2021/02/15 Kubernetes进阶实践
第1章 ETCD数据访问
1.1 k8s在etcd中数据的存储


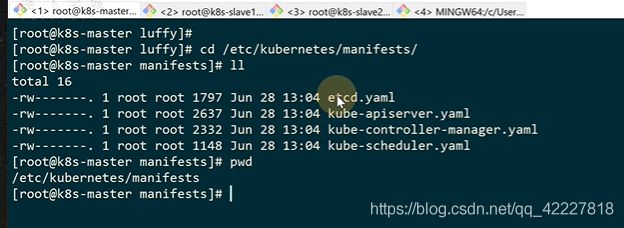
这个文件夹是静态文件,etcd是个静态pod,里面存储了K8S的所有数据

etcd是容器运行的

把etcdctl复制到宿主机

提示我们etcdctl环境变量没有设置,默认是v2版本
如果搭建高可用,etcd节点数和K8S的master的节点数是一致的

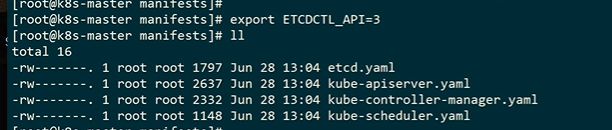
允许客户端去认证,下面是签发 的证书

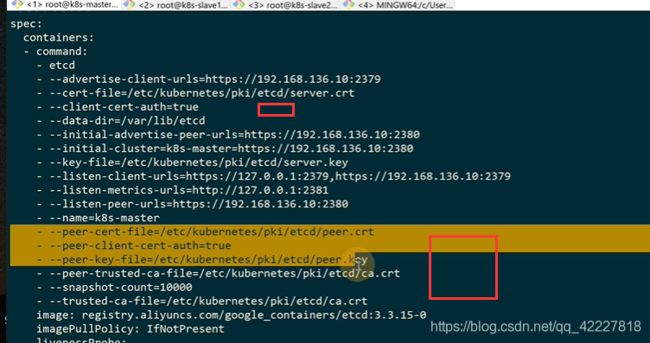
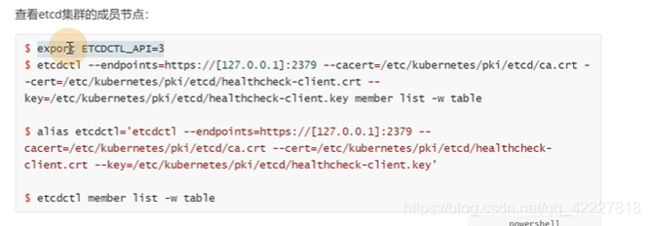
需要三个,一个是跟证书,一个是跟证书签发的私钥,公钥

后面才是真正查询的,成员列表,以表的方式展现

etcd默认监听端口是2379,2380是集群内部服务端去通信使用的端口

因为还需要加上 后面的证书,所以可以直接定义别名


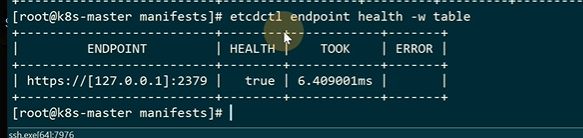
查看节点状态,endpoint是本机的端点,version etcd版本,db size整个数据库大小,现在是单点,如果是集群,db size应该是一样的,is leader是否是主,raft term raft选举的term元素,这个命令一般排错的时候使用

查看健康状态
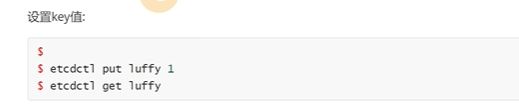
luffy这个key的值是
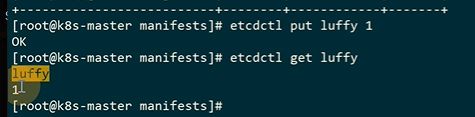
跟就是最上层的目录,–prefix显示前缀(绝对路径),–keys-only只显示key

跟下,全部放在 registry目录下

这里对应的是K8S资源类型

configmap

所有的都放在registry大目录里,子目录资源类型,下一级是名称空间,下一级具体对象名字

这样可以拿到数据

生产商要对etcd数据做快照

现在就保存下来了
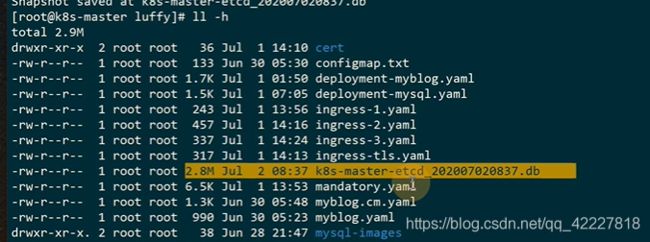
这个快照跟下面显示的大小一样

etcd崩了如何快速 恢复,保证机器ip没有改变,重启起来,哪怕机器重装了也没事,保证K8S集群,hostname和ip都没有改变。
证书也需要保存下来

如果是集群,每个节点都需要恢复

通常pod产生的事件是最占空间的,etcd也可以根据资源类型去查看数据量大小

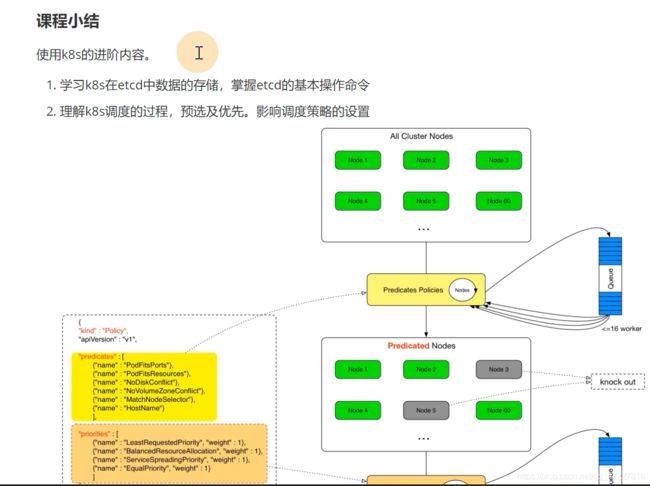
第2章 Kubernetes调度策略实践
2.1 k8s调度详解

调度算法和策略是两个东西,node中 的ku’belet通过apiserver监听scheduler产生的pod绑定事件获取pod信息,然后下载镜像

scheduler根据pod队列和node节点的调度算法,得出具体节点哪个最合适,放到etcd,kubelet监听后,发现自己被选中就进行pod任务
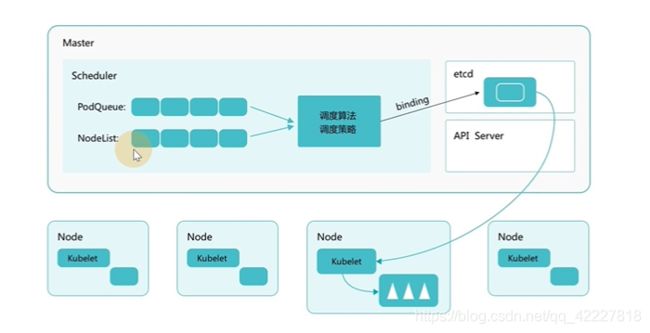
scheduler提供的调度流程 分别预选和优选,预选是筛选符合要求的,优选是给node打分,给得分最高的

假如要pod监听80端口,node节点上80被占用的就被淘汰了
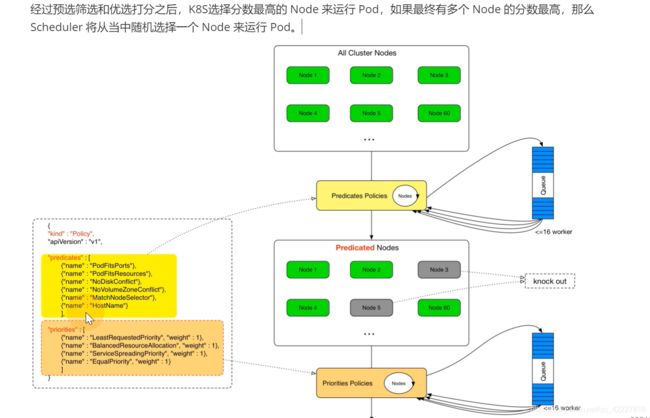
经过一系列策略预选
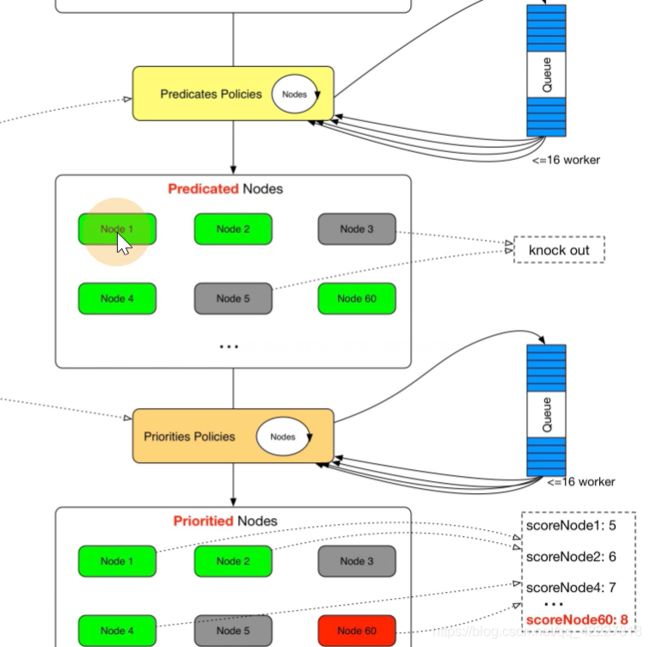
经过优选评分
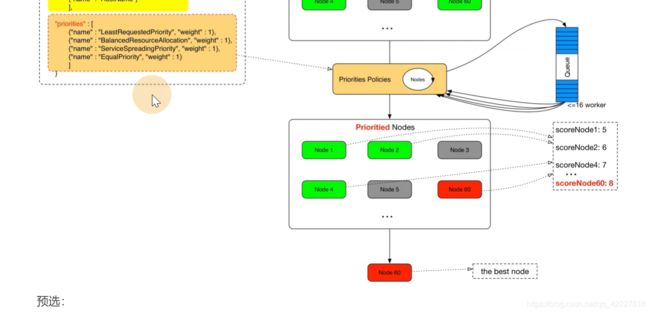
得到一系列的比分,就选择最优的节点
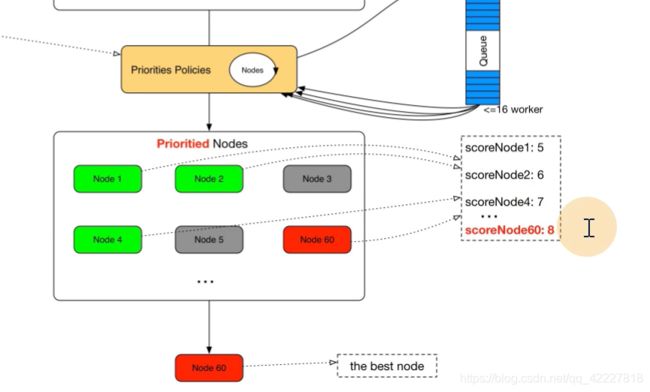
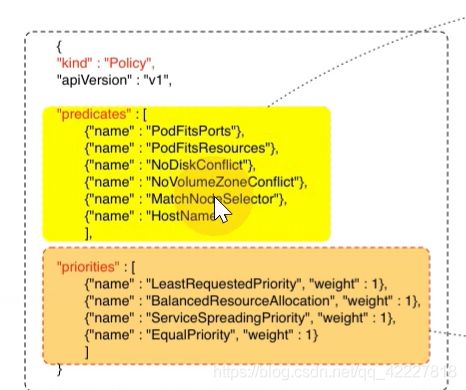
调度算法,预选的



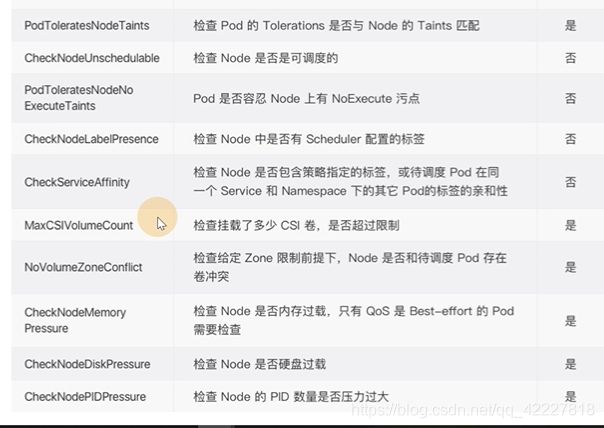
优选的
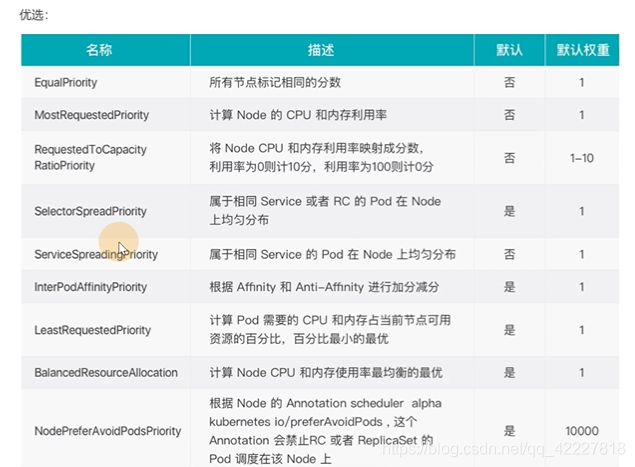

调度算法是根据调度策略的一种实现

cordon标记节点成为一个不可调度的状态
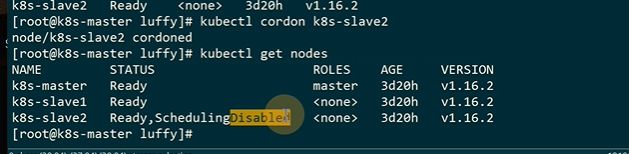
在标记之前的pod是不受影响的

drain是一个驱逐的动作

恢复调度


nodeselector虽然用起来打个标签就好,但是用起来比较有局限性
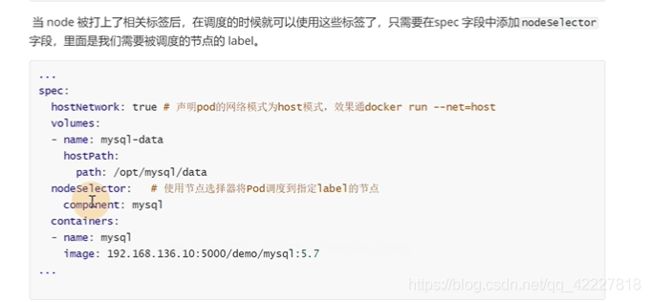
上面是硬策略(没有满足条件的节点,就不断重试调度),
下面是软策略,没有满足要求的节点,就会忽略掉这个规则

如果要满足下面的要求,不能运行在128和132可以是硬策略,但是后面的可以是软策略
![]()
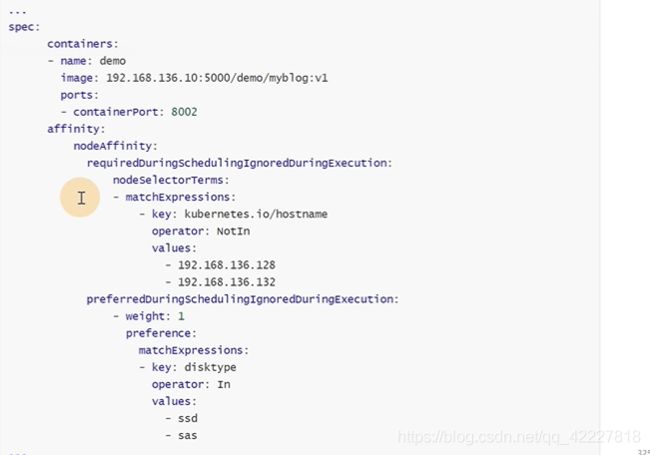
affinity和containers是同级的,因为是以pod为单位的

matchexpression是匹配条件,operator 不再,节点不在这两个里的

软策略,disktype这个key最好是ssd,sas
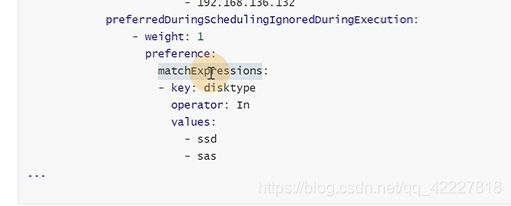

这里如果 match条件有多个,那么满足 其中一个就行,是或者的关系

如果A和B不想调度在一起,那么就可以设置

常用性功能,taints污点和容忍tolerations。
以node为中心打一个污点,阻止pod调度上去,除非能忍受

使用场景

K8S-master防止业务容器调度过来,会去默认加污点

effect是有什么影响,这个值不是自定义的是可选的,默认是不能容忍这个污点就不要调度过来

有节点可以调度,就尽量别过来
![]()
最强硬的,新的别过来,老的不管你
![]()
不能容忍SLVAE1的抽烟习惯,就别过来
![]()

减号代表删除的意思

带有这个key的污点全部删除

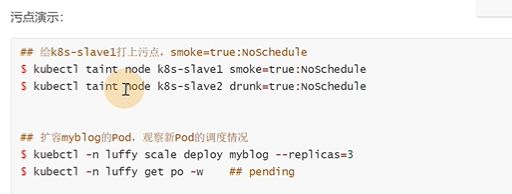
打上两个污点


扩容副本成三个
![]()
上面是一个 新启动的

用的是默认调度器,有三个节点都有污点,pod都不容忍,有哪位没有设置容忍

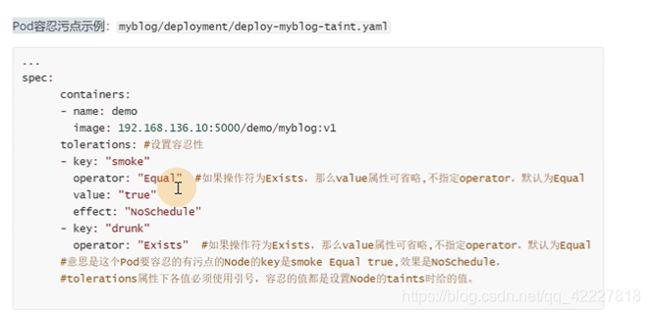
如果匹配到抽烟的污点,就不调度

esists存在drunk这污点,就包容了


 新启动了一个
新启动了一个

但是不想要上面知道具体的污点,就可以设置什么污点都可以接受
第3章 CNI网络的实现原理
3.1 CNI介绍及网络选型
集群内部是通过 pod ip通信的

kubeadm安装集群之后,需要安装cni,节点的状态才会ready
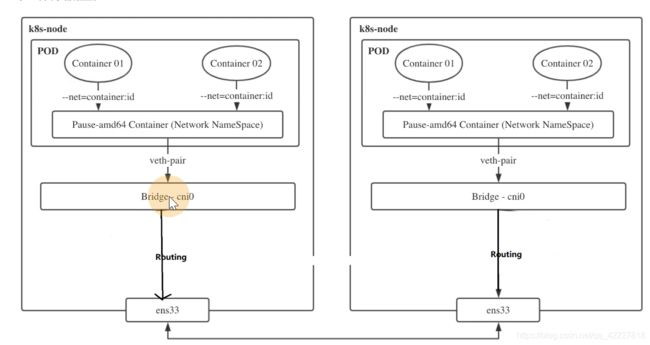
CNI其实是一个接口,有很多实现,不管哪种实现方式,都是去实现pod网络通信,CNI插件,去帮助容器配置网络。
还有一个删除,对应pod的删除
还有IPAM插件,网络地址管理,负责给容器分配ip地址。
现在用的比较多的flannel(范围比较款南宋,K8S集群的3层网络可达,就可以用flannel)和calico
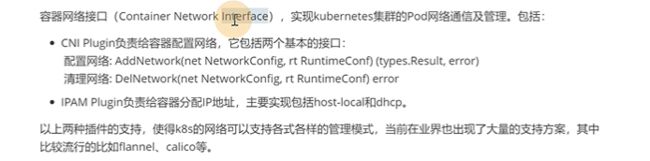
kubelet每次启动pod都会启动一个pause的基础设施相关容器,pause容器去生成network namespace。
调用cni driver,执行文件目录是/opt/cni/bin

这边插件实现是用flannel

调用具体的cni插件也就是flannel,
![]()
这些其实就是和K8S网络相关的一些插件,这些都是不同的cni的实现,kubelet会去调用

调用cni插件后,会给容器配置正确的网络,pod网络空间就一个pause,其他的业务容器,init初始化容器都是会去调用join,不会去创建新的网络空间
![]()
cni的一个仓库



3.2 vxlan介绍及点对点通信的实现
flannel的网络实现,是如何去实现跨节点网络通信
udp涉及到一个用户态和内核态流量的切换,效率低
type是vxlan

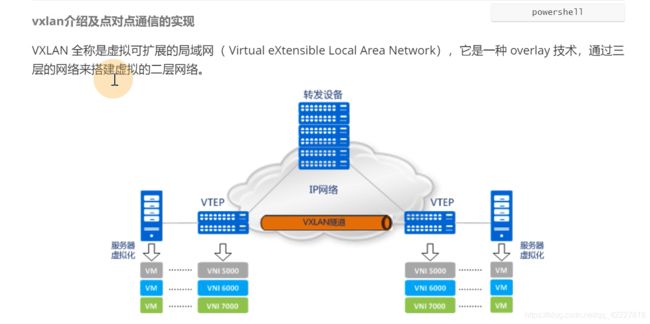
vxlan是虚拟的可扩展的局域网,通过三层的网络来搭建虚拟的二层网络。
没有vxlan技术,之前是这么访问的
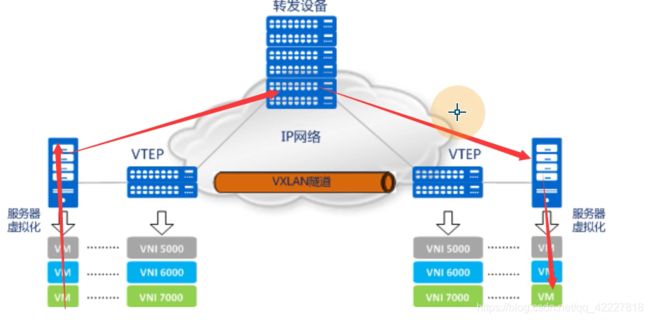
有了vxlan,流量是连接到vtep设备上去,再去走ip网络,再到vtep设备,再转到具体服务器,有一个vxlan隧道,让原来基于ip访问的虚拟机,可以通过隧道去实现一个二层通信

vxlan核心的概念,vtep vxlan的隧道端点,用来处理vxlan的报文处理,vtep可以是网络设备也可以是交换机。

vni可以理解为vxlan的id,每一个vni的号都可以对应一个租户,公有云现在抛弃vlan,vlan的限制只能有12位,vxlan有2的24次方,vxlan可以支持千万级的用户

vxlan网络由唯一的vni标识,不同调度vxlan是不相互影响的
slave1和slave2物理网卡分别是11和12,现在要把slave1利用vxlan技术当作一个vtep设备,这两个中间建立隧道
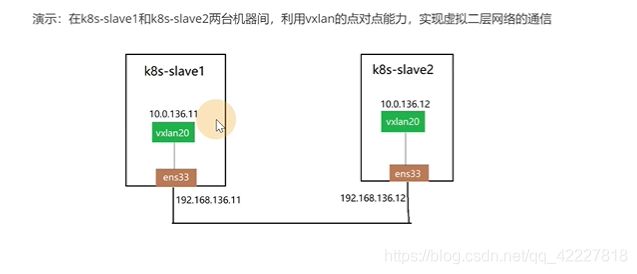
后两位一致其实就是为了方便 找到宿主机

