python使用jieba模块进行文本分析和搜索引擎推广“旅行青蛙”数据分析实战
目录
- 1 需要导入的模块
- 2 中文分词基础步骤
-
- 2.1 载入数据
- 2.2 分词
- 2.3 分词后的数据转回文本
- 2.4 保存分词后的文本为文本文件
- 3 添加自定义词典
-
- 3.1 方法1:直接定义词典列表
- 3.2 方法2:外部载入
- 4 动态增加或删除词典的词
- 5 去停用词
- 6 抽取文档关键词
-
- 6.1 词频统计(词频分析)
- 6.2 案例:分析Python互联网招聘信息中的需求关键字
-
- 6.2.1 方式1:使用词频方式提取关键词
- 6.2.2 方式2:使用TF-IDF权重算法提取关键词(注重信息量)
- 6.2.3 方式3:Text-Rank算法(注重文本)
- 7 词云-WordCloud
-
- 7.1 案例:为《大话西游》台词节选绘制词云
- 7.2 自定义背景的词云图
- 8 实战之分析产品:手游《旅行青蛙》的网络推广策略
-
- 8.1 思路
- 8.2 资源
- 8.3 推荐使用技术
- 8.4 实操之数据预处理
-
- 8.4.1 百度指数 数据手动录入后生成表格
- 8.4.2 百度新闻 内容数据抓取
- 8.4.3 数据规整(基本规整)
- 8.4.4 数据规整(进阶)
- 8.4.5 合并百度指数和百度新闻两表
- 8.5 实操之数据处理
-
- 8.5.1 基于搜索引擎的产品推广策略的背景介绍
- 8.5.2 游戏产品的搜索引擎推广策略
- 8.5.3 2018年1-2月最火的游戏:旅行青蛙 的游戏介绍和数据分析境界
- 8.5.4 推广策略研究
-
- 前期:内行(专业人士,产生信息)
- 中期:联系员(桥梁,从专业小圈子介绍传播到大众圈)
- 后期:推销员(口耳相传,扩散,引爆)
- 8.5.5 数据分析之指标计算:渠道分析(新闻源)
-
- ==指标==:计算每种类别下的网站新闻量排名
- 查询每天的百度指数
- 8.5.6 数据分析之流量监测(指标:各个分类下的网站,每天发帖量)
- 8.5.7 数据分析之内容设计(词云)
- 8.6 总结
-
- 8.7 游戏类产品搜索引擎推广建议
- 8.8 时间点选取详细:
1 需要导入的模块
import numpy as np
import pandas as pd
import jieba
import jieba.analyse
import matplotlib.pyplot as plt
plt.style.use('seaborn') # 改变图像风格
plt.rcParams['font.family'] = ['Arial Unicode MS', 'Microsoft Yahei', 'SimHei', 'sans-serif'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # simhei黑体字 负号乱码 解决
2 中文分词基础步骤
2.1 载入数据
# 1 载入数据
# 写法1
with open(r'data\text.txt','r',encoding='GBk') as f:
a = f.read()
# 写法2
with open('data\\text.txt','r',encoding='GBk') as f:
a = f.read()
a
2.2 分词
- cut() 切割
# 2 分词
b = jieba.cut(a)
b # 得到地址:
list(b) # 列表化

遍历一遍
for i in jieba.cut(a):
print(i)

- lcut() 切割并列表化
# 分词后直接生成列表
c = jieba.lcut(a)
c

2.3 分词后的数据转回文本
# 3 分词后的数据转回文本
d = ' '.join(c)
d

2.4 保存分词后的文本为文本文件
# 4 保存分词后的文本为文本文件
with open(r'temp\20211022cut.txt','w',encoding='utf-8') as f:
f.write(d)
3 添加自定义词典
a = '李小福是创新办主任也是云计算专家'
a

普通分词结果
jieba.lcut(a)

注意:自定义词典文本文件,如果使用Windows记事本编辑,读入Python列表时会带有文件头BOM,应该用高级编辑器去除
3.1 方法1:直接定义词典列表
# 应用自定义词典
# 注意:自定义词典文本文件,如果使用Windows记事本编辑,读入Python列表时会带有文件头BOM,应该用高级编辑器去除
# 方法1:直接定义词典列表
b = ['云计算', '创新办']
jieba.load_userdict(b)
jieba.lcut(a)

3.2 方法2:外部载入
# 3.2 方法2:外部载入
with open(r'data\custom.txt','r',encoding='utf-8') as f:
b = f.read()
b = b.split('\n')
# b
jieba.load_userdict(b)
jieba.lcut(a)

- 方法2升级:输入路径直接应用自定义词典
# 方法2升级
jieba.load_userdict('data\custom.txt')
jieba.lcut(a)

4 动态增加或删除词典的词
# 动态增加或删除词典的词
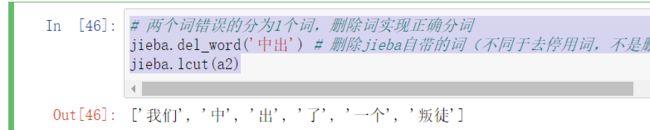
a2 = '我们中出了一个叛徒'
jieba.lcut(a2)

- 两个词错误的分为1个词,删除词实现正确分词
删除jieba自带的词(不同于去停用词,不是删除词,而是重新分词)
# 两个词错误的分为1个词,删除词实现正确分词
jieba.del_word('中出') # 删除jieba自带的词(不同于去停用词,不是删除词,而是重新分词)
jieba.lcut(a2)
- 增加jieba的词
增加jieba的词,和自定义词典相比它可以动态增加词
# 增加jieba的词
jieba.add_word('出了')
jieba.lcut(a2)

- 恢复原状
# 恢复原状
jieba.add_word('中出')
jieba.del_word('出了')
jieba.lcut(a2)

- 调节词的词频
# 调节词的词频,使其能(或不能)被分出
# tune=True:执行词频调整,默认False不执行
jieba.suggest_freq(('中','出'),tune=True)
jieba.lcut(a2)

调整的词以字符串形式输入
# 调整的词以字符串形式输入
jieba.suggest_freq('一个叛徒',tune=True)
jieba.lcut(a2)

恢复jieba到原始状态
# 恢复jieba到原始状态
jieba.suggest_freq(('中出'),tune=True)
jieba.suggest_freq(('一个','叛徒'),tune=True)
jieba.lcut(a2)

5 去停用词
- 与上面相反,当一个字符串不是词,jieba误将其分为词,或者我们不想将某些不重要的词分出来(想删掉某些分出的词)可以自定义停用词词典
- 停用词就是要从分词结果删掉的垃圾无用词
- 词典中的词不会出现在分词结果中
- 停用词词典的内容可以根据项目不断增加
原始代码
# 去停用词
a = '哎,鹅,听说你超级喜欢小游戏的!你是吗?'
a
普通分词
b = jieba.lcut(a)
b

- 去停用词功能jieba不带,需自行实现。下面是实现
先载入停用词
# 载入停用词
# 方法1:手工构造停用词列表
stopword = ['哎','的','是','你','吗','!',',', '?']
# 方式2:载入停用词文件
# with open(r'data\stopword.txt','r',encoding='utf-8') as f:
# # print(f.read())
# s = f.read()
# stopword = s.split('\n') # 会用转译字符'\\u3000','\\n'出现,需要删除
# 方式2提升,若停用词表的特殊词载入时被自动转义,可以判断并恢复
stopword = []
with open(r'data\stopword.txt','r',encoding='utf-8') as f:
for line in f.readlines():
l = line.strip()
if l == '\\u3000':
l = '\u3000'
if l == '\\n':
l = '\n'
stopword.append(l)
stopword
特殊字符恢复成功

- 去停用词,第一步,求差集
# 去停用词,第一步,求差集
x = np.array(b)
x
y = np.array(stopword)
y
# 目的:将分词数组内停用词数组有的值删除
# np.in1d(x,y)
z = x[~np.in1d(x,y)] #反运算 加“~”
z

- 第二步:去掉1个字以下的词
# 第二步:去掉1个字以下的词
k = []
# 遍历写法
# for i in z:
# # print(len(i)) #查看各个词组的字数
# if len(i) > 1:
# k.append(i)
# 列表生成式写法
k = [i for i in z if len(i) > 1]
k

6 抽取文档关键词
抽取文档关键词用于在一篇文章中获取其核心内容(描述了什么?),又叫 生成摘要、打标签、关键词提取等
6.1 词频统计(词频分析)
- 词在文本中出现的次数(频次),某种程度上能当做文本的标签,表示文本内容
- 不是很精准
- 统计前最好先去完成自定义词典和去停用词的前期操作
源数据
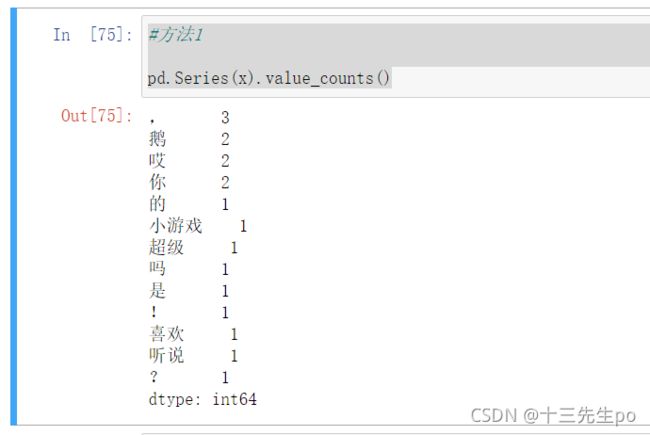
# 词频统计(词频分析)
a = '哎,鹅,听说你超级喜欢小游戏的!你是吗?哎,鹅'
# 略过自定义词典、去停用词
x = jieba.lcut(a)
x

