爬取OJ题目和学校信息通知
一、爬取南阳理工OJ题目
二、爬取学校信息通知
三、总结
参考
一、爬取南阳理工OJ题目
爬取网站:http://www.51mxd.cn
1. 初步分析
通过切换页数可发现,第n页网址为:n.htm
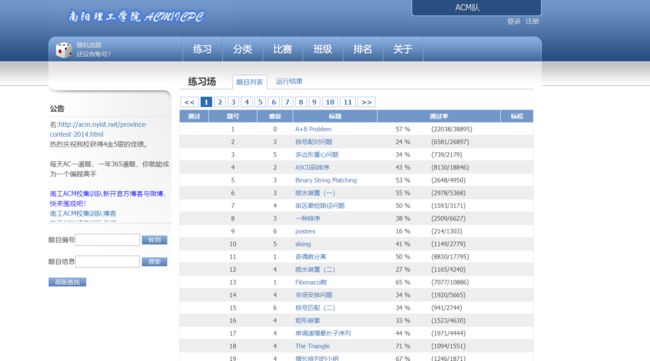
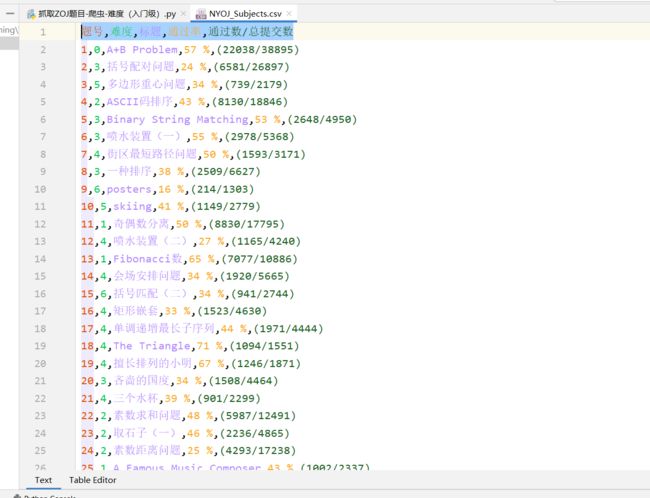
我们需要爬取其题号,难度,标题,通过率,通过数/总提交数:
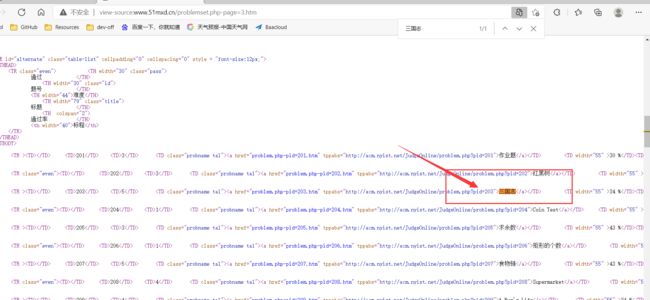
右击查看网页源代码:
在其中 Ctrl + F 搜索该页的某一个题目(此处以三国志为例):
能够搜索到,说明此数据不是动态加载,可直接get该页面以获取:
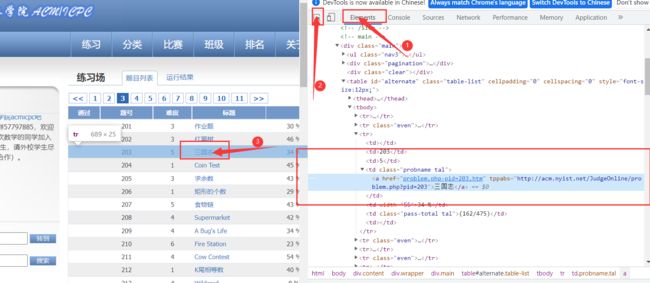
按 F12 打开开发者工具,在Element中点击箭头工具(如下图② 所示),点击一个题目,可在Element中显示:
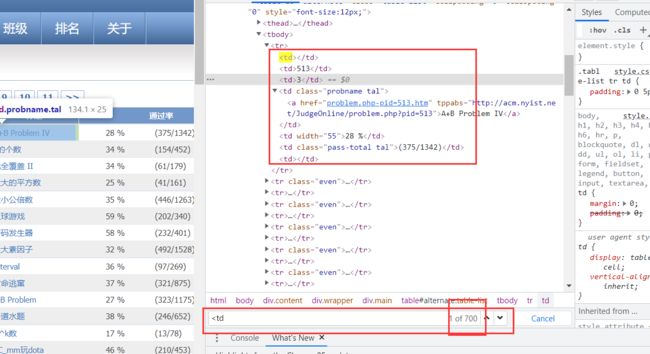
可发现,每一行信息都在一个标签中,每个小信息都在一个标签的字符串里面,在Element中 Ctrl + F 搜索,可发现有700个。100个题目,一行有7个,正好是700个,因此只需要获取所有标签:分析完成后,开始编写代码。
2. 代码编写
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
csvHeaders = [ '题号' , '难度' , '标题' , '通过率' , '通过数/总提交数' ]
subjects = [ ]
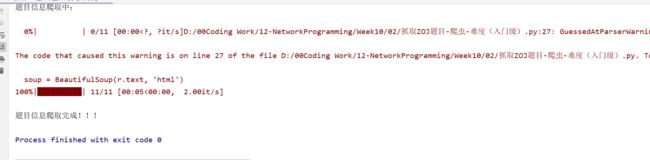
print ( '题目信息爬取中:\n' )
for pages in tqdm( range ( 1 , 11 + 1 ) ) :
r = requests. get( f'http://www.51mxd.cn/problemset.php-page= {
pages} .htm' , Headers)
r. raise_for_status( )
r. encoding = 'utf-8'
soup = BeautifulSoup( r. text, 'lxml' )
td = soup. find_all( 'td' )
subject = [ ]
for t in td:
if t. string is not None :
subject. append( t. string)
if len ( subject) == 5 :
subjects. append( subject)
subject = [ ]
with open ( 'NYOJ_Subjects.csv' , 'w' , newline= '' ) as file :
fileWriter = csv. writer( file )
fileWriter. writerow( csvHeaders)
fileWriter. writerows( subjects)
print ( '\n题目信息爬取完成!!!' )
运行测试:
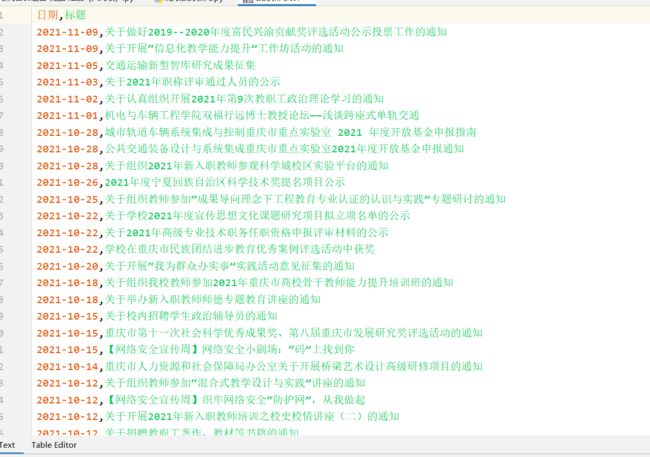
二、爬取学校信息通知
爬取网站:http://news.cqjtu.edu.cn/xxtz.htm
爬取内容:日期 + 标题
1. 每页url分析
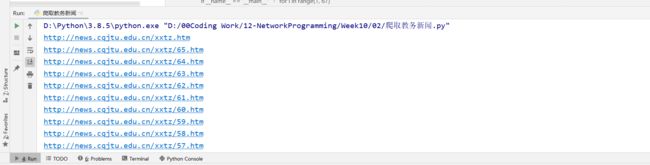
第一页url为http://news.cqjtu.edu.cn/xxtz.htm,第二页为http://news.cqjtu.edu.cn/xxtz/65.htm,第三页为http://news.cqjtu.edu.cn/xxtz/64.htm
一共66页,由此可表示如下:
base_url = "http://news.cqjtu.edu.cn/xxtz/"
for i in range ( 1 , 67 ) :
if ( i == 1 ) :
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else :