那么vxlan是如何实现的

创建vtep设备,type 是vxlan是内核支持的
id 20 就是vni的id号是20
remote 因为是点对点的,可以在vtep的设备上告诉端点的另一端,所以remote的地址一定是slave2的地址
dstport监听端口是4789,默认端口,为了抓包分析更方便点
dev物理设备 ens33


已经有一个vxlan20的设备


加上IP

同样在slave2做同样的操作

slave2节点应该指向slave1

能ping通
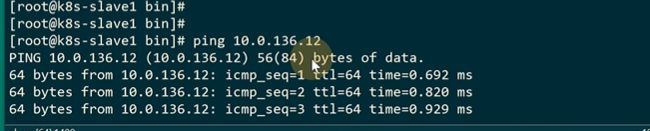
现在给slave1和2分别设置了端点,他们两个就可以直接通信了

等于这两个机器中间实现了一个vxlan的tunnel,也就是在外层的ip网络之上,创建了一个2层的网络,因为都是136端的属于一个2层的网络,可以实现跨机房的通信,所以说是实现了大2层的网络

vxlan的双方都是认为是在直接通信

3.3 tcpdump分析vxlan数据包
虚拟机的报文通过vtep设备转发,会进行一个封装,封装以后发送到另一端,会在对方的vtep拆除这个头,然后根据vni转发到具体机器上

因为没有物理联通,肯定还是依赖物理的三层通信
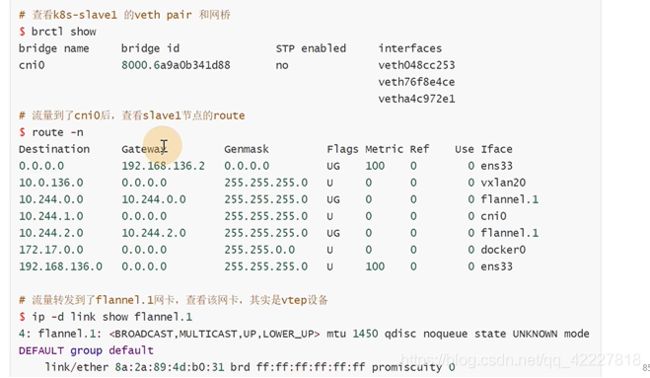
可以查看路由表,用这个vtep设备vxlan20去转发

这里其实知道对端的地址

slave2上也有路由表
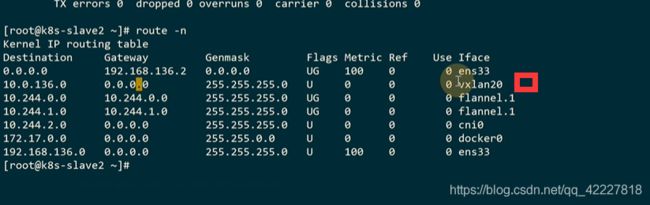

只要流量过来就添加报文转发到192.168.136.12这个机器上

抓取ens33物理网卡的包,host 192.168.136.11源地址机器,-w 保存
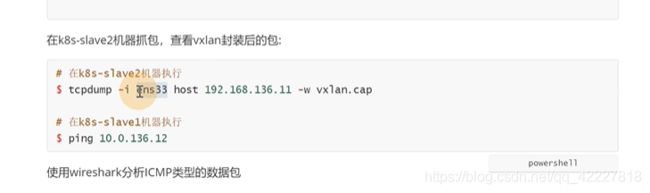

在slave1上去ping

拷贝到宿主机上去分析
用wireshark分析一下
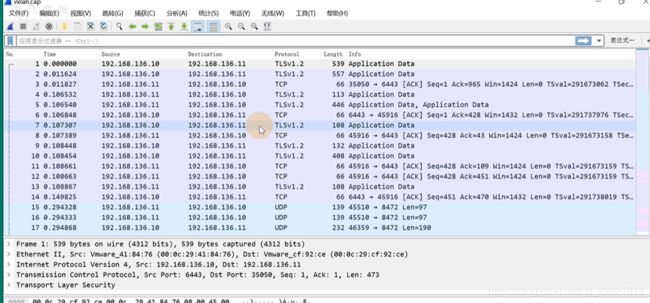
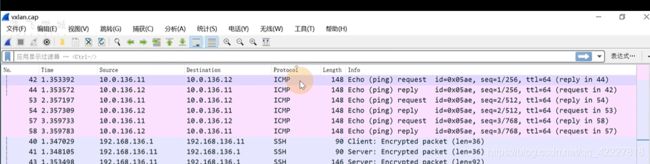
查看下icmp相关的
这个协议就是vxlan的协议,vni是20
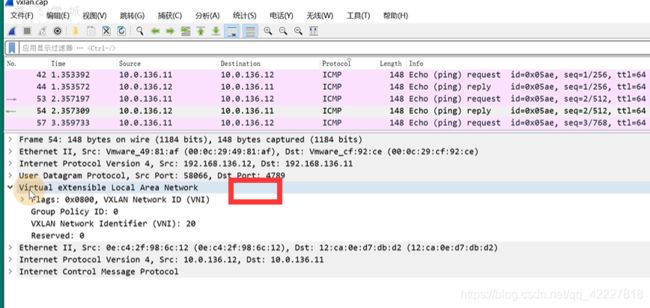
在vxlan之上有原文的报头

3.4 手动实现跨主机容器网络通信(上)
想要实现容器A和容器B这样的通信如何去做,vxlan是打造一个tunnel,tunnel两端是去通信的两个设备
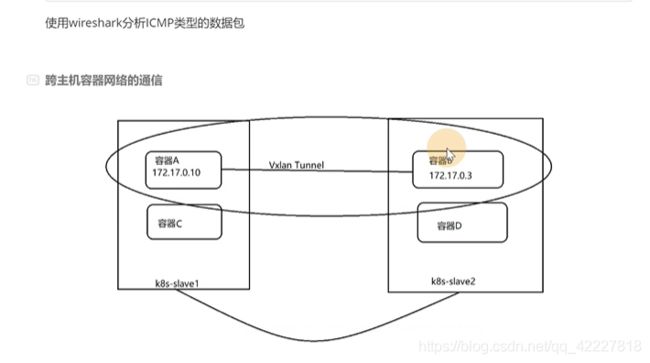
但是容器有很多,不可能每两个都去搭建一个tunnel,如果想要172.0.2和0.3这两个容器通信该如何去做



默认的docker网桥其实是用的172.17.为了避免影响到以前的pod,新建一个网桥172.18段
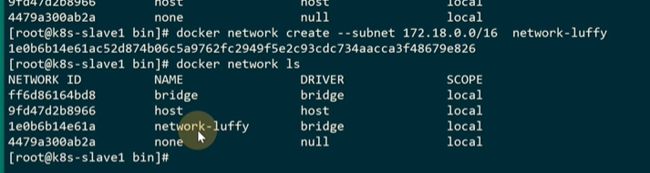
br其实是新建出来的
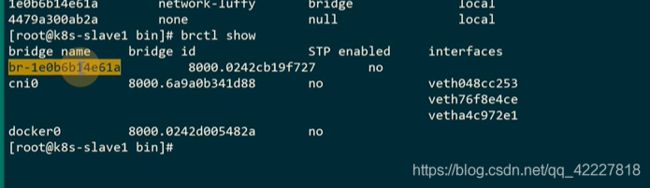

可以通过–net 来指定容器使用的网络是哪个


目前接了一个容器了,每建立一个容器就会建立一个虚拟网卡,插到宿主机上

查看容器的ip地址
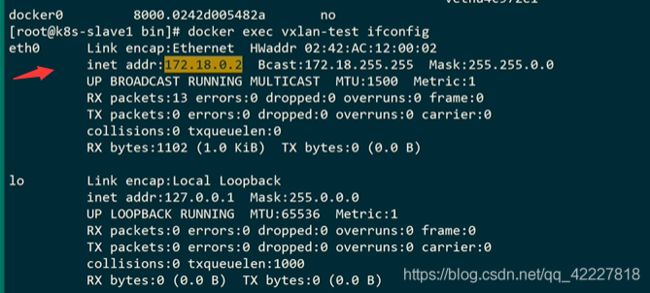
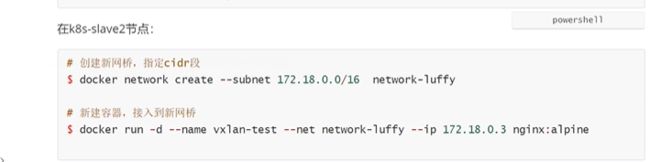
在slave2节点也一样


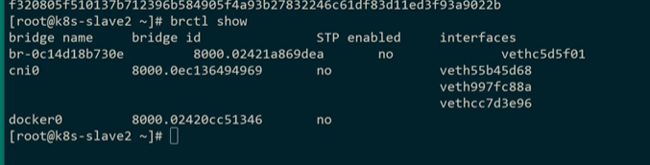
现在是不通的,等于在两台宿主机上新创建了一个网桥,docker网络,在这个桥上接了一个网卡,流量出不去

3.5 手动实现跨主机容器网络通信(下)
现在ping不通,流量都到了这个网桥里
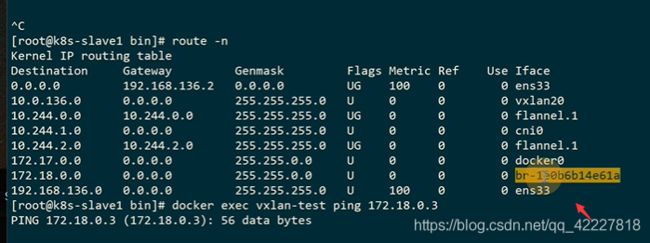

两个宿主机上 的容器访问 需要经过vte设备转发,vtep设备放在网桥上最合适,因为容器所有的流量 都会经过网桥

先要删除旧的vtep设备

![]()
![]()
![]()
一样的remote是对端ip


docker网桥接一个vtep设备

这样就多了一个vtep设备


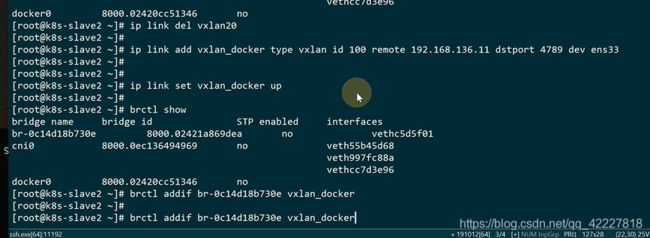
slave2这样也接过来了
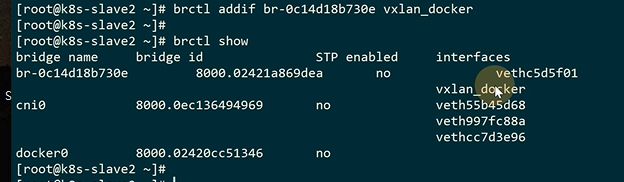
这样旧可以访问了


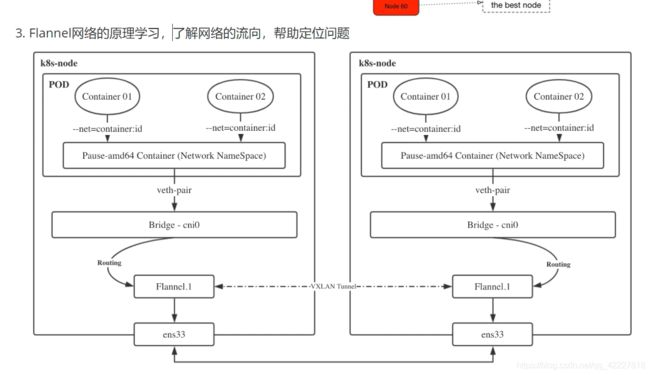
3.6 精讲Flannel的vxlan模式实现原理
1.K8S每台主机都需要跑大量的容器,每个主机都需要一个10.244.0.1/24的ip段.
2.不用点对点的通信,如何实现节点之间的互联
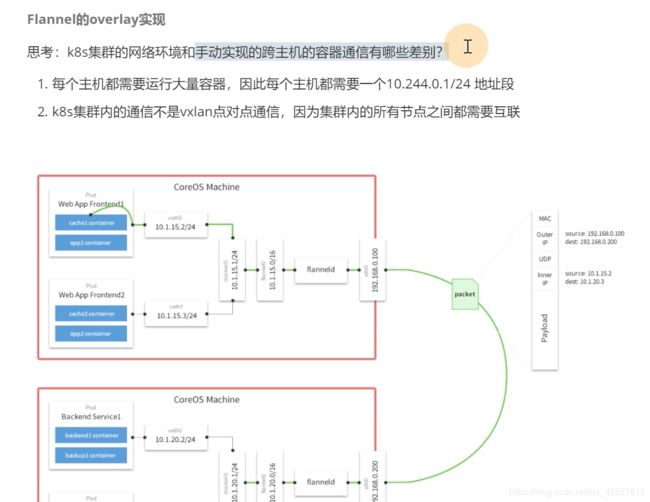
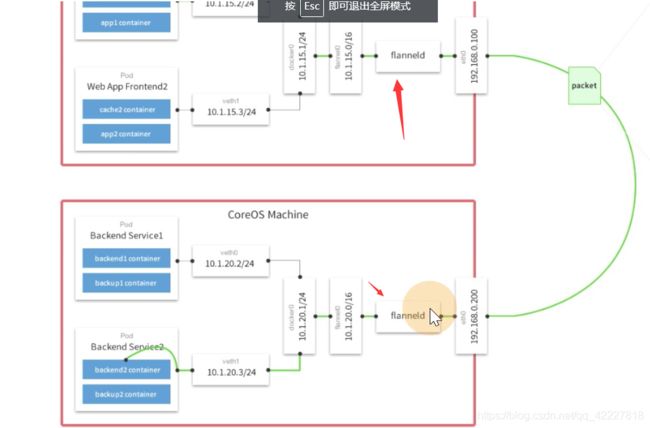
可以不细看下面的图,上面是slave1,下面 是slave2,slave1上的pod要去访问slave2

flanneld会启动vtep设备
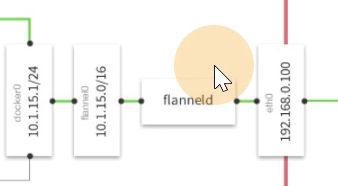
也就是发的包都经过flanneld封装
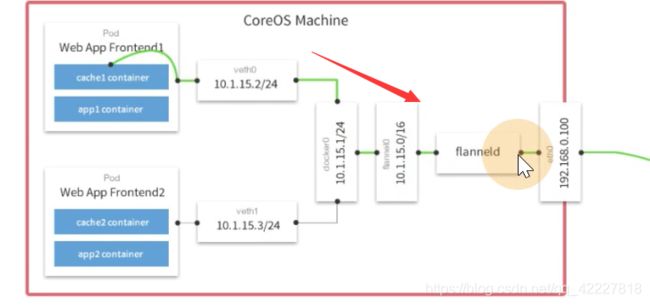
包到下面slave2再进行解包

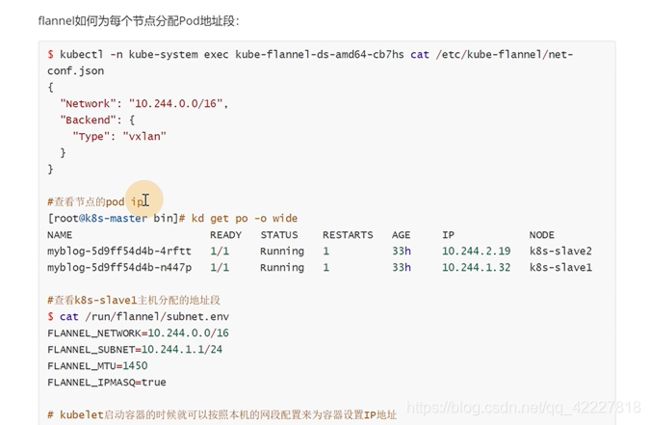
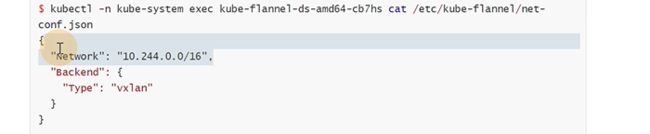
flannel的network是一个大的16位的c类段
这里其实就是设置pod虚拟ip的大网段

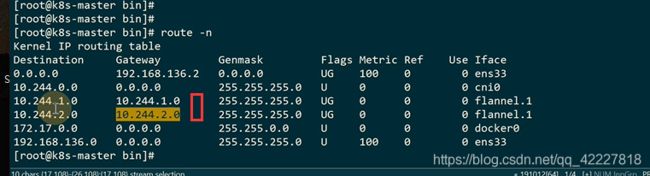
slave1分配的pod ip是10.244.1段的,slave2分配到10.244.2段的
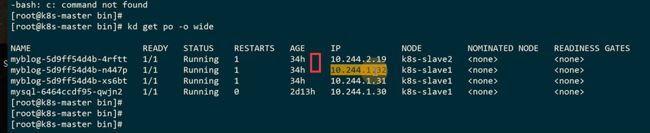
flannel挂了,这个文件就丢失了,master的节点对应10.244.0这个大段

slave1是10.244.1这个大段

每加入一个节点就会按照这个策略去分


flannel创建的vtep设备在这里

这个.1其实就是vni的id,只不过从1 开始,所有的节点都有一个.1的vni设备
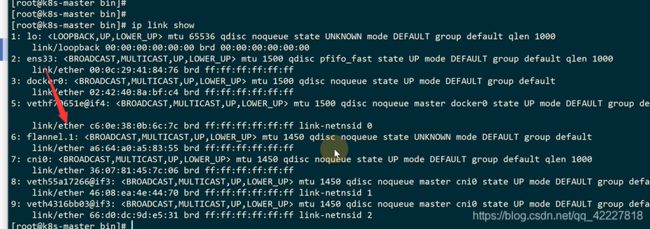
flannel就去充当这vtep设备

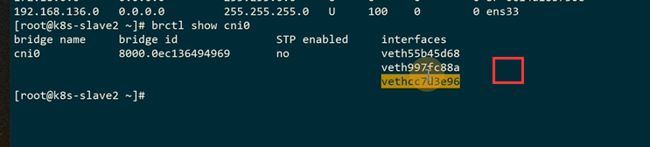
查看网桥,cni的网桥,是cni的实现去创建的

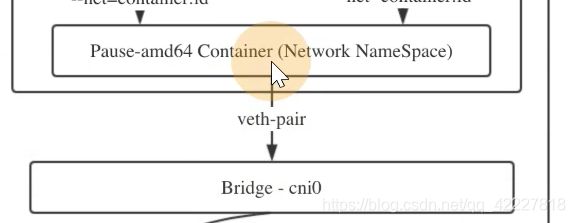
网桥的主要作用其实就是把pod的流量,pod是在一个独立的namespace里,为了是把pod的流量转到网桥上,网桥是在宿主机的空间里,进一步才有可能把流量通过flanneld发送出去
cni网桥已经接了三个设备,这个就是为pod接的设备,因为这个机器上有三个pod已经接入到cni网桥上,以pod为单位,是因为每一个pod内部都共享了一个网络名称空间,就是基础设施pause这容器

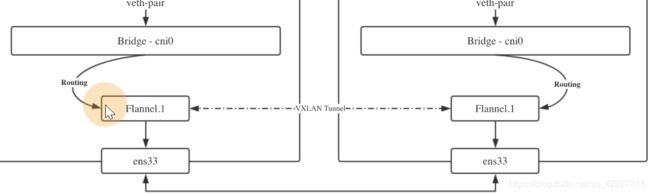
这个就是vtep设备,到10.244.0和10.244.2都会走这个设备,10.244.1就没必要,因为是在本机,所以除了这个段以外的,通过路由规则
目的就是把pod的流量通过vtep设备转发出去

先去建立一个网桥,然后把pod流量通过veth pair转发到网桥上,之后就可以通过具体路由规则来转发

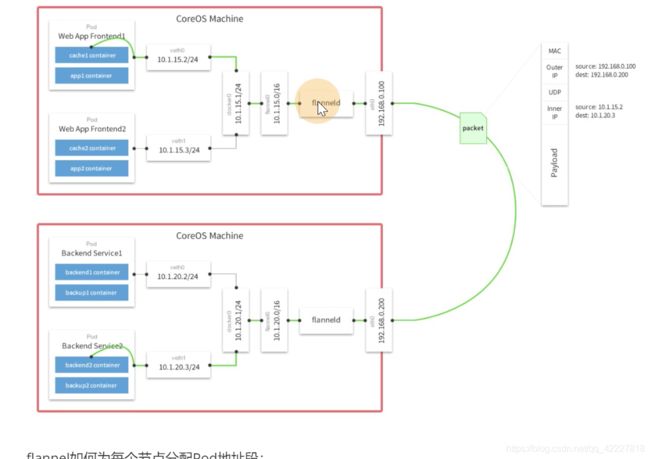
K8S里etcd就是存储数据的,flannel是可以把集中化存储到etcd里去,每个节点都启动flannel,就把数据汇报给etcd


现在要实现跨主机的pod通信

10.244.1段ping10.244.2.段

查看路由,10.244.2段肯定要先匹配路由表才能转发出去
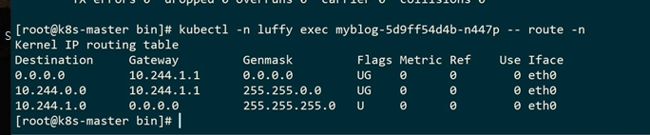
容器里的虚拟网卡应该是插在cni网桥上的,所以它会把流量转发到cni网桥上

