
前言
讲数据质量监控重要性和理论的文章,去网上可以搜到很多,这篇文章主要讲怎么设计和开发数据质量监控平台。
第一部分:介绍
数据质量监控平台(DQC)是支持多数据源的根据用户配置的质量监控规则及时发现问题,并通过邮件通知告警的一站式平台。
目前,数据质量监控功能为用户提供10余种预设的数据质量检测模板,支持:PSI计算、缺失分区和及时性检查、磁盘波动率检查、表行数波动率检查、饱和度检查、列异常数据检查、主键重复值检查和计算统计指标等功能。
想了解我们公司的数据处理流程和数据监控内容,可以参考墨竹的文章,但请注意截图为老版本DQC,新版本UI发生了较多的变化。平台新版本的截图如下。极客星球| 数据质量保障之路的探索与实践
DQC,在架构上分为2层,java开发负责的业务层,大数据开发负责的数据处理层。
业务层是一个web服务,实现了对用户和检测对象的管理,对检测对象的计算调度,对返回监控结果的展示。
数据处理层完成了具体的数据质量监控任务。DQC的架构图如下:
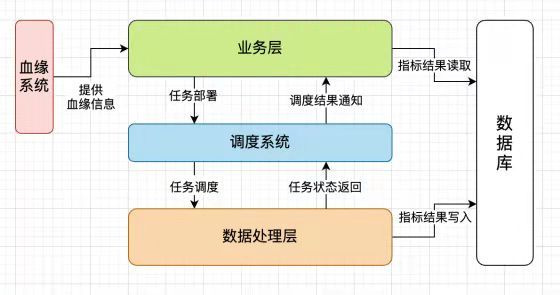
因为本人是大数据平台开发,所以设计和实现主要集中在数据质量监控的数据处理层。业务层的检测对象配置和调度因为和数据处理层联系比较密切,所以也参与了设计。
第二部分:设计
数据质量的核心功能实现,大致就是根据需要预先定义的监控指标设计出计算模版(sql和api)。
然后根据具体需要监控的对象填充对应的模版就可以进行监控。
下面将展示我设计和实现DQC的过程。
一、基本思路
规则的显示大致可以分为2类:
1.sql可以解决的,例如表行数波动率,数据异常率等。
2.其他类型,通过脚本或者接口来实现,例如缺失分区检查,磁盘容量波动率等。
先给一个波动率的公式:
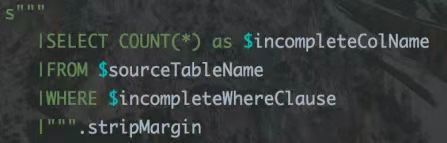
1.1 SQL模版具体的例子(表行数波动率):
1 CREATE TEMPORARY VIEW a as
2 SELECT COUNT(*)
3 FROM ${database}.${table}
4 WHERE day = 'today - period';
5
6 CREATE TEMPORARY VIEW b as
7 SELECT COUNT(*)
8 FROM ${database}.${table}
9 WHERE day = 'today';
10
11 SELECT (b.cnt - a.cnt) / b.cnt as rate
12 FROM a JOIN b
在这个表行数波动率sql模版中需要填充的变量是库表名和时间周期(日,2周,1月等)。
在这个sql模版在实际中会有很多不足,例如日期字段不是day而是date,用户还需要额外的可配置过滤条件等等。这些都需要在结合生产进行进一步的设计和实现。
1.2 脚本的例子(磁盘容量波动率):
以下的代码并不能运行,需要再附加一些额外处理。

rate = (b - a) / b