url = base_url + str ( 67 - i) + '.htm'
print ( url)
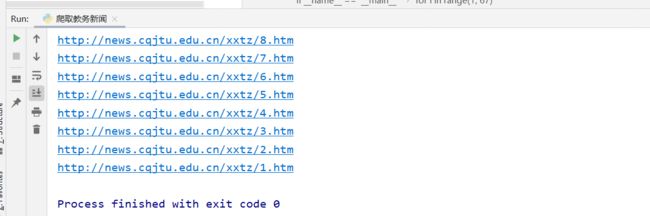
打印如图:
2. 每页内容爬取
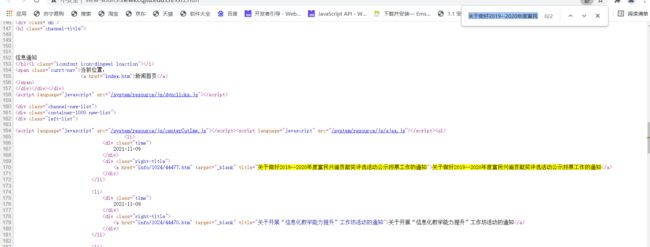
以第一页为例,右击打开网页源代码,搜索一个新闻标题,发现存在,则可直接以get请求获取数据:
在开发者工具中,找到需要爬取的内容,每组日期和标题存在于
所有class="left-list"的div下的class="left-list"的元素,该元素下只有一个
def get_one_page ( url) :
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try :
info_list_page = [ ]
resp = requests. get( url, headers= headers)
resp. encoding = resp. status_code
page_text = resp. text
soup = BeautifulSoup( page_text, 'lxml' )
li_list = soup. select( '.left-list > ul > li' )
for li in li_list:
divs = li. select( 'div' )
date = divs[ 0 ] . string. strip( )
title = divs[ 1 ] . a. string
info = [ date, title]
info_list_page. append( info)
except Exception as e:
print ( '爬取' + url + '错误' )
print ( e)
return None
else :
resp. close( )
print ( '爬取' + url + '成功' )
return info_list_page
测试爬取第一页:
print ( get_one_page( 'http://news.cqjtu.edu.cn/xxtz.htm' ) )
总代码
import requests
from bs4 import BeautifulSoup
import csv
def get_one_page ( url) :
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try :
info_list_page = [ ]
resp = requests. get( url, headers= headers)
resp. encoding = resp. status_code
page_text = resp. text
soup = BeautifulSoup( page_text, 'lxml' )
li_list = soup. select( '.left-list > ul > li' )
for li in li_list:
divs = li. select( 'div' )
date = divs[ 0 ] . string. strip( )
title = divs[ 1 ] . a. string
info = [ date, title]
info_list_page. append( info)
except Exception as e:
print ( '爬取' + url + '错误' )
print ( e)
return None
else :
resp. close( )
print ( '爬取' + url + '成功' )
return info_list_page
def main ( ) :
info_list_all = [ ]
base_url = 'http://news.cqjtu.edu.cn/xxtz/'
for i in range ( 1 , 67 ) :
if i == 1 :
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else :
