浅谈YOLOv3及算法复现
文章目录
- 前言
- 一、数据预处理
- 二、模型搭建
-
- 1.整体框架
- 2.创建模块
- 3.YOLO层
- 4.Darknet类
- 三、训练部分
- 总结
前言
写这篇文章的初衷是为了记录自己在YOLOv3学习过程中的一些理解。在YOLOv3的学习过程中,我会有这种苦恼:网络的整体框架我能够明白,但是具体的实现过程却很模糊,于是便有了这篇博客。之前在学习YOLOv1时,这两篇博客对我的帮助很大:
经典论文解析——YOLOv1——目标检测
动手学习深度学习pytorch版——从零开始实现YOLOv1
如果对YOLO系列还没有大致的了解,建议先从这两篇博客入手学习。可惜博主没有更新后来的YOLO系列,于是我选择精读大神的PyTorch复现版本:
eriklindernoren/PyTorch-YOLOv3
本文就是根据这个版本的复现对YOLOv3算法训练部分的实现细节进行分析,面向的是对YOLOv3已经有大致了解并想研究训练部分具体实现方式的读者。如有错误,请评论指出,共同进步,谢谢。
一、数据预处理
代码是基于COCO数据集的复现,由于我之前用过VOCDeteciton2012的数据集,所以就继续使用VOC数据集了。
datasets.py和transforms.py包括了主要的数据集的读取和预处理。在datasets.py中创建了ListDataset类来封装数据,train.py中读取数据集的代码如下:
# Get dataloader
dataset = ListDataset(train_path, multiscale=True, transform=AUGMENTATION_TRANSFORMS)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=8,
pin_memory=True,
collate_fn=dataset.collate_fn,
)
其中AUGMENTATION_TRANSFORMS的定义在transforms.py中,主要包括boxes的相对坐标和绝对坐标的转换、图片增强、将图片填充为正方形和将图片和boxes转换为tensor形式。
AUGMENTATION_TRANSFORMS = transforms.Compose([
AbsoluteLabels(),
DefaultAug(),
PadSquare(),
RelativeLabels(),
ToTensor(),
])
二、模型搭建
1.整体框架
在介绍models的具体实现方式之前,先来看一下YOLOv3的整体框架图(引用木盏的结构图):
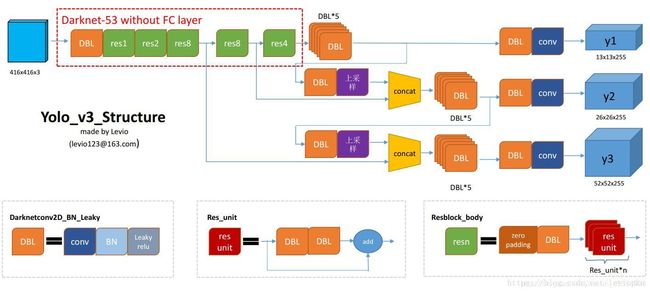
网络的backbone采用了resnet的结构,输入图像为416x416尺寸,经过Darknet-53提取特征。output的尺寸分别为13x13x((5+classes)x3)、26x26x((5+classes)x3)、52x52x((5+classes)x3),分别对应经过32次、16次、8次下采样。其中,5+classes为对x、y、w、h、conf的预测加上class的数量。YOLOv3采用了anchors的方法,对目标的尺寸给予了一个先验指导,作者在数据集上对目标框的大小使用了k-means聚类,得到了9个不同尺寸的anchors,根据anchors的大小,每种尺寸的输出对应3个尺寸的anchors,这也就是为什么输出的第三个维度5+classes要乘以3,至于具体的实现方式将在下文结合代码进行介绍。
2.创建模块
在models.py中定义了create_modules函数用来创建各个模块,该函数会根据cfg文件中对各个层的参数定义生成对应的层加入module_list。
值得一提的是,cfg中的route层是concatenate级联操作层,对于级联和shortcut操作,代码中使用的是创建一个空操作层:
def create_modules(module_defs):
"""此处省略部分代码"""
elif module_def["type"] == "route":
layers = [int(x) for x in module_def["layers"].split(",")]
filters = sum([output_filters[1:][i] for i in layers])
modules.add_module(f"route_{module_i}", EmptyLayer())
elif module_def["type"] == "shortcut":
filters = output_filters[1:][int(module_def["from"])]
modules.add_module(f"shortcut_{module_i}", EmptyLayer())
"""此处省略部分代码"""
class EmptyLayer(nn.Module):
"""Placeholder for 'route' and 'shortcut' layers"""
def __init__(self):
super(EmptyLayer, self).__init__()
相应的操作在后续Darknet类的forward中进行:
class Darknet(nn.Module):
"""此处省略部分代码"""
def forward(self, x, targets=None):
"""此处省略部分代码"""
elif module_def["type"] == "route":
x = torch.cat([layer_outputs[int(layer_i)] for layer_i in module_def["layers"].split(",")], 1)
elif module_def["type"] == "shortcut":
layer_i = int(module_def["from"])
x = layer_outputs[-1] + layer_outputs[layer_i]
"""此处省略部分代码"""
3.YOLO层
YOLO层应该是整个框架的精髓部分,网络的最终输出和loss的计算都将在这一层中完成。YOLO层初始化时需要三个anchors的大小、class的数量以及图片的尺寸。废话不多说,直接上代码。
class YOLOLayer(nn.Module):
"""Detection layer"""
def __init__(self, anchors, num_classes, img_dim=416):
super(YOLOLayer, self).__init__()
self.anchors = anchors
self.num_anchors = len(anchors)
self.num_classes = num_classes
self.ignore_thres = 0.5
self.mse_loss = nn.MSELoss()
self.bce_loss = nn.BCELoss()
self.obj_scale = 1
self.noobj_scale = 100
self.metrics = {
}
self.img_dim = img_dim
self.grid_size = 0 # grid size
其中mse_loss和bce_loss用来计算输出和targets之间的loss
