人工智能之数学基础篇—线性代数基础
人工智能之数学基础篇—线性代数基础
- 1 向量
-
- 1.1 标量
- 1.2 向量
- 1.3 向量的两个基本运算
-
- 1.3.1 向量的加法
- 1.3.2 向量的数乘
- 1.4 向量与数据
- 2 矩阵
-
- 2.1 矩阵的定义
- 2.2 矩阵与数据
- 3 矩阵和向量的创建
-
- 3.1 NumPy 库的导入和使用
- 3.2 矩阵的创建
-
- 3.2.1 直接定义
- 3.2.2 间接创建
- 3.2.3 矩阵元素的存取操作
- 3.3 向量的创建
-
- 3.3.1 直接创建
- 3.3.2 随机生成向量元素
线性代数是代数学的一个分支,主要处理线性关系问题 ( 简称线性问题) 。线性代数中的概念是机器学习必备的基础知识,有助于理解不同机器学习算法背后的原理、算法内部是如何运行的,以便在开发机器学习系统时更好地作决策。在机器学习的背景下,线性代数也是一个数学工具,提供了像向量和矩阵这样的数据结构用于组织大量的数据,同时也提供了如加、减、乘、求逆等有助于同时操作数据的运算,从而将复杂的问题简单化,提升大规模运算的效率。本篇文章将总结一些机器学习中涉及的线性代数中的基础知识,包括向量、矩阵、行列式 、线性方程等基本概念;常见的特殊矩阵,矩阵的加、减、 乘法运算,向量与矩阵的乘法、向量的内积运算、逆矩阵和转置矩阵等慨念,同时提供相应的 Python 实现代码。
1 向量
向量是线性代数最基础、最根源的组成部分,也是机器学习的基础数据表示形式。机器学习中的投影 、 降维等概念,都是在向量的基础上实现的。线性代数通过将研究对象拓展到向量,对多维的数据进行统一研究,进而演化出一套计算的方法,使我们可以非常方便地研究和解决真实世界中的问题。
1.1 标量
标量也称为“无向量”,是用一个单独的数表示其数值的大小(可以有正负之分),可以是实数或复数, 一般用小写的变量名称表示。 例如,用 s s s 表示行走的距离,用 k k k 表示直线的斜率,用 n n n 表示数组中元素的数目, s s s、 k k k、 n n n 都可以看作标量。
1.2 向量
真实世界是多维度的,而且大多数的研究对象也具有非常多的维度,因此用一个数很难表达和处理真实世界中的问题,这就需要用一组数,也就是用向量来表达和处理高维空间中的问题。为表示一个整体,习惯上将这组数用方括号括起来。
定义1 将 n n n 个有次序的数排成一行,称为 n n n 维行向量;将 n n n 个有次序的数排成一列,称为 n n n 维列向量。
如 x = [ 1 2 3 4 ] , y = [ 1 2 3 4 ] \mathbf{x} = \begin{bmatrix} 1 &2 &3 &4 \end{bmatrix},\: \mathbf{y}=\begin{bmatrix} 1\\ 2\\ 3\\ 4 \end{bmatrix} x=[1234],y=⎣⎢⎢⎡1234⎦⎥⎥⎤分别为四维行向量和四维列向量。习惯上如果未加声明,向量一般指列向量,而且将列向量 y \mathbf{y} y 表示为 y = [ 1 2 3 4 ] T \mathbf{y}=\begin{bmatrix} 1 &2 &3 &4 \end{bmatrix}^{T} y=[1234]T。向量 y \mathbf{y} y 的第 i i i 个分量用 y i \mathbf{y_{i}} yi 表示,如 y 2 \mathbf{y_{2}} y2 表示向量 y \mathbf{y} y 的第二个分量,其值为 2。
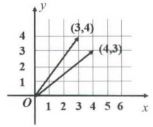
从几何意义上看,向量既有大小又有方向,将向量的分量看作坐标轴上的坐标,该向量可以被看作空间中的一个点。以坐标原点为起点,以向量代表的点为终点,可以形成一条有向线段。 有向线段的长度表示向量的大小,箭头所指的方向表示向量的方向,可以将任意一个位置作为起始点进行自由移动,但一般将原点看作起始点。 如图 1 所示,点 ( 3 , 4 ) (3,4) (3,4) 和点 ( 4 , 3 ) (4,3) (4,3) 分别对应向量 [ 3 , 4 ] T \left [ 3,4 \right ]^{T} [3,4]T 和向量 [ 4 , 3 ] T \left [ 4,3 \right ]^{T} [4,3]T,显然向量是有序的, [ 3 , 4 ] T \left [ 3,4 \right ]^{T} [3,4]T 和 [ 4 , 3 ] T \left [ 4,3 \right ]^{T} [4,3]T 分别代表不同的向量。
1.3 向量的两个基本运算
1.3.1 向量的加法
在一些机器学习的算法中,经常会用到向量的加法运算。
求两个向量和的运算叫作向量的加法。向量加法的值等于两个向量的对应分量之和。
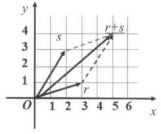
