单目3D多人姿态估计网络(整合自上而下和自下而上网络)
Monocular 3D Multi-Person Pose Estimation by Intergrating Top-Down and Bottom-Up Networks 论文解读
- 贡献
- 实验结果
- 整体框架
- 3D多人姿态估计相关工作
- Network Structure
-
- GCN Structure
- TCN Structure
- Illustration of the heatmaps estimated from the bottom-up network
- Details of Semi-Supervised Learning
- Top-Down Network
- Bottom-Up Network
- Integration with Interaction-Aware Discriminator
- Inter-Person Discriminator
- 实验细节
- 消融术研究
这篇文章发表在CVPR2021,目前官方还没有开源,作者提供的github网站为 https://github.com/3dpose/3D-Multi-Person-Pose
贡献
1、本文引入了一种新的双分支框架,其中自上而下的分支检测多个人,而自下而上的分支在其过程中包含了标准化的图像补丁。其框架从这两个分支中获益,同时也克服了它们的缺点。
2、本文的下扑网络采用多人姿态估计,可以有效地处理检测误差引起的人间遮挡和相互作用。
3、本文将人类检测信息纳入自下而上的分支,以便更好地处理尺度变化,从而解决了现有的自下而上方法中的问题。
4、与现有的关注单人姿态的鉴别器不同,本文引入了一种新的鉴别器,它增强了在相机中心坐标中紧密成两交互的人类姿态的有效性。
实验结果
先来看一下本文提出的双分支整合方法的表现:

为了评估室内和室外场景中三维多人摄像机姿态估计的性能,本文对MupoTS-3D进行了评估,如表3所示。结果表明,本文以相机为中心的多人三维姿态估计比SOTA[1]上的性能好2.3%。本文还使用PCK进行以人为中心的三维姿态估计评估,其中本文比SOTA方法[2]高出了2.1%。对MupotS-3D的评估表明,本文的方法在以相机为中心和以人为中心的三维多人姿态估计方面都优于最先进的方法,因为本文提出的框架克服了自下自上和自上而下分支的弱点,同时受益于它们的优势。
[1] Jiefeng Li, Can Wang, Wentao Liu, Chen Qian, and Cewu Lu. Hmor: Hierarchical multi-person ordinal relations for monocular multi-person 3d pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), 2020.
[2] Jiahao Lin and Gim Hee Lee. Hdnet: Human depth estimation for multi-person camera-space localization. In Proceedings of the European Conference on Computer Vision (ECCV), 2020.

Human3.6M被广泛用于评估三维单人姿态估计。由于本文的方法侧重于处理人间遮挡和尺度变化,不期望本文的方法的性能明显好于SOTA方法。表5总结了对Human3.6M的定量评估,其中本文的方法与SOTA方法[1, 3]对以人为中心的三维人体姿态评估指标(即MPJPE和PA-MPJPE)相当。
[3] Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop. In Proceedings of the
IEEE International Conference on Computer Vision, pages 2252–2261, 2019.
