如何写一个神经网络
本文我们介绍如何利用python自己手写一个神经网络
神经网络介绍
神经网络其实很简单 —— 多层感知机,不懂感知机原理得可以看博主之前写的感知机及Python实现。
正如感知机及Python实现中所描述的,感知机的权重 w w w 和偏置 b b b 很容易更新,但多层感知机的权重就更新就得靠求导工具了。
这里我们使用pytorch中的求导工具来实现,至于神经网络权重更新的过程,还是和感知机一样。
本文我们实现一个3层神经网络:
神经网络python实现
我们用神经网络来模拟 y = x 2 y=x^2 y=x2 的计算过程,以下为代码:
import torch
import matplotlib.pyplot as plt
class Network:
def __init__(self,len_input,len_hidden,len_output):
'''
define some necessary parameters
:param len_input: the length of input data
:param len_hidden: the length of hidden layer
:param len_output: the length of output data
'''
### the weight and bias of hidden layer
self.w1=torch.rand(len_input,len_hidden,requires_grad=True)
self.b1=torch.rand(len_hidden,requires_grad=True)
### the weight and bias of output layer
self.w2=torch.rand(len_hidden,len_output,requires_grad=True)
self.b2=torch.rand(len_output,requires_grad=True)
### other parameter
self.loss=0
def mse(self,act,pre):
'''
calculate mse loss
:param act: actual value
:param pre: predicted value
:return: the loss
'''
assert act.__len__()==pre.__len__()
res=0
for a,p in zip(act,pre):
res+=(a-p)**2
return (res/act.__len__())**0.5
def predict(self,value_input):
'''
predict the label with current parameters
:param value_input: the input data
:return: the predicted data
'''
o1=torch.add(torch.matmul(torch.sigmoid(value_input),self.w1),self.b1)
out=torch.add(torch.matmul(o1,self.w2),self.b2)
out=torch.sigmoid(out)
return out
def update(self,act,pre,learning_rate=0.1):
'''
update the parameters
:param act: actual value
:param pre: predicted value
:param learning_rate: learning rate
:return: None
'''
self.loss=loss=self.mse(act,pre)
loss.backward()
with torch.no_grad():
self.w1.data-=learning_rate*self.w1.grad.data
