07_MapReduce_深入浅出_note
MapReduce
1.1 分布式并行编程
-
概述
- MapReduce是一种分布式并行编程框架
- cpu从05年便不再受摩尔定律控制,数据处理性能无法跟上爆发式增长的大数据
- 数据处理能力提升的两条路线:
- 单核CPU–>双核–>八核
- 分布式并行编程:
- 借助一个集群通过多台机器同时并行处理大规模数据集
- 数据处理能力提升的两条路线:
-
hadoop集成了MapReduce作为其两个核心组件之一
- 解决分布式数据存储的HDFS
- 解决分布式数据处理的Hadoop_MapReduce
-
相关的并行编程框架:
- MPI:消息传递接口,一种非常典型的并行编程框架
- OpenCL
- CUDA
- FL(Federal Learning):一种基于机器学习的分布式并行框架。
-
MapReduce和传统的并行框架的区别
1.2 MapReduce模型简介

MapReduce的策略
1. MapReduce采用分而治之
2. 把非常庞大的数据集,切分成非常多的独立的小分片
3. 为每一个数据分片单独地启动一个map任务
4. 通过多个map任务,并行地在多个机器上处理
MapReduce的理念
- 计算向数据靠拢,而不是数据向计算靠拢
- 传统的计算方法–数据向计算靠拢:
- 要完成一次数据分析时,选择一个计算节点,把运行数据分析的程序放到计算节点上运行
- 然后把它涉及的数据,全部从各个不同的节点上拉过来,传输到计算发生的地方

- MapReduce–计算向数据靠拢

- 传统的计算方法–数据向计算靠拢:
Master/slave的架构

Map函数

Reduce函数

2.MapReduce体系结构
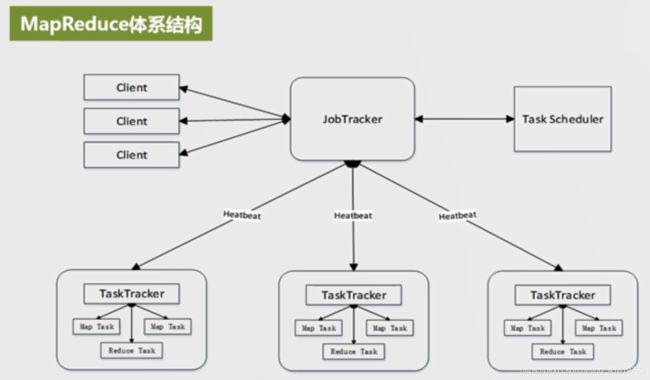
Client(客户端)
- 通过Client可以提交用户编写的应用程序,用户通过Client将应用程序提交到JobTracker端
- 通过Client提供的一些接口可以查看当前提交作业的运行状态
JobTracker(作业跟踪器)
- 负责资源的监控和作业的调度
- 监控底层的其他TaskTracker以及当前运行的Job健康情况
- 一旦探测到失败的情况就把这个任务转移到其他节点,继续跟踪任务执行进度和资源使用量
TaskTracker(任务调度器)
- 执行具体的相关任务:一般接收jobTracker发送过来的命令并执行
- 把自己的资源使用情况,以及任务的运行进度通过心跳*(heartbeat)*的方式发送给JobTracker
slot(槽)
- 在MapReduce中有两种slot
- Map类型的slot:供map任务使用
- reduce类型的slot:供reduce任务使用
- 两种slot无法相互转换
- 如果有空闲的Map类型的slot,TaskTracke则把MapTask分配给该slot执行
- 如果有空闲的reduce类型的slot,TaskTracke则把ReduceTask分配给该slot执行
Task(任务)
-
任务有两种,都是由TaskTracker来启用的:
- map任务
- map函数
- reduce任务
- reduce函数
- map任务
-
在同一个机器下面,这两种任务可以同时处理
3. MapReduce工作流程
MapReduce工作流程概述

- 注意:数据来源即输入(读操作)是HDFS,数据输出(写操作)也是在HDFS中
- 不同的map()任务之间不会进行通信
- 不同的Reduce()任务之间也不会进行通信
MapReduce各个执行阶段
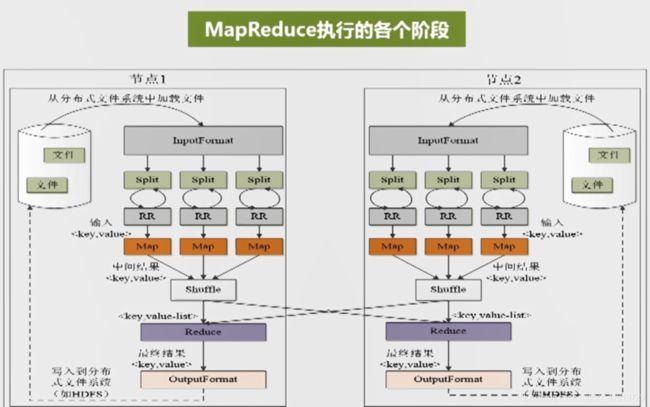
分片(split)
- InputFormat会把大的文件分割成很多个分片(split)