url = base_url + str ( 67 - i) + '.htm'
info_list_page = get_one_page( url)
info_list_all += info_list_page
with open ( '教务新闻.csv' , 'w' , newline= '' , encoding= 'utf-8' ) as file :
fileWriter = csv. writer( file )
fileWriter. writerow( [ '日期' , '标题' ] )
fileWriter. writerows( info_list_all)
if __name__ == '__main__' :
main( )
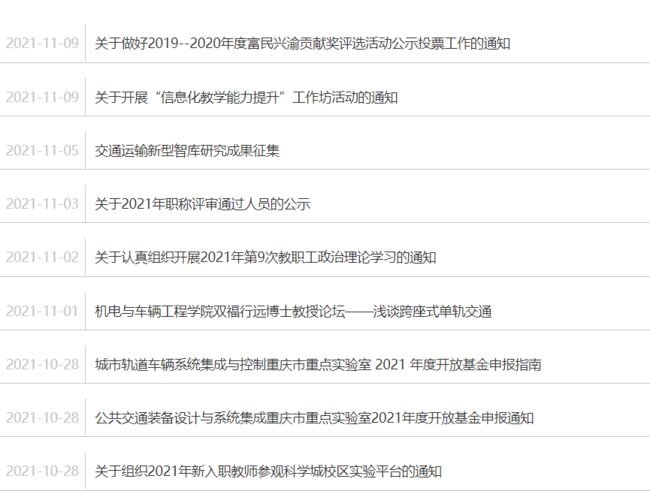
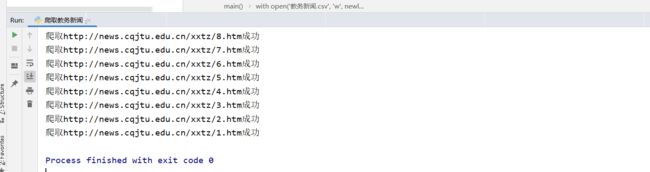
运行结果:
三、总结
学习爬虫之后,可以让我们方便地获取更多的数据源,从而进行更深层次更有效的数据分析,获得更多的价值。
参考
raise_for_status()方法
你可能感兴趣的:(爬虫,python,爬虫,python)
使用python计算等比数列求和的方法
HAMYHF
windows
在python中,计算Sum=m+mm+mmm+mmmm+.....+mmmmm.....,输入两个数m,n。m的位数累加到n的值,列出算式并计算出结果:#为了打印出算式,并计算出结果,将m,mm这些放入到列表中#定义列表中的m初始值为0,用Ele来代表m,mm....Ele=0#定义总和为0Sum=0#定义一个空列表List=[]#输入两个值n=int(input("inputadigit:")
Python+Playwright常用元素定位方法
HAMYHF
python 功能测试
CSSselector选择器在CSS中,定位元素主要通过选择器完成,以下是几种常见的CSS选择器定位方法:标签选择器(element):直接使用HTML元素名称来定位,例如p会选择所有段落元素。属性选择器(attribute):选择所有具有指定属性的元素,无论该属性的值是什么。例如,[title]会选择所有包含title属性的元素。选择具有指定属性,并且该属性值完全等于给定值的元素。例如,[typ
Python中的 redis keyspace 通知_python 操作redis psubscribe(‘__keyspace@0__ ‘)
2301_82243733
程序员 python 学习 面试
最后Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习Python门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的Pytho
Python数据分析与可视化
程序媛小果
python python 数据分析 开发语言
Python数据分析与可视化在数据驱动的商业世界中,数据分析和可视化成为了理解复杂数据集、做出明智决策的关键工具。Python,作为一种功能强大且易于学习的编程语言,提供了丰富的库和框架,使得数据分析和可视化变得简单高效。本文将探讨Python在数据分析和可视化中的应用,包括数据预处理、分析、以及如何通过可视化工具将数据洞察转化为可操作的策略。1.数据分析的重要性数据分析是提取数据中有用信息的过程
【Python 学习 / 7】模块与文件操作
卜及中
Python基础 python 学习 数据库
文章目录前言一、导入模块1.导入整个模块2.导入模块中的特定函数3.给模块或函数起别名二、常用模块1.`math`模块2.`random`模块3.`os`模块4.`sys`模块三、文件处理1.打开文件2.读取文件3.写入文件4.关闭文件5.使用`with`语句管理文件四、日期时间1.`datetime`模块获取当前日期和时间创建日期和时间对象格式化日期和时间解析字符串为日期对象2.`time`模块
经销商管理系统架构设计方案(附 Java版本和Python版本源代码详解)
AI天才研究院
