Apache hive 3.1.2从单机到高可用部署 HiveServer2高可用 Metastore高可用 hive on spark hiveserver2 web UI 高可用集群启动脚本
hive部署
下载apache hive 3.1.2
http://archive.apache.org/dist/hive/
注:先看hive编译文档,使用编译好的安装包进行部署
官方的hive3.1.4和sprk3.0.0不兼容,需要重新编译。
后面配置hive on spark 可以使用spark2.3.0。而spark2.3.0对应的hadoop版本是2.x。
重新编译,参考本人写的另一篇文章
hive3.1.4源码编译 兼容spark3.0.0 hive on spark 升级guava版本兼容hadoop3.x (修改源码依赖 步骤详细)
https://blog.csdn.net/weixin_52918377/article/details/117123969
安装mysql5.7
略
部署hive
1. 上传解压安装包
把apache-hive-3.1.2-bin.tar.gz上传到linux的/opt/resource目录下
解压apache-hive-3.1.2-bin.tar.gz到**/opt/bigdata/**目录下面
[along@hdp14 resource]$ tar -zxvf /opt/resource/apache-hive-3.1.2-bin.tar.gz -C /opt/bigdata/
修改apache-hive-3.1.2-bin.tar.gz的名称为hive
[along@hdp14 resource]$ mv /opt/bigdata/apache-hive-3.1.2-bin/ /opt/bigdata/hive
2. 配置环境变量
修改**/etc/profile.d/my_env.sh**,添加环境变量
[along@hdp14 resource]$ sudo vim /etc/profile.d/my_env.sh
添加内容
#HIVE_HOME
export HIVE_HOME=/opt/bigdata/hive
export PATH=$PATH:$HIVE_HOME/bin
是环境变量生效
[along@hdp14 bigdata]$ source /etc/profile.d/my_env.sh
3. 解决日志Jar包冲突
[along@hdp14 resource]$ mv /opt/bigdata/hive/lib/log4j-slf4j-impl-2.10.0.jar /opt/bigdata/hive/lib/log4j-slf4j-impl-2.10.0.bak
拷贝驱动
将MySQL的JDBC驱动拷贝到Hive的lib目录下
[along@hdp14 resource]$ cp /opt/resource/mysql-connector-java-5.1.48.jar /opt/bigdata/hive/lib
4.添加hive核心配置文件
进入**/opt/bigdata/hive/conf**目录下新建hive-site.xml文件
[along@hdp14 resource]$ vim /opt/bigdata/hive/conf/hive-site.xml
配置文件中添加如下内容
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://hdp14:3306/metastore?useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>000000value>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://hdp14:9083value>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10000value>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>hdp14value>
property>
<property>
<name>hive.metastore.event.db.notification.api.authname>
<value>falsevalue>
property>
<property>
<name>hive.cli.print.headername>
<value>truevalue>
property>
<property>
<name>hive.cli.print.current.dbname>
<value>truevalue>
property>
configuration>
5.修改日志文件配置
Hive的log默认存放在**/tmp/along/hive.log/**目录下
修改hive的log存放日志到**/opt/bigdata/hive/logs/**
修改**/opt/bigdata/hive/conf/hive-log4j.properties.template**文件名称为hive-log4j.properties
[along@hdp14 conf]$ pwd
/opt/bigdata/hive/conf
[along@hdp14 conf]$ mv hive-log4j.properties.template hive-log4j.properties
在hive-log4j.properties文件中修改log存放位置
[along@hdp14 conf]$ vim hive-log4j2.properties
修改内容
property.hive.log.dir=/opt/bigdata/hive/logs
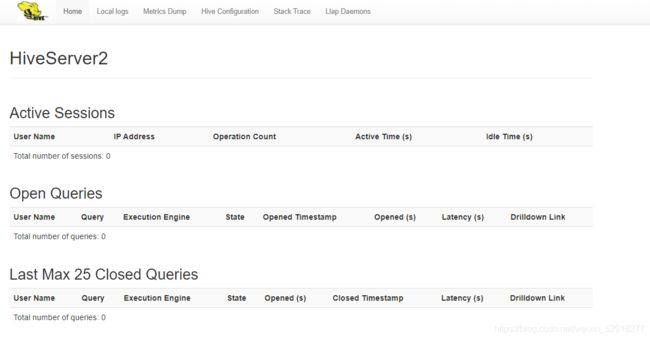
6.hiveserver2的 web UI
从2.0开始,HiveServer2提供了WEB UI,界面中可以直观的看到当前链接的会话、历史日志、配置参数以及度量信息。
修改/opt/bigdata/hive/conf目录下hive-site.xml文件
[along@hdp14 resource]$ vim /opt/bigdata/hive/conf/hive-site.xml
配置文件中添加如下内容
<property>
<name>hive.server2.webui.hostname>
<value>hdp14value>
property>
<property>
<name>hive.server2.webui.portname>
<value>10002value>
property>
7.初始化hive元数据
创建hive源数据库
[along@hdp14 resource]$ mysql -uroot -p000000
mysql> create database metastore;
mysql> quit;
执行初始化命令
[along@hdp14 resource]$ schematool -initSchema -dbType mysql -verbose
8.解决guava版本冲突(使用编译的hive包跳过)
会出现如下错误
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:518)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:430)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5104)
at org.apache.hive.beeline.HiveSchemaTool.<init>(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:318)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
分析日志,可能是hadoop和hive的两个guava.jar版本不一致
查看hadoop和hve的guava的版本
[along@hdp14 conf]$ cd /opt/bigdata/hive/lib
[along@hdp14 conf]$ cd /opt/bigdata/hadoop-3.1.4/share/hadoop/common/lib/