- 分片又会被HDFS分个大小不一的各个数据块block
- 一般来说将一个HDFS数据块的大小作为分片的大小
- 分片的个数就代表则需要并行处理多少个Map()任务
Reduce任务的数量
-
最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目
-
通常设置比reduce任务槽数目少一些的Reduce任务个数(这样可以预留一些系统资源处理可能发生的错误)
4. shuffle过程原理
shuffle过程简介

- 整个shuffle过程包含
- Map端的shuffle
- Reduce端的shuffle
Map端的shuffle过程

- 输入数据和执行map任务
- 从HDFS读取数据(各种类型如.txt文件,二进制文件)
- 将数据进行分片,将多个数据分片交给RecordReader处理
- 通过RecordReader将数据的文件格式统一并输入这些数据到MapReduce的Map任务处理器进行处理
- 写入缓存
- 对于每个Map任务,MapReduce都会分配一个默认的缓存(默认100M)给它使用
- 缓存的作用是缓解寻址开销
- 缓存一旦写满或到达某个设定门槛(溢写比),进入溢写进程
- 溢写
- 分区
- Map()任务输出的一堆键值对最终是交给多个不同的Reduce()任务处理的,所以要进行分区操作交由不同的Reduce()处理
- 分区默认使用Hash函数
- 排序
- 分区后,系统会默认通过key来对各个分区的数据进行排序
- 合并(combine)
- 合并是为了减少溢写到磁盘当中的数据量
- 如:自定义combine函数 {a:1}{a:2} --合并-> {a:3}
- 这样的操作会减少很多的键值对,往磁盘写入的数据量就会大大减少
- 分区
- 文件归并
- 每次溢写都会生成一个磁盘文件,多次溢写后会生成一堆磁盘文件
- 在整个Map()任务运行结束之前,系统会把这些溢写的磁盘文件进行归并成一个大的文件
- 最后将这个大的文件放到本地磁盘中
- JobTracker探测到文件归并进程结束,JobTracker就会通知相应的Reduce()任务把属于各自的分区数据拉走处理
Reduce端的shuffle过程
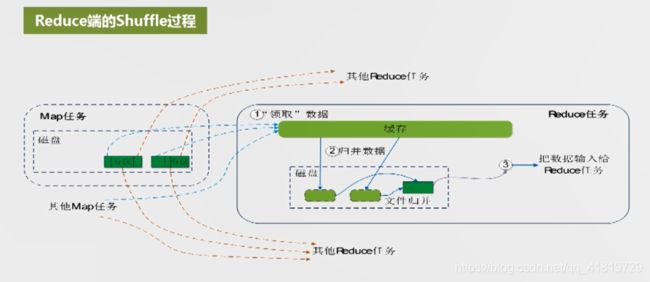
- 归并数据
- 是合并数据的逆向操作
- 如{a:3}–归并–>{a,{1,2}}
- 将map
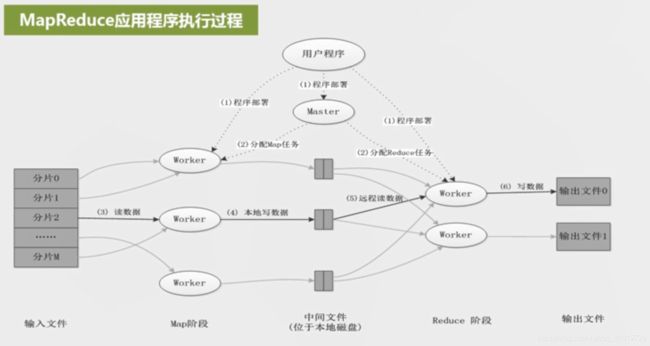
5. MapReduce应用程序执行过程
6.实例分析:WordCount
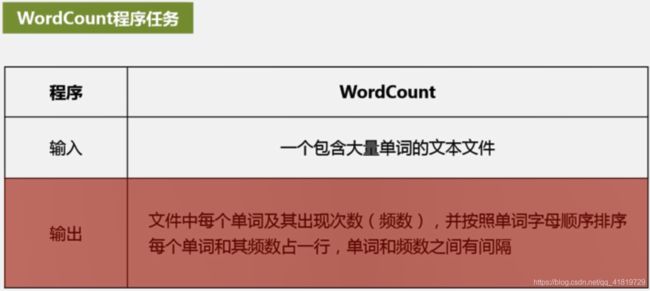
WordCount程序任务
-
输入:一个包含大量单词的文本文件
-
输出:文件中每个单词出现次数,并按照单词字母顺序排序,每个单词和其词频占一行,单词和词频之间有间隔