self.b1.data-=learning_rate*self.b1.grad.data
self.w2.data-=learning_rate*self.w2.grad.data
self.b2.data-=learning_rate*self.b2.grad.data
self.w1.grad.data.zero_()
self.b1.grad.data.zero_()
self.w2.grad.data.zero_()
self.b2.grad.data.zero_()
def accuracy(self,act,pre):
'''
calculate the accuracy
:param act: actual value
:param pre: predicted value
:return: accuracy
'''
assert act.__len__()==pre.__len__()
return round((act==pre).sum().item()/act.__len__(),3)
def show(self,act,pre,epoch):
'''
show training effect real-time
:param act: actual value
:param pre: predicted value
:param epoch: current training time
:return: none
'''
plt.cla()
plt.plot(act,'r',label='actual')
plt.plot(pre,'b',label='predicted')
plt.title('epoch:'+str(epoch))
plt.legend()
plt.pause(0.2)
def train(self,feature,label,epoch,verbose=False):
'''
train your neural network
:param feature: feature
:param label: label
:param epoch: training times
:param verbose: whether view the training process or not
:return: none
'''
for e in range(epoch):
pre=self.predict(feature)
self.update(label,pre)
if e%1000==0 and verbose:
with torch.no_grad():
act=[round(i,3) for i in y.tolist()]
pre=[round(i,3) for i in pre.view(-1).tolist()]
print('epoch:',e,'loss:',self.loss.item())
print('act',act)
print('pre',pre)
self.show(act,pre,e)
if __name__ == '__main__':
### generate feature and label
x=torch.tensor([[0.1*i] for i in range(0,10)]) # feature
y=torch.tensor([i**2 for i in x]) # label
### build your network
net=Network(1,10,1)
### train your network
net.train(x,y,20000,verbose=True)
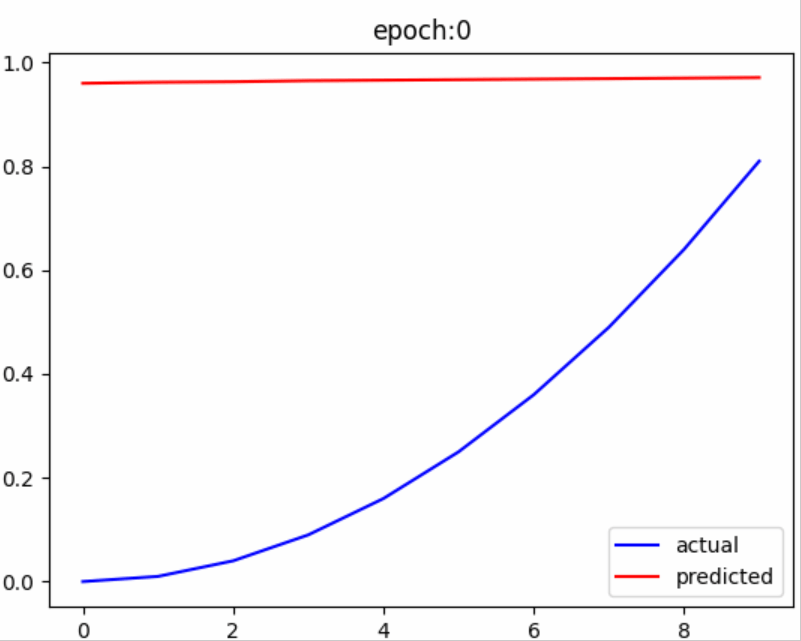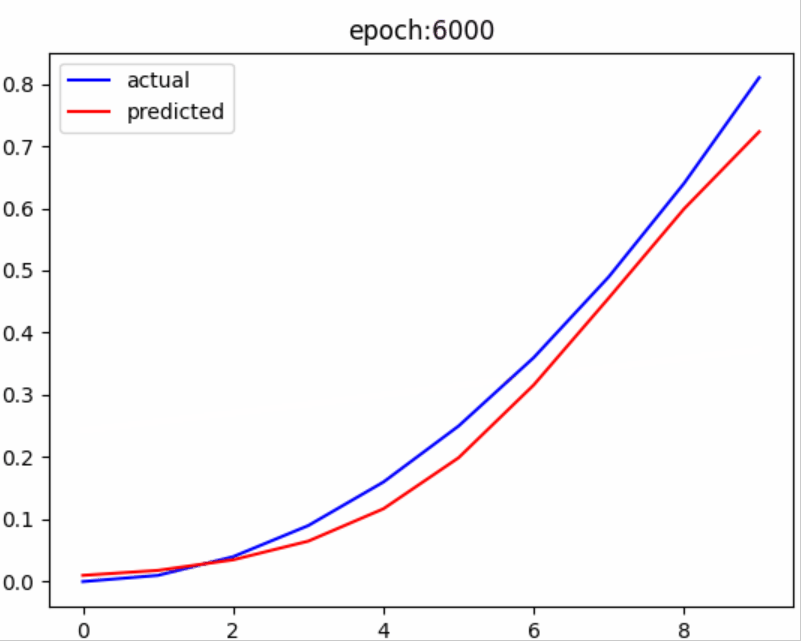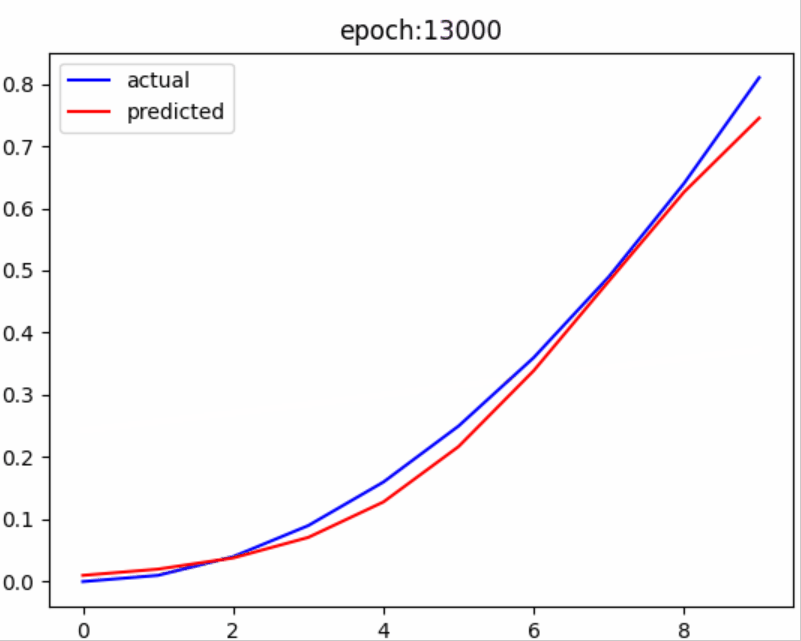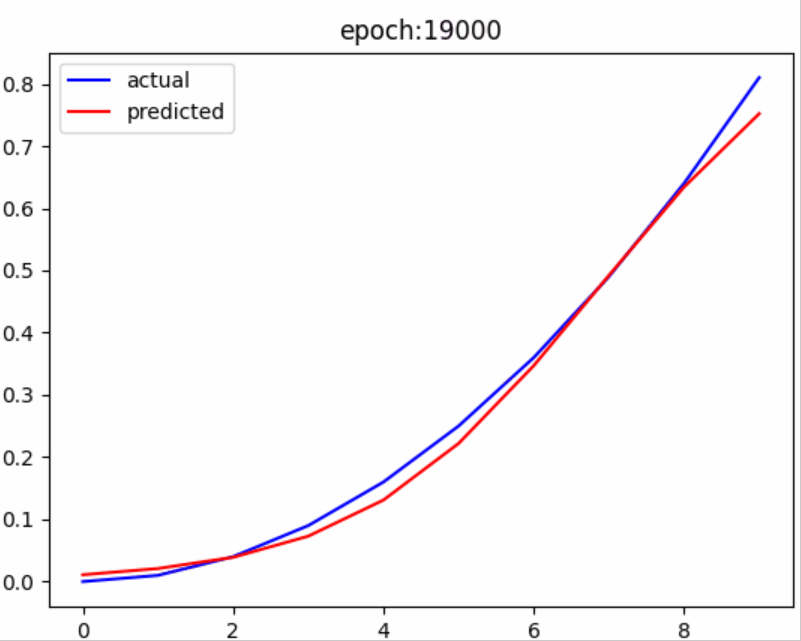
结果展示
从结果中可以看出,随着训练次数的增加,预测值不断接近真实值,没有什么比这更激动人心的时刻了。