轻量化网络:MobileNets
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications(MobileNets paper)是CVPR-2017一篇paper,作者均来之Google,其提出一种“新”的卷积方式来设计网络,主要针对移动端设备所设计,因此,得名MobileNets
注:MobileNets不是模型压缩技术!! 只是一种网络设计思想,利用这种方法设计出来的网络存在1)参数少 2) 运算速度快的优点!
创新点:
- 改变传统卷积方式,采用depth-wise separable convolutions以达到模型压缩(inspired by inception、Xception)
MobileNets在卷积方式上做文章的。
通过采用新的卷积方式,达到:1.减少参数数量 2.提升运算速度。(这两点是要区别开的,参数少的不一定运算速度快!)(MobileNets primarily focus on optimizing for latency but also yield small networks. Many papers on small networks)
-------------------------------------------------分割线-------------------------------------------------------------
言归正传,MobileNets精华就在新的卷积方式——depth-wise separable convolutions;采用depth-wise separable convolutions,会涉及两个超参:Width Multiplier和Resolution Multiplier这两个超参只是方便于设置要网络要设计为多小,方便于量化模型大小。
depth-wise separable convolutions是将标准卷积分成两步:第一步 Depthwise convolution,也即逐通道的卷积,一个卷积核负责一个通道,一个通道只被一个卷积核“滤波”;如下图所示; 第二步,Pointwise convolution,将depthwise convolution得到的结果再“串”起来
,注意这个“串”是很重要的。“串”作何解?为什么还需要 pointwise convolution?作者说:However it only filters input channels, it does not combine them to create new features. Soan additional layer that computes a linear combination ofthe output of depthwise convolution via 1 × 1 convolutionis needed in order to generate these new features。
首先要承认一点:#输出的每一个feature map要包含输入层所有feature map的信息#。仅采用depthwise-convolutions,是没办法做到这点,因此需要pointwise convolution的辅助。
Standard convolution、depthwise convolution和pointwiseconvolution示意图如下:
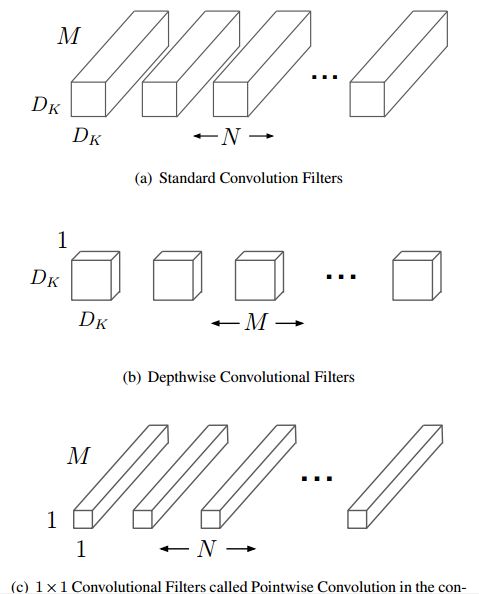
其中输入的feature map有M个,输出的feature map有N个。Standard convolution呢,是采用N个大小为DKDK的卷积核进行操作(注意卷积核大小是DKDK,
DKDKM是具体运算时候的大小!)
而depthwise convolution + pointwise convolution需要的卷积核呢?