DeepSeek R1 & 大数据AI人工智能大模型 AI大模型企业级应用开发实战 AI大模型应用入门实战与进阶 计算科学 神经计算 深度学习 神经网络 大数据 人工智能 大型语言模型 AI AGI LLM Java Python 架构设计 Agent RPA
经销商管理系统架构设计方案(Java实现源代码详解)关键词:经销商管理系统,Java,SpringBoot,MyBatis,MySQL,架构设计,源代码1.背景介绍随着市场竞争的日益激烈,企业对经销商的管理越来越重视。传统的经销商管理方式效率低下,信息滞后,难以适应现代企业的发展需求。为了提高经销商管理效率,降低运营成本,越来越多的企业开始采用信息化的手段来管理经销商,而经销商管理系统应运而生。经
Python:数据从Excel表格链接到Word文档 更新Excel即可自动更新Word
一个花生米生花
python excel word
要使用Python来创建或更新一个Word文档,并将数据从Excel表格链接到Word文档中,你可以使用python-docx库来操作Word文档和openpyxl或pandas库来读取Excel文件。不过,需要注意的是,python-docx库并不支持将外部文件链接到Word文档的功能。你可以在Word文档中插入Excel数据的快照,但它们不会自动更新。如果你想要在Word文档中插入Excel数
使用Odoo Shell卸载模块
odoo中国
odoo odoo 开源软件 erp
使用OdooShell卸载模块我们在Odoo使用过程中,因为模块安装错误或者前端错误等导致odoo无法通过界面登录,这时候你可以使用OdooShell来卸载模块。OdooShell是一个交互式Pythonshell,允许你直接与Odoo数据库和模型进行交互。以下是使用OdooShell卸载模块的详细步骤:步骤1:启动OdooShell要启动OdooShell,你需要在终端中运行以下命令。确保你已经
NumPy的基本使用
Mo思
编程学习 numpy python 开发语言 pip
在Python的数据科学与数值计算领域,NumPy无疑是一颗耀眼的明星。作为Python中用于科学计算的基础库,NumPy提供了高效的多维数组对象以及处理这些数组的各种工具。本文将带您深入了解NumPy的基本使用,感受它的强大魅力。一、安装与导入在使用NumPy之前,首先要确保它已经安装在您的Python环境中。如果您使用的是Anaconda发行版,NumPy通常已经预装。若未安装,可以使用如下命
FOKS-TROT: 一个高效、易用的全功能开源知识图谱生成工具
柳旖岭
FOKS-TROT:一个高效、易用的全功能开源知识图谱生成工具项目简介FOKS-TROT是一个基于Python的全功能开源知识图谱生成工具,旨在帮助研究人员和开发者快速构建具有丰富信息的知识图谱。该项目由hkx3upper在GitCode上开发并维护。通过FOKS-TROT,您可以轻松地将各种数据源(如文本文件、数据库、API)转换为结构化的知识图谱,并对其进行可视化分析和机器学习任务。此外,该工
python实现word文档合并 v2.0
task138
python自动化 python 自动化 运维开发
目录前言要求运行效果脚本下载链接前言之前发表了一个小工具,python用于合并word文档以完成特定的工作任务,现在领导给出了新需求,适当的调整了一下word文档的合并情况。同时,各位同事反馈说,环境部署太难了,脚本的使用成本比较高,难度大,所以我这次把脚本打包成一个EXE可执行文件,直接双击即可使用。要求由于脚本的具体逻辑发生了变化,因此,exe文件的同级目录下,一定要存在一个txt文件,否则无
2025年全国CTF夺旗赛-从零基础入门到竞赛,看这一篇就稳了!
白帽安全-黑客4148
安全 web安全 网络 网络安全 CTF
目录一、CTF简介二、CTF竞赛模式三、CTF各大题型简介四、CTF学习路线4.1、初期1、html+css+js(2-3天)2、apache+php(4-5天)3、mysql(2-3天)4、python(2-3天)5、burpsuite(1-2天)4.2、中期1、SQL注入(7-8天)2、文件上传(7-8天)3、其他漏洞(14-15天)4.3、后期五、CTF学习资源5.1、CTF赛题复现平台5.
2025年全国CTF夺旗赛-从零基础入门到竞赛,看这一篇就稳了!