备份hive中低版本的guava,将hadoop中高版本的guava复制到hive中
[along@hdp14 lib]$ mv guava-19.0.jar guava-19.0.jar.bak
[along@hdp14 lib]$ cp /opt/bigdata/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar ./
再次执行初始化命令
[along@hdp14 resource]$ schematool -initSchema -dbType mysql -verbose
执行成功。
启动hive
Hive 2.x以上版本,要先启动这两个服务,否则会报错
1.编写metastore和hiveserver2启动脚本
[along@hdp14 resource]$ vim /opt/bigdata/hive/bin/hiveservices.sh
添加内容
#!/bin/bash
HIVE_LOG_DIR=/opt/bigdata/hive/logs
mkdir -p $HIVE_LOG_DIR
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "`hostname` Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "`hostname` HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "`hostname` Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "`hostname` HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "`hostname` Metastore服务运行正常" || echo "`hostname` Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "`hostname` HiveServer2服务运行正常" || echo "`hostname` HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
2.执行权限
[along@hdp14 resource]$ chmod +x /opt/bigdata/hive/bin/hiveservices.sh
3.启动
[along@hdp14 resource]$ hiveservices.sh start
打开hive客户端进行测试
[along@hdp14 ~]$ hive
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/bigdata/jdk1.8.0_212/bin:/opt/bigdata/hadoop-3.1.4/bin:/opt/bigdata/hadoop-3.1.4/sbin:/opt/bigdata/hive/bin:/opt/bigdata/spark/bin:/home/along/.local/bin:/home/along/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/bigdata/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = d78b497b-3875-44ec-a4a5-49a9eb3d0562
Logging initialized using configuration in file:/opt/bigdata/hive/conf/hive-log4j2.properties Async: true
Hive Session ID = bcc89614-2c01-40d9-ba0d-9f921e09be6c
执行查询语句
hive (default)> select * from student;
OK
student.id student.name
1 along
Time taken: 2.794 seconds, Fetched: 1 row(s)
hive (default)> show databases;
OK
database_name
default
访问Hiserver2的web UI界面
hive on spark
1. 下载spark安装包
spark3.0.0安装包和spark3.0.0纯净包
下载地址
http://archive.apache.org/dist/spark/spark-3.0.0/
2. 安装spark
2.1 上传解压spark安装包
上传spark-3.0.0-bin-hadoop3.2.tgz和spark-3.0.0-bin-without-hadoop.tgz到**/opt/resource**目录
将spark-3.0.0-bin-hadoop3.2.tgz解压到**/opt/bigdata**,并修改文件夹名称
[along@hdp14 bigdata]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.gz -C /opt/bigdata/
[along@hdp14 bigdata]$ mv /opt/bigdata/spark-3.0.0-bin-hadoop3.2 /opt/bigdata/spark
2.2 配置spark环境变量
[along@hdp14 resource]$ sudo vim /etc/profile.d/my_env.sh
添加内容
#SPARK_HOME
export SPARK_HOME=/opt/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin
2.3 hive中创建spark配置文件
[along@hdp14 resource]$ vim /opt/bigdata/hive/conf/spark-defaults.conf
添加内容
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ns/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
2.4 在HDFS创建如下路径,用于存储历史日志
[along@bigdata resource]$ hadoop fs -mkdir /spark-history
3. 配置 hive on spark
3.1 解压纯净包
将spark纯净包到**/opt/resource**目录下,并解压
[along@hdp14 resource]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
3.2 将解压后的jar包,上传到HDFS上
#创建目录
[along@hdp14 resource]$ hadoop fs -mkdir /spark-jars
#上传
[along@hdp14 resource]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
3.3 修改hive-site.xml
[along@hdp14 ~]$ vim /opt/bigdata/hive/conf/hive-site.xml
添加内容
<property>
<name>spark.yarn.jarsname>
<value>hdfs://ns/spark-jars/*value>
property>
<property>
<name>hive.execution.enginename>
<value>sparkvalue>
property>
<property>
<name>hive.spark.client.connect.timeoutname>
<value>10000msvalue>
property>
4. 重新编译 hive
建表插入数据测试时报错,发现是由于hive3.1.2和spark3.0.0不兼容导致的。
hive3.1.2对应的版本是spark2.3.0,而spark3.0.0对应的hadoop版本是hadoop2.6或hadoop2.7。
所以,如果想要使用高版本的hive和hadoop,我们要重新编译hive,兼容spark3.0.0。
hive编译另作文档
