动手学深度学习实践—文献阅读
文章目录
- 一. 动手学深度学习实践
-
- 1.1 Bi-RNN
- 1.2 编码器-解码器结构
- 1.3 使用API实现 (encoder-decoder)
- 1.4 序列到序列学习(seq2seq)
- 二. 文献阅读— A dual-head attention model for time series data imputation
-
- 2.1 摘要
- 2.2 问题描述
- 2.3 模型设计
- 2.4 评估标准
- 2.5 实验特点
一. 动手学深度学习实践
1.1 Bi-RNN
如果我们希望在循环神经网络中拥有一种机制,使之能够具有前瞻能力,我们就需要修改循环神经网络的设计。只需要增加一个从最后一个词元开始从后向前运行的循环神经网络,而不是只有一个在前向模式下从第一个词元开始运行的循环神经网络。 双向循环神经网络(bidirectional RNNs)添加了反向传递信息的隐藏层,以便更灵活地处理此类信息。 下图描述了具有单个隐藏层的双向循环神经网络的结构。
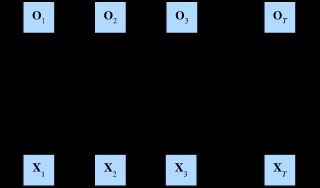
对于任意时间步 t t t,给定一个小批量的输入数据 X t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d} Xt∈Rn×d(样本数: n n n,每个示例中的输入数: d d d),并且令隐藏层激活函数为 ϕ \phi ϕ。在双向结构中,我们设该时间步的前向和反向隐藏状态分别为 H → t ∈ R n × h \overrightarrow{\mathbf{H}}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h 和 H ← t ∈ R n × h \overleftarrow{\mathbf{H}}_t \in \mathbb{R}^{n \times h} Ht∈Rn×h,其中 h h h 是隐藏单元的数目。前向和反向隐藏状态的更新如下:
H → t = ϕ ( X t W x h ( f ) + H → t − 1 W h h ( f ) + b h ( f ) ) , H ← t = ϕ ( X t W x h ( b ) + H ← t + 1 W h h ( b ) + b h ( b ) ) , \begin{aligned} \overrightarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(f)} + \overrightarrow{\mathbf{H}}_{t-1} \mathbf{W}_{hh}^{(f)} + \mathbf{b}_h^{(f)}),\\ \overleftarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(b)} + \overleftarrow{\mathbf{H}}_{t+1} \mathbf{W}_{hh}^{(b)} + \mathbf{b}_h^{(b)}), \end{aligned} HtHt=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f)),=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b)),
其中,权重 W x h ( f ) ∈ R d × h , W h h ( f ) ∈ R h × h , W x h ( b ) ∈ R d × h , W h h ( b ) ∈ R h × h \mathbf{W}_{xh}^{(f)} \in \mathbb{R}^{d \times h}, \mathbf{W}_{hh}^{(f)} \in \mathbb{R}^{h \times h}, \mathbf{W}_{xh}^{(b)} \in \mathbb{R}^{d \times h}, \mathbf{W}_{hh}^{(b)} \in \mathbb{R}^{h \times h} Wxh(f)∈Rd×h,Whh(f)∈Rh×h,Wxh(b)∈Rd×h,Whh(b)∈Rh×h 和偏置 b h ( f ) ∈ R 1 × h , b h ( b ) ∈ R 1 × h \mathbf{b}_h^{(f)} \in \mathbb{R}^{1 \times h}, \mathbf{b}_h^{(b)} \in \mathbb{R}^{1 \times h} bh(f)∈R1×h,bh(b)∈R1×h 都是模型参数。
接下来,将前向隐藏状态 H → t \overrightarrow{\mathbf{H}}_t Ht 和反向隐藏状态 H ← t \overleftarrow{\mathbf{H}}_t Ht ,拼接进行,获得需要送入输出层的隐藏状态 H t ∈ R n × 2 h \mathbf{H}_t \in \mathbb{R}^{n \times 2h} Ht∈Rn×2h。在具有多个隐藏层的深度双向循环神经网络中,该信息作为输入传递到下一个双向层。最后,输出层计算得到的输出为 O t ∈ R n × q \mathbf{O}_t \in \mathbb{R}^{n \times q} Ot∈Rn×q( q q q 是输出单元的数目):
O t = H t W h q + b q . \mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q. Ot=HtWhq+bq.
这里,权重矩阵 W h q ∈ R 2 h × q \mathbf{W}_{hq} \in \mathbb{R}^{2h \times q} Whq∈R2h×q 和偏置 b q ∈ R 1 × q \mathbf{b}_q \in \mathbb{R}^{1 \times q} bq∈R1×q 是输出层的模型参数。事实上,这两个方向可以拥有不同数量的隐藏单元。
小结
- 双向循环神经网络通过反向更新隐藏层,来利用反时间方向的信息。
- 通常是对序列做特征提取,填空,而不是预测未来。
1.2 编码器-解码器结构
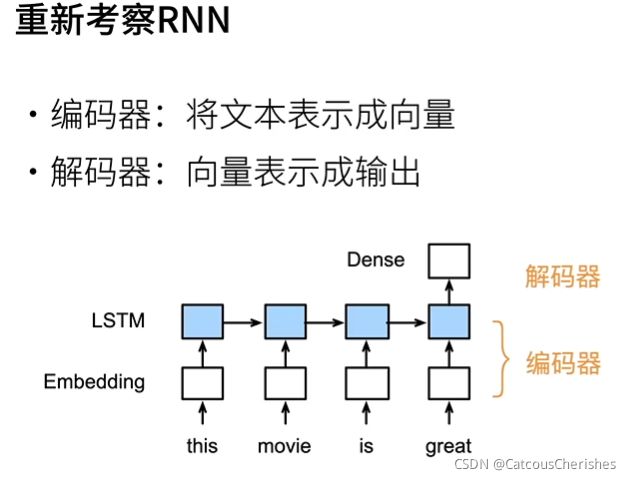
机器翻译是序列转换模型的一个核心问题,其输入和输出都是长度可变的序列。为了处理这种类型的输入和输出,我们可以设计一个包含两个主要组件的结构。第一个组件是一个 编码器(encoder):它接受一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。第二个组件是 解码器(decoder):它将固定形状的编码状态映射到长度可变的序列。
图中是一个更普遍的编码-解码器(Decoder也加上一个input )

