ResNet 论文学习笔记
1. ResNet 提出的背景
深层卷积神经网络在图像分类领域取得了很多很棒的进展,因为随着网络层次的加深,feature level 从 low--mid--high 逐步得到丰富,但是通过简单堆叠多层网络真的可以学的更好吗?(Is learning better networks as easy as stacking more layers? )答案是否定的。随着网络层次的加深,会出现两个问题:
1)梯度消失/爆炸 (vanishing/exploding gardient)
梯度消失/爆炸会阻碍网络收敛,此问题可借助 normalized initialization 和 Intermediate normalization layers(BN层)得到较好的解决。☞ Batch Normalization
2)退化问题(degradation problem)
虽然BN较好的解决了梯度问题,但是随着网络层数的加深,训练正确率会趋于饱和随后急剧下降,该问题并不是由于过拟合导致的(原文作者猜想可能是由于深层网络使得网络的收敛速率指数级下降)。ResNet 就是为了解决退化问题而提出来的(提出了残差结构)。
2. ResNet 的思想
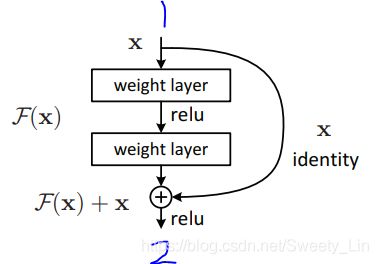
针对当前的这几层来说,如果不考虑 identity 位置的映射x,网络的学习任务是从 1 处的 x 学习一个映射关系 H(x),然后经过 ReLU 模块之后输出到 2 位置,即 σ(H(x))。
但是鉴于 退化问题 的存在,为了保证 2 处的学习效果 不差于 1 处,ResNet 引入了 identity 处的连接,叫做“shortcut connections”,此时 H(x) = F(x) + x,当前模块的学习目标是 resudual function F(x) = H(x) - x。
为什么这样做呢?因为 退化问题 实际上是说 2 处的学习效果差于 1 处,即该模块难以用图中的两个非线性 layer 去学习到一个线性的 恒等映射(此时1和2的学习效果相等);而 residual function 可以通过将 图中两层神经元的权值都逼近0而方便的学到 恒等映射,从而保证了 2 处的学习效果不差于1。
3. ResNet 的学习目标 F(x)
既然要学习 F(x),那我们就来看一下 F(x) 的表达式:
输入 x 经过第一个 weighted layer 的输出为 W1*x,经过 ReLU 之后的输出为 σ(W1*x),再经过第二个 weighted layer 的输出即为 F = W2*σ(W1*x),最终该模块在 2 处的输出为
σ(F + x) = σ(W2*σ(W1*x) + x)
在上面的这个公式中,x 和 F 需要有相同的 dimension,但是实际网络中可能存在 x 和 F 尺寸不相同的情况,此时就涉及到 shortcut 的两种连接方式:
1)identity mapping:当 x 和 F 的尺寸相同时,上式可以直接操作,无需引入额外的参数和计算复杂度;
2)projection:引入一个线性的映射矩阵 WS 将 x 映射为和 F 相同尺寸的矩阵,再进行相加,此时上式变为 σ(F + WS*x)。projection也可以用zero-padding代替,从而无需引入额外的学习参数,但是projection的效果要比zero-padding好一些。
在卷积神经网络中,F 执行的操作是两个 feature map 的 每个通道的 逐像素 求和。
4. Residual block 的架构
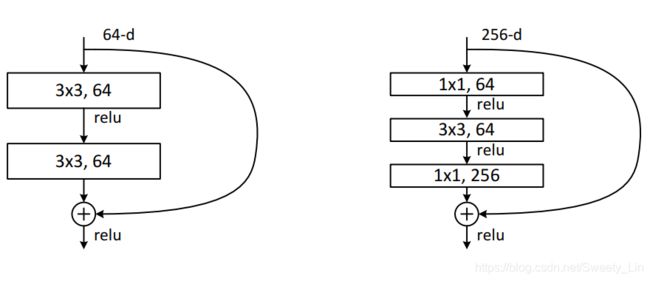
左侧的2层架构用在 ResNet-34 中,右侧的3层架构(bottleneck design)用在 ResNet-50/101/152 中,其中 1*1的层用于降维和升维,从而使得 3*3层的输入输出维度比较小,减少参数量,而且也便于使用 identity mapping,降低了运算复杂度。
为什么右侧的残差结构可以减少训练参数量呢?假设给左右两个架构均输入 256d 的特征向量,针对左侧的残差结构,为了保证主分支与shortcut的输出特征矩阵有相同的 shape,则主分支的 kernel number 也应该设置为256,则左侧的参数量为 3*3*256*256 + 3*3*256*256 = 1179648;而右侧的残差结构通过第一个1*1的降维和第二个1*1的升维,保证了主分支的输出特征维度与shortcut相同,所以右侧的参数量为 1*1*256*64 + 3*3*64*64 + 1*1*64*256 = 69632,是左侧 (1179648 / 69632 ≈ 17)的1/17。
5. ResNet 的整体结构和参数设计
ResNet 是参照 VGG-19的网络架构,首先将网络层数扩展到34层,然后添加了 shortcut connection,如下图所示,其中实线代表3中介绍的 identity mapping,虚线表示 projection:
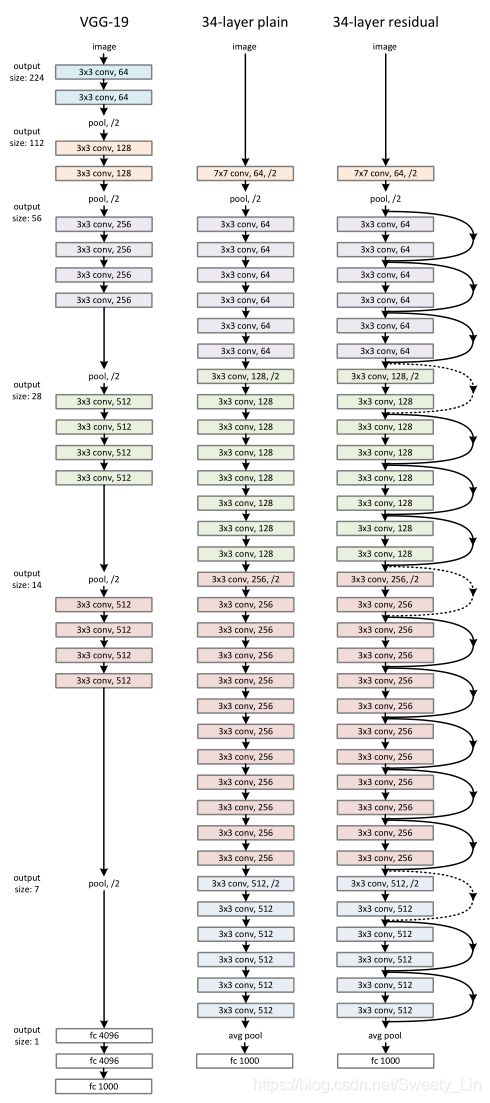
以第一个虚线连接为例,介绍一下projection的操作:

从文章中的结果可以看出, ResNet相较于同层数的 plain net 可以加速收敛,且深层的 ResNet 比 浅层的 ResNet 有很好的性能提升。
网络亮点:
1. 超深的网络结构(突破1000层)
2. 提出 residual 模块
3. 使用 batch normalization 加速训练,丢弃 dropout
原文链接:https://arxiv.org/pdf/1512.03385.pdf