这样流量到了宿主机的网络名称空间里
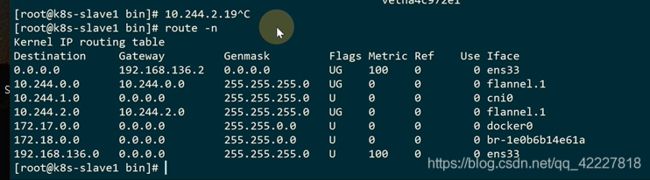
转发到哪里,地址可以查etcd


转到目标宿主机,经过vtep设备解包

匹配到宿主机的网桥上进行转发
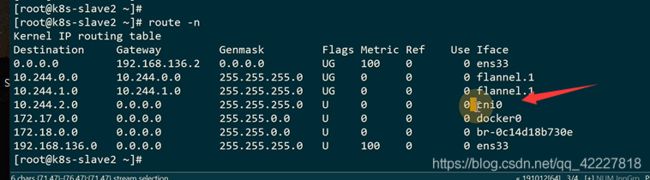
它再去转发流量

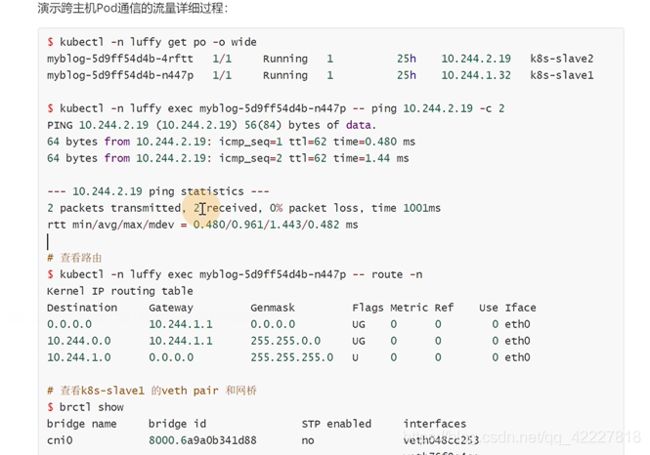

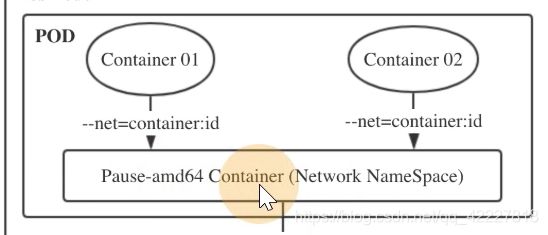
pod里的多个容器,都是使用同一个网络名称空间

起了一个pause容器,这个 容器就是创建网络名称空间,里面的容器都join进来
pod的名称空间和宿主机的cni网桥建立关系,pod的流量都会到网桥上
流量会根据路由规则通过vtep设备 flannel1.1转发,通过etcd知道创建的时候指定的设备ens33,转发到同样vni id的设备flannel1.1,转完之后,通过路由规则,把物理地址的段(物理地址段一定是匹配到cni0设备上),通过网桥转发到具体pod上

3.7 利用host-gw模式提升集群网络性能
之前都是flannel使用vxlan的模式,实现了集群里的pod通信,实际上vxlan模式适用于三层网络环境,对网络要求非常宽松,只要保证集群主机ip能够互通就可以用vxlan。
实际上利用vtep封包解包,对性能还是比较差的。
网络插件的目的就是把本机的cni0网桥的流量发送到目标主机的cni0网桥

既然性能经过封装会消耗,而且K8集群主机都在一个网段,在2层网络里,那么试试直接在cni0网桥通过路由转发,而不是封包经过vtep设备,直接通过路由表去转发流量
这就是host-gatewa,主机网关,主机当作流量转发的gateway使用,如果主机都在同一个二层网络里,其实是可以改成host-gateway模式

有一个flannel的configmap

configmap可以把整个文件内容挂进去

我们需要改的是这里


这两个配置文件对应connfigmap的两个key


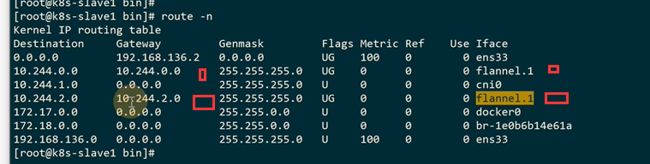
现在的路由表的目标地址和网关是一一对应的
保存以后不会自动创建,需要手动创建,删掉之前的三个
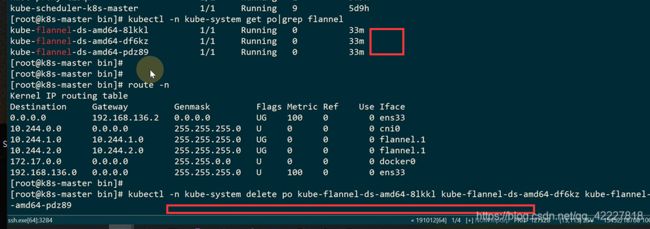
查看下日志

现在的路由表,现在网关变成了宿主机的ip

因为分配到的是10.244.0段,所以0.0的目标地址转发到cni0设备上,转发到自己的网桥上去,因为就是要路由的pod里,所以针对本机的段,一定是路由到cni0上的。
其他节点的段,一定是通过网关的方式

slave1也是同样的道理



pod的ip是不会变的,该怎么走还是怎么走

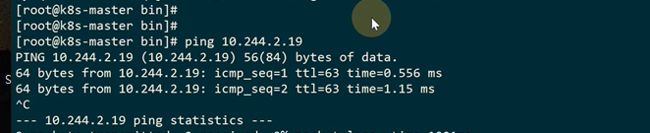
从slave1节点ping slave2,说明就算改成 host-gw模式,对pod也没有任何影响

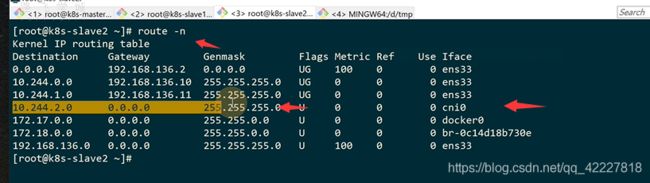
前面不改变,流量还是通过虚拟网卡转发到cni0,到了cni0,物目标地址是10.244.2.19
2.19匹配到这条路由

流量到了salve2也就是192.168.136.12的时候,直接去链接cni0网桥,网桥就是链接pod和宿主机之间的桥梁
由cni0转发到对应的eth0上去

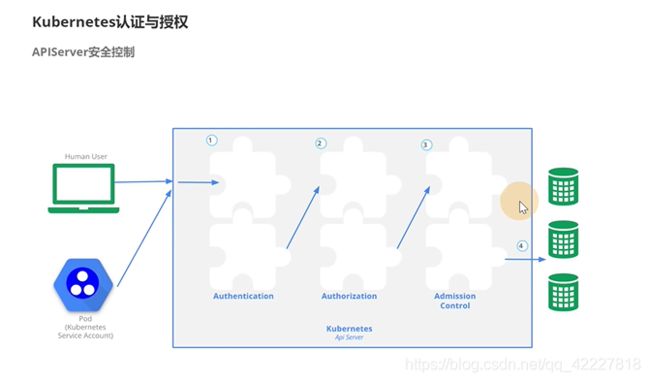
第4章 Kubernetes认证与授权
4.1 APIServer安全控制

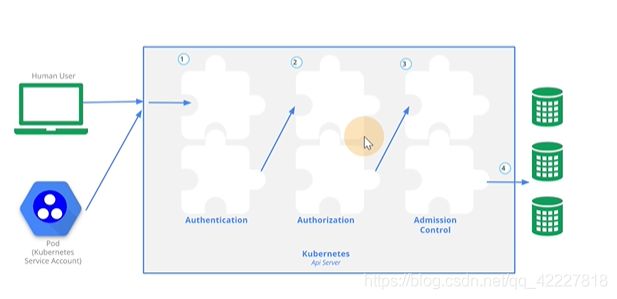
**左边是一些用户的请求,中间是apiserver,右边是etcd存储。
**

中间经历了三块内容,auth认证,授权,admission control整个控制

类似于登录网站输入账号密码,就是身份认证,在K8S里第一个环节有几种方式

basic auth类似在一个配置文件写死账号密码,告诉apiserver,跟配置好的账号密码做一个校验
client证书验证,是https双向
jwt token,拿到token,
这只是其中几种方式。
apisever从输入的http request请求,拿到验证信息

可以选择一种或多种验证方式

kubeadm安装的集群支持clent和jwt token,这两种安全性是更好一些

apiserver在启动的时候加了这两个参数就会支持client和 jwt token


认证完后会拿出来用户信息,user,group,才到第二个环节

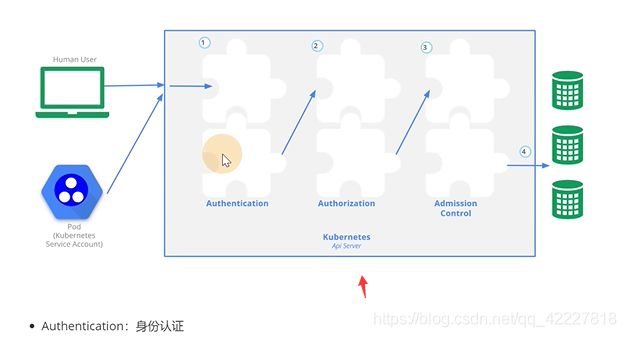
第二个环节拿到用户信息,和要访问什么资源

**通常有两种鉴权策略,node,rbac,webhook
**


这里是鉴权模式,只要通过一种就说明鉴权成成功的
类似一个控制链,每个关卡上都会去请求一次校验,是一种拦截请求的方式。
认证和鉴权都是通过request的header拿信息,没有办法验证body内容。
admission运行在apiserver的增删改查handler中,可以自然地操作apiresource

namespacelifecycle是其中一个关卡,拒绝请求不存在的namespace和出termination状态的,还可以防止删除系统的namespace,default,kube-system,kube-public

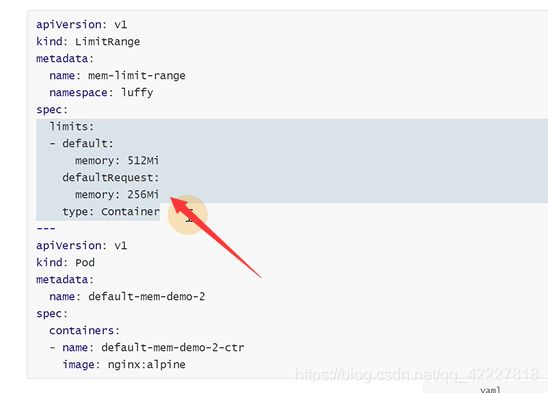
limitranger是设置命名空间的,创建pod的时候会设置limit上限,假如没有设置,就会按照limitranger给的默认值
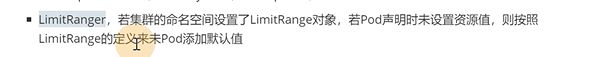
下面没有指定limit的会添加到这个值
node限制,局限于kubelet修改node和pod对象,不允许修改其他node上的

默认开了一个node限制

其实K8S默认会把serviceaccount,或则imitraner都包含进去了,初始化都打到apiserver里了,能拦截整个用户的请求,可以修改一些信息。
比如注入sidecar和initcontainer容器,istio和sidecar就是利用这种方式
自定义业务的实现,比如自己写一个webhook 然后注入到adminssion链里

想要通过apiserver注入etcd里需要走这几步,认证,授权,控制
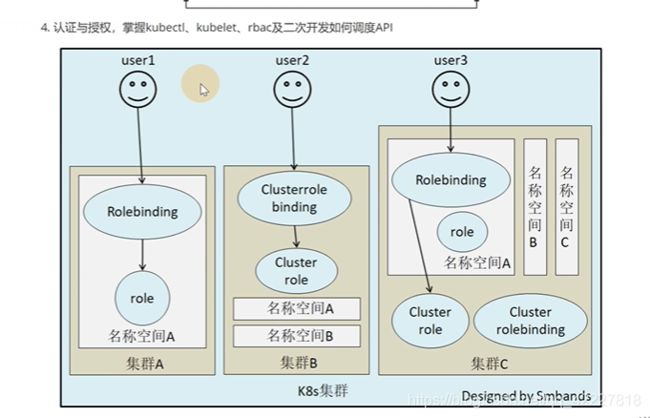
4.2 kubectl如何通过RBAC实现认证授权
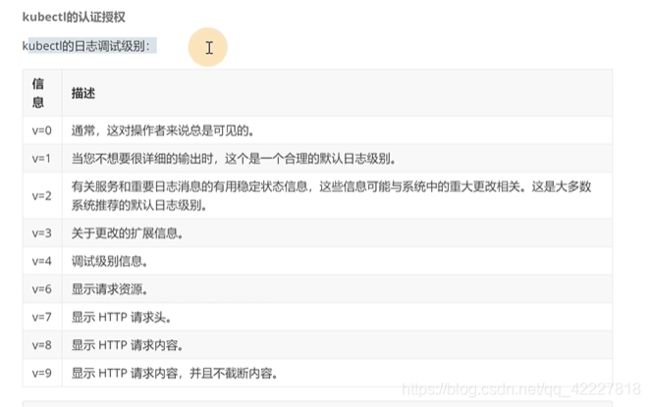
查看更细的细节 可以加-v=0-9

可以显示详细信息
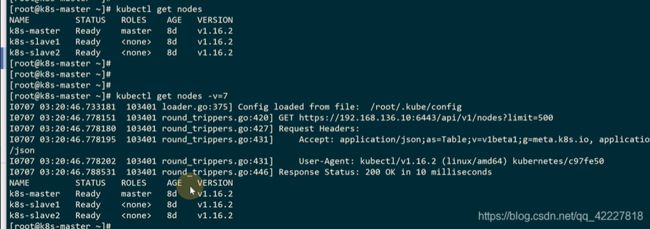 是从文件里加载配置,kubeadm初始化的时候,master配置了这个文件
是从文件里加载配置,kubeadm初始化的时候,master配置了这个文件
![]()



其实是一个kubectl的config文件,都是一些证书的key,用户信息
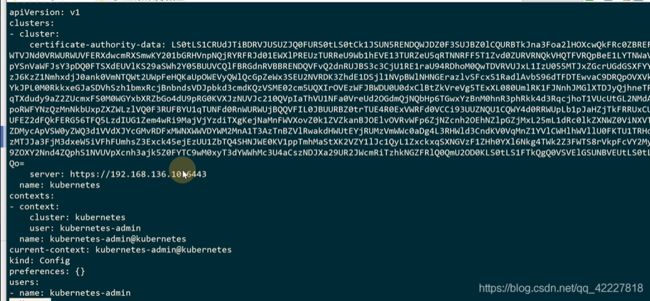

私钥和证书,都是base64加密后的
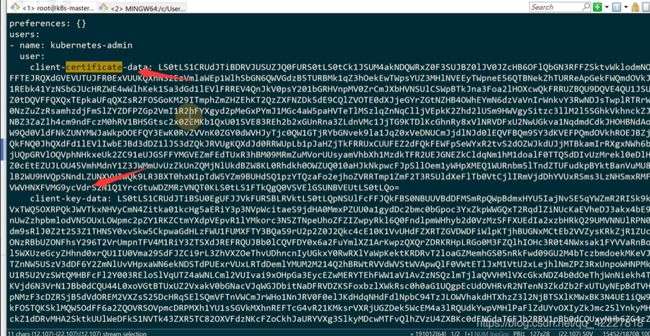
做一下base64解密

这是一个证书文件

可以保存下来
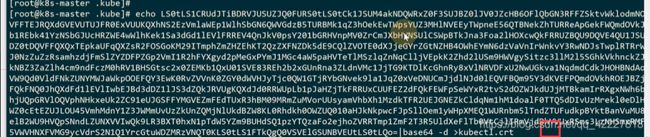
key也是一样的去解码

rsa加密算法的私钥
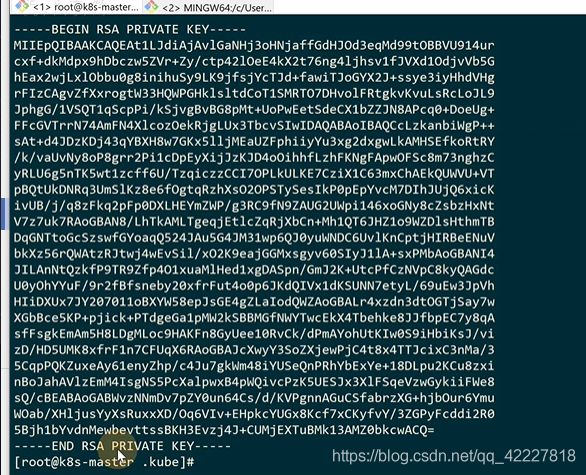
签发证书需要根证书,在这里,是K8S认证的根证书
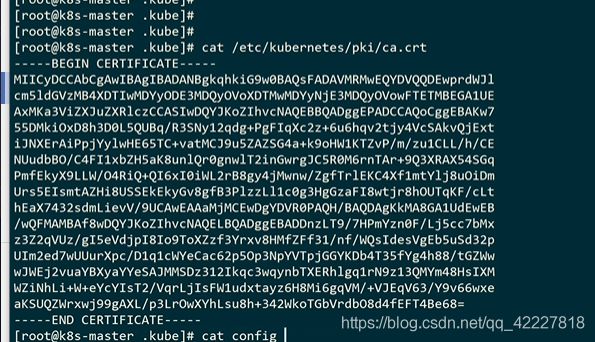
这是一个整个集群的根证书
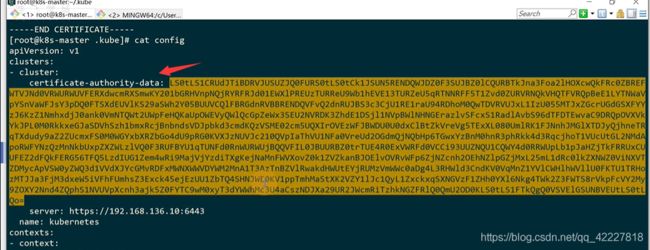
上面那解码出来
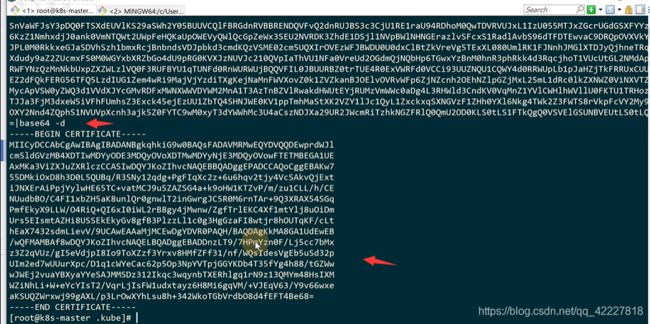
其实和K8S的根证书是一样的
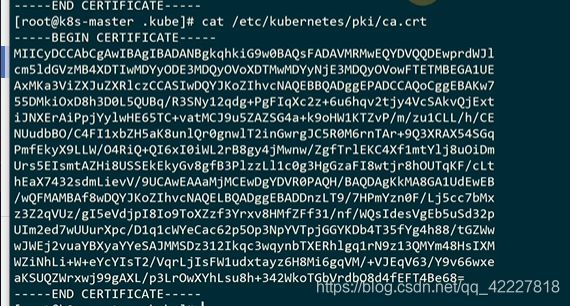
怎么去证明下面的key和证书是K8S根证书签发给你的

这个就是看到的根证书
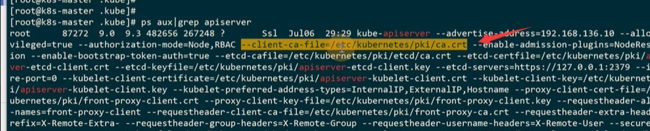
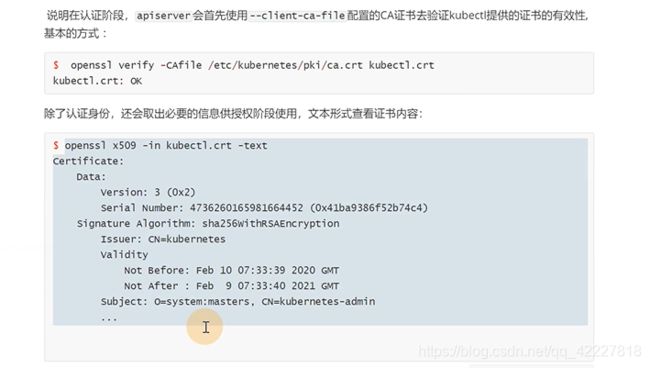
可以校验之前保存下来的kubectl.crt证书,结果OK,说明这个证书是合法的

可以用openssl去模拟apiserver拿到用户,证书信息,所有授权需要的信息

证书的O一般代表证书的group,CN一般是Common Name,也就是用户,传递给apiserver鉴权
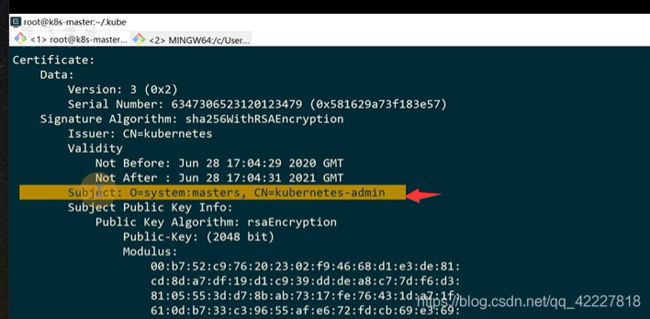
cn=common name当作用户名,O当作组织

RBAC是一种基于角色的访问控制,rule加上组可以去操作rule定义的规则
clusterrule是一类跨集群的角色,角色里面定义一些可操作的资源(也就是定义权限)
clster rolebinding把谁能操作这些权限(用户或组绑定在一起)

默认有很多,后面创建的flannel和其他的也会创建自己的权限

**现在是在看这个clusterrole,这个集群里有哪些权限,resources(就是类似ingress,deployment),*星号代表全部资源,non-resources urls全部非资源的url(健康性检查url ),resource name不创建指定的资源名称,其实就是全部。
verbs就是可创建,可查看,可删除。全是星号就代表最大权限。
你只要是 这个用户绑定了cluster-admin,就是最大权限
**
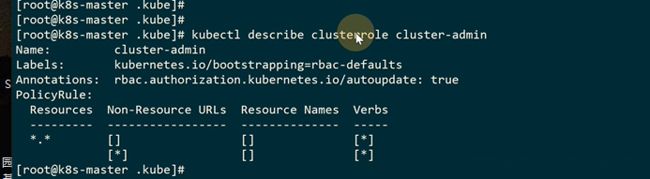
有了权限,就可以看到权限绑定了谁clusterrolebinding
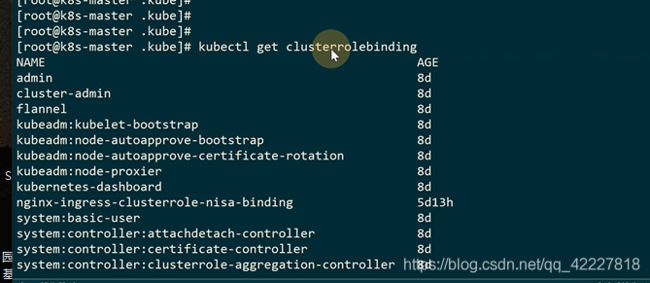
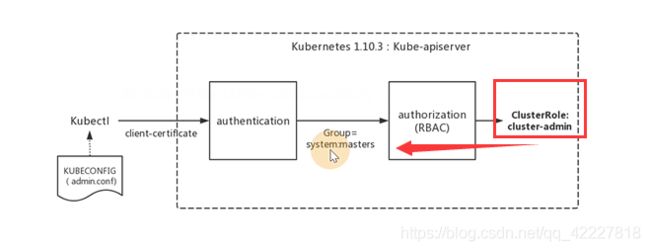
把role绑定到subjects,这个system:masters组有cluster-admin的全部权限
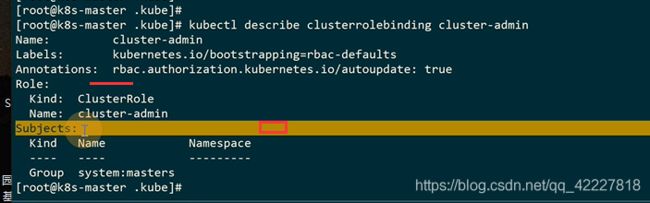
通过kubectl操作集群的时候,也会用到clusteradmin的权限

允许 超级用户去访问和操作集群里 的 任何资源,当使用了clusterrolebinding的时候,给了整个集群任何资源的所有权限

describe role发现是全量的权限

**kubectl操作资源的时候是去读admin config文件,先去拿client-certificate证书做auth认证,取出证书的CN和 O(group是 system:master),通过rbac鉴权,其实绑定了一个cluster-admin的跨集群超级管理员角色 **
**当你kubectl操作出了问题就要 看卡在哪步骤出错了,是证书过期了,还是认证没过,操作权限不在范围里 **