小结:使用编码器-解码器架构模型,编码器负责表示输入,解码器负责表示输出。
1.3 使用API实现 (encoder-decoder)
(编码器)
在编码器接口中,我们只指定长度可变的序列作为编码器的输入 X。任何继承这个 Encoder 基类的模型将完成代码实现。
from torch import nn
#@save
class Encoder(nn.Module):
"""编码器-解码器结构的基本编码器接口。"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
(解码器)
解码器接口中,新增一个 init_state 函数用于将编码器的输出(enc_outputs)转换为编码后的状态。注意,此步骤可能需要额外的输入,(例如:输入序列的有效长度)。为了逐个地生成长度可变的词元序列,解码器在每个时间步都会将输入(例如:在前一时间步生成的词元)和编码后的状态映射成当前时间步的输出词元。
#@save
class Decoder(nn.Module):
"""编码器-解码器结构的基本解码器接口。"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
[合并编码器和解码器]
最后,“编码器-解码器”结构包含了一个编码器和一个解码器,并且还拥有可选的额外的参数。在前向传播中,编码器的输出用于生成编码状态,这个状态又被解码器作为其输入的一部分。
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器结构的基类。"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
在下节中,将学习如何应用循环神经网络,来设计基于“编码器-解码器”结构的序列转换模型。
1.4 序列到序列学习(seq2seq)
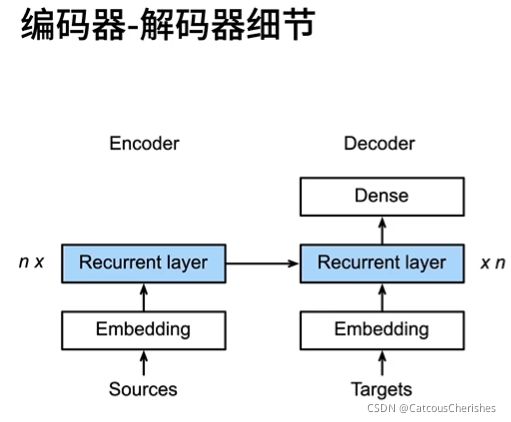
seq2seq最早就是用在机器翻译上的,在机器翻译中的输入序列和输出序列都是长度可变的。 为了解决这类问题,设计了一个通用的”编码器-解码器“结构。


编码器在大多数情况下,是会搞成双向的;但解码器不行,由于它不能看到全局。
其中,特定的eos表示序列结束词元。 一旦输出序列生成此词元,模型就可以停止执行预测。 在循环神经网络解码器的初始化时间步,有两个特定的设计决定。 首先,特定的bos表示序列开始词元,它是解码器的输入序列的第一个词元。 其次,使用循环神经网络编码器最终的隐藏状态来初始化解码器的隐藏状态。