整体框架

上图描述:如图中所示,本文提出的框架由三个主要部分来完成以多人摄像机为中心的三维人体姿态估计:自上而下的精细实例姿态估计网络,自下自上的全局感知姿态估计网络,以及将自上自下和自下而上分支的姿态估计与人机间姿态识别器集成的集成网络。此外,还提出了一种半监督训练过程来增强基于重投影一致性的三维位姿估计。
本文提出的方法包括三个组成部分:1) 一个自上而下的分支来估计细粒度的实例式三维姿态。2) 自下而上的分支,可生成全球感知以相机为中心的三维姿势。3) 一种集成网络,基于自上而下和自下而上的配对姿势生成最终估计,从而从两个分支中获益。
请注意,半监督学习部分是一种训练策略,因此它不包含在本图中。
后面将详细讲述Top-Down、Bottom-Up、Integration with Interaction-Aware Discriminator这三个部分。
3D多人姿态估计相关工作
- Top-Down Network
自上而下的单目三维人体姿态估计 (Top-Down Monocular 3D Human Pose Estimation)
现有的自上而下的三维人体姿态估计方法通常将人体检测作为估计以人为中心的三维人体姿态的方法的重要组成部分。它们在单人评估数据集上展示了良好的性能,不幸的是,由于人间封闭或密切交互,多人场景中的性能会下降。此外,所产生的以人为中心的三维姿态不能用于多人场景,其中需要以相机为中心的三维姿态估计。自上而下的方法独立处理每个人,导致人们对附近其他人存在的认识不足。因此,他们在通常存在人间遮挡和密切互动的多人视频中表现不佳。Rogez等人,开发了一个姿态建议网络来生成边界框,然后为每个人单独进行姿态估计。最近,与以前以人为中心进行姿态估计的方法不同,Moon等人,提出了一种自上而下的三维多人姿态估计方法,该方法可以在相机中心坐标下估计图像中所有人的姿势。然而,该方法仍然依赖于检测和独立处理每个人;因此,它很可能遭受人间的闭塞和密切的相互作用。 - Bottom-Up Network
自下而上的单目三维人体姿态估计(Bottom-Up Monocular 3D Human Pose Estimation)
现有一些自下而向上的方法被提出。Fabbri等人,引入了一个编码器-解码器框架,首先压缩热图,然后在测试时间将其解压缩回原始表示以快速高清图像处理。Mehta等人,建议识别单个关节,组成全身关节,并在三个阶段执行时间和运动学约束,以实现实时三维运动捕捉。Li等人,开发了一种计算复杂度较低的综合方法,用于人体检测、以人为中心的姿态估计和来自输入图像的人体深度估计。Lin等人,将人的深度回归表示为照相机坐标系中多人定位的垃圾桶指数估计问题。Zhen等人,首先估计身体部位的2.5维表示,然后重建以相机为中心的多人三维姿势。这些方法受益于自下而上的方法的性质,它可以同时处理多个人,而不依赖于人类的检测。然而,由于所有的人都以相同的规模进行处理,这些方法不可避免地对人类的规模的变化很敏感,这限制了它们在野生视频上的适用性。 - Integration with Interaction-Aware Discriminator
自上而向下和自下而向上的组合(Top-Down and Bottom-Up Combination)