- 方法1 : 转换为Series结构
#方法1
pd.Series(x).value_counts()
- 方法2:转换成DataFrame结构
#方法2
pd.DataFrame(x)
# pd.DataFrame(x).value_counts() # 方法2.1
pd.DataFrame(x).groupby(0).size().sort_values(ascending=False)
6.2 案例:分析Python互联网招聘信息中的需求关键字
载入文本数据
# 案例:分析Python互联网招聘信息中的需求关键字
# 载入文本数据
with open(r'data\work.txt','r',encoding='utf-8') as f:
txt = f.read()
print(txt)

6.2.1 方式1:使用词频方式提取关键词
- 按3,4,5步骤走一遍
# 方式1:使用词频方式提取关键词
# 1 自定义词典
jieba.load_userdict(r'data\custom.txt')
# 2 分词
w = jieba.lcut(txt)
w
# 3 去停用词
# 载入停用词表
stopword = []
with open(r'data\stopword.txt','r',encoding='utf-8') as f:
for line in f.readlines():
l = line.strip()
if l == '\\u3000':
l = '\u3000'
if l == '\\n':
l = '\n'
stopword.append(l)
# 4 去停用词
# 第一步,求差集
x = np.array(w)
y = np.array(stopword)
z = x[~np.in1d(x,y)] # 反向求差
# 第二步,去掉1个字以下的词
k = [i for i in z if len(i) > 1]
k

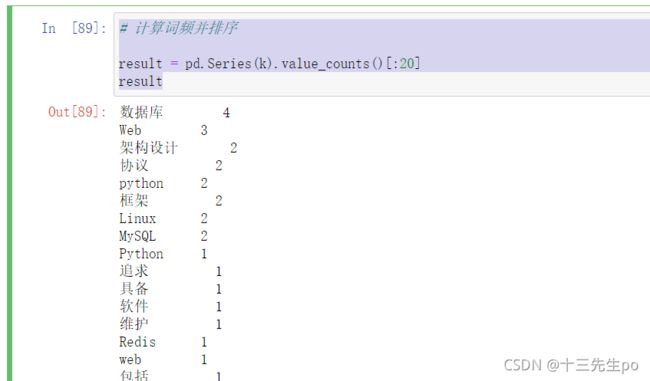
- 统计词频
# 计算词频并排序
result = pd.Series(k).value_counts()[:20]
result
- 保存结果
# 保存结果
result.to_csv(r'temp\20211022keyword.csv',header=0)
- 局限性:统计词频作为文档关键字的准确性不高,还可使用下面的方式
TF-IDF算法 Text-Rank算法 注:TF-IDF和Text-Rank算法运行都不需要手动去停用词,可以用内置函数自动去停用词
6.2.2 方式2:使用TF-IDF权重算法提取关键词(注重信息量)
TF-IDF权重:
词频和重要词的综合分数(权重)
重要词:信息量大的词
- 一个词信息量大小的衡量
在本文章出现的次数多,在通用文档库出现的次数少,就是重要词
如:你我他,你好再见 这些词信息量很小
行业专有名词,如Python/MySQL,信息量就很大
- 首先,应用自定义词典
- 然后,去除停用词,系统自带,给抽取关键字用
# 使用TF-IDF权重算法提取关键词
jieba.load_userdict('data\custom.txt') # 应用自定义词典
jieba.analyse.set_stop_words('data\stopword.txt') # 抽取关键词前去掉自定义停用词
txt

-不需要手动分词,方法会自动分词后抽取关键字
# 不需要手动分词,方法会自动分词后抽取关键字
jieba.analyse.extract_tags(txt)

- 查看详细参数
# 详细参数:
# 字符串
# 返回多少关键词,默认20个
# 是否返回TF-IDF权重
# allowPOS=(),什么词性可以做抽取,默认所有词
k = jieba.analyse.extract_tags(txt,topK=30,withWeight=True)
k

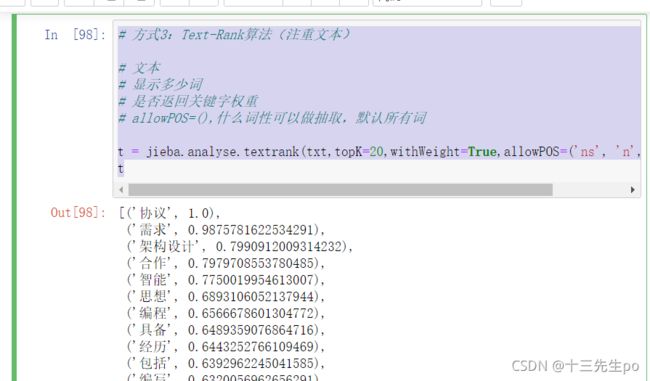
6.2.3 方式3:Text-Rank算法(注重文本)
- 词性标注
# 附:词性标注
a
list(jieba.posseg.cut(a))

# 方式3:Text-Rank算法(注重文本)
# 文本
# 显示多少词
# 是否返回关键字权重
# allowPOS=(),什么词性可以做抽取,默认所有词
t = jieba.analyse.textrank(txt,topK=20,withWeight=True,allowPOS=('ns', 'n', 'vn', 'v'))
t
7 词云-WordCloud
安装 WordCloud库
如系统未安装C++编译库,WordCloud库需要下载whl再使用pip安装
http://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
命令行本地安装:pip install e:/wordcloud‑1.8.0‑cp37‑cp37m‑win_amd64.whl
7.1 案例:为《大话西游》台词节选绘制词云
需要用的库
import numpy as np
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud
from PIL import Image
- 数据载入、分词并转化成文本
- 注意:不用print输出会看见换行符“\n”,例如这样
with open(r'data\大话西游.txt','r',encoding='utf-8') as f:
txt = f.read()
# print(txt) # 不用print输出会看见换行符“\n”
txt

比较稳妥的写法:
# 案例:为《大话西游》台词节选绘制词云
# 数据载入
with open(r'data\大话西游.txt','r',encoding='utf-8') as f:
txt = f.read()
# print(txt) # 不用print输出会看见换行符“\n”
txt2 = ' '.join(jieba.cut(txt))
print(txt2)

- 载入停用词
# 停用词
# 方式2:载入停用词文件
with open(r'data\stopword.txt','r',encoding='utf-8') as f:
# print(f.read())
s = f.read()
stopword = s.split('\n') # 会用转译字符'\\u3000','\\n'出现,需要删除
stopword

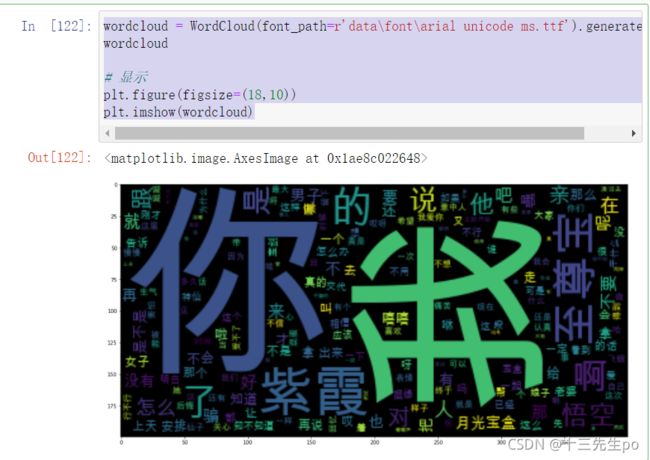
- 基本版词云
wordcloud = WordCloud(font_path=r'data\font\arial unicode ms.ttf').generate(txt2)
wordcloud
# 显示
plt.figure(figsize=(18,10))
plt.imshow(wordcloud)
- 词云优化
# 词云优化
wordcloud = WordCloud(
font_path="data/font/xjlFont.fon", # 字体,不设置则汉字乱码
background_color='white',# 设置背景颜色
max_words=80, # 设置最大现显示词数
max_font_size=80, # font_size可选
stopwords=stopword, # 去停用词
).generate(txt2)
wordcloud
plt.figure(figsize=(18,10),dpi=72)
plt.imshow(wordcloud) # 绘制数据内的图片,双线性插值绘图 interpolation='bilinear'
plt.axis("off") # 去掉坐标轴
plt.savefig(r'temp\20211022test3.png',dpi=300,bbox_inches='tight')

7.2 自定义背景的词云图
使用的背景
# 自定义背景的词云图
alice_mask = np.array(Image.open('data/timg.jpg'))
plt.imshow(alice_mask)

- 插入背景
# 词云优化
wordcloud = WordCloud(
font_path="data/font/xjlFont.fon", # 字体,不设置则汉字乱码
background_color='white',# 设置背景颜色
max_words=80, # 设置最大现显示词数
max_font_size=80, # font_size可选
stopwords=stopword, # 去停用词
mask=alice_mask #设置背景图片
).generate(txt2)
wordcloud
plt.figure(figsize=(18,10),dpi=72)
plt.imshow(wordcloud) # 绘制数据内的图片,双线性插值绘图 interpolation='bilinear'
plt.axis("off") # 去掉坐标轴
plt.savefig(r'temp\20211022test3.png',dpi=300,bbox_inches='tight') # 保存为:带有最小白边且分辨率为300DPI的PNG图片