二. 文献阅读— A dual-head attention model for time series data imputation
2.1 摘要
数字农业越来越依赖于从各种传感器收集的测量数据的可用性和准确性。在这些数据中,水质因其用于作物灌溉、牲畜和其他农业活动而备受关注。准确可靠的水质测量使农民能够全面了解景观,优化资源利用,减少农业对环境的负面影响。在实践中,缺失和不完整的数据可能造成有偏见的估计,并降低数字农业提供的许多有价值应用的效率。本文的目的是提出一种双头序列到序列插补模型(dual-SSIM),用于插补传感器网络中缺失的时间序列数据,从而减少数据缺失和不完整的负面后果。与标准序列到序列结构不同,双SSIM模型具有两个带门控循环单元(GRU)的编码器,用于分别处理缺失间隙前后的时间信息。此外,注意机制同时应用于两个编码器输出,以便在估计缺失数据时,模型能够关注高相对输入。双SSIM的性能效能已通过水质监测进行了调查,该监测来源于澳大利亚水质信息系统。本次调查的实验结果表明,双SSIM在输入两个不同水质变量方面优于基于平均绝对误差(MAE)、均方根误差(RMSE)和动态时间扭曲(DTW)分数的相关备选方案。因此,可以得出结论,双重SSIM为水质数据插补提供了一种有效且有希望的方法。
文章结构:
- 论文背景与研究综述,通过传统的研究到深层神经网络,时间序列,到序列—序列,引入提出双头序列到序列插补模型(dual-SSIM)。
- 描述多步骤数据插补问题和挑战。
- .介绍了双头序列到序列插补模型。
- 实验结果。
- 全文进行总结。
2.2 问题描述
多步骤插补问题的说明:虚点表示时间序列中缺少的数据。缺失缺口两侧都有可用数据。p、k和q分别表示间隙左侧、缺失数据间隙和间隙右侧的数据点数量。
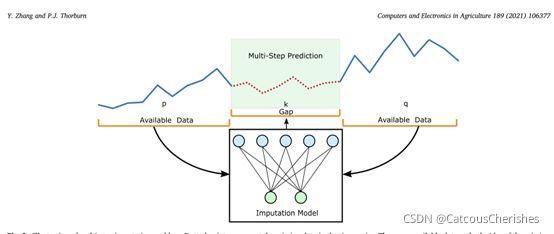
如上图所示,缺失间隙周围的数据包括有价值的信息,以支持预测缺失数据点。让Lavailable和Ravailable表示间隙左侧和右侧的剩余数据,用等式表示:
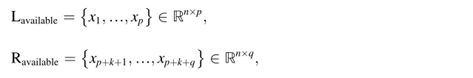
其中p和q表示相应可用时间序列的大小。n表示在每个时间步测量的变量数。
因此,需要一个插补模型来根据所有可用数据预测缺失值。缺失数据M表示:
![]()
将预测模型公式表示为:
![]()
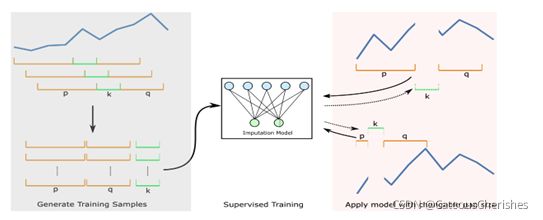
上图是具有可变间隙大小的监督插补模型,左侧描述如何通过滑动窗口去得到监督学习的训练样本,右侧的部分展示了两种不同的填充缺失数据的场景。
数据处理:
预处理:应用了三种数据过滤算法来去除数据流中明显的异常值。阈值过滤器删除了负值和极大值。传感器参考滤波器修复了与传感器相关的测量误差。还应用了一个变化率过滤器,以消除在短时间内有重大变化的测量值。
- 数据标准化
- 利用滑动窗口构建训练样本,测试样本(每个样本包括k个缺失数据作为目标缺口,p个缺口左侧尺寸的可用数据和q个缺口右侧尺寸的可用数据)。
2.3 模型设计
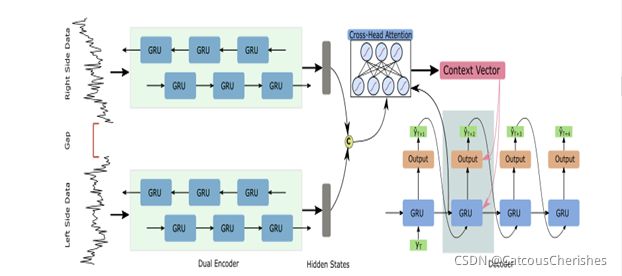
双编码器基于双向GRU。每个编码器负责从间隙的一侧输入数据。两个编码器的隐藏状态由十字头注意力机制模块连接和处理。线性层堆叠在GRU解码器的顶部以生成数值。解码器中的灰色框突出显示解码从编码器传递的信息时的预测步骤。
具体详细的框架设计:
- 双GRU的双编码器
缺口前后的可用信息都有助于插补任务。因此,我们设计了两个编码器分别处理来自间隙两侧的输入信息。选择门控循环单元(GRU)来处理双头编码器中的时间序列输入。每个编码器的输出是一个隐藏状态序列H={h1,h2,…,hn},其中n是输入序列的长度,将两个编码器的隐藏状态concatenated(拼接)。
【GRU是一种特定类型的循环神经网络。与长短时记忆(LSTM)相比,结构简化的GRU在保证神经元记忆能力的同时,可以减少训练参数,加快收敛速度,从而提高预测精度。(双向)在两个方向上对时间信息进行建模可以显著提高循环网络的性能。】
2.交叉头注意解码器( Decoder with cross-head attention)
该模型中使用的注意机制能够从两个编码器处理的输入序列中提取 高相对信息。扩展提出的全局注意模型,并使其支持处理从两个不同编码器学习到的时间表征(下图)。根据上一节,每个编码器都有一系列生成的隐藏状态H。因此,为了利用两个编码器学习到的所有时间表征,我们将这些隐藏状态集中为解码器的新输入:
![]()
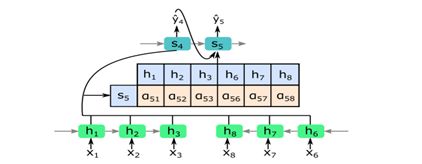
交叉头注意力机制: 该示例显示了注意力模块在估计时间索引 4 和 5 缺失数据时的工作原理。输入数据 {x1,x2,x3} 和 {x6,x7,x8} 分别输入两个编码器。 双编码器学习到的隐藏状态连接到单个向量,并根据隐藏状态 {h1,…,h8} 和解码器 s5 的状态之间的相关性计算相应的注意力分数。
在解码器中,连续生成缺失值的预测。在每个时间索引 t,GRU 单元根据之前的状态S(t-1)、时间索引 t−1 的预测Y(t-1)和注意力向量 ct。线性层堆叠在 GRU 层的顶部以生成数值。上述过程计算如下:

其中st是解码器在时间索引t处的隐藏状态,ct是注意上下文向量,[st;ct]是解码器隐藏状态和上下文向量的串联。线性层生成最终预测yt。
那Ct是怎么计算的?
在每个解码时间索引t中,注意上下文向量ct可以描述为双头编码器传递的隐藏状态的加权和:

每个隐藏状态hi的权重αti由以下公式计算:

a是一个可以与GRU解码器联合训练的神经网络,其中eti表示hi周围的隐藏状态与时间t的输出之间的相关性。。将softmax激活功能应用于eti,以确保将所有注意力权重之和归一化为1。
注意力机制的作用:
根据描述的交叉头注意机制,解码器可以根据注意分数重新加权输入信息,如(12)所示。因此,在预测不同时间指标的缺失数据值时,该模型可以从输入序列中找出最相关的信息。此外,注意机制提供了一种有效的方式来解释和可视化模型在生成预测时所看到的信息。
训练特点——优化增强训练
- 计划抽样
当训练模型以产生时间序列t的预测时,我们选择使用真实的先前观测yt−1的概率ε,或使用估计的̂yt−1来自模型本身,概率为1−ε. 在推理过程中,dual-SSIM仅根据其自身先前的预测值进行预测。其过程如图:

通过应用计划抽样,可以缓解训练和推理之间的差异。它产生了一个插补模型,该模型在训练过程中学会了纠正自己在推理中的错误,因而更加稳健。
2.损失函数(不同以往的)
均方误差 (MSE) 和平均绝对误差 (MAE) 被绝大多数方法应用于回归任务。 在对时间序列中的多个缺失值进行插补时,我们不仅期望估计的缺失值具有较低的平均误差,而且与实际时间序列轨迹具有较高的相似性。 因此,我们应用失真损失,包括形状和时间 (DILATE)模型。
让̂y和y∈Rk表示长度为k的预测和实际时间序列,扩张损失函数公式表示如下:
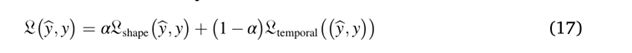
α∈ [0,1]是一个超参数,用于平衡两个损失项shape和temporal。
2.4 评估标准
基于均方根误差(RMSE)、平均绝对误差(MAE)和动态时间扭曲(DTW)的缺失数据恢复性能,公式如下:

其中P是时间序列之间的最佳对齐路径。
2.5 实验特点
- 超参数应用网格搜索
测试了编码器和解码器从1到3的层数。此外,GRU单元的数量在[25,50,75]范围内进行测试。 - 为了自然地支持缺失间隙的时间序列数据,设计了两个带有选通循环单元的编码器来处理时间信息。此外,还设计了一个注意模块,通过交叉两个编码器的隐藏状态来计算注意分数。