早期探索自下扑和自下而上的人姿态估计方法的非深度学习方法的形式是数据驱动的信念传播、联合位置和骨架的不同分类器,或概率高斯混合建模。最近基于深度学习的方法试图利用自上向下和自下而上的信息,主要是关于估计二维姿态。Hu and Ramanan提出了一种分层修正的高斯模型,将自上自下的反馈与自下而上的cnn相结合。Tang等人,开发了一个具有自下而上推理的框架,然后基于人体的组合模型进行自上而向下的细化。Cai等人,引入了一种同时使用自下而积和自上而下特征的时空图卷积网络(GCN)。对这些方法进行探索,以受益于自上而下和自下而上的信息。然而,它们不适合三维多人姿态估计,因为自下向下和自下而上方法的基本弱点都没有完全解决,包括人间遮挡引起的检测和关节组合错误,以及尺度变化问题。Li等人,采用LSTM,将自下而上的热图与人体检测相结合,进行二维多人姿态估计。它们解决了被遮挡和检测移位的问题。不幸的是,他们使用一个自下而上的网络,并且只添加检测边界框作为自上而向下的信息来分组关节。因此,他们的方法基本上仍然是自下而上的,因此仍然容易受到人类规模变化的影响。
Network Structure
GCN Structure
- 与现有的使用无向图的GCN方法不同,本文使用有向图。使用有向图的优点是,具有较高可信度的更可靠的节点能够影响具有非对称邻接矩阵的低可信度的不可靠节点。我们采用如下的GCN方法。
这些特征根据GCNs中的相邻矩阵进行传播,这意味着传播图中的边缘值。给定二维姿态估计器的热图H,我们选择图中最高值的位置作为每个关节图中的顶点,邻接矩阵由以下方程式组成:
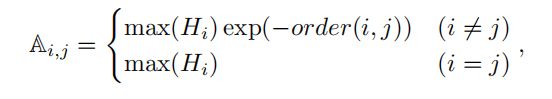
其中,Ai,j 是从顶点i到顶点j的向外的权重。max(Hi) 代表 i-th 关节的置信度。阶 (i, j) 是从顶点 i 到达顶点 j 所需的最小跳数。这种邻接的形成使对近顶点的权重更大,而对远顶点的权重更小。
TCN Structure
- 本文的GCN可以在遮挡或缺失信息下完成姿势,但由于缺乏时间平滑性而产生令人不安的结果。以往对时间卷积网络(TCN)的研究表明,TCN在限制预测的三维姿态的时间平滑性方面的有效性。我们采用了TCN结构。如下图所示,本文分别利用两个TCNs来估计以人为中心的三维姿态(即关节)和以相机为中心的根关节的深度。本文将这两个TCN命名为:Joint-TCN 和 Root-TCN。

上图描述:本文的TCN包括一个用于相对姿态估计的联合TCN和一个用于以相机为中心的根深度估计的根TCN。- Joint-TCN 以GCN生成的三维姿势序列作为输入,并通过考虑时间信息来输出精确的以人为中心的三维姿势。估计姿态PTCN与其地面真相P˜之间的损失为L2,公式为:
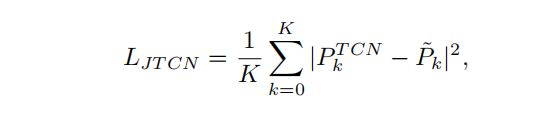
其中,K是关节的数量 - Root-TCN 以GCN生成的三维姿态序列和姿态估计器生成的二维姿态序列作为输入,并输出估计的以相机为中心的根深度。本文没有直接估计凸轮中心的深度Z,而是估计了归一化的根深度,即基于焦距f的RTCN=Zf,以避免照相机固有参数的影响。损失函数介于估计RTCN与其地面真实值R˜之间:
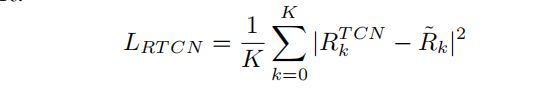
其中,K是关节的数量;基于等式提供的以个人为中心的三维姿势和来自等式的根缝深度,得到了以相机为中心的三维姿态。
- Joint-TCN 以GCN生成的三维姿势序列作为输入,并通过考虑时间信息来输出精确的以人为中心的三维姿势。估计姿态PTCN与其地面真相P˜之间的损失为L2,公式为:
Illustration of the heatmaps estimated from the bottom-up network