在YOLO层的forward中,输入进来的第三个维度为3x(5+classes)的特征图会增加一个维度,可以理解为分成三个部分,每个部分对应一个尺寸的anchor:
prediction = (
x.view(num_samples, self.num_anchors, self.num_classes + 5, grid_size, grid_size)
.permute(0, 1, 3, 4, 2).contiguous()
)
以13x13x75的特征图为例(博主使用的是voc的数据集,所以class只有20种),feature map被“划分”为3个13x13x25的tensor,对于第三个维度,0位置代表对x相对于grid原点坐标的预测,1位置代表对y相对于grid原点坐标的预测,2位置代表对目标Width和anchor的Width偏移量的预测,3位置代表对目标Height和anchor的Height偏移量的预测,5~25位置代表对20个class的预测。代码如下:
x = torch.sigmoid(prediction[..., 0]) # Center x
y = torch.sigmoid(prediction[..., 1]) # Center y
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
然后再将预测的x和y加上grid的x和y,anchor的w和h乘上预测的偏移量,就得到了最终预测的pred_boxes,:
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x.data + self.grid_x
pred_boxes[..., 1] = y.data + self.grid_y
pred_boxes[..., 2] = torch.exp(w.data) * self.anchor_w
pred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h
再resize一下并拼接起来,将每个grid的输出依次排列,最终得到1x507x25的输出tensor,507为13x13x3,其他尺寸的feature map类似,方便后续的计算处理:
output = torch.cat(
(
pred_boxes.view(num_samples, -1, 4) * self.stride,
pred_conf.view(num_samples, -1, 1),
pred_cls.view(num_samples, -1, self.num_classes),
),
-1,
)
如果target为None,即没有标签信息,这时就会直接返回output,否则就会计算loss。在计算loss之前需要对labels进行预处理,将原始的目标种类和box信息转化为可以计算loss的形式
首先先创建和YOLO层输出大小相同的tensor来存储label的信息,这里的obj_mask和noobj_mask是用来在计算loss时进行掩膜处理,因为loss的设计中,对于有目标和没有目标的grid在计算loss时的处理是不同的:
def build_targets(pred_boxes, pred_cls, target, anchors, ignore_thres):
BoolTensor = torch.cuda.BoolTensor if pred_boxes.is_cuda else torch.BoolTensor
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda else torch.FloatTensor
nB = pred_boxes.size(0)
nA = pred_boxes.size(1)
nC = pred_cls.size(-1)
nG = pred_boxes.size(2)
# Output tensors
obj_mask = BoolTensor(nB, nA, nG, nG).fill_(0)
noobj_mask = BoolTensor(nB, nA, nG, nG).fill_(1)
class_mask = FloatTensor(nB, nA, nG, nG).fill_(0)
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0)
tx = FloatTensor(nB, nA, nG, nG).fill_(0)
ty = FloatTensor(nB, nA, nG, nG).fill_(0)
tw = FloatTensor(nB, nA, nG, nG).fill_(0)
th = FloatTensor(nB, nA, nG, nG).fill_(0)
tcls = FloatTensor(nB, nA, nG, nG, nC).fill_(0)
之后就是将label中的信息放入对应的位置,这里需要说明,由于一共有3个anchors,所以需要先计算label中的框和哪一个anchor的iou最大,只将最大的那个anchor对应的tensor的相应位置写入坐标和class信息:
# Convert to position relative to box
target_boxes = target[:, 2:6] * nG
gxy = target_boxes[:, :2]
gwh = target_boxes[:, 2:]
# Get anchors with best iou
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors])
best_ious, best_n = ious.max(0)
# Separate target values
b, target_labels = target[:, :2].long().t()
gx, gy = gxy.t()
gw, gh = gwh.t()
gi, gj = gxy.long().t()
# Set masks
obj_mask[b, best_n, gj, gi] = 1
noobj_mask[b, best_n, gj, gi] = 0
# Set noobj mask to zero where iou exceeds ignore threshold
for i, anchor_ious in enumerate(ious.t()):
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0
# Coordinates
tx[b, best_n, gj, gi] = gx - gx.floor()
ty[b, best_n, gj, gi] = gy - gy.floor()
# Width and height
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
# One-hot encoding of label
tcls[b, best_n, gj, gi, target_labels] = 1
# Compute label correctness and iou at best anchor
class_mask[b, best_n, gj, gi] = (pred_cls[b, best_n, gj, gi].argmax(-1) == target_labels).float()