8 实战之分析产品:手游《旅行青蛙》的网络推广策略
8.1 思路
- 根据百度指数热门程度判断游戏流行时间和流行度
- 数据获取:抓取百度新闻 旅行青蛙 (按标题或内容查询)关键字的文字标题和相关信息
8.2 资源
- 百度指数:http://index.baidu.com/
- 百度新闻:http://news.baidu.com/
8.3 推荐使用技术
- 数据获取
- 爬虫:抓取内容,百度新闻
- 标题
- 来源
- 时间,精确到日
- 数据清洗:先抓取数据保存,然后再进行清洗
- 字符串清理规整建议使用Python原生字符串处理函数实现
- 例如:join(),replace(),split(),remove(),append()等等
- 爬虫:抓取内容,百度新闻
- 非结构化数据分析
- 分词
- 词云
- 结构化数据分析
- Pandas数据预处理和数据分析
- 分组聚合
- 可视化
- Pandas数据预处理和数据分析
8.4 实操之数据预处理
导入可能需要的库
import time
import json
import requests
from lxml import etree
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
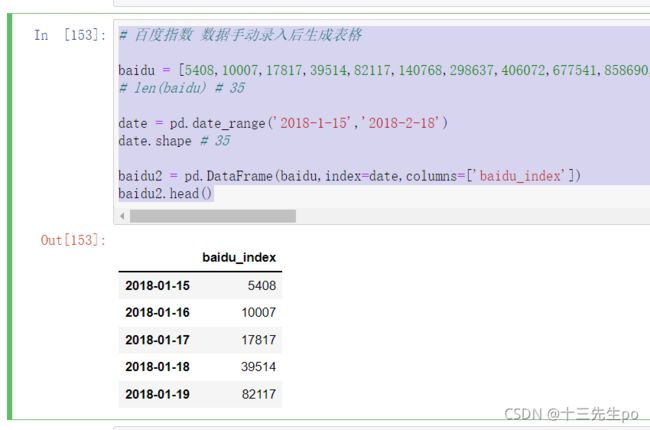
8.4.1 百度指数 数据手动录入后生成表格
- 在百度指数中输入关键词,卡特定的时间,手动输入数据
- 生产dataframe结构
# 百度指数 数据手动录入后生成表格
baidu = [5408,10007,17817,39514,82117,140768,298637,406072,677541,858690,839792,744390,653541,496701,390412,322492,256334,212914,180933,157411,140104,120038,125914,105679,88426,75185,66567,61036,54812,49241,42768,35784,33774,33621,34388]
# len(baidu) # 35
date = pd.date_range('2018-1-15','2018-2-18')
date.shape # 35
baidu2 = pd.DataFrame(baidu,index=date,columns=['baidu_index'])
baidu2.head()
- 保存数据
# 保存数据
baidu2.to_csv(r'data2/baidu_index.csv')
- 读取数据
# 读取数据
# parse_dates参数作用:将csv中的时间字符串转换成日期格式
baidu = pd.read_csv(r'data2/baidu_index.csv',parse_dates=['Unnamed: 0']).set_index('Unnamed: 0')
baidu
# 将原有的索引名“Unnamed: 0”换值
baidu.index.name = 'date'
# 查看前5行和后5行数据
baidu.head().append(baidu.tail())

- 检查数据类型
# 检查数据类型
# 原来第一列日期变成了索引列,只剩一行
baidu.info()

baidu.describe()

8.4.2 百度新闻 内容数据抓取
- 具体实施:
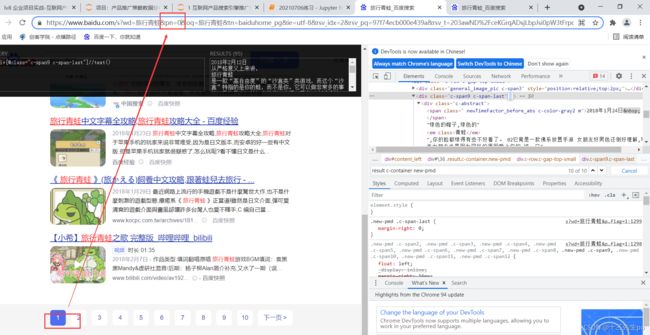
- 根据百度指数热门程度直观分析,抓取百度新闻 旅行青蛙 (按时间排序,媒体网站)关键字的文字标题和相关信息,
时间从 2018-1-15到2018-2-18日 - 目前是(临时使用):新闻页码1-11,每页10条,一共11页(页码pn参数值为0-100)
- 随着时间变化,新闻增加,抓取页码也应该跟着变化
- 根据百度指数热门程度直观分析,抓取百度新闻 旅行青蛙 (按时间排序,媒体网站)关键字的文字标题和相关信息,
起始页:https://www.baidu.com/s?wd=%E6%97%85%E8%A1%8C%E9%9D%92%E8%9B%99&pn=0&oq=%E6%97%85%E8%A1%8C%E9%9D%92%E8%9B%99&tn=baiduhome_pg&ie=utf-8&rsv_idx=2&rsv_pq=97f74ecb000e439a&rsv_t=203awND%2FceKGrqADsjLbpJsi0pW3tFrpcVUE23%2FtFWcPLT5Vnz80grVRZHTmbfvED9KL&gpc=stf%3D1515945600%2C1518883200%7Cstftype%3D2&tfflag=1
终止页:https://www.baidu.com/s?wd=%E6%97%85%E8%A1%8C%E9%9D%92%E8%9B%99&pn=100&oq=%E6%97%85%E8%A1%8C%E9%9D%92%E8%9B%99&tn=baiduhome_pg&ie=utf-8&rsv_idx=2&rsv_pq=be7a7ece000eb2a4&rsv_t=cd1cpTDUXK0oMiSFOSxFIcW08CH2acCb6aTII9RykE452zK8WubRYR059Czcuc1Zulyw&gpc=stf%3D1515945600%2C1518883200%7Cstftype%3D2&tfflag=1
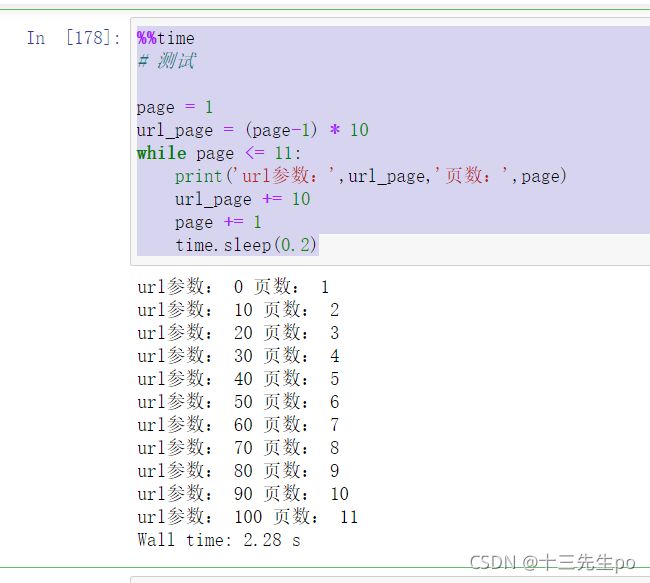
测试一下目标网址页数和pn值的关系是否对应
%%time
# 测试
page = 1
url_page = (page-1) * 10
while page <= 11:
print('url参数:',url_page,'页数:',page)
url_page += 10
page += 1
time.sleep(0.2)
是有一定数量关系的
- 锁定目标抓取数据
需要注意的小问题
- 抓取的数据本身如果有空格,在编译的时候会输出字符\xa0 ,使用join和split的组合方法去掉
''.join(i.get_text().split())
# split方法输出的是列表
# join方法输出的是字符串,刚好配合起来

想要的输出的结果:

- 使用过beautifulsoup模块下的select方法会输出特定标签下的所用文本
例如该标签下的所有文本中,仍然有标签,而且标签内还有文本,也会一个输出

输出的效果:时间和摘要连在了一起

- select方法会输出特定标签下的所用文本,而且输出的是列表值,如果要对select后找到的标签继续查找,可以将“这个列表”的元素抽出来继续查找
例如:
在列表后面命令输出第0个值
source = i.select('div[class="f13 c-gap-top-xsmall se_st_footer user-avatar"]')[0].select('a')[0].get_text()