Depthwise convolution :一个卷积核负责一个通道,一个通道只被一个卷积核卷积;则这里有M个DKDK的卷积核;
Pointwise convolution:为了达到输出N个feature map的操作,所以采用N个11的卷积核进行卷积,这里的卷积方式和传统的卷积方式是一样的,只不过采用了1*1的卷积核;其目的就是让新的每一个feature map包含有上一层各个feature map的信息!在此理解为将depthwise convolution的输出进行“串”起来。
下面举例讲解 Standard convolution、depthwise convolution和pointwise convolution
假设输入的feature map 是两个55的,即552;输出feature map数量为3,大小是33(因为这里采用33卷积核)即333。
标准卷积,是将一个卷积核(33)复制M份(M=2),让二维的卷积核(面包片)拓展到与输入feature map一样的面包块形状。
逐通道卷积则没有二维变到三维这一操作,具体如下图所示:
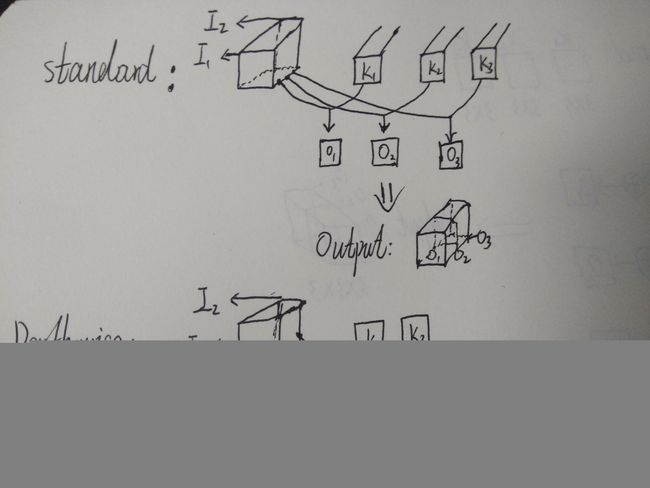
Standard过程如下图,X表示卷积,+表示对应像素点相加,可以看到对于O1来说,其与输入的每一个feature map都“发生关系”,包含输入的各个feature map的信息。而Depthwise并没有,可以看到depthwise convolution 得出的两个feature map——fd1 和fd2分别只与i1和i2 “发生关系” ,这就导致违背上面所承认的观点“输出的每一个feature map要包含输入层所有feature map的信息”,因而要引入pointwise convolution
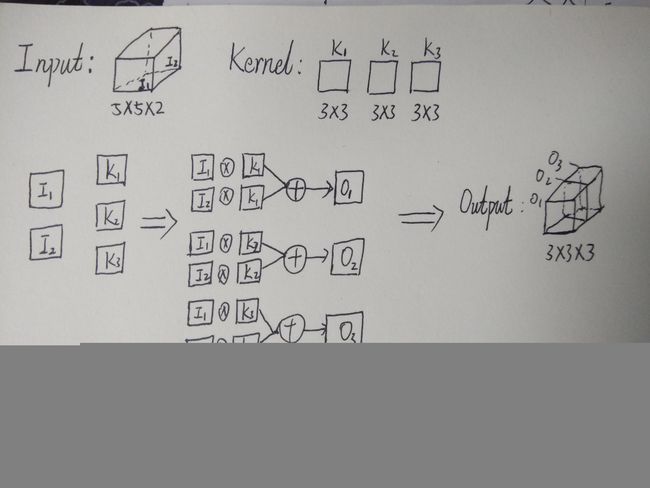

那么参数减少了多少呢?通过如下公式计算:

其中DK为标准卷积核大小,M是输入feature map通道数,DF为输出feature map大小,N是输出feature map通道数。本例中,DK=3,M=2,DF=5,N=3
其实主要就与卷积核大小DK有关~~~
至于实现方面,毕竟是google的人做的文章,自然是对Tensorflow支持比较好,有人在caffe上实现过,但由于架构不一样,发现并没有获得好的提速效果。
至于两个超参我是没理解具体怎么用,若有知道的朋友请在评论区讨论讨论呗!
胡思乱想:
回顾一下standard convolution,请看下图standard部分:
假如K1、K2、K3具有很强的相关性呢?或者是线性相关呢?这样得出来的O1、O2、O3岂不是有冗余?
那么对这些卷积核进行SVD分解,恰恰是解决这个问题~ 但是SVD分解是对训练好的模型进行操作,还是有够完美,那么能否在训练过程中就进行卷积核“去相关”操作呢? 最直接的方法就是找一个衡量相关性的变量,然后将其扔进目标函数当中,作为一个正则项,就可以在训练过程当中进行卷积核的去留选择,达到“压缩”目的。
不少CVPR,ICCV,ECCV的paper就是提出一个高大上的东西,其作用就是regularization(
例如
2016-ICCV:Augmenting Supervised Neural Networks with Unsupervised Objectives-ICML-2016;
2014-ECCV-TCDCN-Facial Landmark Detection by Deep Multi-task Learning
2017-ICCV-Networks Slimming
等~
新idea就是找一个变量控制卷积核相关性,将其扔到目标函数当中,在训练时达到模型压缩效果。有兴趣同学可以试试,如果OK的话,就可以投一篇CVPR,ICCV,ECCV了~~