白帽安全-黑客4148
网络安全 web安全 linux 密码学 CTF
目录一、CTF简介二、CTF竞赛模式三、CTF各大题型简介四、CTF学习路线4.1、初期1、html+css+js(2-3天)2、apache+php(4-5天)3、mysql(2-3天)4、python(2-3天)5、burpsuite(1-2天)4.2、中期1、SQL注入(7-8天)2、文件上传(7-8天)3、其他漏洞(14-15天)4.3、后期五、CTF学习资源5.1、CTF赛题复现平台5.
基于python深度学习遥感影像地物分类与目标识别、分割实践技术应用
xiao5kou4chang6kai4
深度学习 遥感 勘测 python 深度学习 分类
专题一:深度学习发展与机器学习深度学习的历史发展过程机器学习,深度学习等任务的基本处理流程梯度下降算法讲解不同初始化,学习率对梯度下降算法的实例分析从机器学习到深度学习算法专题二深度卷积网络、卷积神经网络、卷积运算的基本原理池化操作,全连接层,以及分类器的作用BP反向传播算法的理解一个简单CNN模型代码理解特征图,卷积核可视化分析专题三TensorFlow与keras介绍与入门TensorFlow
python 快速实现链接转 word 文档
嘿嘿潶黑黑
python word
python快速实现链接转word文档演示代码展示最后演示代码展示fromnewspaperimportArticlefromdocximportDocumentfromdocx.sharedimportPt,RGBColorfromdocx.enum.styleimportWD_STYLE_TYPEfromdocx.oxml.nsimportqn#tkinterGUIimporttkintera
Python入门笔记
「已注销」
计算机
文章目录第0周课程导学第1周Python基本语法元素保留字数据类型语句与函数输入函数第2周Python基本图形绘制turtle库绝对坐标海龟坐标turtle角度坐标体系RGB色彩体系画笔控制函数运动控制函数方向控制函数循环语句第3周基本数据类型整型浮点数科学计数法复数类型数值运算操作符二元操作符有对应的增强赋值操作符数值运算函数字符串类型的表示字符串切片字符串类型及操作字符串类型格式化time库时
pythonxml模块高级用法_Python minidom模块用法示例【DOM写入和解析XML】
Lucy-露西娅
pythonxml模块高级用法
本文实例讲述了Pythonminidom模块用法。分享给大家供大家参考,具体如下:一、DOM写XML文件#-*-coding:utf-8-*-#!python3#导入minidomfromxml.domimportminidom#1.创建DOM树对象dom=minidom.Document()#2.创建根节点。每次都要用DOM对象来创建任何节点。root_node=dom.createElemen
React 渲染 Flash 接口数据
ox0080
# 北漂+滴滴出行 VIP 激励 Web react.js 前端 前端框架
1.后端Python代码使用Flask创建多个接口,每个接口返回不同的数据,并使用自定义装饰器来绑定路由。代码:#app.pyfromflaskimportFlask,jsonifyapp=Flask(__name__)defapi_route(route,methods=['GET']):"""自定义装饰器,用于将函数与HTTP路由绑定"""defdecorator(func):app.rout
LQB---基础练习---十六进制转八进制
「已注销」
# LQB LQB
试题基础练习十六进制转八进制资源限制内存限制:512.0MBC/C++时间限制:1.0sJava时间限制:3.0sPython时间限制:5.0s问题描述给定n个十六进制正整数,输出它们对应的八进制数。输入格式输入的第一行为一个正整数n(1<=n<=10)。接下来n行,每行一个由09、大写字母AF组成的字符串,表示要转换的十六进制正整数,每个十六进制数长度不超过100000。输出格式输出n行,每行为
【2025年】全国CTF夺旗赛-从零基础入门到竞赛,看这一篇就稳了!