- 有时候匹配找到的标签下面没有值,但代码依然是命令赋值给对象,但原本就已经找不到,还赋值的话就会报错,如:
IndexError: list index out of range
解决方法是增加try except语句,如果报错就添加特定字符,如:
try:
date = i.select('.c-abstract')
dict['date'].append(''.join(date[0].get_text().split()))
except:
print('空值')
dict['date'].append(''.join('青蛙'))
- 抓取数据写法1(不建议):将所有特定标签找出来,放在对应的列表,但可能会出现标签与标签之间数据量不一样的情况,如:
由于方法存在缺陷,有些值并没有抓取。。。。。 这里仅展示部分完成的代码
%%time
# 数据抓取
data_list = [] # 创建空列表储存数据
# 请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 按时间顺序抓取,页码1-11的pn值为0-100
page = 1
url_page = (page-1) * 10
while page <= 1:
print('url参数:',url_page,'页数:',page)
# 创建空字典存储得到的数据,并将该列表添加进空列表c
dict = {'page':page,'title':None,'source':None,'date':None,'url':None}
# print(dict)
# 写法1
# ============================================
# 网址
url = 'https://www.baidu.com/s?wd=%E6%97%85%E8%A1%8C%E9%9D%92%E8%9B%99&pn={}&oq=%E6%97%85%E8%A1%8C%E9%9D%92%E8%9B%99&tn=baiduhome_pg&ie=utf-8&rsv_idx=2&rsv_pq=97f74ecb000e439a&rsv_t=203awND%2FceKGrqADsjLbpJsi0pW3tFrpcVUE23%2FtFWcPLT5Vnz80grVRZHTmbfvED9KL&gpc=stf%3D1515945600%2C1518883200%7Cstftype%3D2&tfflag=1'.format(url_page)
# 得到响应并解码
res = requests.get(url,headers=headers).content.decode()
# print(res)
# 转类型
soup = BeautifulSoup(res,'lxml')
# print(soup)
# 匹配
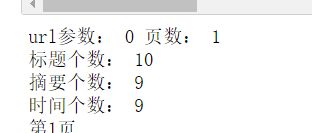
# 1 匹配标题
title = soup.select('.t')
# print(len(title))
dict['title'] = [i.get_text() for i in title]
# 添加进字典
print('标题个数:',len(dict['title']))
# 2 匹配摘要
date = soup.select('.c-abstract')
# print(len(date))
# print(date)
# 摘要部分包含了时间,但时间后面带了一个空格,
# 在编译的时候会输出字符\xa0 ,使用join和split的组合方法去掉
dict['date'] = [''.join(i.get_text().split()) for i in date]
# print(dict['date'])
print('摘要个数:',len(dict['date']))
# 3 匹配时间
t = soup.select('span[class="newTimeFactor_before_abs c-color-gray2 m"]')
# print(t)
dict['time'] = [''.join(i.get_text().split()) for i in t]
# print(dict['time'])
print('时间个数:',len(dict['time']))
print('第{}页'.format(str(page)))
print(dict)
print('===========================')
print('===========================')
url_page += 10
page += 1
time.sleep(0.2)
# 由于方法存在缺陷,有些值并没有抓取。。。。。
得到的数据其实并不相等,而且随着页数的增加,更难去手动添加,对于这个问题,推荐使用方法2

- 爬取方法2(推荐):匹配每一个文章块标签(包含了每个部分想找的东西的标签),同时创建的空字典中,如果键值为空,先赋值一个空列表,如:
dict = {
'page':page,'title':[],'source':[],'date':[],'time':[]}
完整代码为:
%%time
# 数据抓取
data_list = [] # 创建空列表储存数据
# 请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 按时间顺序抓取,页码1-11的pn值为0-100
page = 1
url_page = (page-1) * 10
while page <= 11:
print('url参数:',url_page,'页数:',page)
# 创建空字典存储得到的数据,并将该列表添加进空列表c
dict = {
'page':page,'title':[],'source':[],'date':[],'time':[]}
# print(dict)
# 写法2
# ============================================
# 网址
url = 'https://www.baidu.com/s?wd=%E6%97%85%E8%A1%8C%E9%9D%92%E8%9B%99&pn={}&oq=%E6%97%85%E8%A1%8C%E9%9D%92%E8%9B%99&tn=baiduhome_pg&ie=utf-8&rsv_idx=2&rsv_pq=97f74ecb000e439a&rsv_t=203awND%2FceKGrqADsjLbpJsi0pW3tFrpcVUE23%2FtFWcPLT5Vnz80grVRZHTmbfvED9KL&gpc=stf%3D1515945600%2C1518883200%7Cstftype%3D2&tfflag=1'.format(url_page)
# 得到响应并解码
res = requests.get(url,headers=headers).content.decode()
# print(res)
# 转类型
soup = BeautifulSoup(res,'lxml')
# print(soup)
# 匹配
# 匹配文章块标签(包含了每个部分想找的东西的标签)
news = soup.select('div[class="result c-container new-pmd"]')
# print(news)
# 遍历匹配所需内容
# count = 0
for i in news:
# 1 匹配标题
# 使用select方法得到的数据是列表,必须将其中的值提出来才可以使用get_text()方法提取文本
title = i.select('.t')[0]
# print(title)
# print(title.get_text())
# 添加进字典
# 如果字典的对应键设定是空值(none值),没有设定是空列表,
# 直接使用append方法添加元素对会报错
# 因为append方法无法对none值进行增添
# 可以用if判断,判断是否是none值,如果是就加上一个空列表,也可以直接将原字典中的键值改成是空列表
dict['title'].append(title.get_text())
# print(len(dict['title']))
# 2 匹配摘要
# 摘要值因为同一标签值的原因没有找到,直接赋值会报错,因为代码根本没有找到标签,并不用说提取得到数据的列表元素
# 需要增加try except语句,如果报错就添加特定字符
try:
date = i.select('.c-abstract')
dict['date'].append(''.join(date[0].get_text().split()))
except:
print('空值')
dict['date'].append(''.join('青蛙'))
# print(date)
# print(dict['date'])
# print(len(dict['date']))
# 3 匹配时间
try:
t = i.select('span[class="newTimeFactor_before_abs c-color-gray2 m"]')
dict['time'].append(''.join(t[0].get_text().split()))
except:
print('时间空值')
dict['time'].append(''.join('时间'))
# print(dict['time'])
# 4 匹配出处
try:
source = i.select('div[class="f13 c-gap-top-xsmall se_st_footer user-avatar"]')[0].select('a')[0].get_text()
dict['source'].append(''.join(source.split()))
except:
print('来源空值')
dict['source'].append(''.join('其他网站'))
# print(len(source))
# print(dict['source'])
# 查看每一列的长度
print(len(dict['title']),len(dict['date']),len(dict['time']),len(dict['source']))
print('第{}页'.format(str(page)))
# print(dict)
print('===========================')
print('===========================')
url_page += 10
page += 1
time.sleep(0.2)
# 把字典加入列表中
data_list.append(dict)

爬取成功,而且没有遗漏的值,查看一下此时的列表
data_list,len(data_list)

- 列表或字典转为字符串并保存为json文本
转换的方法可以参考json和python内置数据类型的转换
# 列表或字典转为字符串并保存为json文本
json.dumps(data_list)
with open(r'data2\baidu_news.csv','w',encoding='utf-8') as f:
f.write(json.dumps(data_list))
- 读取JSON数据并转为列表或字典
# 读取JSON数据并转为列表或字典
with open(r'data2\baidu_news.csv','r',encoding='utf-8') as f:
j = json.load(f)
j

- 数据抓取完成
8.4.3 数据规整(基本规整)
将获取数据清理干净
- 基本规整:字符串类数据清洗,操作繁杂,建议使用原生Python来处理
- 详细规整:DataFrame数据集中重构使其适合分析
# 此处为旧版网站的数据规整方式,由于网站改版已经失效,留作备份
'''
# 1: 标题字符串规整
j
j[0]
j[0]['title']
j[0]['title'][0], j[0]['title'][1], j[0]['title'][2]
_ = []
for i in j:
# print(i)
# print(i['title'])
# 将10个1组的列表转为一个大标题列表
_ += ','.join(i['title']).replace(',', '').split('\n') # 列表合为字符串,去除逗号,换行符重新切为列表
print(_)
type(_), len(_)
# 进一步清理
title = []
for i in _:
i2 = i.strip() # 删除字符串前后空值
if i2 != '': # 去除空列表值
title.append(i2)
title
len(title)
# 2:来源和时间字符串规整
j[0]
j[0]['content']
j[0]['content'][1]
# 来源和时间字符串规整,放入列表content
content = []
for i in j:
for i2 in i['content']:
# 过滤和替换掉相应字符,字符串转列表,二维
i3 = i2.replace('\xa0', ' ').replace('\t', '').replace('\n', '').replace('年', '-').replace('月', '-').replace('日', '').split(' ') # 去除各种空值,转为列表
# print(i3)
# 删除列表空值
while '' in i3:
i3.remove('')
if len(i3): # 判断列表值是否整体为空
content.append(i3)
# 去掉 两种 列表,只存储 来源、日期、时间三种数据
# 数据变化,没用了
# if i3 != ['查看更多相关新闻>>'] and i3 != []:
# content.append(i3)
content
len(content)
# 3:将将标题和内容列表值合并入列表c,内层字典存储相关数据
c = []
if len(title) == len(content): # 俩列表长度相同否则退出
for i in range(len(title)): # 遍历值
# 合并两个列表
# print(title[i], content[i])
if len(content[i]) == 3: # 判断content内是否有缺失值
c.append({
'id': i + 1,
'title': title[i], # 标题
'source': content[i][0], # 来源
'date': content[i][1], # 日期
'time': content[i][2], # 时间
})
else:
print(i, '注意:来源列表长度不是3个值,不会写入数据中!')
else: # 长度不一致,错误
print('标题和来源列表长度不一致,错误!')
# 如出现错误可能是抓取问题,可以重新抓取数据后再测试
c
len(c)
'''
将一部分数据拿出来查看
# 8.4.3 数据规整(基本规整)
j[1]['title']

j[1]['title'][0],j[1]['source'][0],j[1]['time'][0],j[1]['date'][0]