如下图所示,说明了由本文使用的自下而上的网络估计的四个热图输出的一个示例。左上角是一个输入图像。顶部中间是一个关节图,它显示了关节的热图,其中所有通道合并在一起,以便更好地可视化所有关节。右上角是估计的三维姿势。左下角显示了ID标签分布。中间是根深度图,红色代表一个人比其他人更远。右下角是相对于骨盆关节的相对深度映射的一个例子,其中以左臂深度为例。与他的骨盆相比,左人的手臂距离相机更远(红色),而右人的骨盆更靠近相机(蓝色)。

从自下而上分支估计热图的可视化
Details of Semi-Supervised Learning
本文的半监督学习(SSL)管道如图所示。首先,使用训练好的模型来生成无标签数据的伪标签,这是本文12个实验中的COCO数据集。注意,本文只使用了图像,而不是关节的二维地面来模拟未标记的数据场景。不幸的是,伪标签不能直接使用,因为其中一些标签是不正确的。因此,本文使用了两个一致性项来测量所有伪标签的质量:本文中提到的重投影误差和多透视误差。
由于二维数据集的姿态变化比三维数据集的姿态变化更丰富,例如。与H36M相比,COCO在不同的环境和姿态方面,估计的2D姿态比估计的三维姿态更健壮。现有的重投影误差测量生成的三维姿态与检测到的二维姿态之间的偏差。与此不同的是,本文利用二维姿态热图中关节的置信度作为权重,自适应地调整重新投影的三维姿态,以匹配基于关节的置信度的估计的二维姿态。
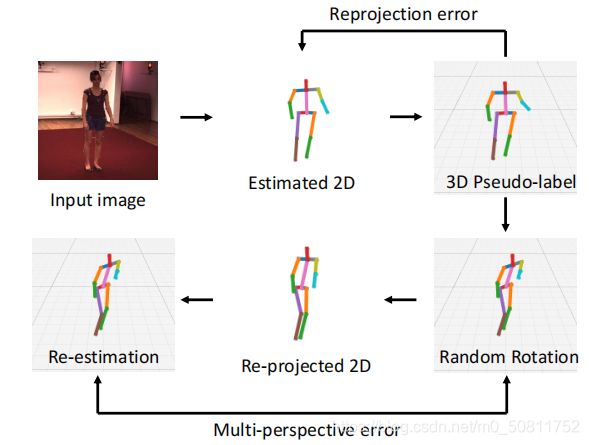
上图描述:SSL旨在保持两种一致性:重新投影和多视角。
Top-Down Network
给定一个人体检测边界框,现有的下扑方法估计一个人的全身关节。因此,如果盒子内或有多个人的部分边界外的身体部位,全身关节估计很可能是错误的。下图显示了现有方法的故障示例。相比之下,本文的方法可以为边界框内部的所有关节生成热图(即,放大以适应不准确的检测)并估计每个关节的标识,以将其分成相应的人员。

上图描述:估计的人类关节热图的例子。左图显示的输入帧上覆盖有不准确的检测边界框(即仅检测到一个人)。中间的图显示了现有的自上而下方法的估计热图。右边的图像显示了本文自上而下的分支的热图。
给定一个输入视频,对于每一帧,我们都应用一个人类检测器,并根据检测到的边界框裁剪图像补丁。对每个贴片应用二维姿态检测器,为所有人体关节,如肩膀、骨盆、踝关节等生成热图。具体地说,我们的二维姿态热图的下顶损失是预测热和地真热图之间的L2损失,公式为:

其中H和H˜分别是预测的和地面真值热图。
获得二维姿态热图后,定向GCN网络用于细化由遮挡或部分边界框体部分引起的潜在不完整姿态,并使用两个TCN基于给定的二维姿态序列类似于估计以个人为中心的三维姿态和以相机为中心的根深度。由于TCN需要同一实例的输入序列,因此将使用姿态跟踪器来跟踪输入视频中的每个实例。本文还在训练中应用数据增强训练TCN,以便它可以处理闭塞。
Bottom-Up Network
自上而下的方法在边界框内进行估计,因此缺乏对他人的全局认识,导致难以估计以相机为中心的坐标中的姿势。为了解决这个问题,本文进一步提出了一个自下而向上的网络,同时处理多个人。由于自下向上的姿态估计存在人类尺度的变化,本文将自上而下网络的热图与原始输入框架作为自下而上网络的输入。在自上而下的热图是目标探测器的结果和基于归一化盒的姿态估计的指导下,自下而上的网络的估计对尺度变化具有更强的鲁棒性。本文的自下而上的网络输出四个热图:一个二维姿态热图、ID标签图、相对深度图和根深度图。二维姿态热图和ID标签图的定义方式与上一节中的定义方式相同。相对深度图是指每个关节相对于其根(骨盆)关节的深度图。根深度图表示根关节的深度图。
特别是,本文将深度损失应用于相对深度图h根和根深度h根的估计。请参见补充材料,例如来自自下而上网络的四个估计热图。对于N个人和K个接头,损失可表述为:
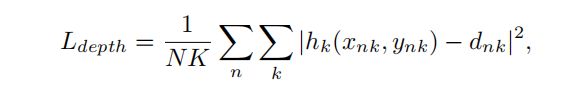
其中h是深度图,d是地面真值的深度值。请注意,对于骨盆(即根关节),深度是以相机为中心的深度。对于其他接头,深度相对于对应的根接头是相对的。
本文将热图分组为实例(即人员),并使用与在自上而下的网络中相同的程序来检索联合位置。此外,通过检索关节(即根或其他关节)所在的相应深度图,可以获得根关节z根的凸轮心深度和其他关节的相对深度。具体是:

其中,i,k 分别指ith实例和 k-th 关节。
Integration with Interaction-Aware Discriminator
在得到自上而下和自下而上网络的结果后,首先需要找到两个网络结果之间的对应姿势,即自上而下姿势和自下而上姿势属于同一个人。请注意,在本文中,P代表以相机为中心的三维姿势。
给定来自自下而上分支PBU和自上而下分支PTD的两个姿态集,我们匹配来自这两个集合的姿势,以形成姿势对。两种姿势的相似性定义为:
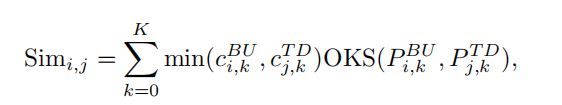
其中,
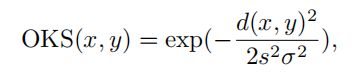
OKS表示对象关键点相似度,它度量给定联合对的联合相似度。d(x,y) 是两个接头之间的欧几里得距离。s和σ是两个控制参数。Sim i,j 测量了自下而上网络的ith3D姿态PiBU与自上而下网络的 j-th 三维姿态PjTD之间的相似性。请注意,来自自上而下的 PTD 和自下而上的 PBU 的姿势都是以相机为中心的;因此,相似度是基于相机坐标系来测量的。cBUi、k和cTDj、k分别是三维姿态PiBU和PjTD的联合k的置信值。根据Sim i,j 的定义计算了两组姿态PTD和PBU之间的相似性矩阵,利用匈牙利算法得到了匹配结果。
一旦得到了匹配的对,就将每对三维姿势和每个关节的置信度提供给我们的积分网络。本文的集成网络由3个全连通的层组成,它们输出了最终的估计。
Inter-Person Discriminator
为了训练集成网络,本文提出了一种新的人间鉴别器。不像大多数现有的关于人体姿态估计的鉴别器。当他们只能区分一个人的三维姿态时,本文提出了一个交互感知鉴别器来强制姿态对的交互是自然和合理的,它不仅包括现有的单人鉴别器,而且还推广到相互作用的人。具体地说,本文提出的鉴别器包含两个子网络:D1,专门用于一个以人为中心的3D姿势;还有,D2,专门用于两个人的一对以相机为中心的3D姿势。
实验细节
- Multi-Person Pose Estimator
- 我们的多人姿态估计器使用HRNet-w32作为骨干,并在MuCO和COCO数据集的组合上进行训练。我们复制了两次COCO数据集,以平衡两个数据集之间的训练数据。网络由 Adam 优化器训练,学习率从0.001开始,在epoch 30和40时减少至1/10。该网络被训练了50个epochs,使用8x RTX Quadro 8000 GPUs进行训练需要35个小时。
- GCN and TCNs
- 本文的GCN和TCNs是基于从多人姿态估计器中预先提取的热图来训练的。本文用 Adam 优化器来训练网络,学习率从0.001开始,并每40个epochs减少至1/10。这些网络经过了100个epochs的训练,使用单个RTX 2080Ti GPU进行训练需要25个小时。本文使用增强功能来训练网络以更好地处理遮挡。
- Bottom-Up Network