-
注意,只有满足可以分而治之的数据集才能用MapReduce进行处理,若数据集之间结果有强依赖,则无法利用Hadoop_MapReduce
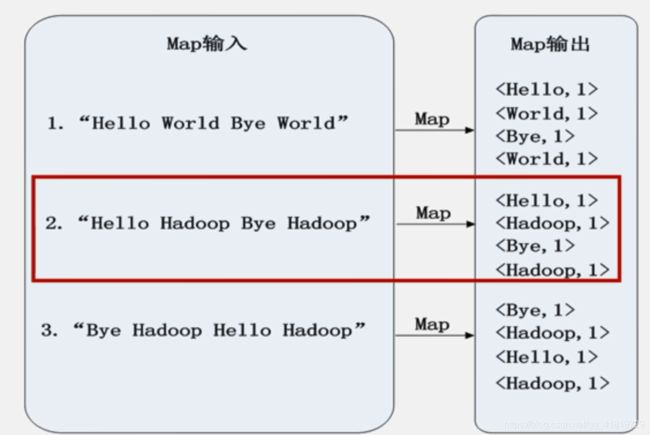
WordCount设计思路
-
WordCount程序能不能用MapReduce去做?
- Yes,可以把文本文件内容切分给多个Map任务,各自统计和排序。最后利用Reduce任务汇总
-
若用户没有定义combine函数

-
若用户定义了combine函数

7. MapReduce具体应用



8. MapReduce编程实践
任务要求

分析

-
Map处理逻辑
-
输入类型
-
输出类型<单词,单词出现次数>,如
-
自定义类MyMapper继承MapperReduce提供的Mapper类
- 重写Mapper提供的map()函数,编写Map处理逻辑:

-
-
Reduce处理逻辑
-
输入类型
-
输出类型
-
自定义MyReducer类继承MapReduce提供的Reducer类
- 重写reduce()方法,编写reduce处理逻辑

-
-
main函数

-
完整代码


import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* 定义一个主类WordCount,用来描述job并提交job
* 相当于一个Hadoop集群的客户端,
* 需要在此封装我们的MapReduce程序相关运行参数,指定jar包
* 最后提交给Hadoop
* @author Administrator
*/
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
// 1 获取配置信息,或者job对象实例
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] " );
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
// 2 指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
// 3 指定最终输出数据的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 4 指定job的输入原始文件所在目录
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/**
* KEYIN:默认情况下,是MapReduce框架所读到的一行文本的起始偏移量,int;
* 在hadoop中有自己的更精简的序列化接口,所以不直接用Int,而是用IntWritable
* VALUEIN:默认情况下,是MapReduce框架所读到的一行文本内容,String;此处用Text
* KEYOUT:是用户自定义逻辑处理完成之后输出数据中的key,在此处是单词,String;此处用Text
* VALUEOUT,是用户自定义逻辑处理完成之后输出数据中的value,在此处是单词次数,Integer,此处用IntWritable
*
* @author Administrator
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
/**
* map阶段的业务逻辑就写在自定义的map()方法中 maptask会对每一行输入数据调用一次我们自定义的map()方法
*/
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 1 将maptask传给我们的文本内容先转换成String,并且利用工具类StringTokenizer根据空格将这一行切分成单词
StringTokenizer itr = new StringTokenizer(value.toString());
// 2 将单词输出为<单词,1>
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
// 将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reducetask中
context.write(this.word, one);
}
}
}
/**
* KEYIN , VALUEIN 对应mapper输出的KEYOUT, VALUEOUT类型
* KEYOUT,VALUEOUT 对应自定义reduce逻辑处理结果的输出数据类型 KEYOUT是单词 VALUEOUT是总次数
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
/**
* key,是一组相同单词kv对的key
*/
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
// 1 汇总各个key的个数
for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable) i$.next();
}
// 2输出该key的总次数
this.result.set(sum);
context.write(key, this.result);
}
}
}
- 编译打包代码




使用Eclipse编译运行MapReduce程序
在Hadoop框架中执行MapReduce任务的几种方式

9. 一篇总结得比较好的博客
MapReduce入门