- 将标题和内容列表值合并入列表c2,内层字典存储相关数据
一共有11页数据(第一层循环),每页有10个数据,数量和标题数据刚好齐平(第二层数据)
对于时间time,可以使用split方法将字符串整理干净,再用replace方法将一开始判断为空值的时间值替换成统一的时间
# 将标题和内容列表值合并入列表c2,内层字典存储相关数据
c2 = []
# 第一层循环:一共有11页数据
for i in range(len(j)):
# 输出每页的页数和该页的所有标题
# print(i,j[i]['title'])
# 第二层数据:每页有10个数据,数量和标题数据齐平
for i2 in range(len(j[i]['title'])):
# 输出每页页数和该页每个标题的位置下标,每个标题、时间、摘要、网站的位置下标一一对应相同
# print(i,i2)
c2.append({
'title':j[i]['title'][i2],
'source':j[i]['source'][i2],
'date':j[i]['date'][i2],
'time':j[i]['time'][i2].split()[0].replace('时间','2018-2-17').replace('年','-').replace('月','-').replace('日','')
}) #对于时间time,可以使用split方法将字符串整理干净,再用replace方法将一开始判断==为空值==的时间值替换成统一的时间
c2
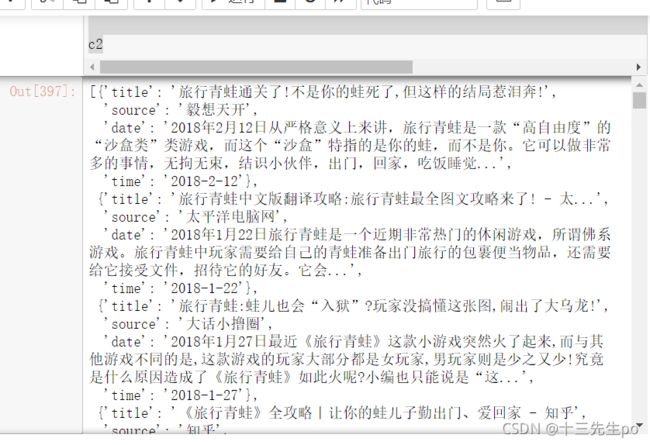
- 列表转为DataFrame
data = pd.DataFrame(c2)
data

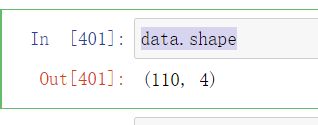
- 检查数据类型
data.info()

data.shape
- 保存数据
# 保存数据
data.to_csv(r'data2\content.csv',index=False)

8.4.4 数据规整(进阶)
使用Pandas,根据分析思路对数据详细规整
- 读取数据
# 数据规整(进阶)
# 读取数据
data = pd.read_csv(r'data2\content.csv',
parse_dates=['time'] # 字符串列转时间类型
).set_index('time').sort_index() # 时间列转行索引,排序
data.head().append(data.tail())

- 检查数据
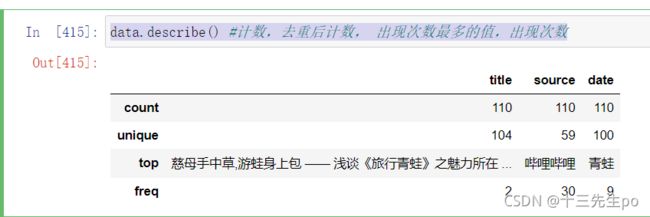
# 检查数据
data.info()

data.index

data.describe() #计数,去重后计数, 出现次数最多的值,出现次数
- 新闻数据正常
8.4.5 合并百度指数和百度新闻两表
目前有的两份表
# 合并百度指数和百度新闻两表
baidu.head()
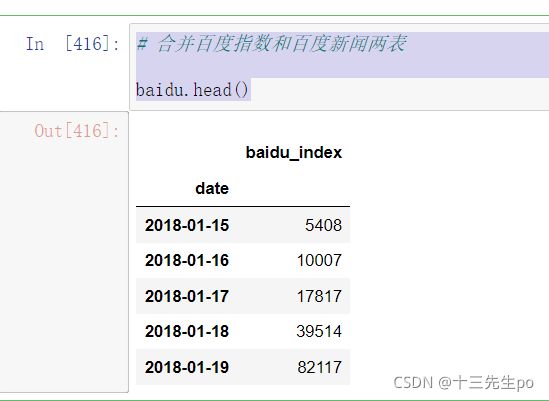
data.head()

- 查看两个组数据的维度数量差别
baidu.shape,data.shape

- 按索引合并两表
# 按索引合并两表
# data.join(baidu)
# 合并后数据可能有缺失值,将缺失值行删除
data2 = data.join(baidu).dropna()
data2
# 数据类型如果异常,修改
# data2.info()
data2['baidu_index'] = data2['baidu_index'].astype(np.int)
# 重新设置索引列的名字
data2.index.name = 'time'
data2.head()
# data2.info()
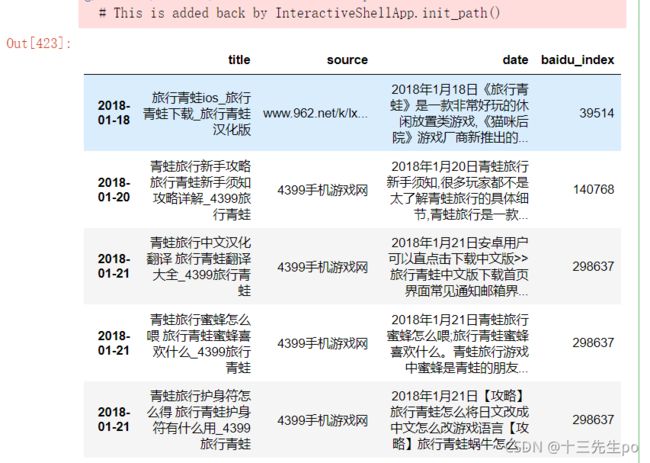
- 检查数据类型
data2.info()
- 保存数据
之前保存的2个原始数据,数据分析时使用这个清洗后的数据,记得这里要保留索引列(时间),不用更改方法里面的index参数状态
# 保存数据
data2.to_csv(r'data2\content2.csv')
- 读取数据
# 读取数据
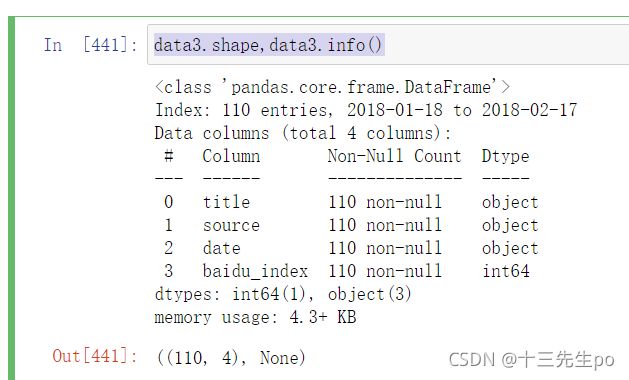
data3 = pd.read_csv(r'data2\content2.csv',
).set_index('time').sort_index() # 时间列转行索引,排序
data3.head().append(data3.tail())

- 检查读取出来的数据
data3.shape,data3.info()
data3.describe()

8.5 实操之数据处理
8.5.1 基于搜索引擎的产品推广策略的背景介绍
-
SEO:搜索引擎优化
- 内容
- 外链
-
SEM:搜索引擎营销
-
搜索引擎优化的意义
搜索引擎作为传统互联网的主要数据源,在信息传播过程中占有重要地位
个人发布信息被搜索引擎收录、展示,可以引来流量,以较低成本实现产品推广 -
搜索引擎优化途径:
在搜索引擎可以检索到的各种公开社区发布文章,为自己的产品引流。
如:论坛社区、问答、贴吧、博客、视频、自媒体等等
8.5.2 游戏产品的搜索引擎推广策略
- 排名分析
- 选择什么渠道?(在哪儿发软文)
- 选择相关内容搜索排名靠前的网站发布信息
- 流量监测
- 发布信息时间?
- 监测不同网站流量效果,调整推广渠道
- 内容设计(标题)
- 发布信息标题和内容的设计
- 精心设计标题,吸引用户点击
8.5.3 2018年1-2月最火的游戏:旅行青蛙 的游戏介绍和数据分析境界
游戏介绍
- 游戏情况
- 《旅行青蛙》是由游戏公司HIT-POINT开发的休闲小游戏,一款放置类型手游
- 游戏内容
- 玩家通过收集三叶草去商城买东西,青蛙带着这些东西出门旅行,旅行途中拍照片邮寄回来
- 社会反响
- 这款游戏顺应了广大青年的佛系情感述求。成为社交圈刷屏的现象级游戏,产生了巨大的社会影响
境界浅析
做翻译的两种境界:
是忠于原著严格将译文翻译为原著一样好
还是自我发挥,将原著本地化好?
做记者的两种境界:
是忠于事实只报道现实好
还是对事情有个人判断,偏向性的报道好?(有态度的报道)
写数据分析报告的两种境界
是忠于数据,严格按数据表现的事实写报告好
还是分析前已经对事物有自己的判断,分析只是证明或证伪自己的判断好?
8.5.4 推广策略研究
流行的引爆取决于三类人的先后贡献 --- 《引爆点》
任何一场潮流到来时,总有几个关键的人物,他们独有的社会关系和其他特点,如激情和个人魅力,能够快速将信息在一定范围散布开来。
具体来说。流行的引爆取决于三类人的先后贡献,如果在引爆潮流的不同时期,找准人群中的个别关键人物,利用他们来传播信息,就能点燃潮流
流行引爆的三个不同时期:
前期:内行(专业人士,产生信息)
- 某一领域有丰富知识的权威人士
- 在前期实现原始信息的产生
- 内行专业且乐于讨论分享,但没有很好的说服力
----如专业社区,专业圈子,如某软件或游戏等产品论坛
中期:联系员(桥梁,从专业小圈子介绍传播到大众圈)
- 什么人都认识的交际人才
- 其人际和社会关系可同时涉及几种不同领域
- 联系员能够将信息从某固定小圈子散布到其他更大的领域
----如行业社区、行业圈子,如互联网社区、帝吧、虎扑、知乎,原创自媒体
后期:推销员(口耳相传,扩散,引爆)
- 对信息领域未必了解,但具有说服力
- 决定了信息传播的“最后一公里”
- 推销员使信息病毒式扩散,实现最终引爆
----如大众社区,大众圈子,如各种自媒体、微博、微信朋友圈,腾讯网易新浪搜狐等传统媒体、报纸电视广播等
举例
中文互联网流行词或梗的流行全过程
如:六学/明学/时间管理
流行过程:直播(孙笑川) -> 虎扑,贴吧,抖音,知乎、B站,豆瓣,微博,公众号 -> 网易搜狐新浪腾讯新闻 -> 电视 -> 春晚
8.5.5 数据分析之指标计算:渠道分析(新闻源)
自定义指标
source列为搜索引擎推广渠道,我们按照理论将其分为:
- 前期:内行
- 中期:联系员
- 后期:推销员
三类
然后统计不同渠道的新闻数量,目前数据的状态
data3

