
class A(object):
def __init__(self,a,b):
self.a1 = a
self.b1 = b
print("初始化方法")
def myfunc(self):
print("myfunc")
def __getattr__(self, item):
return self.myfunc
a1 = A(10,20)
a1.fn1()
a1.fn2()
a1.fn3()
__getattr__。*args 不定参数来兼容。第80题: python下多线程的限制以及多进程中传递参数的方式?
import threading
global_num = 0
def test1():
global global_num
for i in range(1000000):
global_num += 1
print("test1", global_num)
def test2():
global global_num
for i in range(1000000):
global_num += 1
print("test2", global_num)
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
import threading
import time
global_num = 0
lock = threading.Lock()
def test1():
global global_num
lock.acquire()
for i in range(1000000):
global_num += 1
lock.release()
print("test1", global_num)
def test2():
global global_num
lock.acquire()
for i in range(1000000):
global_num += 1
lock.release()
print("test2", global_num)
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
start_time = time.time()
t1.start()
t2.start()
第81题:解释一下python的and-or语法
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
>>> a = "first"
>>> b = "second"
>>> 1 and a or b # 输出内容为 'first'
>>> 0 and a or b # 输出内容为 'second'
>>> a = ""
>>> b = "second"
>>> 1 and a or b # 输出内容为 'second'
def choose(bool, a, b):
return (bool and [a] or [b])[0]
第82题: 请至少列举5个 PEP8 规范?
https://www.python.org/dev/peps/pep-0008/
第83题: HTTPS和HTTP的区别:
第84题:简述Django的orm
第85题: Flask中的请求上下文和应用上下文是什么?
这保证了请求的处理过程不被干扰。
包含了和请求处理相关的信息,同时Flask还根据werkzeug.local模块中实现的一种数据结构LocalStack用来存储“请求上下文”对象。
“应用上下文” 的构造函数也和 “请求上下文” 类似,都有app、url_adapter等属性。“应用上下文” 存在的一个主要功能就是确定请求所在的应用。第86题:django中间件的使用?
def __init__():
pass
def process_response(request):
pass
def process_view(request.view_func, view_args, view_kwargs):
pass
def peocess_template_response(request, response):
pass
def process_response(request, response):
pass
def process_exception(request, execption):
pass
第87题: django开发中数据做过什么优化?
第88题: 解释一下 Django 和 Tornado 的关系、差别?
第89题:什么是restful API ,谈谈你的理解?
第90题: 简述解释型和编译型编程语言?
第91题:Python解释器种类以及特点?
第92题: 位和字节的关系?
第93题: 字节码和机器码的区别?
手编程序时,程序员得自己处理每条指令和每一数据的存储分配和输入输出,还得记住编程过程中每步所使用的工作单元处在何种状态。
这是一件十分繁琐的工作,编写程序花费的时间往往是实际运行时间的几十倍或几百倍。
而且,编出的程序全是些0和1的指令代码,直观性差,还容易出错。
现在,除了计算机生产厂家的专业人员外,绝大多数的程序员已经不再去学习机器语言了。第94题:Python3和Python2中 int 和 long的区别?
int类型的最大值不能超过sys.maxint,而且这个最大值是平台相关的。
可以通过在数字的末尾附上一个L来定义长整型,显然,它比int类型表示的数字范围更大。
由于已经不存在两种类型的整数,所以就没有必要使用特殊的语法去区别他们。第95题:是否遇到过python的模块间循环引用的问题,如何避免它?
第96题:简单介绍一下python函数式编程?
fliter(),map(),reduce(),apply()函数来支持函数式编程。
所以你的重点围绕fliter(),map(),reduce().apply()来介绍就可以顺利和面试官达成一致第97题:python中函数装饰器有什么作用?
插入日志、性能测试、事务处理、缓存、权限校验等场景。第98题: 按照要求完成编码?
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def function(lefdict,rightdict,choice):
samelist=lefdict.keys() & rightdict.keys() # dict.keys()返回的是一个可迭代对象,取两个dict的keys的交集
diflist = lefdict.keys() ^ rightdict.keys() # 取两个dict的keys的不同集
newdict={
}
for key,value in lefdict.items():
if key in diflist:
newdict[key]=value
elif key in samelist:
if value==choice:
newdict[key]=value
for key,value in rightdict.items():
if key in diflist:
newdict[key]=value
elif key in samelist:
if value==choice:
newdict[key]=value
print(samelist,diflist)
print(newdict)
return newdict
function({
1:'a',2:'b',3:'c'},{
4:'f',2:'b',3:'d'},'b')
第99题:如何理解 Django 被称为 MTV 模式?
第100题:解释下什么是 ORM 以及它的优缺点是什么?
第101题:Django 系统中如何配置数据库的长连接?
CONN_MAX_AGE,在 settings 的 DATABASES 配置中。配置了该选项后,Django 会跟数据库保持链接(时长取决于 CONN_MAX_AGE设定的值 ),不再会针对每个请求都创建新的连接了。第102题: 请解释一下python的线程锁Lock和Rlock的区别,以及你曾经在项目中是如何使用的?
第103题:字典、列表查询时的时间复杂度是怎样的?
结尾给大家推荐一个非常好的学习教程,希望对你学习Python有帮助!