4.3 RBAC
rbac是role-based access control

这里有node和rbac两种模式
rbac的实现引入了4个资源类型,第一个是role角色,下面是可以定义只能查看default名称空间下pod的权限

api version

rule这个角色一定要固定在namespace里

**权限通过rule字段定义。
**

apigroup,K8S设计api的时候做了一个分组,kubectl api-version列出了整个版本
![]()
常见的
不限制apigroup
![]()
资源类型,可以是service,可以是pod
![]()
![]()
![]()
get获取一个,list查询列表,watch监控资源的动态变化,创建,更新,patch修复,删除,exec
![]()
pod-reader这个role权限是读取default命名空间下的pod,对pod的操作有get,list,watch

K8S的所有资源只能通过role和clusterrole暴露,角色就是专门划分权限的
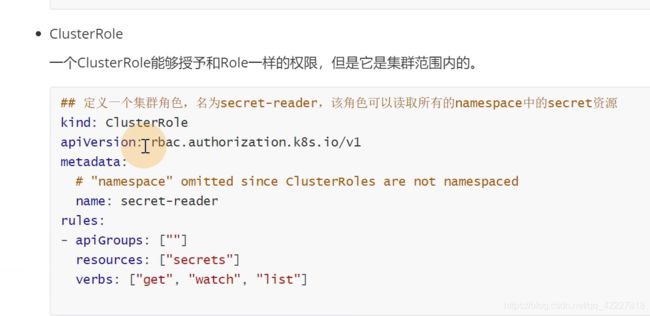
clusterrole里,metadta是没有namespace的,clusterRole不是去限制namespace的

false代表不属于某一个名称空间,是一个跨namspace的

定义一个读secret的reader,读secret权限的一组role,但是这个role是可以读所有namespacce的

role和clustrroe只是定义了权限,还不知道给谁用.
下面是把custerrole绑定给了group。只有做了绑定后,前端的请求才会被K8S认识
如何去做绑定rolebinding,是绑定 在namespace里的
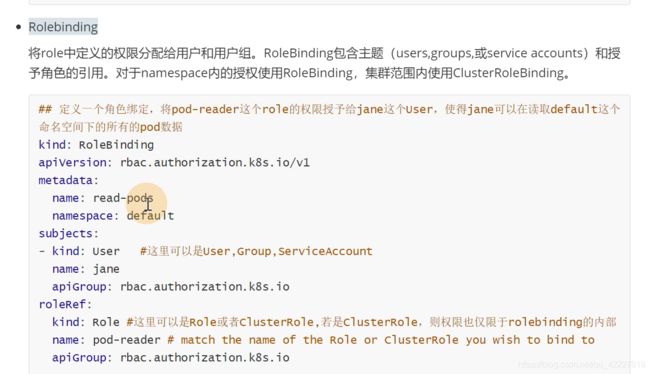
绑定的主题subjects,name,group

把pod-reader这个权限赋值给jane

注意名称空间的范围

这里因为用的是rolebinding,用户和serviceaccount所以只能操作development下的权限,虽然权限是clusterrole,但是是用了rolebinding来绑定权限。
rolebinding可以来限制权限范围


可以实现一个跨集群的访问操作

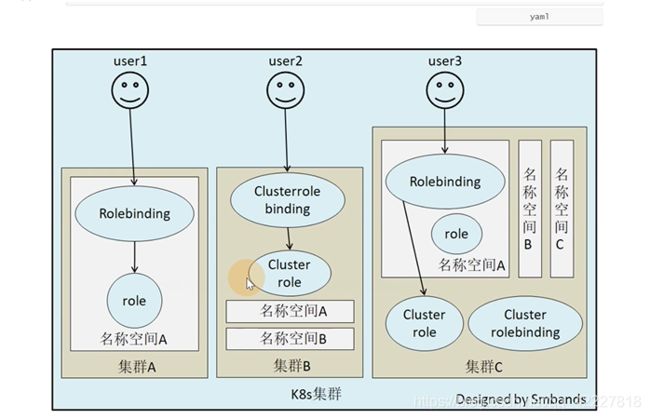
用户想要role权限,可以通过 rolebinding指定到这个role里

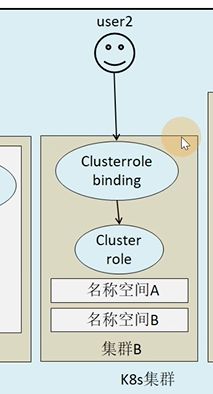
有两个名称空间,可以使用跨命名空间clusterrolebinding
集群c有三个名称空间,虽然绑定的是一个集群的角色,但是绑定方式是rolebinding,所以只有名称空间A的权限

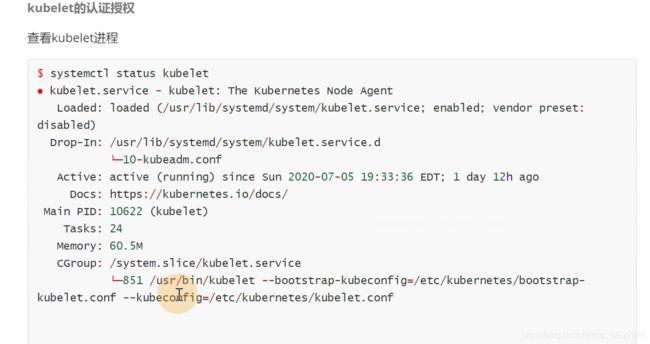
4.4 kubelet如何利用Node模式实现认证授权
kubelet可以汇报节点状态,也可以去启动pod,更新pod,也需要调用apiserver,调用etcd

这里有一个kubeconfig文件
跟kubectl的文件非常相似,前面是跟证书
下面是跟证书签发的证书和私钥
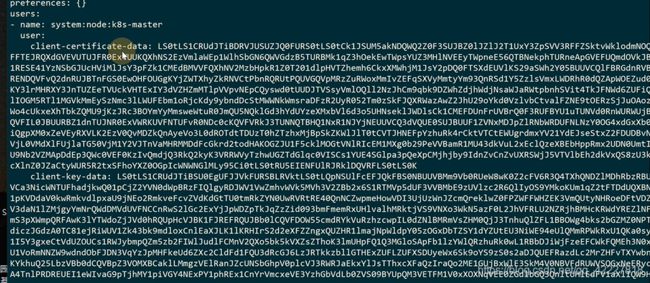

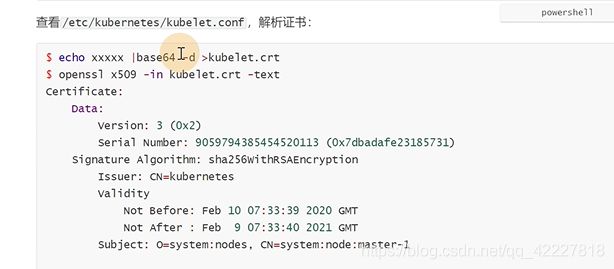
保存下来,方便看内容
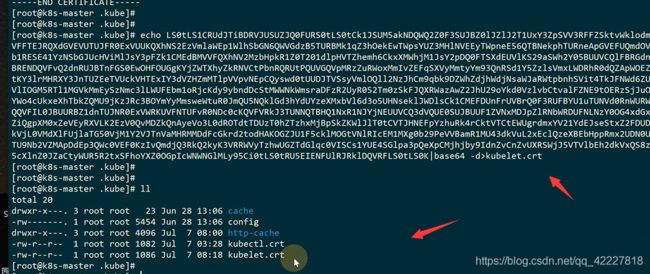
是不是集群根证书签发的

证书里的认证没问题,还需要拿到用户和组信息鉴权,这两个信息作为group,cn传递给rbac授权,使用rbac授权的就会有rolebinding和clusterrolebinding来绑定这个权限给用户

查看整个集群全部的rolebinding

get资源的时候不值当具体资源,K8S会把资源全部打印出来
![]()
clusterrole
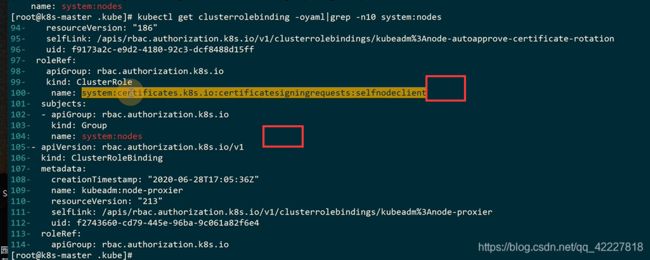
用这个clusterrolle去像操作kubectl一样是肯定不行的
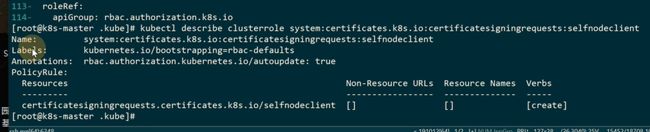


找一下clusterrolebinding

![]()
这里是核心组件的权限

允许kubelet访问资源,包括读写的权限

应该使用前面的替代后面的角色

这个是为了兼容之前的版本,1.8之前都是system:node,1.8之后K8S不使用了,但是为了保持之前的版本兼容,保留了
![]()
使用node授权,node就是去解决kubelet授权的

这些是读操作

写操作和授权相关操作

未来可能在node选择器里增加和删除确保kubelet只能拥有它所需要的操作权限
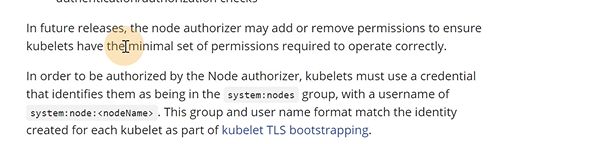
如果要使用node选择器,必须保证传过来的组叫system:nodes和用户名是system:node:< nodename>

![]()



kubelet授权和kubectl是两种授权,kubectl是rbac,kubelet是node authorization
4.5 Service Account及k8s api的调用

基本上在K8S二次开发都是使用serviceaccount+rbac方式

加个—,就是同一个yaml文件写多个资源的写法

kubectl就是用的cluster-admin,集群管理员的角色,把这个权限赋予给subject主体,serviceaccount,就可以通过这个账号去操作集群里的资源



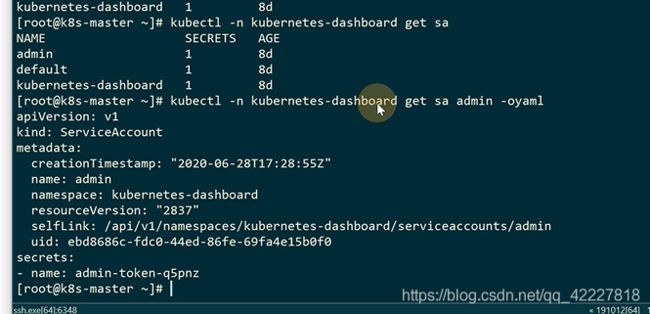
这里之前有一个dashboard

找一下这个secrect

描述一下这个secrect的信息,主要是这个token信息

所有的resources都可以操作

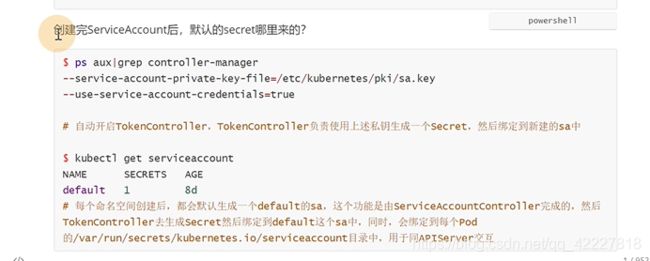
这是contoller-manager的地址


controller-manager组件会去自己开启tokencontroller,会去检测每一个创建的serviceaccount对象,如果没有token,就会去用我们的私钥去生成一个,绑定到新建的serviceaccount中
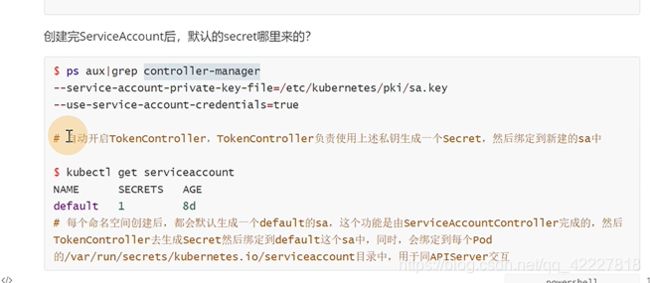
在默认名称空间里有一个默认的default,serviceaccount

其实任何一个名称空间里都有一个default的serviceaccount

在这个default之下才会有secret
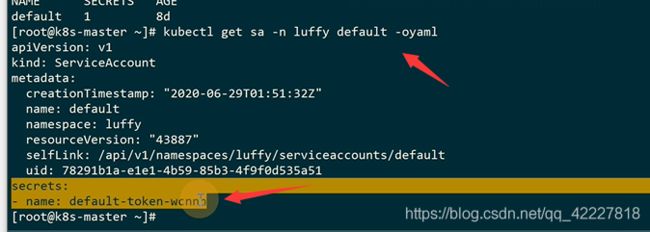
**我们创建每一个namespace的时候,会首先生成一个default的serviceaccount。
**
由于controller-manager有两个参数,token-controller会在default serviceaccount里绑定一个 secrect
serviceaccountcontroller会在创建一个名称空间的时候创建一个叫default的serviceaccount,有了这个default的serviceaccount,tokencontroller才会去生成secret然后 绑定到default这个sa中。
同时每创建一个pod,会绑定一个/var/run/secrets/kubernetes.io/serviceacount,用于和apiserver交互,也就是在pod内部可以和apiserver做交互
创建的默认的secrect挂载在这个路径下


首先在dashboard创建了一个叫test名字的serviceaccount

创建了一个role,在kubernetes这个名称空间 里只有pod的读取权限

创建一个rolebinding,绑定给serviceaccount
![]()


新建了一个test

每创建一个pod都会创建一个secret

可以用这个token去访问dashboard,来验证授权规则

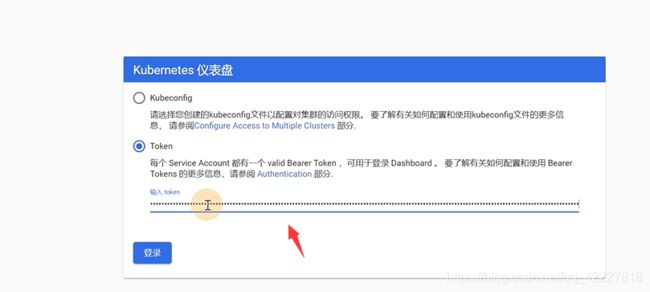

点击pod,可以展示出内容
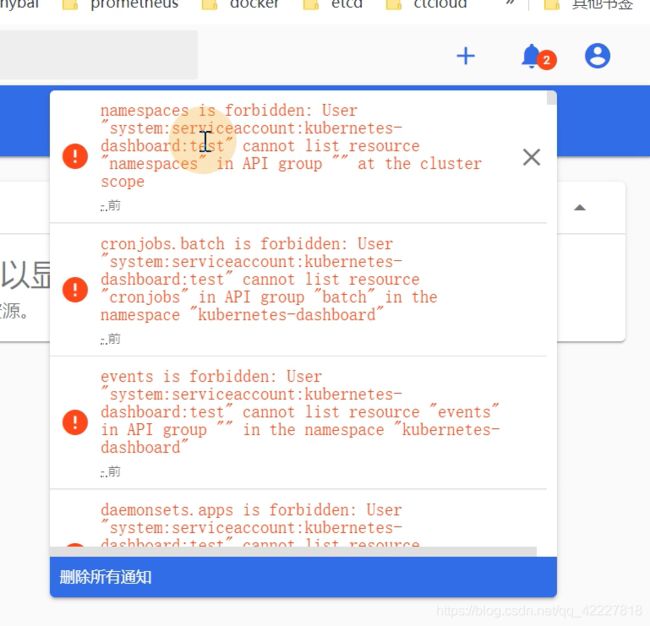
提示我们没有权限
通过curl如何去调用api


我们要调用api就是这个
authorization:bearer 是经常开发的时候用的一个认证的头,bearer后面有一个空格,多一个不行,少一个 也不行

复制这个token
后面跟dashboard的url,指定kubernnetes-dashboard名称空间
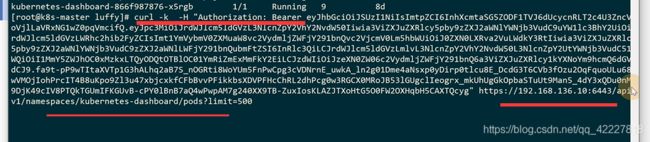
可以拿到数据
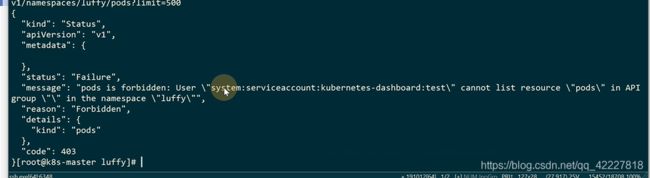
换成luffy名称空间就访问不到数据了

没有权限
K8S认证包括三大部分,一部分是认证(证书和token),一部分是授权(rbac和node,node只有kubelet用 这种方式去授权,理论上操作资源都是通过rbac去做),adminssion control整个控制(偏安全管理方面的)
二次开发的时候更多的是用serviceaccount和rbac去做cluster API的开发
第5章 通过HPA实现业务应用弹性伸缩
5.1 HPA控制器介绍
使用HPA,让业务实现动态缩容扩容
horizontal pod autoscaling,pod水平自动伸缩

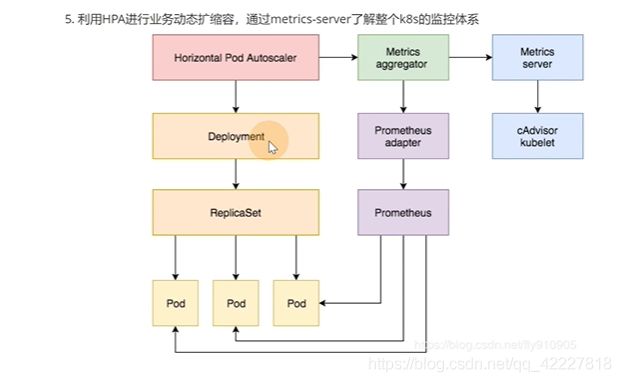
rc是副本控制集,deployment是部署,scale连接了HPA,HPA作用于某个deployment或者rc,rs上的,是一个支持水平扩展的资源,像daemonset这个资源就不行,不支持水平扩展
HPA其实是一个监控pod的使用率,满足阀值就去扩容缩容

HPA需要拿到pod的metric数据,也就是监控数据

通过apiserver这种方式代理了之后,整个访问路径是service_namep[portname],这样明显不符合restful风格规范。
不能像apiserver鉴权。
metric apiK8S把监控也做的标准化了
1.8开始,metrics-server就逐渐成为一种监控方式,作为HPA请求 的一种数据来源
-v=7 可以查看执行过程
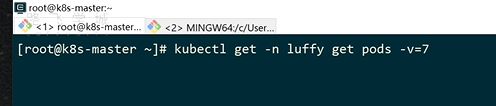
这里有一个url地址

可以像访问K8S里的核心资源一样,访问一些监控数据(metric-server提供的)

HPA通过metrics.k8s.io/v1beta1,调用mertic-server提供的mertiecs-api,metrics-server再去通过kubernetes.summary_api调用kubelet去拿数据,采集数据还是kubelet去做

5.2 Metrics-Server安装
HPA的实现有两个版本,v1只包含了根据cpu指标的检测,v2beta1,支持内存的指标和自定义的指标

metric server收集每个节点的summary api,真实采集数据是kubelet去做的。
metrics server 把自己的api注册到K8s官方的 aggregator聚合器,这样才能通过标准的K8Sapi去访问数据

直接运行会报错,提示我们需要修改一些配置

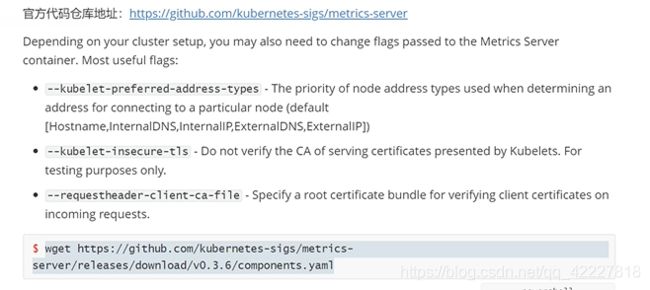

**metric通过kubelet拿数据,就需要访问kubelet的地址,这就是kubelet地址的访问顺序 **

hostname就是这个,mertics是容器部署,就肯定解析不到这个域名
internalip就是内网ip,是可以访问到的

kubeadm初始化签发证书的时候,其实是把每台机器的hostname打到证书里,叫ipsince(里面一堆证书或者域名)

下面的就不用配置了,因为前面已经insecure不校验证书了


一个yaml文件可以写多个资源类型
![]()
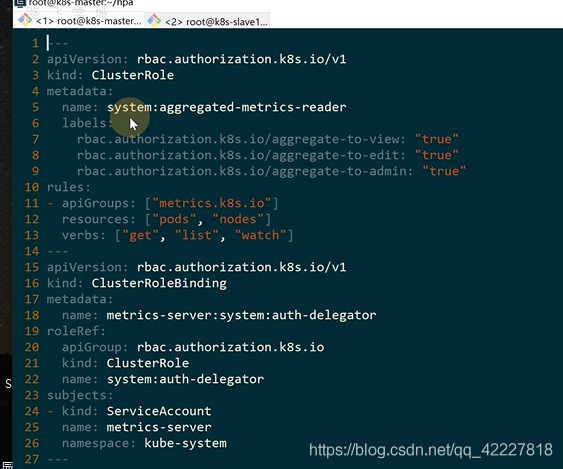
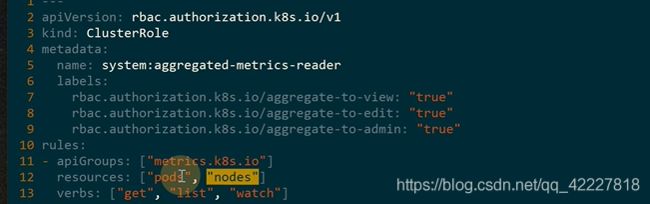
定义一个clusterrole,只需要拿pod和node的监控数据就可以了
绑定到了一个metrics-server的serviceaccount

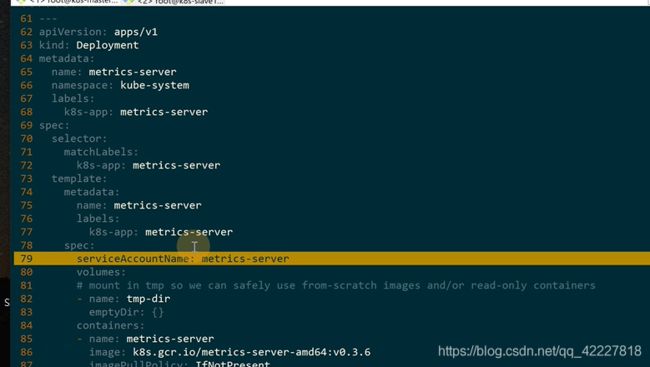
下面 是deployment使用一个serviceaccount叫metrics-server,这样pod里的容器就有了metrics-server权限,这是在pod内部使用metrics-server的用法
加上参数否则会报错,顺便替换成阿里云