- 查询所有新闻源和他们发布的文章数(#垃圾进 垃圾出)
写法1:查看所有
cate = data3.groupby('source').size().sort_values(ascending=False)
cate

写法2:按发布数据排序后控制选择发布次数
# 写法2
cate = data3.source.value_counts()
# 设置条件筛选
cate[cate>=2]
#垃圾进 垃圾出
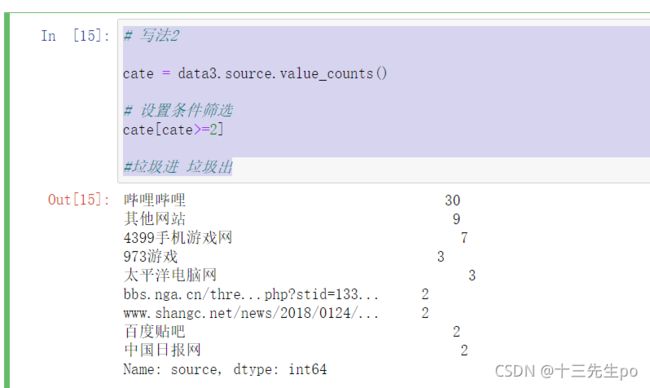
- 手动整理的三个时期典型网站
前期:973游戏,4399手机游戏网
中期:百度贴吧,哔哩哔哩
后期:太平洋电脑网,中国日报网
- 查询其中一个网站的数据
# 查询其中一个网站的数据
data3[data3.source == '4399手机游戏网']

- 手动分类并使用loc方法自动生成列
# 手动分类
n1 = ['973游戏','4399手机游戏网']
n2 = ['百度贴吧','哔哩哔哩']
n3 = ['太平洋电脑网','中国日报网']
# 查询符合条件的数据
cate2 = data3[data3.source.isin(n1) | data3.source.isin(n2) | data3.source.isin(n3)]
# 生成列
cate2.loc[cate2.source.isin(n1),'period'] = 1
cate2.loc[cate2.source.isin(n2),'period'] = 2
cate2.loc[cate2.source.isin(n3),'period'] = 3
cate2

- 查看数据类型并适当规整(完成了浮点数的转换)
# 查看数据类型并适当规整
cate2.info()
#转化浮点数
#先删除(重新替换)列
cate3 = cate2.dropna().drop('period',axis=1) #去除缺失值行和period列
cate3['period'] = cate2.dropna()['period'].astype(np.int) # 重新添加去除缺失值行的数据并转换类型
cate3
原本是float类型,现在变成了int类型

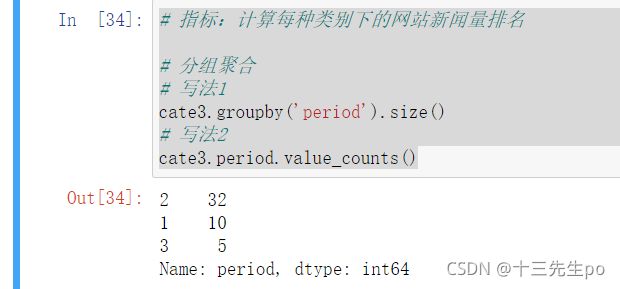
指标:计算每种类别下的网站新闻量排名
# 指标:计算每种类别下的网站新闻量排名
# 分组聚合
# 写法1
cate3.groupby('period').size()
# 写法2
cate3.period.value_counts()
- 交叉表查看
# 交叉表查看
cross = pd.crosstab(cate3.source,cate3.period)
cross

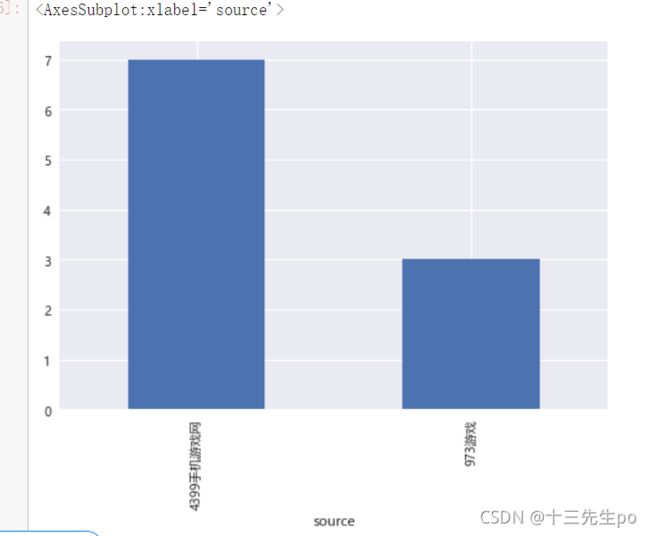
- 前期新闻源发帖量排名
写法1:用交叉表查询
# 前期新闻源发帖量排名
# 写法1:用交叉表查询
b1 = cross[1][cross[1]>0].sort_values(ascending=False)
b1

写法2:用手动分类的数据查询
# 写法2:用手动分类的数据查询
b11 = cate3[cate3['period']==1].source.value_counts()
b11

- 前期新闻源发帖量排名可视化
plt.style.use('seaborn') # 改变图像风格
plt.rcParams['font.family'] = ['Arial Unicode MS', 'Microsoft Yahei', 'SimHei', 'sans-serif'] # 解决中文乱码
plt.rcParams['axes.unicode_minus'] = False # simhei黑体字 负号乱码 解决
b1.plot.bar()
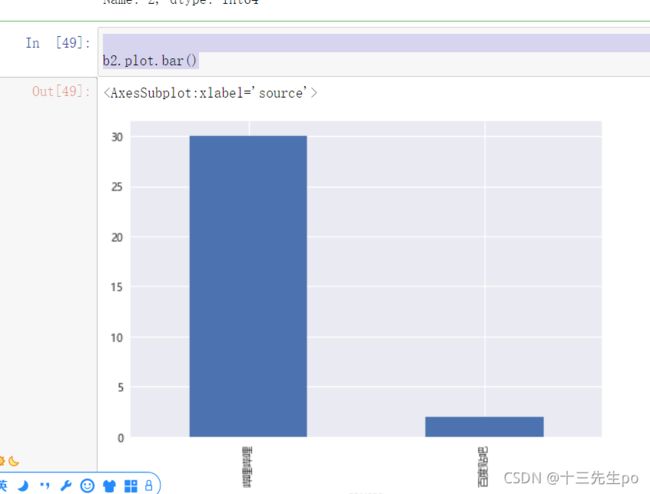
- 中期新闻源发帖量排名
# 中期新闻源发帖量排名
b2 = cross[2][cross[2]>0].sort_values(ascending=False)
b2
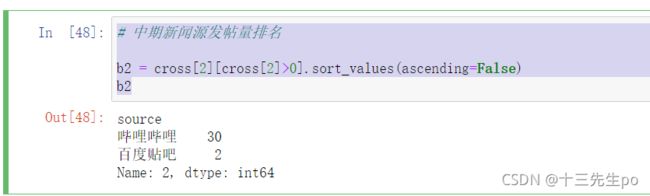
- 中期新闻源发帖量排名可视化
b2.plot.bar()
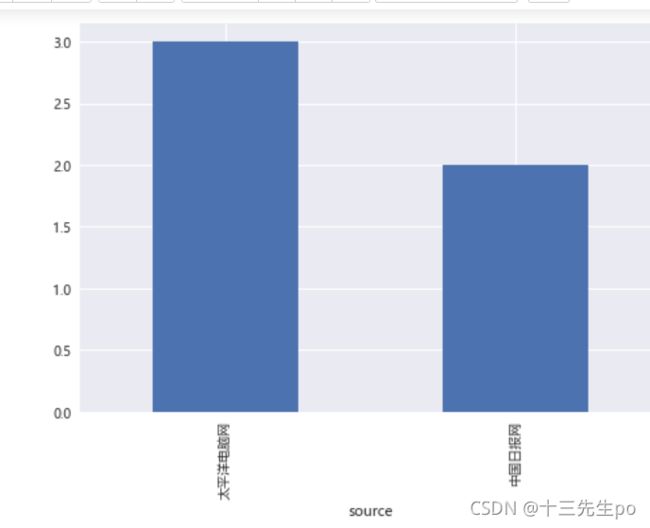
- 后期新闻源发帖量排名
# 后期新闻源发帖量排名
b3 = cross[3][cross[3]>0].sort_values(ascending=False)
b3
- 后期新闻源发帖量排名可视化
b3.plot.bar()
查询每天的百度指数
目前数据情况
cate3