iou_scores[b, best_n, gj, gi] = bbox_iou(pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False)
tconf = obj_mask.float()
return iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf
最后的class_mask和iou_scores是用于计算评价指标,在计算loss的部分并不会使用到。
在得到label的信息之后就可以开始计算loss了,对与x、y、w、h、class的loss只计算有obj的部分,而conf的loss计算是将obj_loss和noobj_loss乘上权重之后相加。x、y、w、h使用的是mse均方误差,conf和class使用的是bce二值交叉熵误差:
iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf = build_targets(
pred_boxes=pred_boxes,
pred_cls=pred_cls,
target=targets,
anchors=self.scaled_anchors,
ignore_thres=self.ignore_thres,
)
# Loss : Mask outputs to ignore non-existing objects (except with conf. loss)
loss_x = self.mse_loss(x[obj_mask], tx[obj_mask])
loss_y = self.mse_loss(y[obj_mask], ty[obj_mask])
loss_w = self.mse_loss(w[obj_mask], tw[obj_mask])
loss_h = self.mse_loss(h[obj_mask], th[obj_mask])
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask])
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls
4.Darknet类
至此YOLO层就构建完毕了,之后就是封装一个Darknet类,来读取cfg文件和调用create_modules函数搭建网络框架,并定义forward的函数对输入进行处理:
class Darknet(nn.Module):
"""YOLOv3 object detection model"""
def __init__(self, config_path, img_size=416):
super(Darknet, self).__init__()
self.module_defs = parse_model_config(config_path)
self.hyperparams, self.module_list = create_modules(self.module_defs)
self.yolo_layers = [layer[0] for layer in self.module_list if isinstance(layer[0], YOLOLayer)]
self.img_size = img_size
self.seen = 0
self.header_info = np.array([0, 0, 0, self.seen, 0], dtype=np.int32)
def forward(self, x, targets=None):
img_dim = x.shape[2]
loss = 0
layer_outputs, yolo_outputs = [], []
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
if module_def["type"] in ["convolutional", "upsample", "maxpool"]:
x = module(x)
elif module_def["type"] == "route":
x = torch.cat([layer_outputs[int(layer_i)] for layer_i in module_def["layers"].split(",")], 1)
elif module_def["type"] == "shortcut":
layer_i = int(module_def["from"])
x = layer_outputs[-1] + layer_outputs[layer_i]
elif module_def["type"] == "yolo":
x, layer_loss = module[0](x, targets, img_dim)
loss += layer_loss
yolo_outputs.append(x)
layer_outputs.append(x)
yolo_outputs = to_cpu(torch.cat(yolo_outputs, 1))
return yolo_outputs if targets is None else (loss, yolo_outputs)
三、训练部分
训练数据已经封装好了,网络搭建完毕,损失函数也已经定义好了。剩下的训练部分就是一些常规操作,这里只附上一些代码,不多做说明:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Darknet(opt.model_def).to(device)
# Get dataloader
dataset = ListDataset(train_path, multiscale=True, transform=AUGMENTATION_TRANSFORMS)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=8,
pin_memory=True,
collate_fn=dataset.collate_fn,
)
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(opt.epochs):
model.train()
for batch_i, (_, imgs, targets) in enumerate(tqdm.tqdm(dataloader, desc=f"Training Epoch {epoch}")):
batches_done = len(dataloader) * epoch + batch_i
loss, outputs = model(imgs, targets)
loss.backward()
if batches_done % opt.gradient_accumulations == 0:
# Accumulates gradient before each step
optimizer.step()
optimizer.zero_grad()
总结
至此,YOLOv3的训练部分的实现方式就大致介绍完毕了。通过源码我们可以明显感觉到YOLO系列的“简单粗暴”,通过回归的方式直接预测了目标的所有信息,在这种简洁有效的网络背后是作者大大满满的心血。而且对于YOLO作者给出了非常简单的复现方式,可以轻松在工程实践中落地,这是非常难得的。
You Only Look Once