网安詹姆斯
web安全 CTF 网络安全大赛 python linux
【2025年】全国CTF夺旗赛-从零基础入门到竞赛,看这一篇就稳了!基于入门网络安全/黑客打造的:黑客&网络安全入门&进阶学习资源包目录一、CTF简介二、CTF竞赛模式三、CTF各大题型简介四、CTF学习路线4.1、初期1、html+css+js(2-3天)2、apache+php(4-5天)3、mysql(2-3天)4、python(2-3天)5、burpsuite(1-2天)4.2、中期1、S
机器学习·文本数据读写处理
AAA顶置摸鱼
python 深度学习 机器学习 人工智能 数据处理
前言在自然语言处理的第一步,需要面对的是各种各样以不同形式表现的文本数据,比如,txt、Excel中的表格数据,还有无法直接打开的pkl文件等。针对这些不同类型的数据,可以基于Python中的基本功能函数或者调用某些库进行读写以及作一些基本的处理。一、文本数据读写方法1.读写TXT文件读取方法:read():读取整个文件,返回字符串。readline():逐行读取,返回字符串。readlines(
LQB(4)-python-DFS搜索
AAA顶置摸鱼
蓝桥杯python组 深度优先 算法 python 蓝桥杯
前言DFS即深度优先搜索(Depth-FirstSearch),是一种用于遍历或搜索树或图的算法,有三种核心的应用场景(基础遍历、回溯、剪枝)。一、DFS-基础遍历1.核心原理深度优先搜索(DFS)是一种遍历或搜索树/图的算法,优先沿着一条路径尽可能深入,直到无法继续再回溯。实现方式:递归:隐式利用系统调用栈。栈模拟:显式使用栈数据结构。2.代码实现(1)递归实现(树结构)classTreeNod
Python中LLM的知识图谱构建:动态更新与推理
二进制独立开发
GenAI与Python 非纯粹GenAI python 知识图谱 开发语言 自然语言处理 人工智能 分布式 机器学习
文章目录引言1.知识图谱的基本概念1.1知识图谱的定义1.2知识图谱的构建流程2.利用LLM进行知识抽取2.1实体识别2.2关系抽取2.3属性抽取3.知识融合3.1实体对齐3.2冲突消解4.知识存储5.知识推理5.1规则推理5.2基于LLM的推理6.动态更新6.1增量更新6.2实时更新7.结论引言随着人工智能技术的飞速发展,知识图谱(KnowledgeGraph,KG)作为一种结构化的知识表示方法
Python's SQLAlchemy and Object-Relational Mapping
zhanglizhuo
Python
Acommontaskwhenprogramminganywebserviceistheconstructionofasoliddatabasebackend.Inthepast,programmerswouldwriterawSQLstatements,passthemtothedatabaseengineandparsethereturnedresultsasanormalarrayofrec
Jira,一个强大灵活的项目和任务管理工具 Python 库
图灵学者
python精华 jira python 开发语言
目录01初识Jira为什么选择Jira?02安装与配置安装jira库配置Jira访问获取APItoken:配置Python环境:03基本操作创建项目创建任务查询任务更新任务删除任务04高级操作处理子任务搜索任务添加附件评论任务05实战案例自动化创建与分配任务自动生成项目报告06结语01初识JiraJira是Atlassian公司开发的一款项目和任务管理工具。它广泛应用于软件开发、IT支持、营销等各
使用LlamaIndex查询 MongoDB 数据库,并获取 OSS (对象存储服务) 上的 PDF 文件,最终用Langchain搭建应用
朴拙Python交易猿
数据库 mongodb pdf
使用LlamaIndex查询MongoDB数据库,并获取OSS(对象存储服务)上的PDF文件,然后利用Langchain搭建应用,涉及多个步骤。下面我们将详细介绍如何将这些步骤结合起来,构建一个系统:1.环境准备首先,确保你已经安装了以下Python库:pipinstallllama_indexpymongolangchainopenaiboto3pdfplumberpymongo:MongoDB
python 连接 jira
我就是我是好孩子啊
python jira 开发语言
Python连接到Jira实例、登录、查询、修改和创建bug首先,你需要安装jiraPython库pip3installjira连接到Jira并登录fromjiraimportJIRAfromjira.exceptionsimportJIRAError#Jira服务器地址,用户名和密码jira_server='https://your-jira-server.com'jira_user='your
python调用接口返回401,带有Python的Jira API在有效凭据上返回错误401
weixin_39743369
python调用接口返回401
IamtryingtousetheJirapythonlibrarytodosomequitebasicthings.Evenbeforedoinganything,theconstructorfails.address='https://myaddress.atlassian.net'options={'server':address}un='
[email protected] '#un='my'#alsod
python邮件发送哪个好_(原创)python发送邮件
加勒比考斯
python邮件发送哪个好
这段时间一直在学习flask框架,看到flask扩展中有一个mail插件,所以今天就给大家演示如果发邮件。首先我注册了一个163邮箱,需要开启smtp功能,(网易的电子邮件服务器)。注册好163邮箱,然后开启smtp功能,如下图所示:开启的过程中需要绑定手机。我最终实现的样子是这样的:使用flask搭建了一个web服务器,然后做了一个网页,将收件人,主题,正文填好之后,点击发送,上面会显示发送结果
如何用 python 获取实时的股票数据?_python efinance(2)
元点三
2024年程序员学习 python java linux
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课
多线程编程之join()方法
周凡杨
java JOIN 多线程 编程 线程
现实生活中,有些工作是需要团队中成员依次完成的,这就涉及到了一个顺序问题。现在有T1、T2、T3三个工人,如何保证T2在T1执行完后执行,T3在T2执行完后执行?问题分析:首先问题中有三个实体,T1、T2、T3, 因为是多线程编程,所以都要设计成线程类。关键是怎么保证线程能依次执行完呢?