从这2个例子中,可以看出这里一共由2个子步骤组成。首先是就是获取规则中所需要的统计数量(表行数,磁盘容量等);然后是根据具体的规则指标(波动率)进行计算。
通过计算得到规则实际结果,需要跟预期值进行比较。例如希望表行数波动在[-0.2, 0.2]之间,如果是0.5就告警,通知对应负责人进行处理。
二、模块化设计
根据基本思路中三步骤,来详细展开。我在设计系统的时候,参考了ebay开源的Apache Griffin。
2.1 统计数量的计算获取
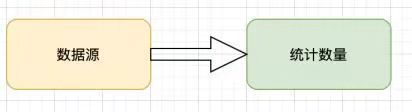
统计数量的计算获取可以分为2个部分,一个是数据源,一个统计数量。
数据源可以是hive,hbase,mysql,mongodb等等。
统计数量也就是计算或者是获取到对应的数据,在基本思路中可以看到,这里的计算和获取动作是会重复的。所以在这一层是可以做一些抽象的。可以细化出一些小的方法,然后进行组合,来得到实际的效果。
这一层抽象出了数据源和数据计算子步骤。
2.2 规则指标的计算
规则指标的计算就是最重要的一部分,这部分会影响到上面的统计数量具体的实现。

上面是我们在实际生产经验中提取出来需要监控的规则指标。
一共14个,除了第一个缺失分区检查可以直接得到结果。后面都含有计算逻辑在其中。统计指标我直接使用spark dataframe的summary算子得到的,这里也可以使用udf来实现。其他的12个大致由以下操作(操作包含了2.1中统计数量)得到。
1.检查数据是否匹配 Accuracy
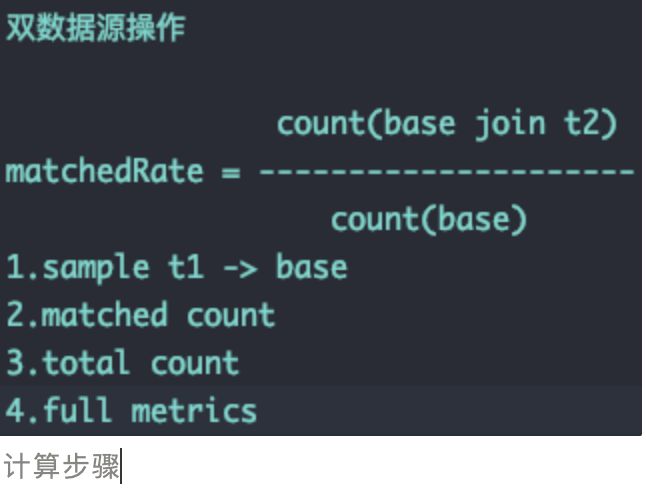
2.检查数据完整性 Completeness
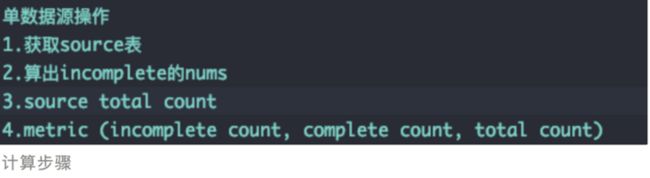
3.数据去重计数和区间计数 Distinctness
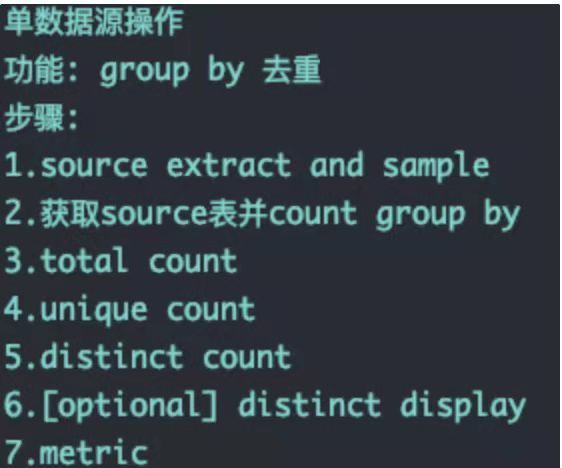
4.环比 Ratio
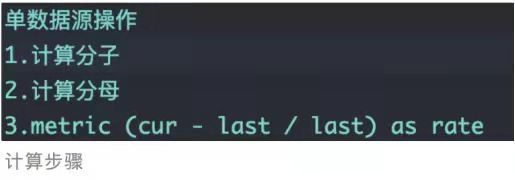
5.PSI
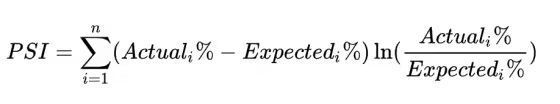
所以在这里,我根据需要计算的指标模版进行了详细的操作拆分,形成4个计算步骤组合,其子步骤部分,不同步骤组之间可以共享,也可以单独实现子步骤组。观察上面可以看到有sample这个步骤,做数据质量检查的时候,全量有时候太慢,就失去了及时性,同时也会对集群资源造成压力。所以需要提供数据采样功能。
这里附一张我们系统实现的步骤组。多出来的2个,MultiRatio是做分组波动计算的,算是ratio的扩展。profiling可以算是子步骤的一种,用户实际处理数据中,会有更高的要求,profiling这个步骤组可以完成spark sql计算的所有功能(用户并不会传完整的sql,所以需要这样一个步骤组来处理)。本人对特殊指标,例如缺失分区检查,就单独实现了,并不会用到步骤组,后面实现部分可以看到另一层抽象。

所以在这个部分,我们完成对整个数据计算的步骤抽象。