默认放在kube-system里的

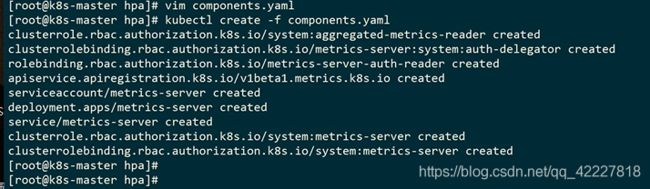
跑到了slave1节点上
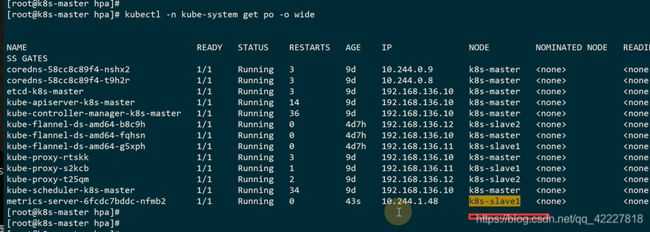
查看日志有没有坑

有些pod如果不加资源 限制会有错误


5.3 kubelet与cadvisor如何采集监控数据
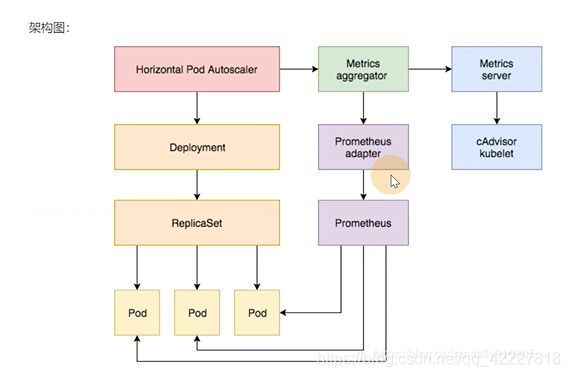
无论是heapster还是metric-server,都只是 数据的中转和汇集,本身不采集 数据,只是把数据拿来之后暴露出去,两者都是去调用kubelet的api去获取数据。kubelet有很多功能,负责采集 指标的只是cadvisor这个模块。
可以通过10250的端口获取数据


直接访问是不行的,需要认证

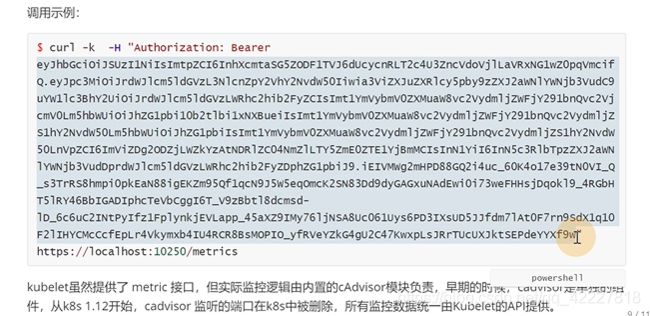
可以去拿dashboard-admin这个token,因为已经是最大权限了
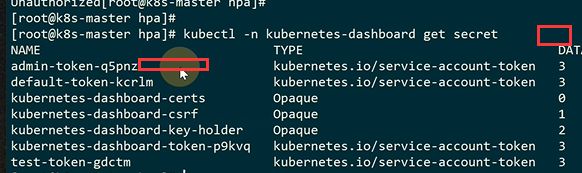

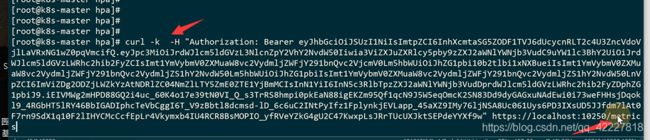
类似prometheus的数据

验证下container的数据,只需要改一个cadvisor
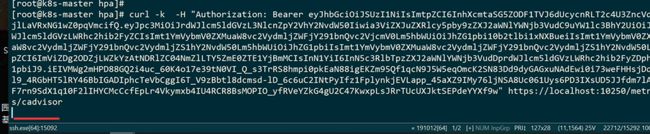
每个指标按照容器pod做了展示
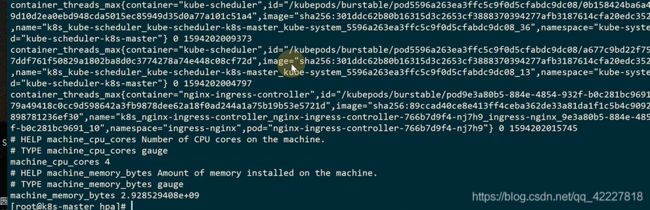
真正干活的还是这两个

cadvisor其实是去负责采集的,采集之后,metric-server是负责调用采集api的。cadvisor独立的实现在1.12以后都删除 了,都迁到了kubelet里
runc/container是docker一开始为了去实现跨平台的库,让docker去兼容linux,其他系统。libcontainer是对cgroup文件的封装,cadvisor是一个 转发者,它的数据来自于cgroup文件,整个linux一切皆文件


对docker容器来讲

这个是容器id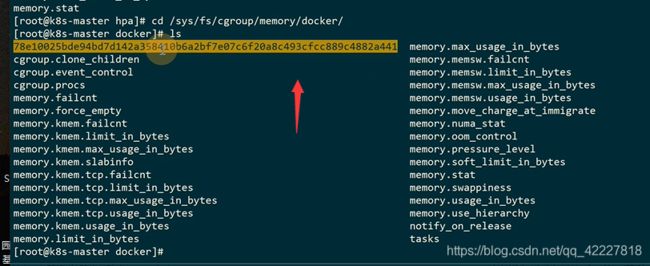

内存使用的值会放在memory.usage_in_bytes

如果是K8S起的POd,上面两个是K8S里服务质量用到的属性
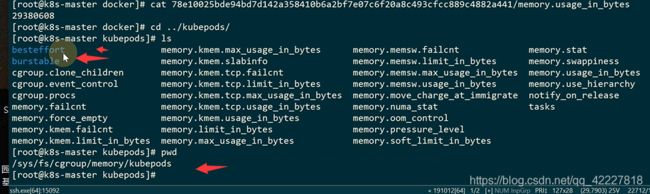
以pod开头的就是K8S数据
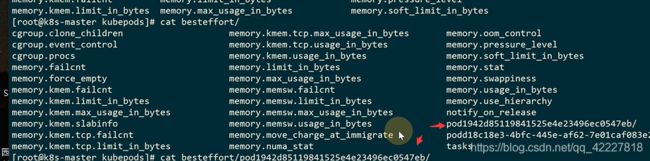
这是按pod统计的

kubectl top命令其实到最后采集的是文件里的数据
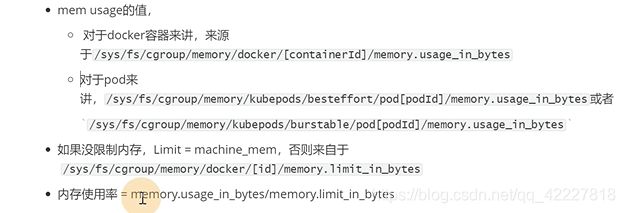
kubectl和dashboard,scheduler使用的时候通过apiserver(其实就是metric)调用kubelet(实际cadvisor组件),采集cgroup文件数据
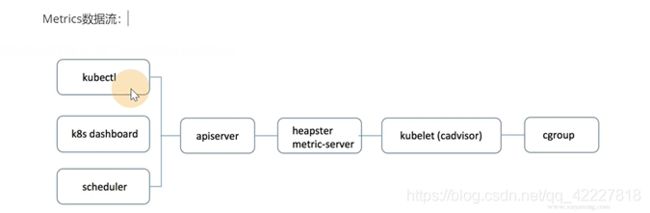


5.4 kube-aggregator聚合器及Metrics-Server的实现
K8S的聚合器aggregator。
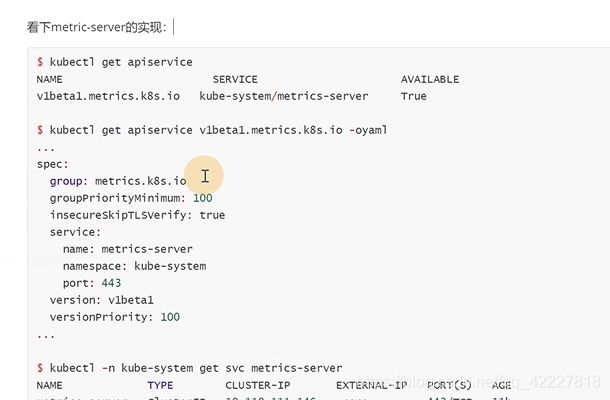
metric server是一个独立的服务,只能服务内部实现自己的api,是如何做到通过标准的K8S api暴露出去。
聚何其是一种apiserver的api一种 拓展机制。允许开发人员写一个自己的服务,把这个服务注册到K8S的api里。

apiserver是蓝色部分,除了标准的api以外还有api聚合器,自己开发的api其实是一个可插拔式的设计,它的apiserver可以通过聚合层暴露出去

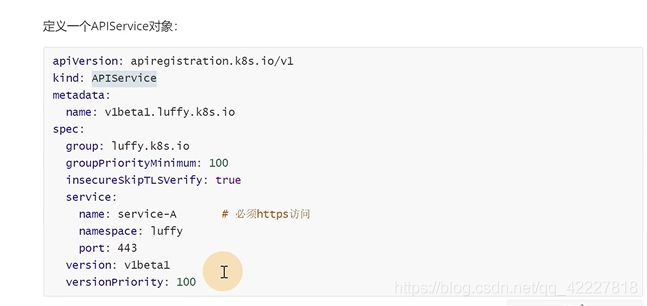
这是一个开发写的具体的业务服务,自己写的service端口必须支持https访问
这么写的yaml,K8S会以下面的url代理请求
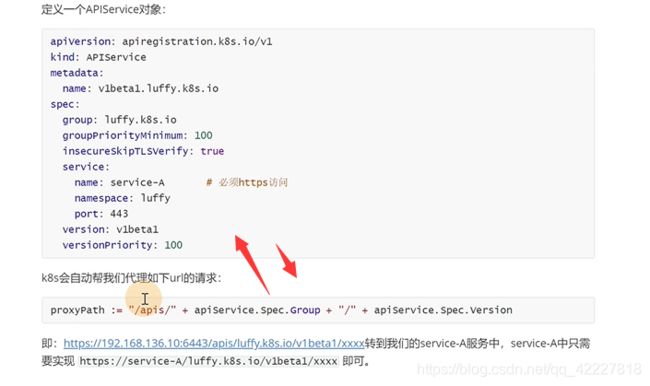
这里就是我们service具体去实现访问的url

查看metric-server实现

这是安装kube-metric-server,安装过来的

metric.k8s.io就是内部去实现的一个组,用的版本是v1beta1

组metrics.k8s.io/版本v1beta1/
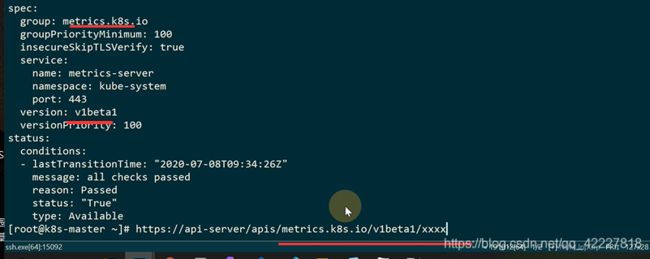
要实现上面的url访问,metrics-server就要去实现下面的路由
![]()

apiserver地址/apis/组/版本/namespaces/名称空间名字/pods

查看一下它的名字
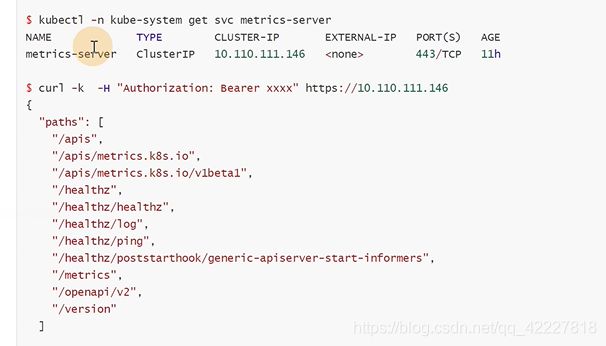
通过 一个标准的api来访问监控数据,这是通过聚合之后的api地址去访问。
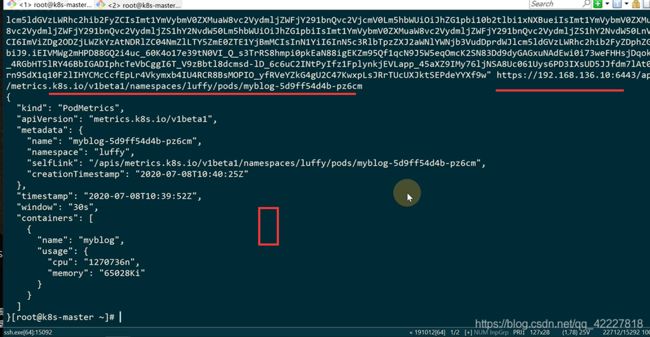
标准apiserver会转到具体的apiserver,才会用同样的url去访问

可以查看一下metrics-server的地址


直接访问metric-server地址,效果是一样的
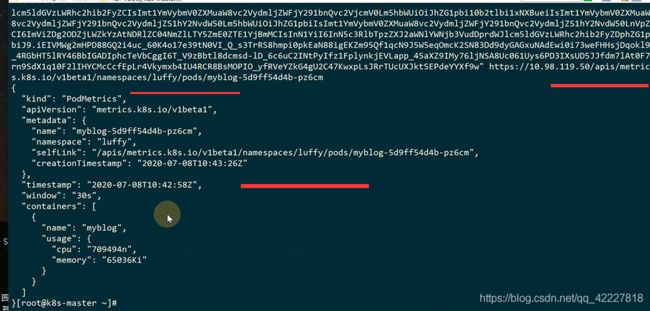
K8S只是把服务地址换成标准的apiserver地址

访问metric-server地址的时候可以打出所支持的所有path

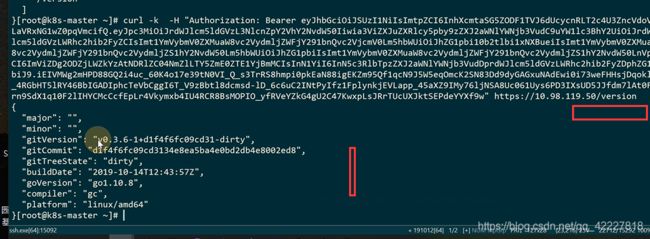
这是一个metrics-server的具体实现

5.5 基于CPU实现业务的水平扩缩容
HPA已经具体定义到一个控制器里了
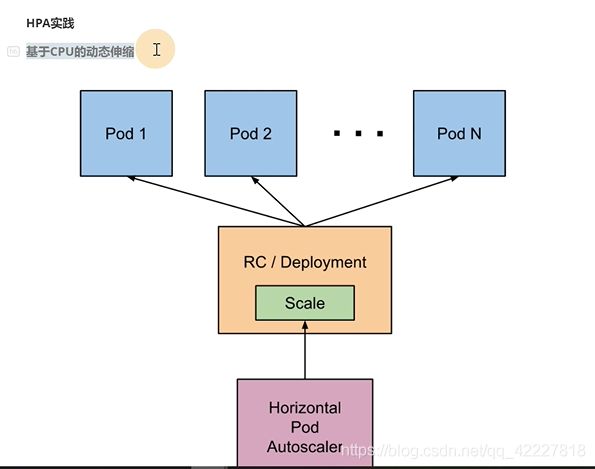
把HPA加载到deployment之上

最小一个副本,最大三个副本
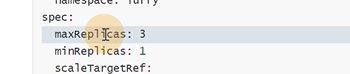
平均使用率超过10%就扩容



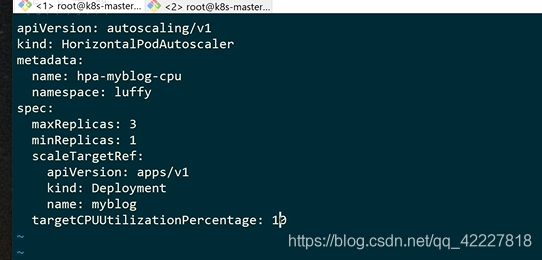


现在试试把cpu利用率涨上去,这里使用的是一个默认15秒的周期,kube-metrics设置

可以做一个模拟压测
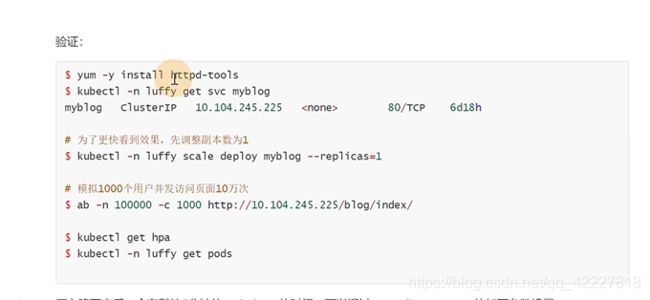
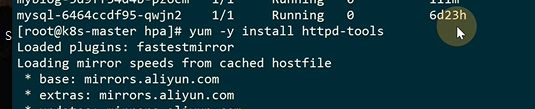


进行压测


已经开始启动了


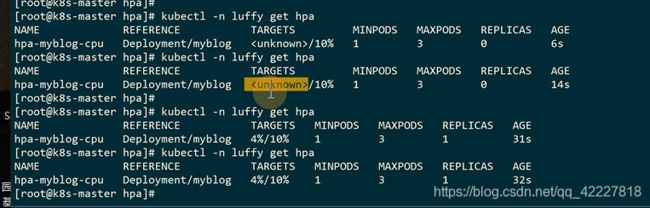
cpu使用率上升,把副本变成3个了
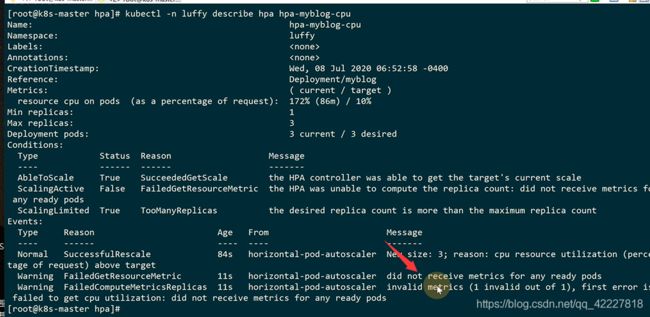
停止压测

pod数还是三个


HPA官方文档
![]()
一个scaledown的事件,需要5分钟的间隔时间

每次缩放是一个,一个间隔5分钟

5.5 基于CPU实现业务的水平扩缩容
5分钟以后开始删除第一个
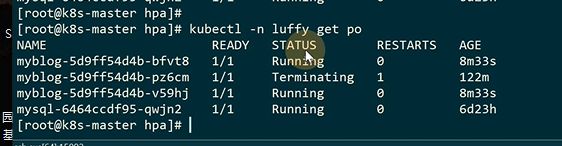
apiserver,v1只支持基于cpu的,v2支持基于内存和自定义指标d
![]()
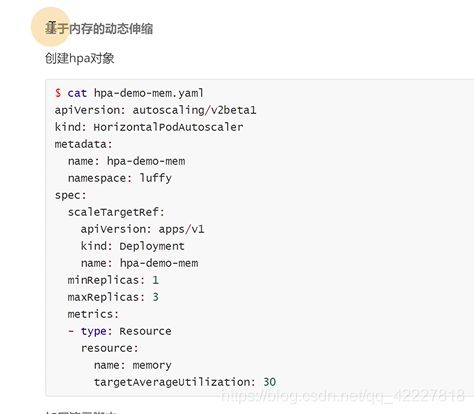
上面是基于内存指标的HPA,下面要求加压
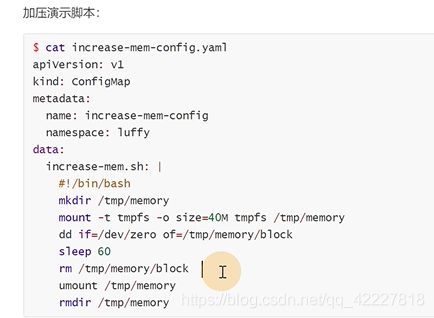
文件名就是一个脚本,去划一个临时的内存系统过去,挂载容器里之后,dd往里面打进去,等于直接写内存数据,但是mount要超级用户权限

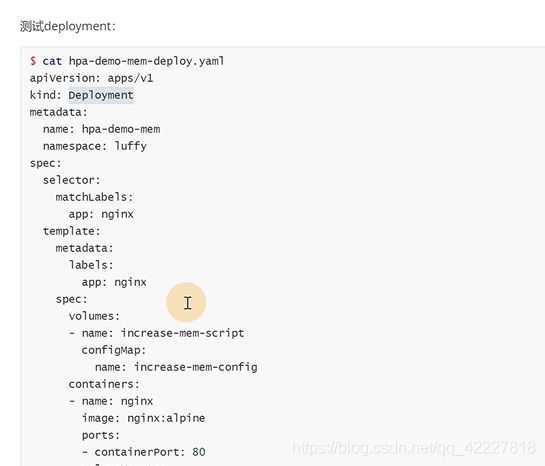
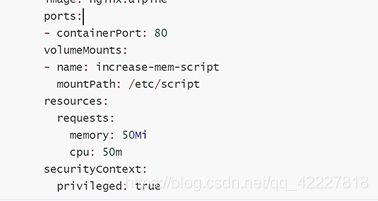
要加一个参数给超级权限
![]()
挂载是用刚才定义的configmap名字定义到volumes里

挂载到这里
先建立deployment再去建立HPA
创建configmap的yam文件
![]()

HPA
![]()

![]()
创建deployment
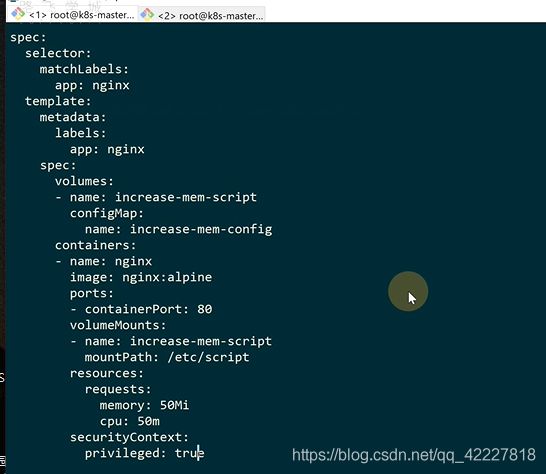
创建是有顺序的,,先创建confgmap,deployment,HPA