- 按索引日期分组聚合,筛选出其中最大值
# 查询每天的百度指数
cate3['baidu_index'] # 全是不一样的值,不能直接用来分组聚合
cate3.index
# 按索引日期分组聚合,筛选出其中最大值
baidu_index = cate3.groupby(cate3.index)['baidu_index'].max()
baidu_index,baidu_index.shape

- 按时间行索引分组聚合求每个分类下 每天的新闻数
三个时期,每个时期的新闻源 每天 发布新闻的个数
# 三个时期,每个时期的新闻源 每天 发布新闻的个数
# 前期
period1 = cate3[cate3['period']==1]
period1
count1 = period1.groupby(period1.index).size()
count1
# 中期
period2 = cate3[cate3['period']==2]
period2
count2 = period2.groupby(period2.index).size()
count2
# 后期
period3 = cate3[cate3['period']==3]
period3
count3 = period3.groupby(period3.index).size()
count3

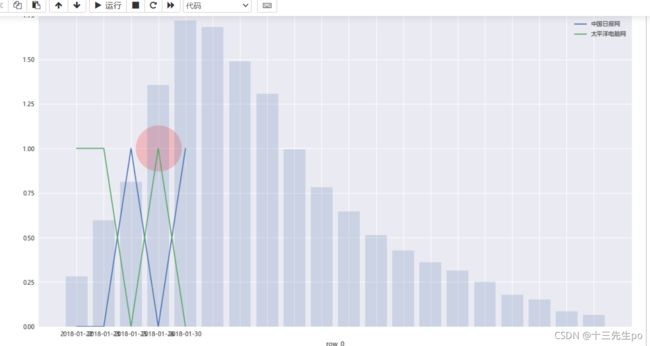
- 数据可视化
三种类别的推广渠道 随时间发展 对百度指数热度的贡献趋势
- 可视化:搜索引擎推广渠道VS百度指数,比较对照
取三类网站新闻数量随时间变化画三条折线图,背景叠加百度指数柱状图
主要看不同类别折线的峰值出现时间(先后代表三类过程)
# 数据可视化
# 取三类网站新闻数量随时间变化画三条折线图,背景叠加百度指数柱状图
# 主要看不同类别折线的峰值出现时间(先后代表三类过程)
# 绘制
plt.figure(figsize=(18,10))
# 百度指数的柱状图
#修改数量值,使前中后期数据可见
plt.bar(baidu_index.index,baidu_index/160000,alpha=0.2,label='百度指数')
# 前中后期发帖数量的折线图
count1.plot(label='前期:内行',color='r')
count2.plot(label='中期:联系员',color='b')
count3.plot(label='后期:推销员',color='g')
# 标识三个时期的典型特征
plt.scatter(['2018-01-20','2018-01-27','2018-01-21'],[1,4,3],s=6000,alpha=0.2,color='r')
# 辅助显示
plt.legend()
# 标签
plt.xticks(baidu_index.index)
plt.show()

- 结论:
呈现明显的前、中、后期发展趋势- 数据验证偏差:
可能因为新闻源分类错误,可根据分析结果重新调整新闻源分类
更大的原因:数据搜集不完整,如缺乏其他重要渠道数据(APP市场、微博、微信朋友圈等)
又或者公司根本没有采用搜索引擎推广,而是碰巧火了
- 数据验证偏差:
8.5.6 数据分析之流量监测(指标:各个分类下的网站,每天发帖量)
先查看一下目前每个时期的新闻源
# 流量监测
period1.head()
period2.head()
period3.head()

- 交叉表
# 交叉表
pc1 = pd.crosstab(period1.index,period1.source)
pc1
pc2 = pd.crosstab(period2.index,period2.source)
pc2
pc3 = pd.crosstab(period3.index,period3.source)
pc3

- 分别分析三个时期的渠道情况
前期各网站发帖数量趋势
内行:
前期渠道:游戏网站(专业社区类)
作用:信息源,提供原始信息
游戏网站内部,行家们进行信息的碰撞、交互和传递,形成原始信息
# 分别分析三个时期的渠道情况
# 前期可视化
# 发帖量
pc1.plot(figsize=(18,10))
# 百度指数
plt.bar(baidu_index.index,baidu_index/500000,alpha=0.2,label='百度指数')
# 辅助显示
plt.scatter(['2018-01-22'],[3],s=6000,alpha=0.2,color='r')

中期各网站发帖数量趋势
联系员:
中期渠道:一些通用和专业结合的社区
作用:粘合剂:连接内行与推销员
借助百度搜索的独特优势,将信息从内行传递给推销员
# 中期可视化
# 发帖量
pc2.plot(figsize=(18,10))
# 百度指数
plt.bar(baidu_index.index,baidu_index/500000,alpha=0.2,label='百度指数')
# 辅助显示
plt.scatter(['2018-01-27'],[4],s=6000,alpha=0.2,color='r')
plt.xticks(baidu_index.index)

后期各网站发帖数量趋势
推销员:
后期渠道:大众新闻网站、自媒体,包括新闻、视频、社交媒体等
作用:完成最后接力,实现引爆
标记引爆点,使信息病毒式传播
# 后期可视化
# 发帖量
pc3.plot(figsize=(18,10))
# 百度指数
plt.bar(baidu_index.index,baidu_index/500000,alpha=0.2,label='百度指数')
# 辅助显示
plt.scatter(['2018-01-23'],[1],s=6000,alpha=0.2,color='r')
plt.xticks(baidu_index.index)
8.5.7 数据分析之内容设计(词云)
- 各时期新闻标题设计:关键字查看和可视化
导入词云库
# 各时期新闻标题设计:关键字查看和可视化
import jieba
import jieba.analyse
- 合并三种类别来源的title为字符串
# 合并三种类别来源的title为字符串
title_list1 = ' '.join(period1['title']) # 空格隔开每条字符串
title_list2 = ' '.join(period2['title']) # 空格隔开每条字符串
title_list3 = ' '.join(period3['title']) # 空格隔开每条字符串
title_list3
- 分词
1 应用自定义的词典
# 分词
# 1 应用自定义的词典
jieba.load_userdict(r'data\custom.txt')
2 分词
# 2 分词
p1f = jieba.lcut(title_list1)
p2f = jieba.lcut(title_list2)
p3f = jieba.lcut(title_list3)
p3f

3 保存分词后的文本为文本文件,绘制词云用
# 3 保存分词后的文本为文本文件,绘制词云用
' '.join(p1f) # join方法以空格隔开每个词并输出字符串
with open(r'data/p1title.txt','w',encoding='utf-8') as f:
f.write(' '.join(p1f))
with open(r'data/p2itle.txt','w',encoding='utf-8') as f:
f.write(' '.join(p2f))
with open(r'data/p3itle.txt','w',encoding='utf-8') as f:
f.write(' '.join(p3f))

4 去停用词
# 4 去停用词
def stopw(period):
stopword = []
with open('jieba/stopword.txt', 'r', encoding='utf-8') as f:
for line in f.readlines():
l = line.strip()
if l == '\\n':
l = '\n'
if l == '\\u3000':
l = '\u3000'
stopword.append(l)
# stopword
# 去停用词,第一步,求差集
x = np.array(period) # 将分好的词列表转为数组
y = np.array(stopword) # 将停用词转为数组
z = x[~np.in1d(x,y)] # x的元素是否包含于y
k = [i for i in z if len(i) > 1]
return k
stopw(p1f) # 去停用词
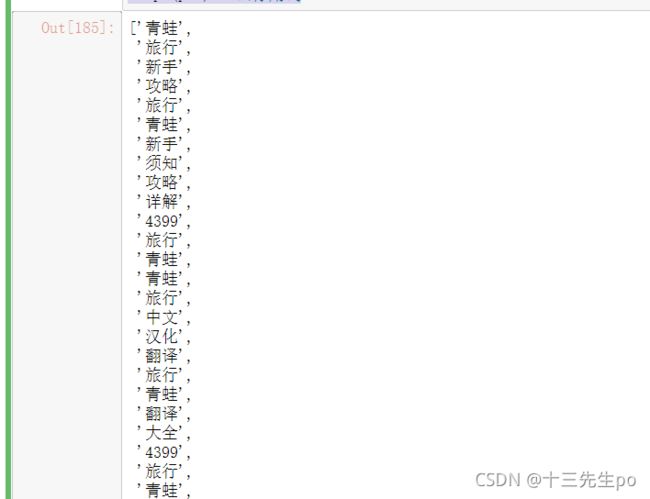
- 计算词频并排序
# 计算词频并排序
t1 = pd.Series(stopw(p1f))
pc1 = t1.value_counts()
pc1.head()
t2 = pd.Series(stopw(p2f))
pc2 = t2.value_counts()
pc1.head()
t3 = pd.Series(stopw(p3f))
pc3 = t3.value_counts()
pc3.head()