hive高可用
1. HiveServer2 高可用
1. 1 修改配置hive-site.xml
增加以下内容
<property>
<name>hive.server2.support.dynamic.service.discoveryname>
<value>truevalue>
property>
<property>
<name>hive.server2.zookeeper.namespacename>
<value>hiveserver2_zkvalue>
property>
<property>
<name>hive.zookeeper.quorumname>
<value>hdp16,hdp17,hdp18value>
property>
<property>
<name>hive.zookeeper.client.portname>
<value>2181value>
property>
1.2 将安装的好的hive文件夹,同步到hdp15
[along@hdp14 hive]$ scp -r /opt/bigdata/hive along@hdp15:/opt/bigdata/
1.3 修改hdp15中的配置 hive-site.xml
添加
<property>
<name>hive.server2.thrift.bind.hostname>
<value>hdp15value>
property>
<property>
<name>hive.server2.webui.hostname>
<value>hdp15value>
property>
1.4 分别重启启动两台的hiveServer2和metaStore
hdp14
[along@hdp15 hive]$ bin/hiveservices.sh stop
[along@hdp15 hive]$ bin/hiveservices.sh start
hdp15
[along@hdp15 hive]$ bin/hiveservices.sh start
等到2个服务启动后
[along@hdp15 hive]$ bin/hiveservices.sh status
Metastore服务运行正常
HiveServer2服务运行正常
[along@hdp14 hive]$ bin/hiveservices.sh status
Metastore服务运行正常
HiveServer2服务运行正常
1.5进入zk目录执行zkCli.sh,打开zk客户端,执行
[along@hdp16 ~]$ cd /opt/bigdata/zookeeper-3.5.9/
[along@hdp16 zookeeper-3.5.9]$ bin/zkCli.sh
查看zk上的信息
[zk: localhost:2181(CONNECTED) 14] ls /hiveserver2_zk
[serverUri=hdp14:10000;version=3.1.2;sequence=0000000009, serverUri=hdp15:10000;version=3.1.2;sequence=0000000008]
hiveServer2在hdp14上
注意需要等待一会,hiveserver2启动得比较慢
1.6 连接hive
高可用搭建完毕,使用jdbc或者beeline两种方式进行访问
- beeline
控制台输入: beeline 打开窗口
在窗口中输入:
!connect jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk along root
执行查询语句
[along@hdp14 ~]$ beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/bigdata/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> !connect jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk along root
Connecting to jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
21/05/20 18:07:49 [main]: INFO jdbc.HiveConnection: Connected to hdp15:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hdp16,hdp17,hdp18/> select * from student;
INFO : Compiling command(queryId=along_20210520180758_217ccf0e-9eaa-4a6d-9a8f-545ef7d9e8ee): select * from student
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student.id, type:int, comment:null), FieldSchema(name:student.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=along_20210520180758_217ccf0e-9eaa-4a6d-9a8f-545ef7d9e8ee); Time taken: 3.907 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=along_20210520180758_217ccf0e-9eaa-4a6d-9a8f-545ef7d9e8ee): select * from student
INFO : Completed executing command(queryId=along_20210520180758_217ccf0e-9eaa-4a6d-9a8f-545ef7d9e8ee); Time taken: 0.006 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------+---------------+
| student.id | student.name |
+-------------+---------------+
| 1 | along |
+-------------+---------------+
1 row selected (4.426 seconds)
0: jdbc:hive2://hdp16,hdp17,hdp18/>
根据提示
21/05/20 18:07:49 [main]: INFO jdbc.HiveConnection: Connected to hdp15:10000
可知使用的是hdp15上的hiveserver2
- Jdbc
。。。
1.7 验证HiveServer2高可用
在hdp15上,杀掉占用10000端口的进程,即杀掉hdp12的hiveServer2进程
[along@hdp15 ~]$ netstat -ntpl |grep 10000
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 :::10000 :::* LISTEN 3480/java
[along@hdp15 ~]$ kill -9 3480
在hdp15上打开beeline,测试连接
[along@hdp15 logs]$ beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/bigdata/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> !connect jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk along root
Connecting to jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
21/05/20 18:12:47 [main]: INFO jdbc.HiveConnection: Connected to hdp14:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hdp16,hdp17,hdp18/> select * from student;