已经运行


现在去加压

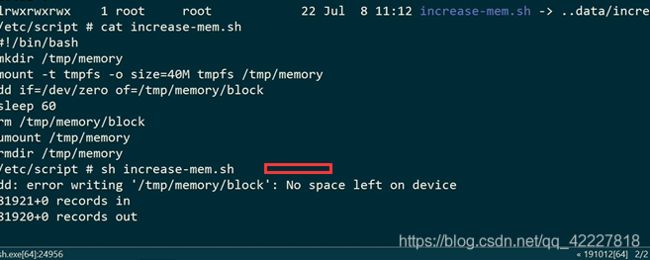
-w持续观察

已经到89%
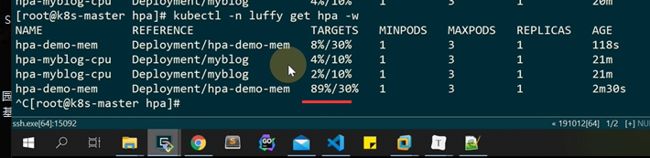
触发了扩容
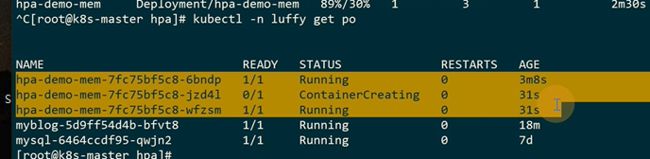
超过阀值做了扩容
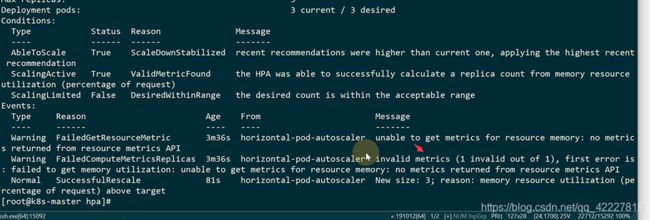
scale down,每一个默认需要5分钟,10个就是50分钟


基于cpu和内存其实是一个通用的实现(通过metric server),自定义的指标需要用到Prometheus adapter,会把数据提供HPA,有点类似metric server的作用
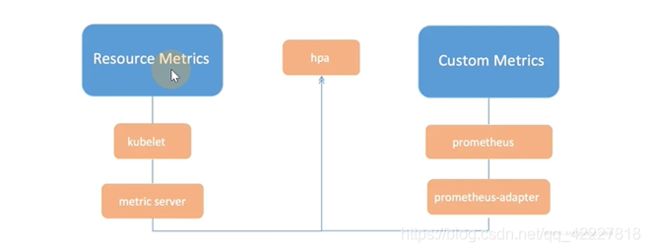
HPA通过metrics 的聚合器,调用metrics-server(到kubelet和cadvisor拿数据),自定义是metrics聚合器到Prometheus adapter拿数据
第6章 PC+PVC对接分布式存储
6.1 pv与pvc快速入门
以前的第一种挂载方式是emptydir
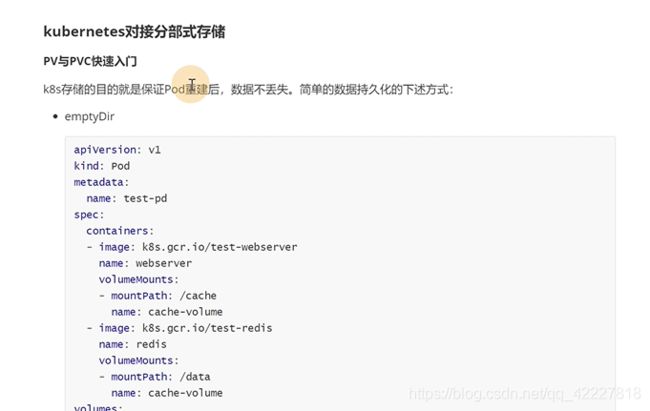
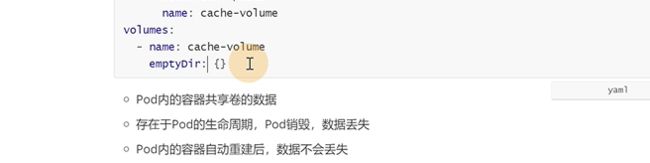
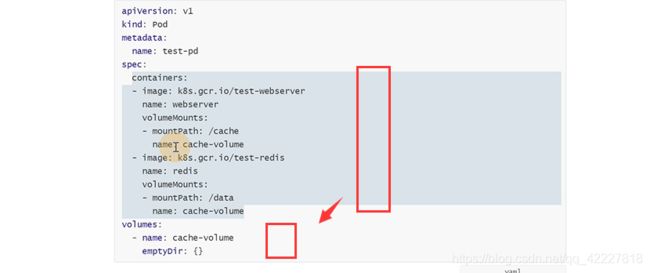
定义了volume以后,pod里所有的容器都可以挂载再这个上,这个pod不挂,数据就丢不掉,但是pod重建了数据就丢失
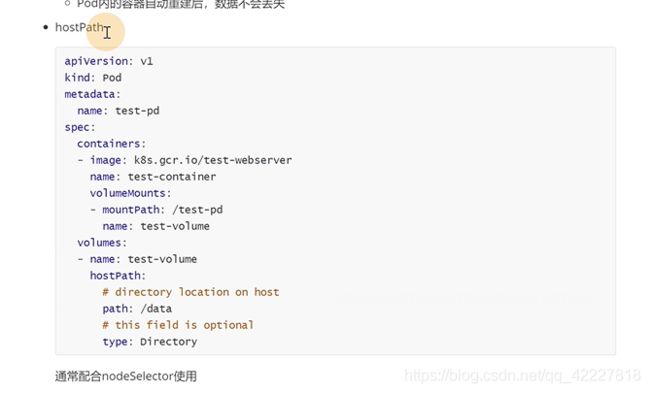
第二种就是hostpath类型,一般配合node-selector做联合使用
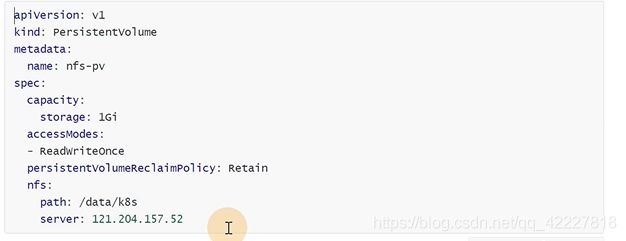
用nfs可以实现不和某台宿主机进行绑定

支持的volumes类型
![]()
K8S引入了PV和PVC屏蔽每种后端 存储的细节

PV persistentvolume持久化卷

现在只支持storage存储空间


访问模式,readwriteonce读写权限只能被单个节点挂载
![]()

cephfs都支持,nfs也都支持
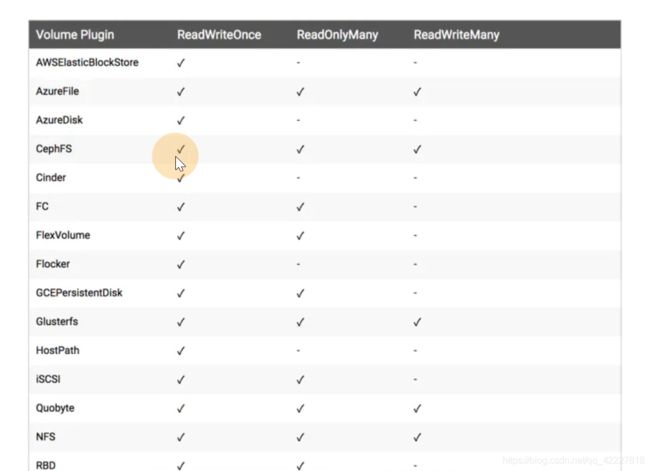
pv的回收策略
![]()

pv删除之后,底层的数据,还不会自动删除,需要手动删除
![]()
删除PV的时候同时把底层数据删除了
![]()
一般用于云厂商,用的比较少
![]()
pv是一个跨namespace的资源
pv是直接对接 底层的存储,node可以为pod提供cpu内存,pv可以为pod提供 存储资源

pvc是持久化卷申明,是一种用户存储的申明,可以和pv实现一对一绑定,对应真正使用的用户不需要关心底层的存储细节 。
它是有一个名称空间概念的
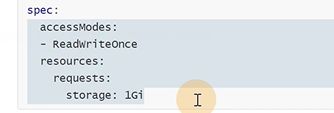
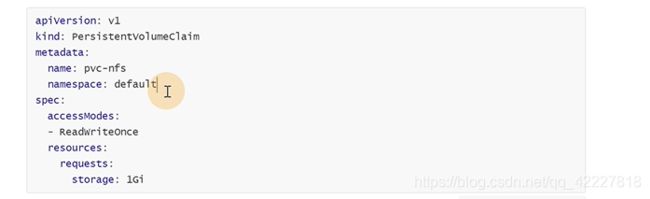 要实现PVC和PV绑定,这里的条件要和PV能对上,如果PVC需要1G,PV的大小只有500M那就匹配不上。accessmode访问模式也需要和PV定义的一致
要实现PVC和PV绑定,这里的条件要和PV能对上,如果PVC需要1G,PV的大小只有500M那就匹配不上。accessmode访问模式也需要和PV定义的一致
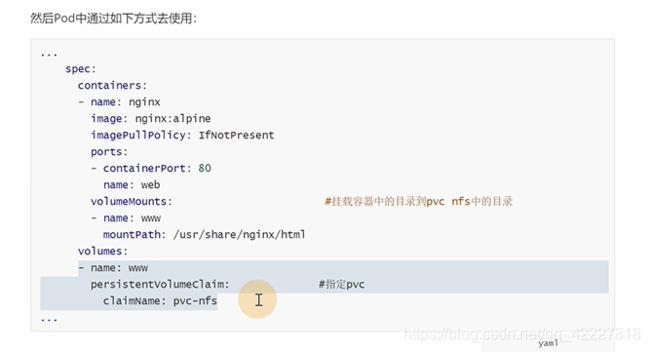
pod里只需要写一个pvc,就不关心底层的实现了

PV的出现就是因为volume有很多,PV和PVC用来给pod屏蔽底层存储的一些实现

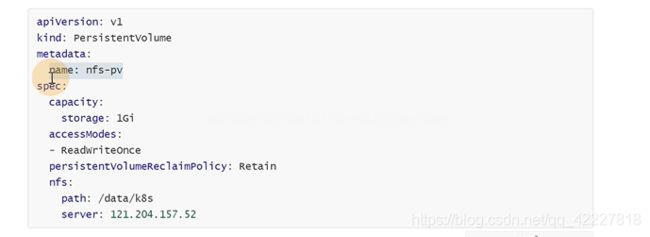
**首先定义一个PV,在PV里直接对接底层的存储 **
匹配的大小和访问模式要匹配后面定义的pvc值,pv是和底层存储打交道,pod是不会直接用pv的

pod是通过pvc里找到pv

pod通过pvc找到pv,就是通过这么 几个条件去匹配

在pod里使用,写法就比较简单了
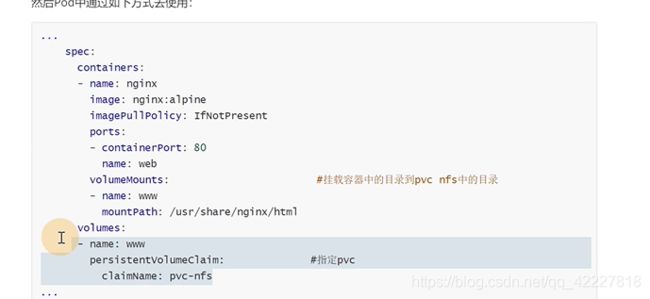
6.2 pv与pvc管理NFS存储实践


创建共享目录,nfs可以挂载这个目录


K8S集群挂载外部的nfs存储

slave1和slave2安装


tuch一个文件试试

server端现在有这个文件

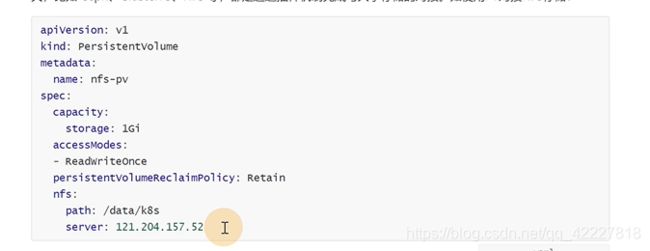
创建PV
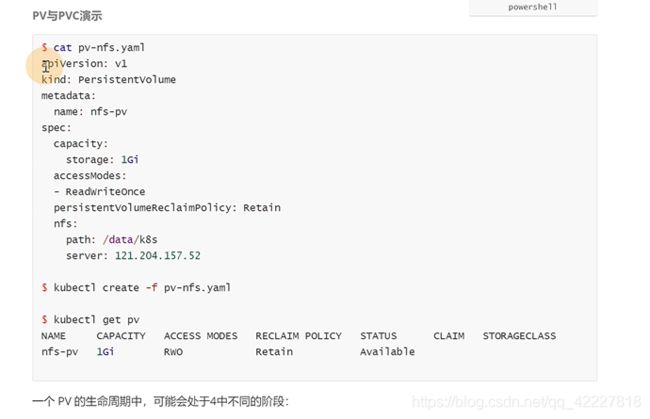
创建pv



整个PV的生命周期

还未被使用,处于单身
![]()
已经被人绑定
![]()
分手了
![]()
找一个男朋友,也就是pvc

访问模式要和之前的匹配
大小要符合



状态变成bound

pv也变成bound


假如先创建pvc



一直是pending,因为之前的已经绑定好了,所以就一直处于pending

有了合适的pv会立马进行绑定

如何挂载在pod里




![]()
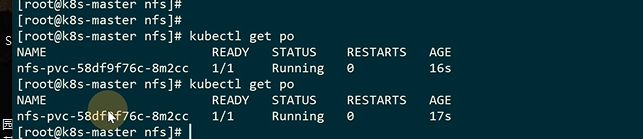
进入容器看到整个文件,说明成功
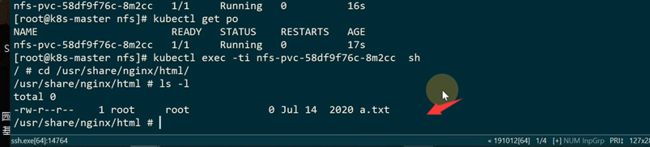

这个pod就是在用nfs存储

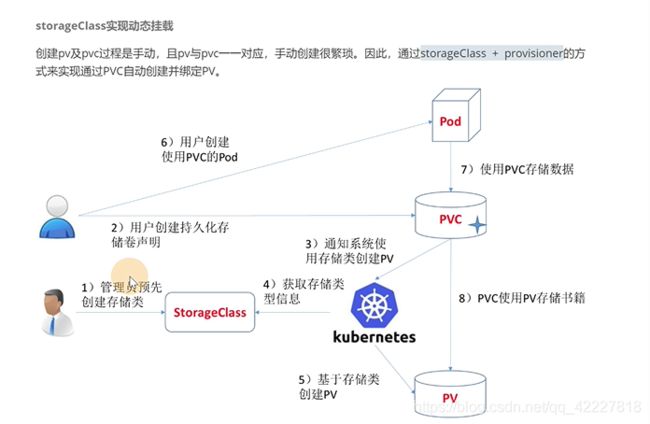
6.3 storageClass实现动态挂载
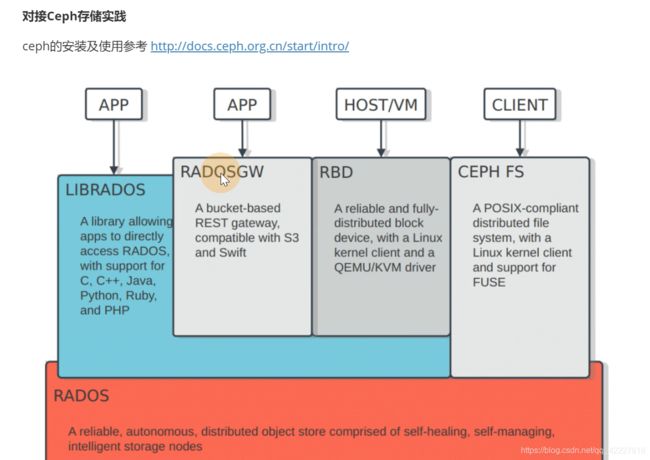 ceph安装比较复杂,但是这里省略,下面是文档,主要针对K8S如何对接ceph
ceph安装比较复杂,但是这里省略,下面是文档,主要针对K8S如何对接ceph

底层的rados,是ceph的底层分配,针对故障的存储恢复
cephfs,类似nfs,可以挂载使用的
rbd模式,效率比cephfs高一些

gateway,实现了cephfs存储的api

用librados的库实现和rados的交互
列出创建的几个pool

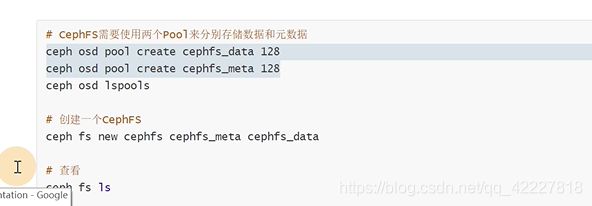
new一个元数据和存储数据的池子

数据存储其实是用cephfs做对接


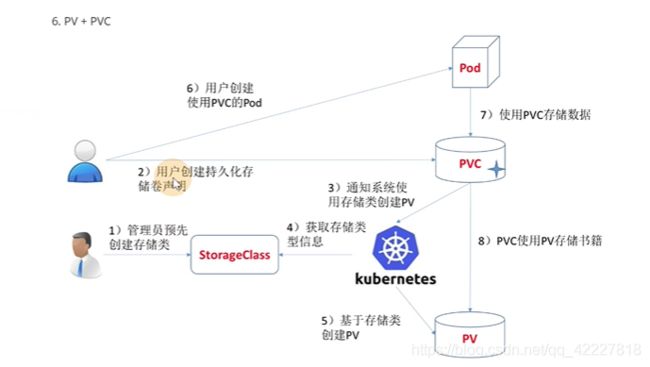
如果每个业务创建pv和pvc是比较繁琐的,通过storageclass+provisioner工商实现pvc自动创建并绑定 pv

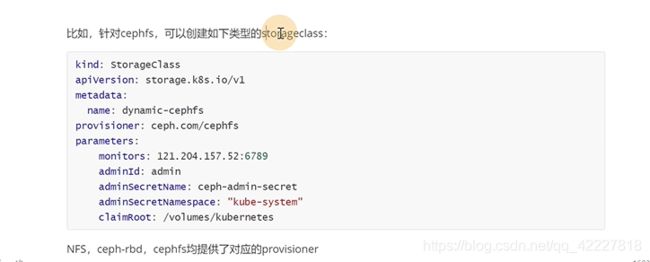
需要让storageclass知道对应的底层存储是哪一个
![]()
这里的参数就是provisioner的参数,通过K8S直接连cephfs,需要知道的参数

1先去创建storageclass
2用户创建pvc,pvc里指定好创建的storageclass
3K8S给pvc去分配的时候,发现没有对应的pv,但是指定了storageclass
4.K8S获取存储类,可以告诉 K8S基于storageclass创建一个pv
5。K8S根据storageclass定义的信息创建一个pv
6,78,就是常规的方式,创建pv,pvc,pod挂载pvc
K8S可以针对不同的存储,可以针对不同的存储创建不同的storageclass

K8S可以针对不同的存储,可以针对不同的存储创建不同的storageclass
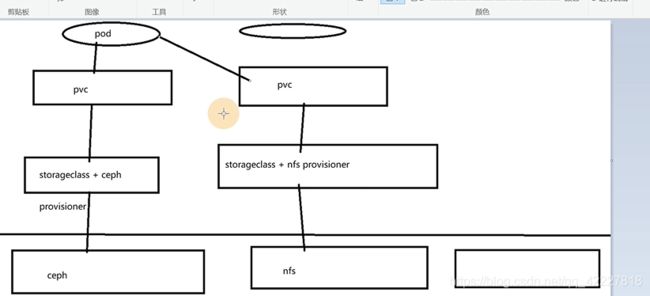
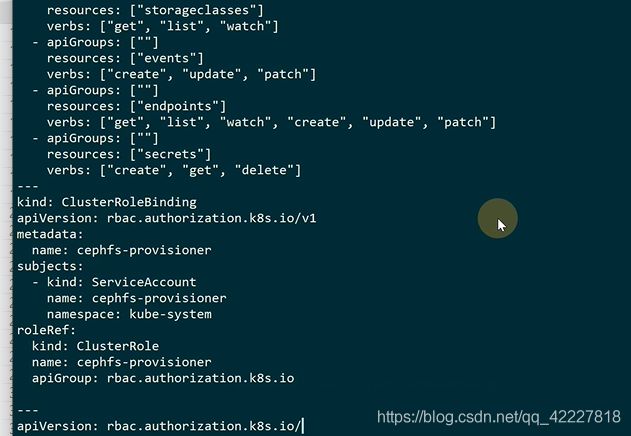
除了cephfs有povisioner,NFS和ceph-rbd都有

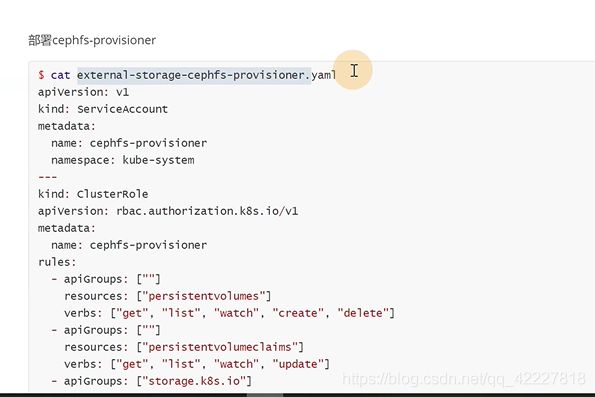
有些K8S并没有做好标准,新出来的存储可以用插件的方式,定义一些rbac的信息,读取K8S的资源

这个镜像就是插件
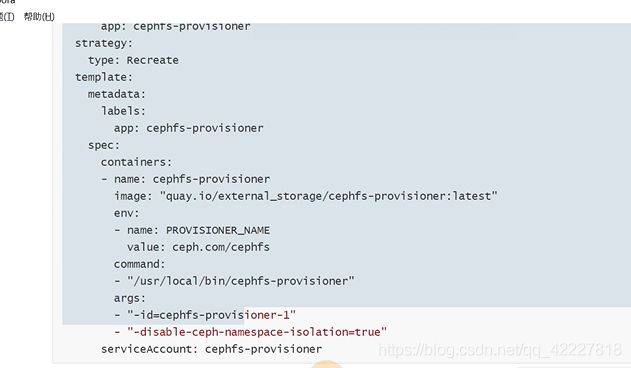
配置的用户信息是放在secret里


cephfs有个admin权限
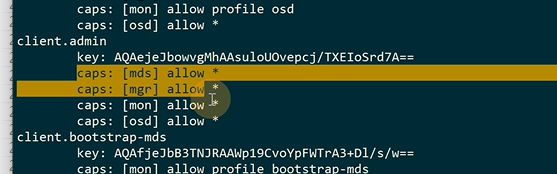
这个就是key

需要创建一个secret文件,但是secret需要做一次base64



创建这个secrect是因为创建deployment的时候会去读这个信息


![]()
![]()
提供者的插件装好了,下面就可以创建storageclass了

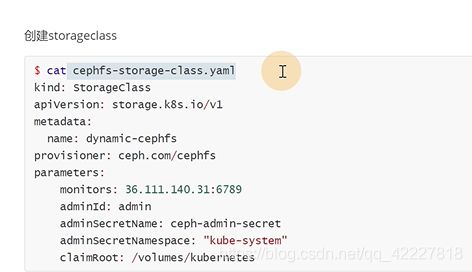
![]()