- 5 保存结果
# 5 保存结果
type(pc3) # pandas.core.series.Series
pc3.reset_index() # 可以将Series结构变成dataframe结构
pc1.reset_index().to_csv(r'data\kewword1.csv',index=False)
pc2.reset_index().to_csv(r'data\kewword2.csv',index=False)
pc3.reset_index().to_csv(r'data\kewword3.csv',index=False)

- 词云绘制,打开分词后的保存文本,注意是!!分词后的文本,即没有频数的那一份!!!
比表格高频词更直观
# 打开分词后的保存文本,注意是!!分词后的文本,即没有频数的那一份!!!
with open(r'data\p1title.txt','r',encoding='utf-8') as f:
ptitle1 = f.read()
ptitle1
with open(r'data\p2itle.txt','r',encoding='utf-8') as f:
ptitle2 = f.read()
ptitle2
with open(r'data\p3itle.txt','r',encoding='utf-8') as f:
ptitle3 = f.read()
ptitle3

- 读入停用词文件为列表
# 读入停用词文件为列表
with open(r'jieba\stopword.txt','r',encoding='utf-8') as f:
s = f.read()
stopword = s.split('\n')
stopword

- 读取背景图
# 读取背景图
alice_mask = np.array(Image.open(r'jieba\timg.jpg'))

- 分词,提取高频词,绘制词云
前期标题设计特点:攻略、问题相关,铺垫,技术型文章,比较硬
# 前期
wordcloud = WordCloud(
background_color = 'white',# 设置背景颜色
max_words=30,# 设置最大现显示词数
font_path='jieba/arial unicode ms.ttf',# 字体,不设置则汉字乱码
stopwords=stopword,# 去停用词
mask=alice_mask# 设置背景图片
).generate(ptitle1)
wordcloud
plt.figure(figsize=(18, 10), dpi=300)
plt.imshow(wordcloud, interpolation='bilinear') # 绘制数据内的图片,双线性插值绘图
plt.axis("off") # 去掉坐标轴

中期标题设计特点:内容相关,造势
# 中期
wordcloud = WordCloud(
background_color = 'white',
max_words=30,
font_path='jieba/arial unicode ms.ttf',
stopwords=stopword,
mask=alice_mask
).generate(ptitle2)
wordcloud
plt.figure(figsize=(18, 10), dpi=300)
plt.imshow(wordcloud, interpolation='bilinear') # 绘制数据内的图片,双线性插值绘图
plt.axis("off") # 去掉坐标轴

后期标题设计特点:标签相关,提供话题,如佛系、儿子、爆红等
# 后期
wordcloud = WordCloud(
background_color = 'white',
max_words=30,
font_path='jieba/arial unicode ms.ttf',
stopwords=stopword,
mask=alice_mask
).generate(ptitle3)
wordcloud
plt.figure(figsize=(18, 10), dpi=300)
plt.imshow(wordcloud, interpolation='bilinear') # 绘制数据内的图片,双线性插值绘图
plt.axis("off") # 去掉坐标轴

- 摘要分词(类似上面的步骤)
注意点:摘要部分有x年x月x日字样 要提前去掉,系统会默认切割,可以使用如下代码去掉
# 生成日期列表
date_list = ['2018年{}月{}日'.format(str(i+1),str(j)) for i in range(2) for j in range(31)]
# 将‘2018年’捆绑在一起
jieba.del_word('2018年')
# 或者jieba.add_word('2018年') 需要看实际情况
date_listcut = jieba.lcut(' '.join(date_list))
date_listcut
目前的代码

合并所有字符串
# 摘要分词
# 合并所有字符串
datah1 = ' '.join(period1['date'])
datah2 = ' '.join(period2['date'])
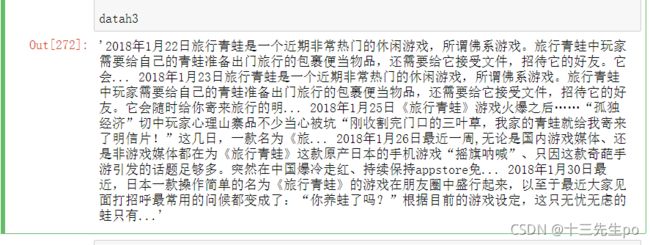
datah3 = ' '.join(period3['date'])
datah3
1 应用自定义的词典
# 1 应用自定义的词典
jieba.load_userdict(r'data\custom.txt')
2 分词
# 有x年x月x日字样 要提前去掉,系统会默认切割
# 生成日期列表
# date_list = ['2018年{}月{}日'.format(str(i+1),str(j)) for i in range(2) for j in range(31)]
# jieba.del_word('2018年')
# date_listcut = jieba.lcut(' '.join(date_list))
# date_listcut
# 2 分词
d1f = jieba.lcut(datah1)
d2f = jieba.lcut(datah2)
d3f = jieba.lcut(datah3)
d3f
def stopw(period):
date_list = ['2018年{}月{}日'.format(str(i+1),str(j)) for i in range(2) for j in range(31)]
date_listcut = jieba.lcut(' '.join(date_list))
with open('jieba/stopword.txt', 'r', encoding='utf-8') as f:
for line in f.readlines():
l = line.strip()
if l == '\\n':
l = '\n'
if l == '\\u3000':
l = '\u3000'
date_listcut.append(l)
for i in range(30):
date_listcut.append(i)
# stopword
# 去停用词,第一步,求差集
x = np.array(period) # 将分好的词列表转为数组
y = np.array(date_listcut) # 将停用词转为数组
z = x[~np.in1d(x,y)] # x的元素是否包含于y
k = [i for i in z if len(i) > 1]
return k
' '.join(stopw(d1f)) # 转换文本
' '.join(stopw(d2f))
' '.join(stopw(d3f))

3 保存分词后的文本为文本文件
# 3 保存分词后的文本为文本文件,绘制词云用
' '.join(p1f) # join方法以空格隔开每个词并输出字符串
with open(r'data/p1data.txt','w',encoding='utf-8') as f:
f.write(' '.join(d1f))
with open(r'data/p2data.txt','w',encoding='utf-8') as f:
f.write(' '.join(d2f))
with open(r'data/p3data.txt','w',encoding='utf-8') as f:
f.write(' '.join(d3f))
前期
# 前期
wordcloud = WordCloud(
background_color = 'white',# 设置背景颜色
max_words=30,# 设置最大现显示词数
font_path='jieba/arial unicode ms.ttf',# 字体,不设置则汉字乱码
mask=alice_mask# 设置背景图片
).generate(' '.join(stopw(d1f)))
wordcloud
plt.figure(figsize=(18, 10), dpi=300)
plt.imshow(wordcloud, interpolation='bilinear') # 绘制数据内的图片,双线性插值绘图
plt.axis("off") # 去掉坐标轴

中期
# 中期
wordcloud = WordCloud(
background_color = 'white',# 设置背景颜色
max_words=30,# 设置最大现显示词数
font_path='jieba/arial unicode ms.ttf',# 字体,不设置则汉字乱码
mask=alice_mask# 设置背景图片
).generate(' '.join(stopw(d2f)))
wordcloud
plt.figure(figsize=(18, 10), dpi=300)
plt.imshow(wordcloud, interpolation='bilinear') # 绘制数据内的图片,双线性插值绘图
plt.axis("off") # 去掉坐标轴

# 后期
wordcloud = WordCloud(
background_color = 'white',# 设置背景颜色
max_words=30,# 设置最大现显示词数
font_path='jieba/arial unicode ms.ttf',# 字体,不设置则汉字乱码
mask=alice_mask# 设置背景图片
).generate(' '.join(stopw(d3f)))
wordcloud
plt.figure(figsize=(18, 10), dpi=300)
plt.imshow(wordcloud, interpolation='bilinear') # 绘制数据内的图片,双线性插值绘图
plt.axis("off") # 去掉坐标轴

8.6 总结
8.7 游戏类产品搜索引擎推广建议
- 渠道选取
- 游戏专业社区
- 互联网类社区
- 通用社区,自媒体
- 时间点选取
- 前期
- 中期
- 后期
- 标题设计
- “攻略”铺垫
- “内容”造势
- “标签”话题
8.8 时间点选取详细:
-
内行
- 前期铺垫
- 在专业网站上发布游戏评测、软文等,提供下载、攻略、汇总、大全等
- 吸引内行注意,激励其积极讨论
-
联系员
- 中期造势
- 在IT、互联网类专业社区等搜索引擎检索信息源集中投放广告、发布软文
- 使非内行开始接触游戏信息
-
推销员
- 后期话题
- 制造话题,蹭热度,创造新鲜有趣、与众不同的游戏标签,在各大通用社区(新浪、网易、朋友圈、微博热搜)等火力全开
- 利用黏性话题踢好临门最后一脚