INFO : Compiling command(queryId=along_20210520181250_8855f689-b429-40d6-ba9c-21244e1d9f5a): select * from student
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student.id, type:int, comment:null), FieldSchema(name:student.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=along_20210520181250_8855f689-b429-40d6-ba9c-21244e1d9f5a); Time taken: 3.154 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=along_20210520181250_8855f689-b429-40d6-ba9c-21244e1d9f5a): select * from student
INFO : Completed executing command(queryId=along_20210520181250_8855f689-b429-40d6-ba9c-21244e1d9f5a); Time taken: 0.01 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------+---------------+
| student.id | student.name |
+-------------+---------------+
| 1 | along |
+-------------+---------------+
1 row selected (4.191 seconds)
在hdp15上打开beeline,测试连接
[along@hdp14 ~]$ beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/bigdata/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> !connect jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk along root
Connecting to jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
21/05/20 18:16:52 [main]: INFO jdbc.HiveConnection: Connected to hdp14:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hdp16,hdp17,hdp18/> select * from student
. . . . . . . . . . . . . . . . . > ;
INFO : Compiling command(queryId=along_20210520181714_6ea57470-a26c-4e2d-8d28-aa45a147f175): select * from student
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student.id, type:int, comment:null), FieldSchema(name:student.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=along_20210520181714_6ea57470-a26c-4e2d-8d28-aa45a147f175); Time taken: 0.282 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=along_20210520181714_6ea57470-a26c-4e2d-8d28-aa45a147f175): select * from student
INFO : Completed executing command(queryId=along_20210520181714_6ea57470-a26c-4e2d-8d28-aa45a147f175); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------+---------------+
| student.id | student.name |
+-------------+---------------+
| 1 | along |
+-------------+---------------+
1 row selected (0.467 seconds)
从日志中这句
21/05/20 18:16:52 [main]: INFO jdbc.HiveConnection: Connected to hdp14:10000
可以看出hiveservice2已变成了hdp14
再查看zk中的命名空间:
[zk: localhost:2181(CONNECTED) 3] ls /hiveserver2_zk
[serverUri=hdp14:10000;version=3.1.2;sequence=0000000009]
2. Metastore 高可用
2.1 修改2个节点hive配置文件hive-site.xml
<property>
<name>hive.metastore.urisname>
<value>thrift://hdp14:9083,thrift://hdp15:9083value>
property>
2.2 重启hive的hivesever2和metasrore服务
执行hiveservice.sh
[along@bigdata /]$ hiveservices.sh start
Metastore服务运行正常
HiveServer2服务运行正常
2.3 连接beeline,执行查询语句
在14上通过zk命名空间连接beeline,并执行任意查询语句
[along@hdp14 ~]$ beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/bigdata/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop-3.1.4/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 3.1.2 by Apache Hive
beeline> !connect jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk along root
Connecting to jdbc:hive2://hdp16,hdp17,hdp18/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk
21/05/21 13:14:33 [main]: INFO jdbc.HiveConnection: Connected to hdp15:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hdp16,hdp17,hdp18/>
0: jdbc:hive2://hdp16,hdp17,hdp18/>
0: jdbc:hive2://hdp16,hdp17,hdp18/>
0: jdbc:hive2://hdp16,hdp17,hdp18/> select * from student;
INFO : Compiling command(queryId=along_20210521131447_3a5d778a-c239-4160-b445-e9ef85a436fa): select * from student