2.3 结果的检查与输出
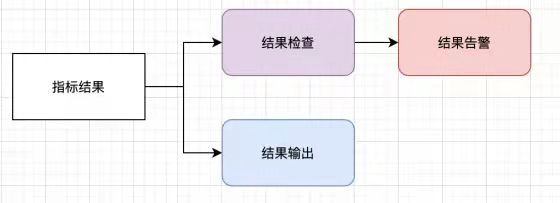
经过以上2步,我们就到了指标结果。我们需要将指标结果落库,同时对指标结果进行检查,不符合用户设定的阈值就发送邮件告警,让用户来处理。
结果输出部分,结果是以约定的json形式存储,采用json存储,看中其可伸缩性。原因如下:在计算指标的时候,一些中间结果会在查错提供很大帮助。例如:是我们计算异常占比的时候,同时会计算出异常值的数量和总量,当结果不符合预期的时候,这些内容是很重要的查错信息。我们可以选择mongodb,mysql等存储最终结果。
结果检查部分,我用了scala的解析器组合子库来实现,具体见实现。在结果输出部分提到了,结果可能输出多个,那同样的,用户也就可以同时检查多个结果值,提供了dsl来完成这项工作。
在这一层,我们完成了结果输出的抽象和结果检查的功能实现。
三、实现
整个数据处理层会使用spark来作为计算引擎。根据业务层传来的Json参数来进行具体的任务生成。下图是任务参数框架。

- 数据源
因为采用spark作为计算引擎,所以从数据源中获取对应的数据用spark的算子即可。spark本身实现对很多数据源的数据提取,所以整个数据源部分的实现相对简单,可以根据自己实际的需求来编写数据源类。对每种数据源会有自己需要定制化的内容,我们在config参数中进行即可。

我会拿Hive数据源讲解一下,实现了哪些内容,数据库类的数据源相对容易实现。针对Hive数据源,首先是需要一些过滤条件,这部分以key value对的方式来配置。
在数据质量检查中最重要的一个变量就是时间。关于时间,主要有2个需要处理的点。
1.因为具体的时间格式不同,有的是yyyyMM, yyyy-MM-dd,或者具体到时间。我们采用的方案是业务层统一传yyyyMMdd,其为变量$day,可以在分区字段中使用即可。还提供了${latest_partition}变量来获取最新分区。以及对这2个变量可以使用spark udf来获取指定的时间格式。
2.另外一些指标,例如波动率,是同一个数据2个时间点的比较。所以还会带入时间周期的概念。例如每天,每周二,每月16日。

- 构建计算步骤
这里许多概念和Apache Griffin一致,但具体实现有很大差异。
业务层首先会根据触发条件和库表聚合调度,使得同一个数据源同一日期的检测对象一起调度。
检测对象下文都称为rule。
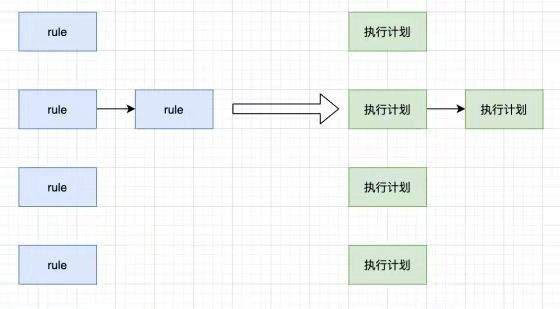
第一步 rule的处理
构建的第一步就是对rule进行处理,例如psi这类的rule,可以先拆分成多个rule,例如分布区间的psi,可以拆分为分布区间和psi 2个rule,这里就存在了依赖关系。构建了一个rule的DAG。
第二步 rule转换成执行计划
一个rule转换成一个执行计划。执行计划的功能就是生成具体的任务步骤。
第三步 生成计算步骤
这一步有很多的优化空间,详细内容见四、优化
计算步骤分为4大类:
1.不需要走spark任务计算,例如磁盘容量,直接用hadoop api查询即可。
2.spark sql步骤组就是2.2 规则指标的计算中提到的,由4组成。
3.spark 算子,例如查询hbase和数据库,summary算子之类的操作。
4.spark sql计算步骤,写好的spark sql,预留了变量填充。
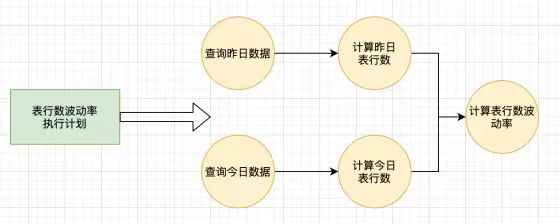
每一个执行计划会对应一个或者多个计算步骤。如下图,展示了表行数波动率和异常数据占比率的转换过程。
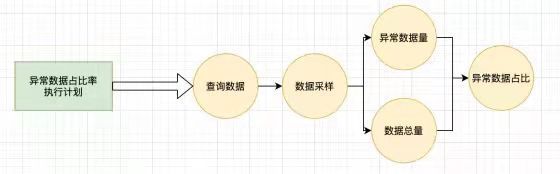
3 .计算步骤执行
经过上述的转换,我们可以得到计算步骤的DAG,之后对这个DAG进行并发执行就可以了。
这样的并发执行可以更充分的使用sprak executor的资源。比如串行执行,200cores的资源,一个job因为数据倾斜等原因,最后20个task执行较慢。这时候后面的job并不会启动,而且可能因为等待时间过长,部分executor被释放了。但如果是并发执行,空闲的180cores就会执行其他未完成的job。
- 结果告警
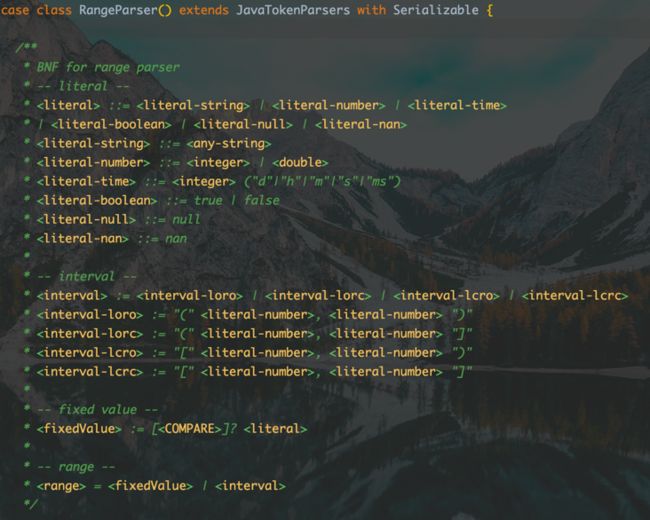
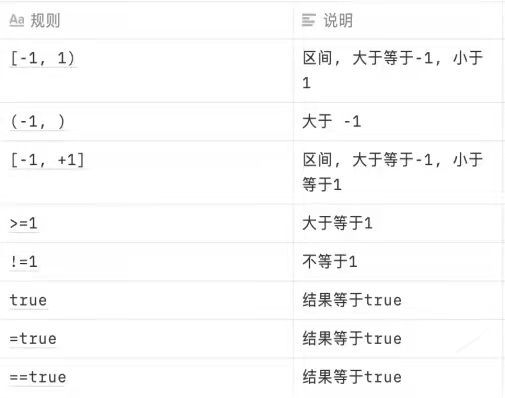
结果检查部分,我用了scala的解析器组合子库来实现,BNF和规则如下图。得到结果后就会发给邮件指定的负责人,这里也可以支持短信和电话。
- 结果输出
这里是结果落库的步骤,根据不同库的写入方式落库即可。
四、优化
这里的优化都是针对构建计算步骤的。整体的优化方向就是合并DAG和复用已经存在的结果。
- 过程复用
计算步骤DAG可以根据节点是否计算逻辑相同进行合并重组,形成优化的计算步骤DAG。
如图所示,16个计算步骤被优化成11个计算步骤。被复用的节点会用 df.cache() 算子来进行缓存,加速计算。
这里主要实现有节点的身份信息(其计算逻辑和数据信息),依据节点的身份信息来进行比较合并。
同时需要依据更新的节点信息来合并多个子DAG。
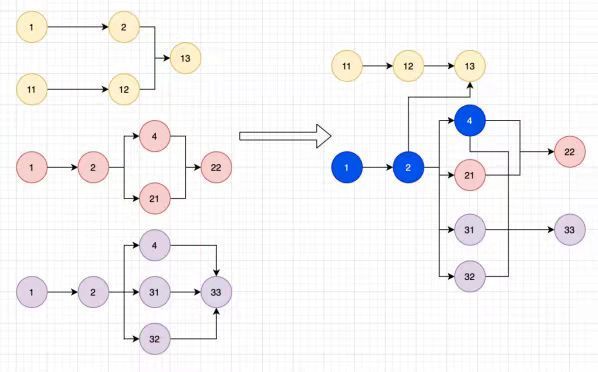
2 .计算步骤DAG节点转换
常量替换
计算异常数据波动率,公式为异常数据量/总数据量。如果用户使用该规则,采样了10w数据,那总数据量其实并不需要触发计算,可以直接转换成常量。公式就会转换成异常数据量 / 10w。
过往结果复用
表行数波动率(每日),公式为(今⽇数据量—昨⽇数据量)/ 昨⽇数据量。
7月2日的时候,公式为![]()
7月3日的时候,公式为![]()
可以从中看到7月3日计算表行数波动率时,7月2日的Cnt可以读取前一天的结果,从而避免计算。但需要注意的是,复用这个结果之前,需要检查前一天结果计算完毕之后,分区数据和检测对象配置有没有发生改变。没有发生改变才可以复用,否则,必须重新计算。
这种将计算步骤转换成常量读取,来规避触发计算,也能带来显著的性能提升。