![]()
storageclass没有命名空间的概念

现在storageclass创建好了,只需要验证pvc调用storageclass信息能不能自动创建pv了

6.4 动态pvc验证ceph存储及实现分析
现在storageclass已经创建好了
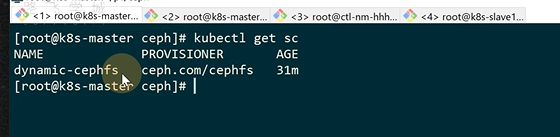
第二步就是创建pvc

指定了之前创建storageclass的名字
![]()
![]()
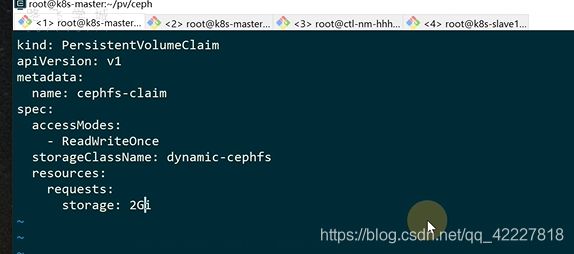

接下来就是K8S根据pvc获取storageclass信息创建pv了

现在已经绑定了

创建的pvc

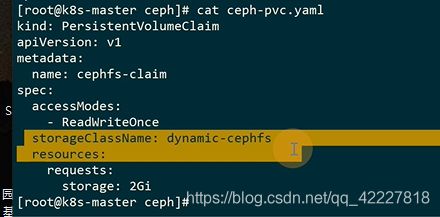

可以创建个pod挂载

![]()
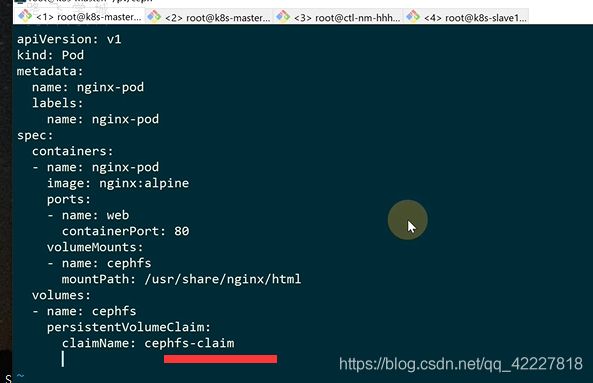
![]()

进入pod已经看到一个cephfs目录

所谓的持久化都是宿主机volume的持久化,因为pod是支持销毁重建的。
整个pod挂载,K8S会创建这样一个路径的volume的目录

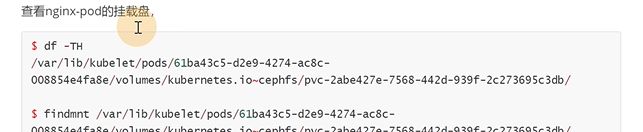

到slave1节点看看,上面是远端地址,下面是本地地址

**K8S创建pod,默认会把使用的serviceaccount所在的token信息挂载进来,每个pod都会有数据,都会区挂载 指定的serviceaccount创建的secret信息,为了和K8Sapi交互用
**
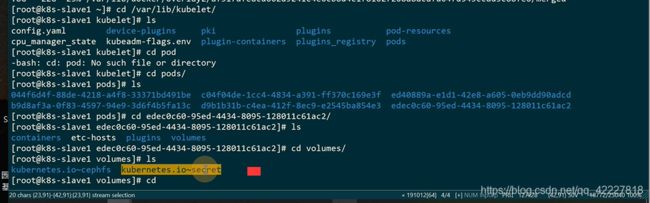

创建一个pvc挂载到挂载点后其实是目录的规范
![]()
查看这个目录的挂载信息


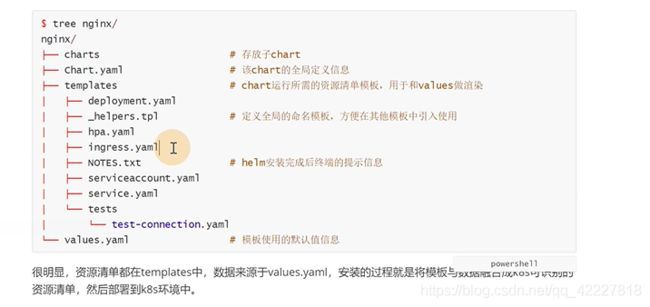
第7章 使用Helm管理复杂业务应用
7.1 认识Helm

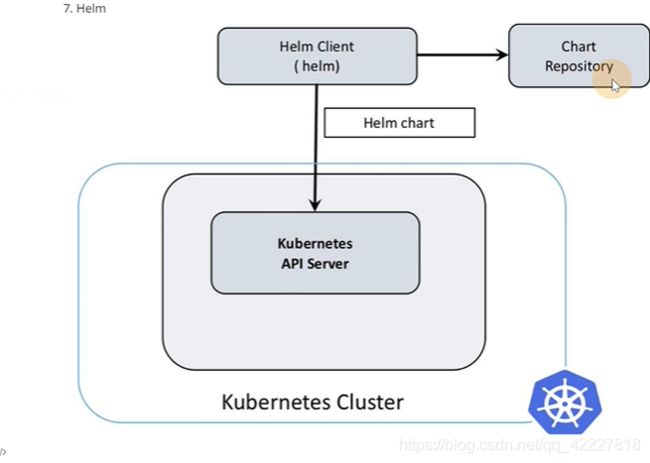
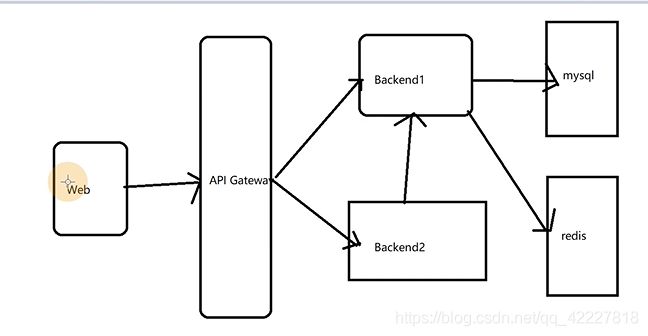
一般的服务架构是这样的,是否可以把一整个架构做为一个产品打一个包,就是helm的一个概念chart,chart其实就是一堆模板,实际部署的时候把值传递给模板,这样就在不同环境部署起来了

有chart的软件仓库


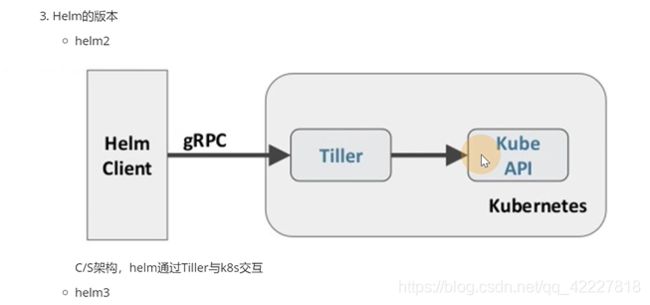
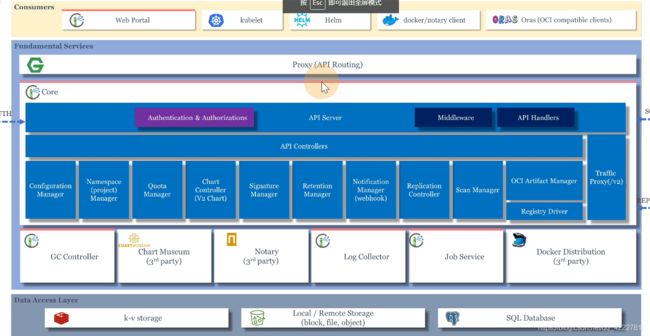
helm2的架构,现在用helm3的比较多,k8S里部署了一个Tiller组件 ,充当server端,调用K8Sapi
helm3多了一个chart仓库,helmclient可以直接和apiserver做交互,这是2banben和3版本的区别


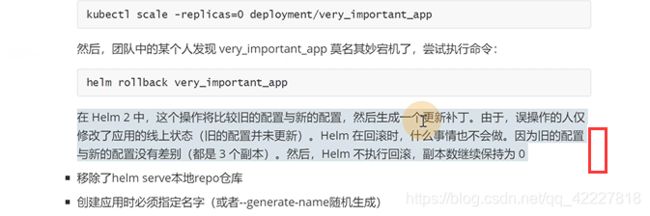
helm2假如直接用kubectl edit是无法回滚的,helm3会对比内容,来达到回滚的作用
chart就像一个镜像一样,镜像部署了就叫一个容器,chart部署了以后叫release

怎么去拉chat,打包chart,把chart直接安装到K8S了

7.2 helm安装与快速入门实践

helm3就需要一个客户端
当前版本是3.2.4

可以看一些环境变量信息
 stable只是一个仓库名字
stable只是一个仓库名字

![]()

去抓取 新仓库里的索引文件
![]()
可以查看这个stable里有哪些包

chartversion是这个chart的version,app version是里面中间件的一个版本


这是一个release名字,将容器起来的名字

描述信息里是这个chart的基本使用

没有指定namespace是在默认的namespacce里,mysql这个应用打包了一个service和deployment,replicaset


helm在安装的时候可以设定一些参数
创建一个chart

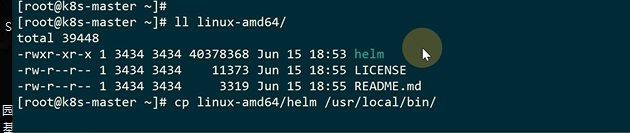
这就是刚创建的一个nginx的chart
本地有这个chart也可以直接install这个目录

已经在运行了


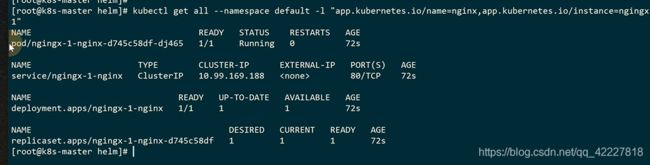
过滤一下nginx的数据

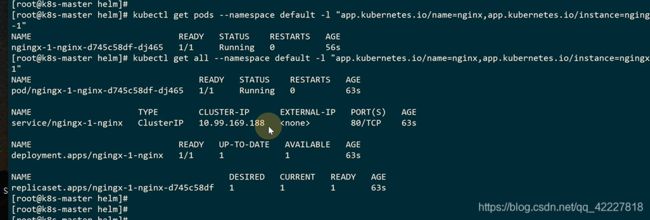
这是创建的nginx的chart

两种基本使用chart的方式,一种是在仓库里,
第二种是本地知道的时候,可以通过create,根据需要改里面的东西,改完之后进行一个安装测试
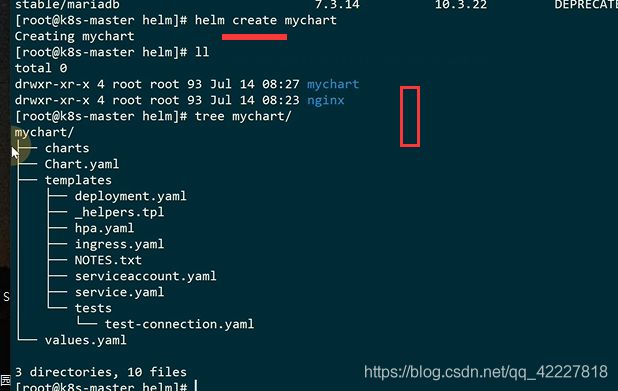
7.3 chart模板语法及开发
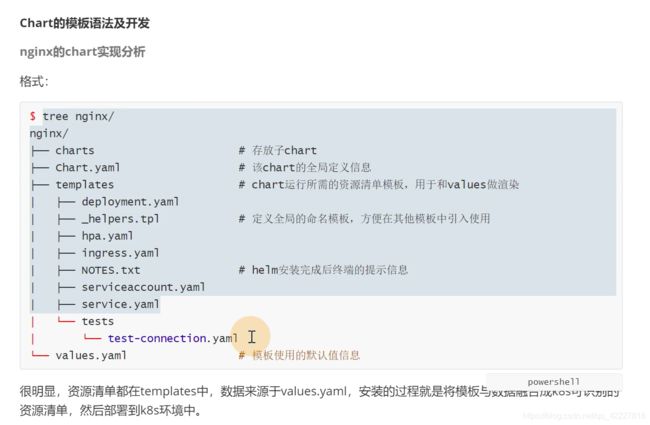
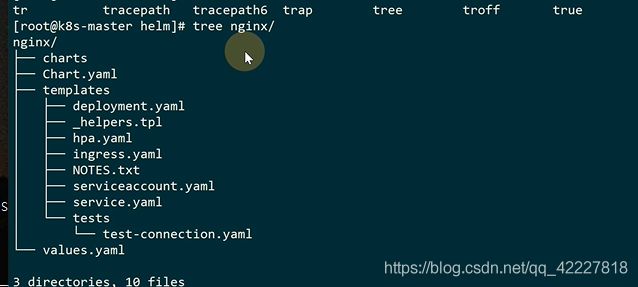
如果chart依赖其他chart,可以在这个目录里生成
![]()
全局定义的一些信息
![]()
模板就是整个K8S里的一些清单文件

安装后打印的提示信息
![]()
安装完成后的一些test方法,检验一下chart安装是否成功
![]()
有些值需要和模板进行融合,这个也是执行配置更换的一个入口
![]()


chart类似一个小 项目,可以打开这个项目看看
![]()
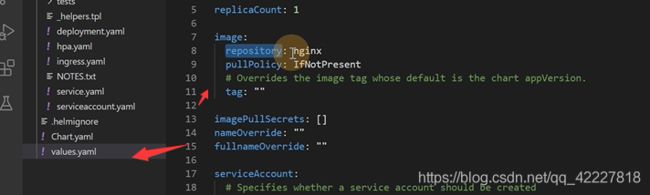
values是默认的值
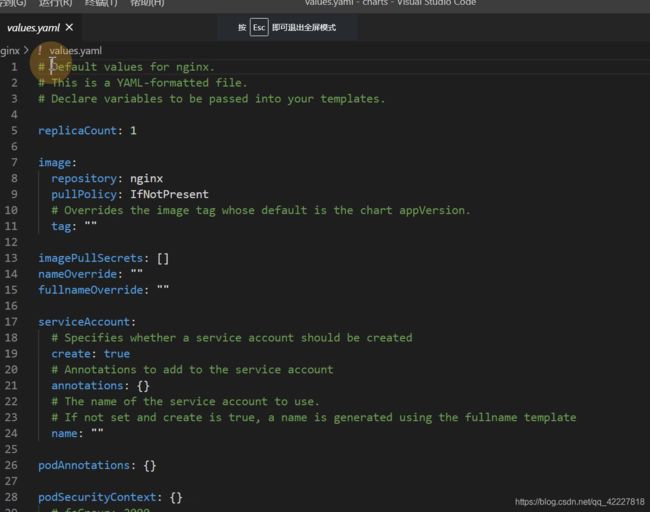



默认的nginx副本数

给这个image用的默认tag,就是nginx:latest

注解,安全性

创建的service类型和端口
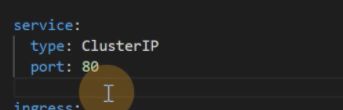
如果是false,就是helm安装的部署的时候不会装ingress


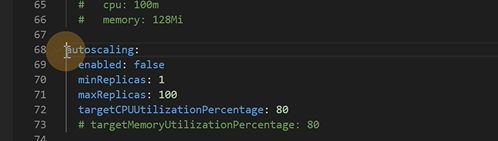
resource就是限制资源

HPA,CPU百分之80就扩容

![]()
chart.yaml是定义的全局信息

chart的version

nginx的一个版本

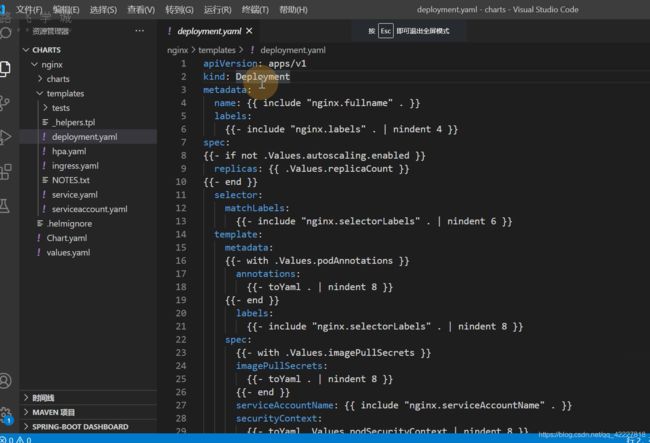
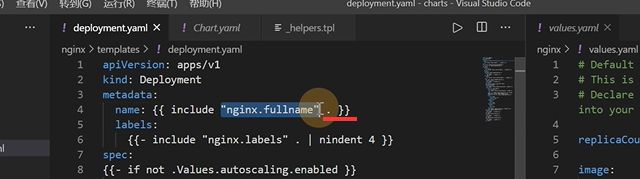
看一下deployment,{ {}}两个大括号其实就是一个GO语言的模板
这里values定义好了值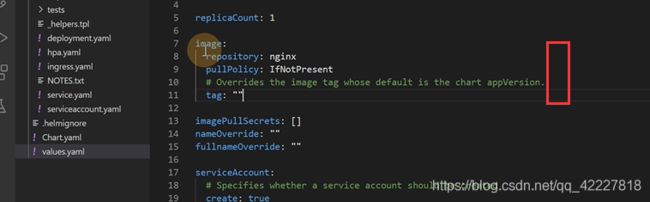
.Values,这个.点号就是最大的作用域,tag里如果没有就用appversion

.点号等于找这个yaml里的整个对象
include就是包含,从模板里引用

模板就是从这里来,不是yaml就不会被K8S当作一个资源

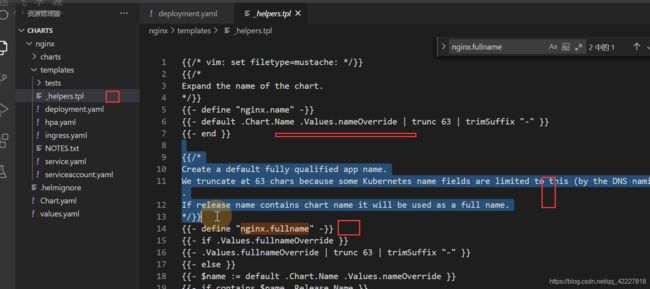
定义一个模板就nginx.fullname,nginx全量名称
 】
】![]()
如果设置了这个
 trunc 63最多63个字符,trimsuffix去掉文件后缀的一个 方法
trunc 63最多63个字符,trimsuffix去掉文件后缀的一个 方法
![]()
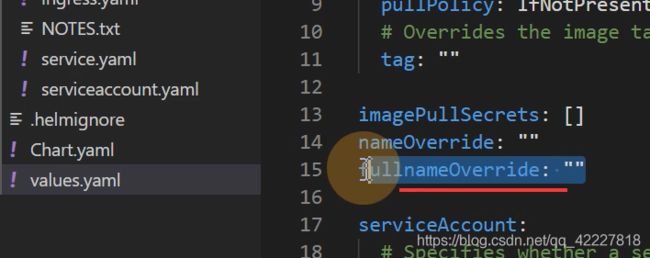
$符号定义一个局部变量,如果nameoverride没定义就会变成chart.name

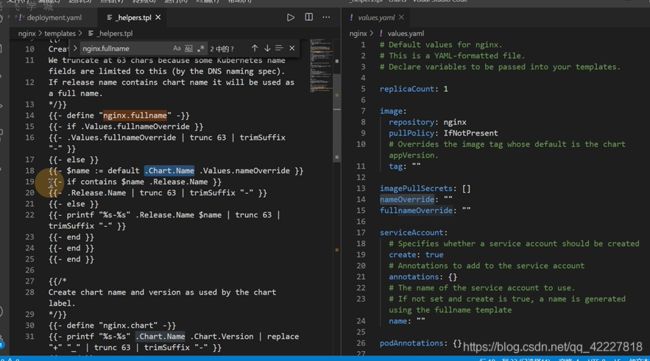
如果release的名字包含了这个名字,就进行去除字符

通过开关性质的来隐藏
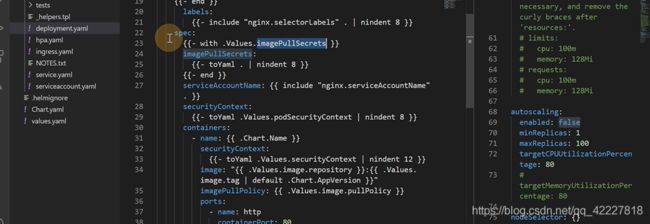
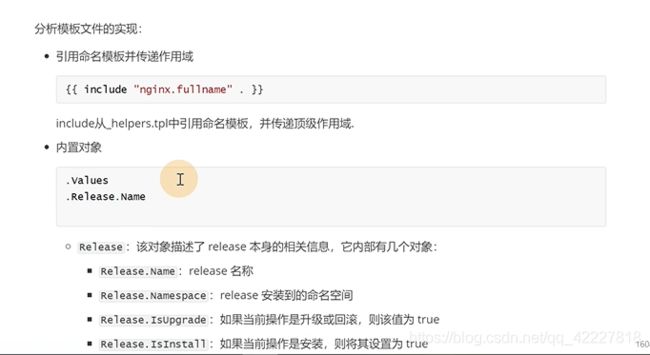
.点号就是跟作用域
values可以拿到所有的变量,release.name可以拿到创建的名字



去掉左边的空格和换行

中甲有个换行一般再{ {}}后面bianchneg { { -}}

前面保留6个空格就满足yanml规范了



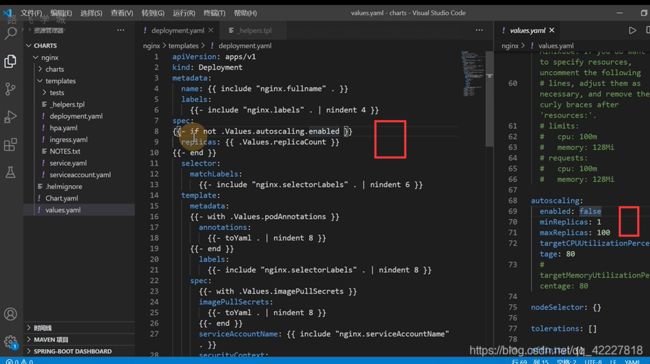
控制整个开关,是否显示字段


toyaml就是为了符合yaml写法


大的if,如果有就有内容,没有就没有内容

chart需要有一定的基础才能去使用
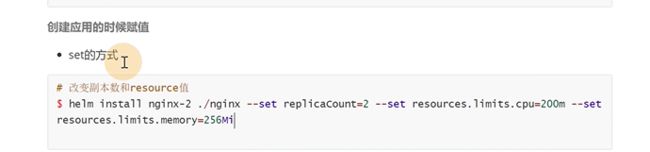
7.4 定制chart的方式
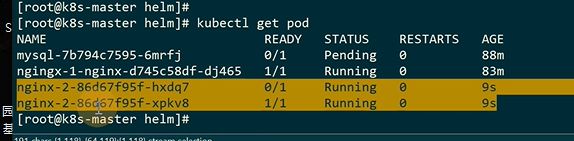
创建helm的时候赋值上,让它变成一个定制的,每一个赋值都需要–set