Java实现过程如下:
public class T1 implements Runnabl
java中switch的使用
bingyingao
java enum break continue
java中的switch仅支持case条件仅支持int、enum两种类型。
用enum的时候,不能直接写下列形式。
switch (timeType) {
case ProdtransTimeTypeEnum.DAILY:
break;
default:
br
hive having count 不能去重
daizj
hive 去重 having count 计数
hive在使用having count()是,不支持去重计数
hive (default)> select imei from t_test_phonenum where ds=20150701 group by imei having count(distinct phone_num)>1 limit 10;
FAILED: SemanticExcep
WebSphere对JSP的缓存
周凡杨
WAS JSP 缓存
对于线网上的工程,更新JSP到WebSphere后,有时会出现修改的jsp没有起作用,特别是改变了某jsp的样式后,在页面中没看到效果,这主要就是由于websphere中缓存的缘故,这就要清除WebSphere中jsp缓存。要清除WebSphere中JSP的缓存,就要找到WAS安装后的根目录。
现服务
设计模式总结
朱辉辉33
java 设计模式
1.工厂模式
1.1 工厂方法模式 (由一个工厂类管理构造方法)
1.1.1普通工厂模式(一个工厂类中只有一个方法)
1.1.2多工厂模式(一个工厂类中有多个方法)
1.1.3静态工厂模式(将工厂类中的方法变成静态方法)
&n
实例:供应商管理报表需求调研报告
老A不折腾
finereport 报表系统 报表软件 信息化选型
引言
随着企业集团的生产规模扩张,为支撑全球供应链管理,对于供应商的管理和采购过程的监控已经不局限于简单的交付以及价格的管理,目前采购及供应商管理各个环节的操作分别在不同的系统下进行,而各个数据源都独立存在,无法提供统一的数据支持;因此,为了实现对于数据分析以提供采购决策,建立报表体系成为必须。 业务目标
1、通过报表为采购决策提供数据分析与支撑
2、对供应商进行综合评估以及管理,合理管理和
mysql
林鹤霄
转载源:http://blog.sina.com.cn/s/blog_4f925fc30100rx5l.html
mysql -uroot -p
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
[root@centos var]# service mysql
Linux下多线程堆栈查看工具(pstree、ps、pstack)
aigo
linux
原文:http://blog.csdn.net/yfkiss/article/details/6729364
1. pstree
pstree以树结构显示进程$ pstree -p work | grep adsshd(22669)---bash(22670)---ad_preprocess(4551)-+-{ad_preprocess}(4552) &n
html input与textarea 值改变事件
alxw4616
JavaScript
// 文本输入框(input) 文本域(textarea)值改变事件
// onpropertychange(IE) oninput(w3c)
$('input,textarea').on('propertychange input', function(event) {
console.log($(this).val())
});
String类的基本用法
百合不是茶
String
字符串的用法;
// 根据字节数组创建字符串
byte[] by = { 'a', 'b', 'c', 'd' };
String newByteString = new String(by);
1,length() 获取字符串的长度
&nbs
JDK1.5 Semaphore实例
bijian1013
java thread java多线程 Semaphore
Semaphore类
一个计数信号量。从概念上讲,信号量维护了一个许可集合。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release() 添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore 只对可用许可的号码进行计数,并采取相应的行动。
S
使用GZip来压缩传输量
bijian1013
java GZip
启动GZip压缩要用到一个开源的Filter:PJL Compressing Filter。这个Filter自1.5.0开始该工程开始构建于JDK5.0,因此在JDK1.4环境下只能使用1.4.6。
PJL Compressi
【Java范型三】Java范型详解之范型类型通配符
bit1129
java
定义如下一个简单的范型类,
package com.tom.lang.generics;
public class Generics<T> {
private T value;
public Generics(T value) {
this.value = value;
}
}
【Hadoop十二】HDFS常用命令
bit1129
hadoop
1. 修改日志文件查看器
hdfs oev -i edits_0000000000000000081-0000000000000000089 -o edits.xml
cat edits.xml
修改日志文件转储为xml格式的edits.xml文件,其中每条RECORD就是一个操作事务日志
2. fsimage查看HDFS中的块信息等
&nb
怎样区别nginx中rewrite时break和last
ronin47
在使用nginx配置rewrite中经常会遇到有的地方用last并不能工作,换成break就可以,其中的原理是对于根目录的理解有所区别,按我的测试结果大致是这样的。
location /
{
proxy_pass http://test;
java-21.中兴面试题 输入两个整数 n 和 m ,从数列 1 , 2 , 3.......n 中随意取几个数 , 使其和等于 m
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
public class CombinationToSum {
/*
第21 题
2010 年中兴面试题
编程求解:
输入两个整数 n 和 m ,从数列 1 , 2 , 3.......n 中随意取几个数 ,
使其和等
eclipse svn 帐号密码修改问题
开窍的石头
eclipse SVN svn帐号密码修改
问题描述:
Eclipse的SVN插件Subclipse做得很好,在svn操作方面提供了很强大丰富的功能。但到目前为止,该插件对svn用户的概念极为淡薄,不但不能方便地切换用户,而且一旦用户的帐号、密码保存之后,就无法再变更了。