- 本文的自下而上的网络是基于MuCO和COCO数据集的结合来训练的。为了平衡训练样本的数量,本文复制了两次COCO数据集,并与MuCO数据集结合。自下向上的网络由 Adam 优化器训练,学习率从0.001开始,在第30和第40个epoch降到1/10。该网络被训练了50个epochs,使用8个 8x RTX Quadro 8000 GPUs.进行训练需要65个小时。
- Integration Network
- 本文的集成网络包含5层完全连接,层大小为512。网络一开始用 Adam 优化器训练,学习率为0.001,并每50个epochs减少到1/10。网络经过150次训练,单个RTX 2080Ti GPU进行训练需要3.5小时。本文主要讨论了数据增强的过程。为了清楚起见,在这里简要地解释:1) 本文使用随机掩蔽来模拟遮挡,其中被遮挡的关节被掩盖到(0,0)。2) 本文应用基于高斯随机的关节随机位移方法来模拟不准确的位姿估计。3) 本文随机将配对中的一个姿势设为零,以模拟未配对的姿势。
消融术研究
消融研究旨在验证本文的框架中的每个子模块的有效性。本文使用现有的自上而下的姿态估计器(即检测一个全身关节)作为基线来验证本文提出的自上而下的网络,缩写为TD(w/oMP),以与本文称为TD(wMP)的自上而下网络进行比较。本文还使用现有的自下而上的热图估计来验证自下而上的网络作为baseline,成为BU(w/o CH),以与本文自下而上的网络BU(wCH)进行比较。为了评估本文的集成网络,本文使用了三个基线。第一个是通过结合现有的TD和BU网络的直接集成。第二种是硬集成,缩写为TDBU(hard),其中总是使用自上而下的以人为中心的姿势,再加上来自自下而上的网络的根深度。第三种是线性积分,缩写为TDBU(linear),根据估计热图的置信值,将自上向下的三维姿态与相应的自下置上姿态相结合。
如下表所示,可以观察到本文的自上而下的网络、自下而上的网络和集成网络明显优于它们相应的基线。与自下而上的网络相比,本文的自上而下的网络往往有更好的以人为中心的三维姿态估计,因为自上而下的网络不仅受益于多人姿态估计器,还有助于处理遮挡姿势的GCN和TCN姿势。相反,本文的自下而上网络在根关节估计方面取得了更好的性能,因为它基于一个完整的图像来估计根深度;而自上而下网络的根深度是基于单个骨架来估计的。最后,与自上而下和自下而上网络的姿态组合相比,本文的集成网络显示了优越的性能,验证了其有效性。
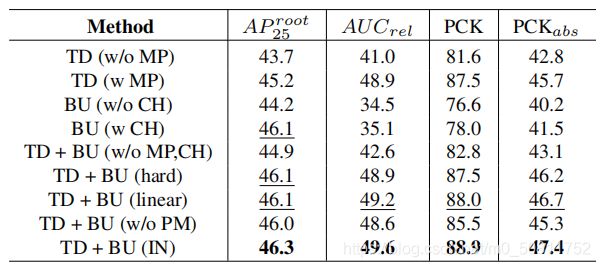
上图描述:对 MuPoTS-3D 数据集的消融研究。TD、BU、MP、CH、IN 和 PM 分别代表自上而下、自下而上、多人姿态估计器、组合热图、集成网络和姿态匹配。
除了验证本文的自上而下和自下而上的网络外,本文还对提出的半监督学习进行了消融分析。本文在下表中展示了使用鉴别器使用重投影损失、多透视损失、重投影损失,以及使用鉴别器使用重投影和多透视损失的结果。可以看到,重新投影损失比多透视损失更有用,因为它利用了来自二维姿态估计器的信息,这是用具有大量姿态和环境变化的二维数据集来训练的。更重要的是,可以观察到,与其他模块相比,本文提出的交互感知鉴别器进行了最大的性能改进,证明了加强人员之间交互的有效性的重要性。

上图描述:对 MuPoTS-3D 数据集的消融研究。Rep, MP和 dis 代表重新投影、多视角和鉴别器。
=====================================================================
最后还有一些定量定性分析就不阐述了,详细可以看论文。后面等作者代码开源后,再复现进行讨论。