也可以不通过–set去覆盖,可以创建一个value的yaml文件去做
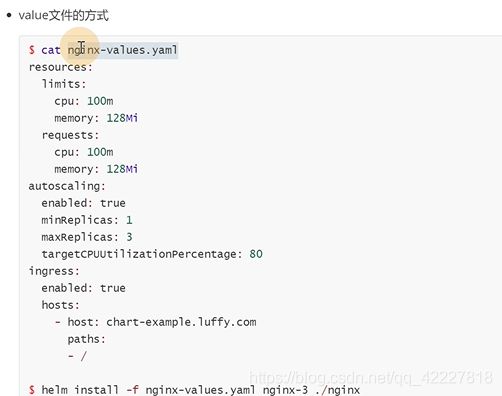
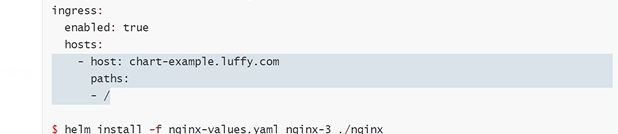
这里path做了一个循环



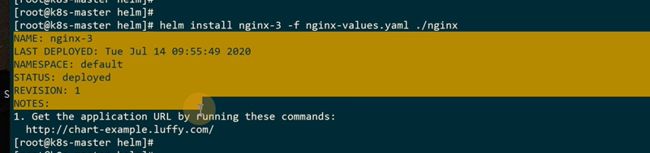
ingress地址都打印出来了
![]()

转发的地址
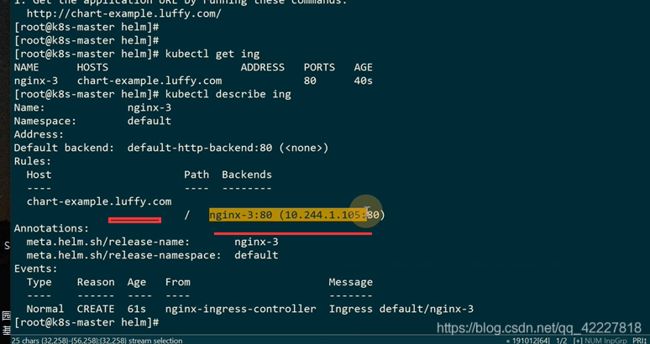
chart生成了一个HPA

配置以恶hosts


删除chart也很简单
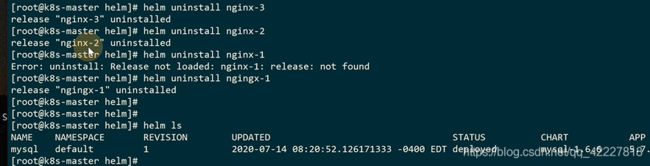
现在就访问不到了

只要是通过helm起的资源,都会被删除


可以搜索mysql

解压一下

也是一个chart模板
7.5 harbor架构介绍及chart参数设置
harbor可以用作镜像和helm仓库的
 core去提供服务
core去提供服务
项目的存户空间,有多少可以存储,配额管理

harbor和多个仓库间去同步任务



![]()
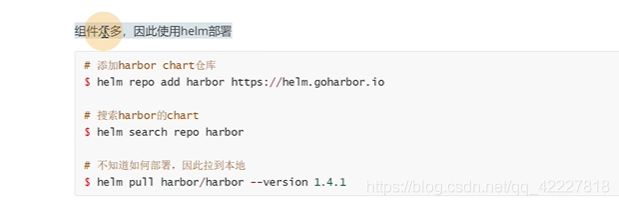
添加一个harbor源

查找一下harbor

pull到本地
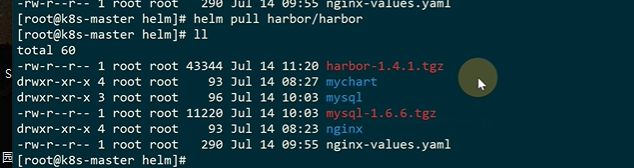

解压到本地,看看chart的实现

开启一个ingress

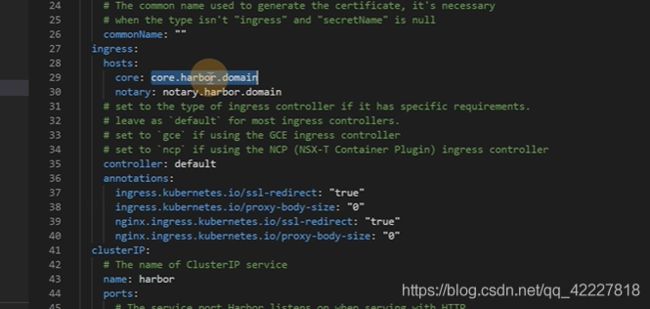
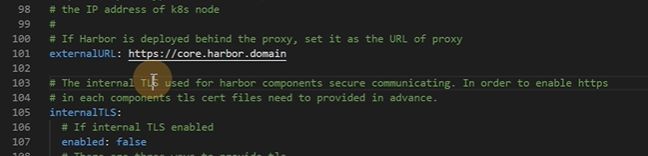
内部组件使用 的一些证书可以先不管

创建一个storageclass可以自动创建pv
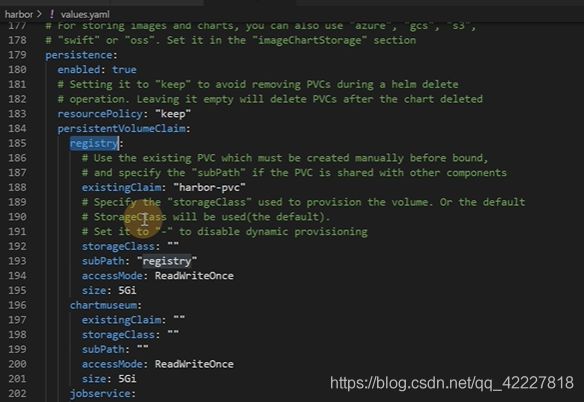

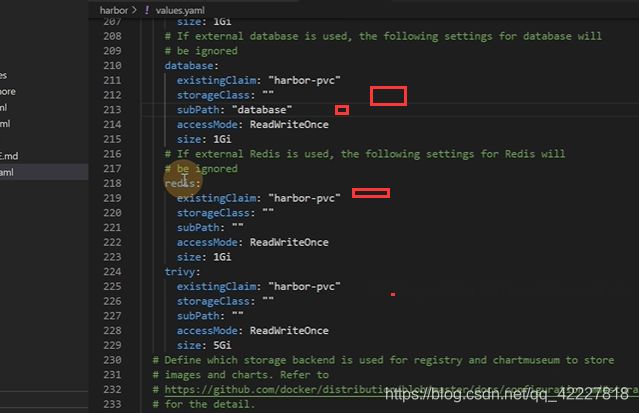
根据同一个存储,不同的子目录来建立持久化存储
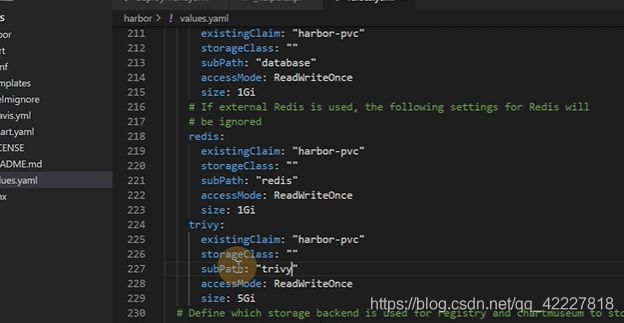
容器内部,可以选择什么文件系统

需要proxy代理的一些组件
这些不是核心的服务,就留给你可以控制是否开启的权限

7.6 harbor踩坑部署
 粘贴过来
粘贴过来

现在的values.yaml是改过之后的文件

现在需要创建一个叫harbor-pvc的pvc
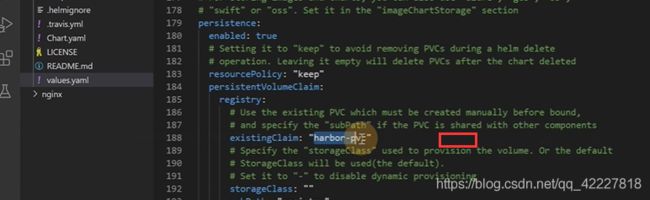
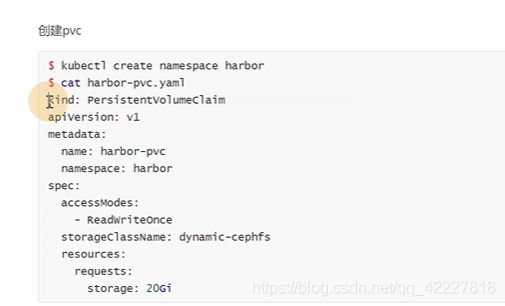
可以直接用创建好的storageclass

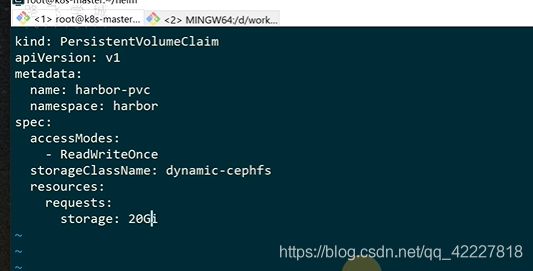
创建一个名称空间,再创建pvc


这样PV就自动创建好了

指定 目录,名称空间


这是ingress

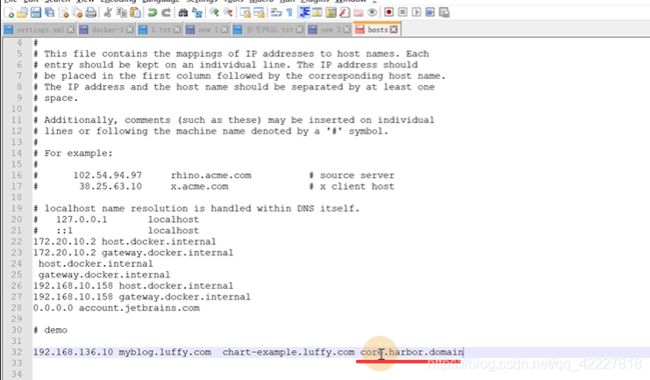

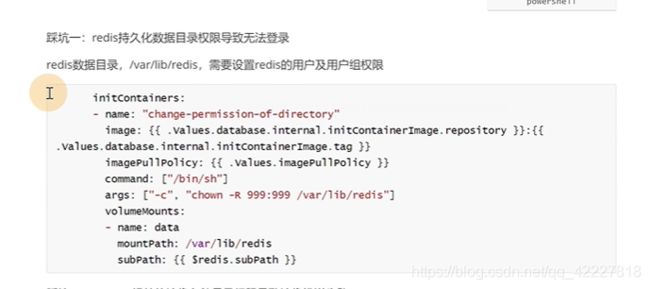
默认的用户 是redis,但是目录是 root用户,写的时候肯定写不进去,这是给的一个坑
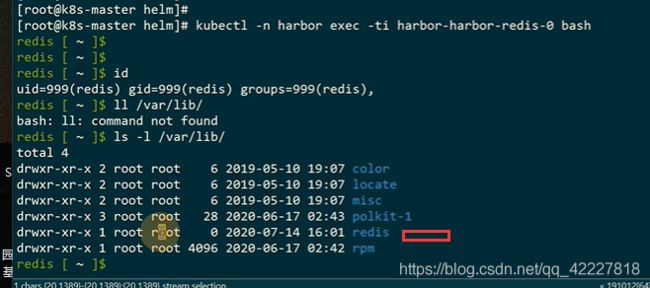
postgres可以写

initcontainer里可以做对用户授权下操作的
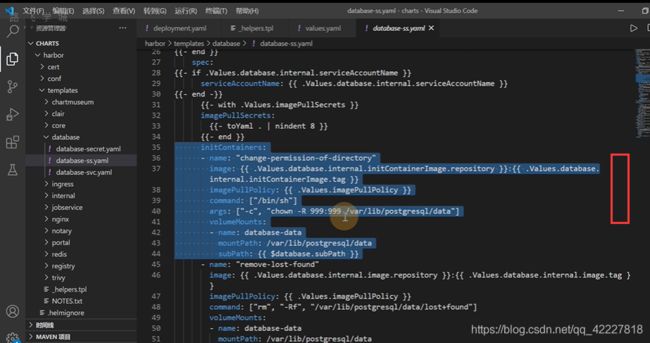
这里是镜像
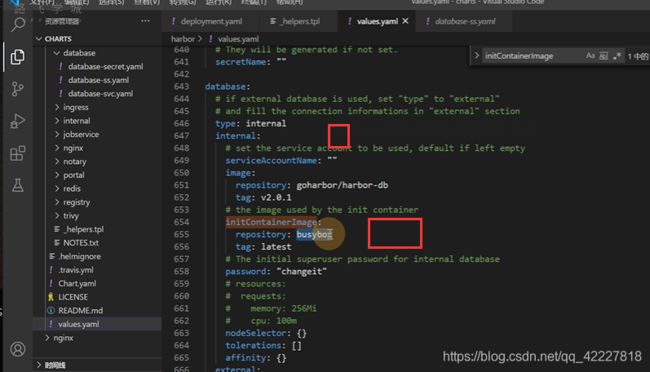
这里做了挂载和修改权限

redis没有初始化容器,少了给目录授权的操作
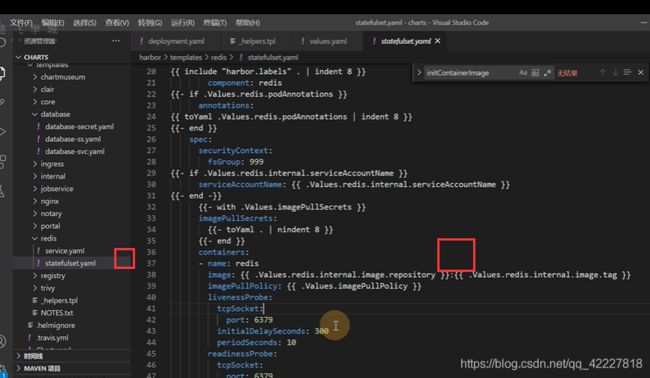
修改一下
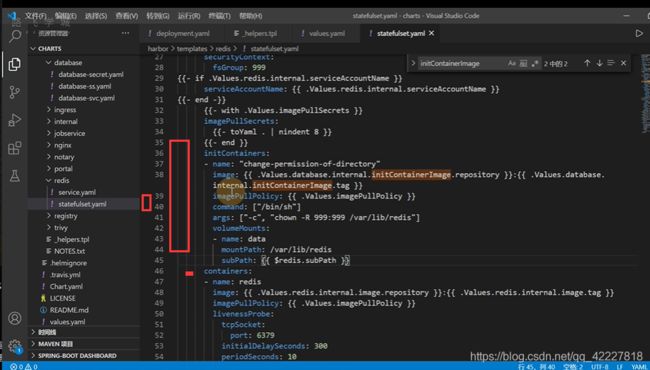

storage也是root存在写不进来的权限
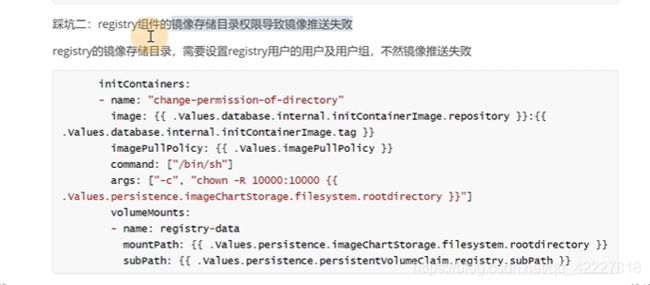
修改yaml文件

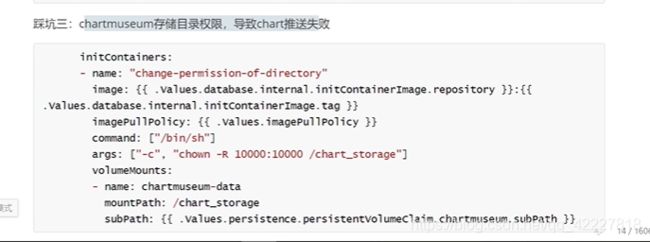
chartmuseum也是一样



还有registry文件
![]()



更新一下


现在就是redis

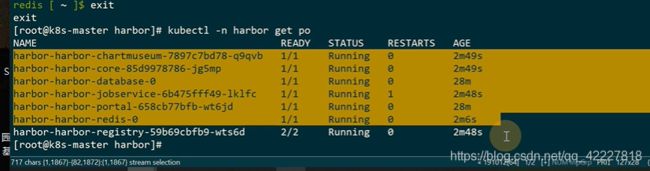
7.7 harbor的镜像管理

![]()
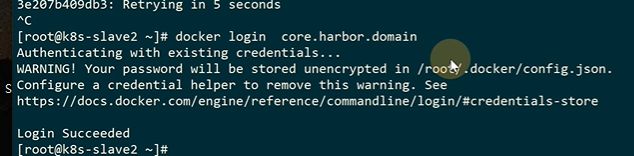

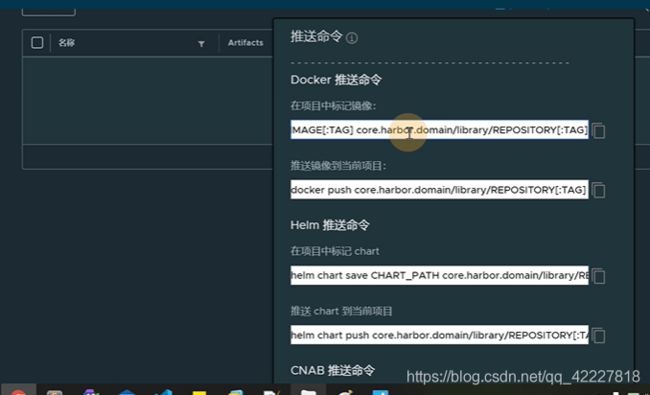
7.8 推送chart到harbor仓库
这个包很大,推荐离线安装

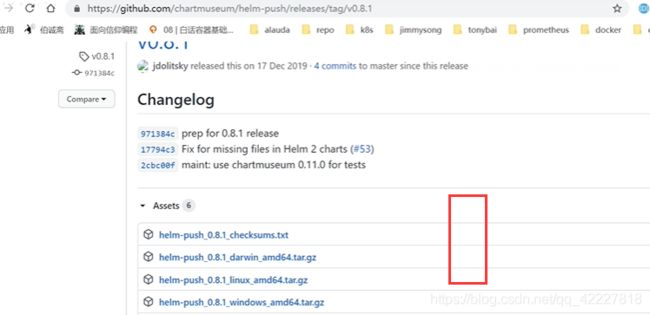
解压文件
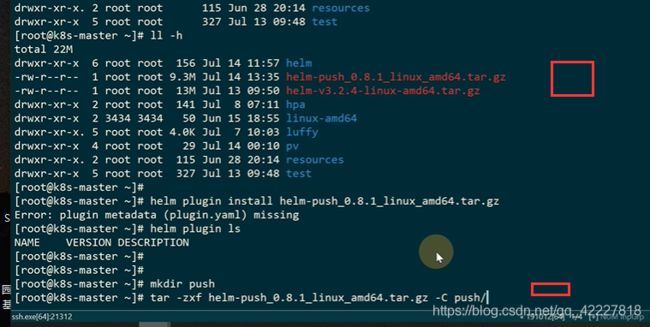
已经读到push插件了
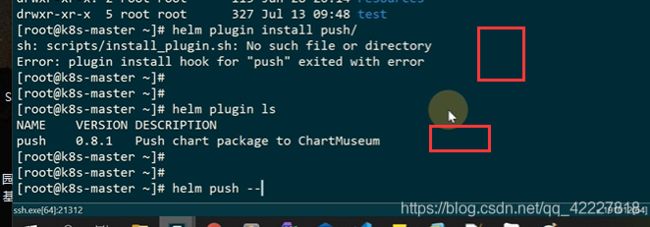
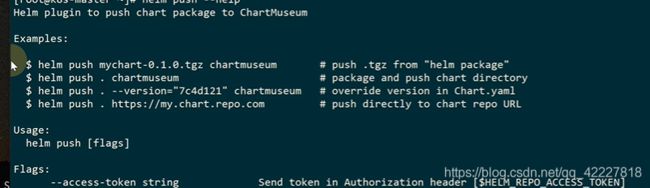

这个目录里就这几个文件

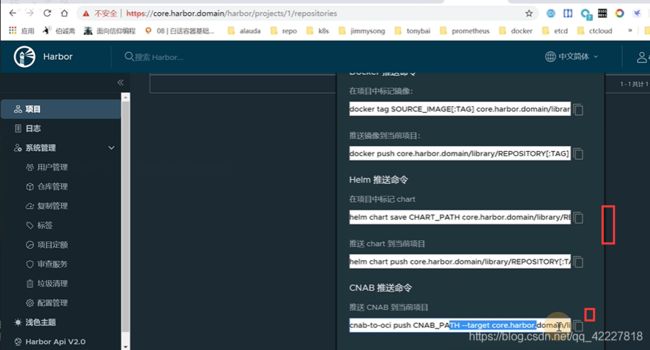

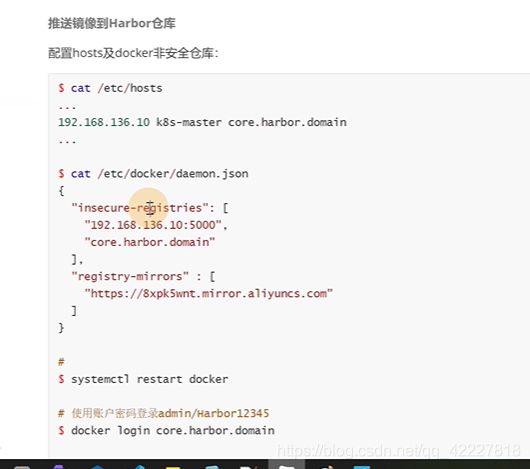
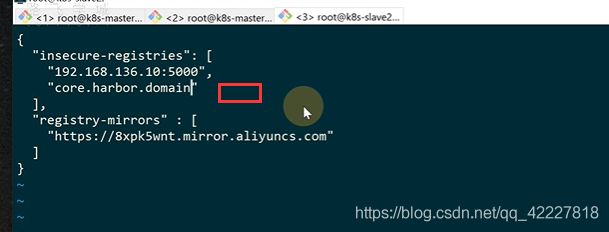
**添加仓库。自签名的证书不支持
**

找到harbor的证书,再secret里,ingress的https证书
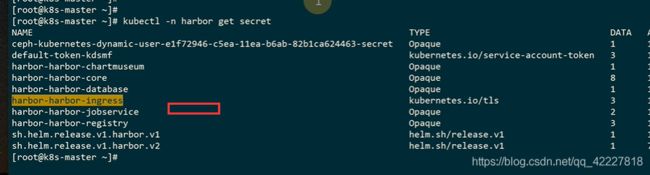
证书文件


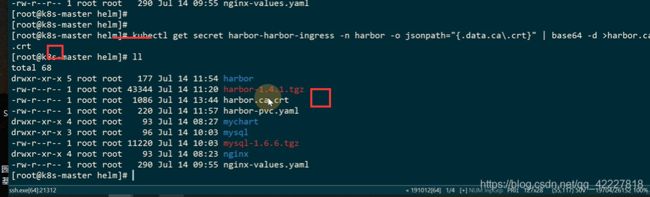
如何去信任证书
拷贝到信任证书的目录,update-ca-trust就会把证书放到信任证书列表里



地址添加成功了

push到仓库里

可以识别一个helm的帮助信息

第8章 小结
8.1 小结

flannel的vxlan模式对集群的网络要求最低