解决思路:
删除subclipse记录的帐号、密码信息,重新输入
[电子商务]传统商务活动与互联网的结合
comsci
电子商务
某一个传统名牌产品,过去销售的地点就在某些特定的地区和阶层,现在进入互联网之后,用户的数量群突然扩大了无数倍,但是,这种产品潜在的劣势也被放大了无数倍,这种销售利润与经营风险同步放大的效应,在最近几年将会频繁出现。。。。
如何避免销售量和利润率增加的
java 解析 properties-使用 Properties-可以指定配置文件路径
cuityang
java properties
#mq
xdr.mq.url=tcp://192.168.100.15:61618;
import java.io.IOException;
import java.util.Properties;
public class Test {
String conf = "log4j.properties";
private static final
Java核心问题集锦
darrenzhu
java 基础 核心 难点
注意,这里的参考文章基本来自Effective Java和jdk源码
1)ConcurrentModificationException
当你用for each遍历一个list时,如果你在循环主体代码中修改list中的元素,将会得到这个Exception,解决的办法是:
1)用listIterator, 它支持在遍历的过程中修改元素,
2)不用listIterator, new一个
1分钟学会Markdown语法
dcj3sjt126com
markdown
markdown 简明语法 基本符号
*,-,+ 3个符号效果都一样,这3个符号被称为 Markdown符号
空白行表示另起一个段落
`是表示inline代码,tab是用来标记 代码段,分别对应html的code,pre标签
换行
单一段落( <p>) 用一个空白行
连续两个空格 会变成一个 <br>
连续3个符号,然后是空行
Gson使用二(GsonBuilder)
eksliang
json gson GsonBuilder
转载请出自出处:http://eksliang.iteye.com/blog/2175473 一.概述
GsonBuilder用来定制java跟json之间的转换格式
二.基本使用
实体测试类:
温馨提示:默认情况下@Expose注解是不起作用的,除非你用GsonBuilder创建Gson的时候调用了GsonBuilder.excludeField
报ClassNotFoundException: Didn't find class "...Activity" on path: DexPathList
gundumw100
android
有一个工程,本来运行是正常的,我想把它移植到另一台PC上,结果报:
java.lang.RuntimeException: Unable to instantiate activity ComponentInfo{com.mobovip.bgr/com.mobovip.bgr.MainActivity}: java.lang.ClassNotFoundException: Didn't f
JavaWeb之JSP指令
ihuning
javaweb
要点
JSP指令简介
page指令
include指令
JSP指令简介
JSP指令(directive)是为JSP引擎而设计的,它们并不直接产生任何可见输出,而只是告诉引擎如何处理JSP页面中的其余部分。
JSP指令的基本语法格式:
<%@ 指令 属性名="
mac上编译FFmpeg跑ios
啸笑天
ffmpeg
1、下载文件:https://github.com/libav/gas-preprocessor, 复制gas-preprocessor.pl到/usr/local/bin/下, 修改文件权限:chmod 777 /usr/local/bin/gas-preprocessor.pl
2、安装yasm-1.2.0
curl http://www.tortall.net/projects/yasm
sql mysql oracle中字符串连接
macroli
oracle sql mysql SQL Server
有的时候,我们有需要将由不同栏位获得的资料串连在一起。每一种资料库都有提供方法来达到这个目的:
MySQL: CONCAT()
Oracle: CONCAT(), ||
SQL Server: +
CONCAT() 的语法如下:
Mysql 中 CONCAT(字串1, 字串2, 字串3, ...): 将字串1、字串2、字串3,等字串连在一起。
请注意,Oracle的CON
Git fatal: unab SSL certificate problem: unable to get local issuer ce rtificate
qiaolevip
学习永无止境 每天进步一点点 git 纵观千象
// 报错如下:
$ git pull origin master
fatal: unable to access 'https://git.xxx.com/': SSL certificate problem: unable to get local issuer ce
rtificate
// 原因:
由于git最新版默认使用ssl安全验证,但是我们是使用的git未设
windows命令行设置wifi
surfingll
windows wifi 笔记本wifi
还没有讨厌无线wifi的无尽广告么,还在耐心等待它慢慢启动么
教你命令行设置 笔记本电脑wifi:
1、开启wifi命令
netsh wlan set hostednetwork mode=allow ssid=surf8 key=bb123456
netsh wlan start hostednetwork
pause
其中pause是等待输入,可以去掉
2、
Linux(Ubuntu)下安装sysv-rc-conf
wmlJava
linux ubuntu sysv-rc-conf
安装:sudo apt-get install sysv-rc-conf 使用:sudo sysv-rc-conf
操作界面十分简洁,你可以用鼠标点击,也可以用键盘方向键定位,用空格键选择,用Ctrl+N翻下一页,用Ctrl+P翻上一页,用Q退出。
背景知识
sysv-rc-conf是一个强大的服务管理程序,群众的意见是sysv-rc-conf比chkconf
svn切换环境,重发布应用多了javaee标签前缀
zengshaotao
javaee
更换了开发环境,从杭州,改变到了上海。svn的地址肯定要切换的,切换之前需要将原svn自带的.svn文件信息删除,可手动删除,也可通过废弃原来的svn位置提示删除.svn时删除。
然后就是按照最新的svn地址和规范建立相关的目录信息,再将原来的纯代码信息上传到新的环境。然后再重新检出,这样每次修改后就可以看到哪些文件被修改过,这对于增量发布的规范特别有用。
检出