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student.id, type:int, comment:null), FieldSchema(name:student.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=along_20210521131447_3a5d778a-c239-4160-b445-e9ef85a436fa); Time taken: 3.997 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=along_20210521131447_3a5d778a-c239-4160-b445-e9ef85a436fa): select * from student
INFO : Completed executing command(queryId=along_20210521131447_3a5d778a-c239-4160-b445-e9ef85a436fa); Time taken: 0.009 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------+---------------+
| student.id | student.name |
+-------------+---------------+
| 1 | along |
+-------------+---------------+
1 row selected (5.128 seconds)
2.4 验证Metastore高可用
在14干掉metastore服务,再执行查询语句
[along@hdp14 ~]$ jps -ml
2337 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
5107 org.apache.hadoop.util.RunJar /opt/bigdata/hive/lib/hive-service-3.1.2.jar org.apache.hive.service.server.HiveServer2
5635 sun.tools.jps.Jps -ml
1972 org.apache.hadoop.hdfs.tools.DFSZKFailoverController
5382 org.apache.hadoop.util.RunJar /opt/bigdata/hive/lib/hive-beeline-3.1.2.jar org.apache.hive.beeline.BeeLine
1639 org.apache.hadoop.hdfs.server.namenode.NameNode
2519 org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer
4923 org.apache.hadoop.util.RunJar /opt/bigdata/hive/lib/hive-metastore-3.1.2.jar org.apache.hadoop.hive.metastore.HiveMetaStore
[along@hdp14 ~]$ kill -9 5107
[along@hdp14 /]$ hiveservices.sh status
Metastore服务运行异常
HiveServer2服务运行正常
执行查询语句,高可用验证完成
0: jdbc:hive2://hdp16,hdp17,hdp18/> select * from student;
INFO : Compiling command(queryId=along_20210521132757_624d5cbb-e906-465c-812e-cef4b1f56599): select * from student
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student.id, type:int, comment:null), FieldSchema(name:student.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=along_20210521132757_624d5cbb-e906-465c-812e-cef4b1f56599); Time taken: 0.227 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=along_20210521132757_624d5cbb-e906-465c-812e-cef4b1f56599): select * from student
INFO : Completed executing command(queryId=along_20210521132757_624d5cbb-e906-465c-812e-cef4b1f56599); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------+---------------+
| student.id | student.name |
+-------------+---------------+
| 1 | along |
+-------------+---------------+
1 row selected (0.286 seconds)
0: jdbc:hive2://hdp16,hdp17,hdp18/>
3.hive高可用集群启动脚本
hive高可用配置完了,在两个服务启动的时候还不是很方便,写一个启动脚本
vim /home/along/bin/hive2server.sh
添加如下内容
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== hdp14 启动 HiveServer2和Metastore服务 ==================="
ssh hdp14 "/opt/bigdata/hive/bin/hiveservices.sh start"
echo " =================== hdp15 启动 HiveServer2和Metastore服务 ==================="
ssh hdp15 "/opt/bigdata/hive/bin/hiveservices.sh start"
;;
"stop")
echo " =================== hdp14 停止 HiveServer2和Metastore服务 ==================="
ssh hdp14 "/opt/bigdata/hive/bin/hiveservices.sh start"
echo " =================== hdp15 停止 HiveServer2和Metastore服务 ==================="
ssh hdp15 "/opt/bigdata/hive/bin/hiveservices.sh start"
;;
"status")
echo " =================== hdp14 查看 HiveServer2和Metastore服务 ==================="
ssh hdp14 "/opt/bigdata/hive/bin/hiveservices.sh status"
echo " =================== hdp15 查看 HiveServer2和Metastore服务 ==================="
ssh hdp15 "/opt/bigdata/hive/bin/hiveservices.sh status"
;;
*)
echo "Input Args Error...start|stop|status"
;;
esac
执行测试
[along@hdp14 bin]$ hive2server.sh status
=================== hdp14 查看 HiveServer2和Metastore服务 ===================
hdp14 Metastore服务运行正常
hdp14 HiveServer2服务运行正常
=================== hdp15 查看 HiveServer2和Metastore服务 ===================
15 Metastore服务运行正常
15 HiveServer2服务运行正常