以两个二维向量的加法为例,如: r = [ 3 , 1 ] T \mathbf{r} = \left [ 3,1 \right ]^{T} r=[3,1]T 和 s = [ 2 , 3 ] T \mathbf{s} = \left [ 2,3 \right ]^{T} s=[2,3]T,则 r + s = [ 3 + 2 , 1 + 3 ] T = [ 5 , 4 ] T \mathbf{r}+\mathbf{s} = \left [ 3+2,1+3 \right ]^{T}=\left [ 5,4 \right ]^{T} r+s=[3+2,1+3]T=[5,4]T。
在二维平面内,可以将向量加法理解为求以这两个向量为边的平行四边形的对角线表示的向量。如图2所示,即从原点出发,先沿 x x x 轴方向移动3个单位,再沿 y y y 轴方向移动1个单位,得到 r \mathbf{r} r 的位置, r \mathbf{r} r 加上 s \mathbf{s} s,可以理解为继续沿着 x x x 轴方向移动2个位置,再沿 y y y 轴方向移动3个位置,最终到达的位置 ( 5 , 4 ) (5,4) (5,4) 就是 r + s \mathbf{r} + \mathbf{s} r+s 对应的向量 [ 5 , 4 ] T \left [ 5,4 \right ]^{T} [5,4]T。
1.3.2 向量的数乘
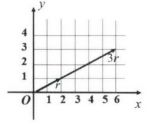
数乘向量是数量与向量的乘法运算。一个数 m m m 乘一个向量 r \mathbf{r} r,结果是向量 m r m\mathbf{r} mr。以一个二维向量的数乘为例,如 m = 3 m=3 m=3, r = [ 2 , 1 ] T \mathbf{r} = \left [ 2,1 \right ]^{T} r=[2,1]T,则 m r = [ 3 × 2 , 3 × 1 ] T = [ 6 , 3 ] T m\mathbf{r} =\left [ 3\times2,3\times1 \right ]^{T}=\left [ 6,3 \right ]^{T} mr=[3×2,3×1]T=[6,3]T。
在二维平面内, 3 r 3\mathbf{r} 3r 即3个 r \mathbf{r} r 相加,可以理解为从 r \mathbf{r} r 位置出发,沿着 x x x 轴方向再移动 2 × 2 2\times2 2×2 个单位,沿着 y y y 轴方向再移动 2 × 1 2\times1 2×1个单位,到达的位置 ( 6 , 3 ) (6,3) (6,3) 即 3 r 3\mathbf{r} 3r 对应的向量 [ 6 , 3 ] T \left [ 6,3 \right ]^{T} [6,3]T,如图3所示。
1.4 向量与数据
在机器学习中,对一个对象或事件的描述称为样本,反映样本某方面的表现或性质的事项称为特征或属性,特征的取值称为特征值,由样本组成的集合称为数据集。在数据集中,样本用向量表示,向量的维度可以看作样本的特征数。如经典的鸢尾花数据集,用萼片长度、萼片宽度、花瓣长度和花瓣宽度 4 4 4 个特征刻画鸢尾花,4个特征值组成一个样本,用四维行向量表示。如一个行向量 [ 5.1 , 3.5 , 1.4 , 0.2 ] [5.1,3.5,1.4,0.2] [5.1,3.5,1.4,0.2] 表示一个鸢尾花样本,则有 5.1 5.1 5.1、 3.5 3.5 3.5、 1.4 1.4 1.4 和 0.2 0.2 0.2 共 4 4 4 个特征值。
2 矩阵
标量是一个数,向量是对标量的扩展,是一组数;矩阵是对向量的扩展,可看作一组向量。在图像处理、人工智能等领域,常用矩阵来表示和处理大量的数据。矩阵是线性代数中最有用的工具。
2.1 矩阵的定义
定义2 由 m × n m \times n m×n 个数 a i j a_{ij} aij, i = 1 , 2 , . . . , m ; j = 1 , 2 , . . . , n i=1,2,...,m;\: j = 1,2,...,n i=1,2,...,m;j=1,2,...,n 排成的 m m m 行 n n n 列的数表,称为 m m m 行 n n n 列矩阵,简称 m × n m \times n m×n 阶矩阵,记作,

简记为 A = A m × n = ( a i j ) m × n A = A_{m \times n} = \left ( a_{ij} \right )_{m \times n} A=Am×n=(aij)m×n。其中 a i j a_{ij} aij 称为矩阵的元素, a i j a_{ij} aij 的第1个下标 i i i 称为行标,表明该元素位于第 i i i 行;第 2 个下标 j j j 称为列标,表明该元素位于第 j j j 列。
将元素为实数的矩阵称为实矩阵,元素为复数的矩阵称为复矩阵。在实际使用的过程中,一般都是实矩阵。
从数组的角度看,向量是一维数组,是标量的数组;矩阵是二维数组,是向量的数组。
给定一个矩阵,可以将其看作由行向量构成,也可以看作是由列向量组成 。
例如:矩阵 A A A
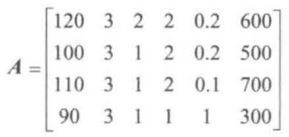
按行看,可以看作由 [120, 3, 2, 2, 0.2, 600] 、 [100, 3, 1, 2, 0.2, 500] 、 [110, 3, 1, 2, 0.1, 700] 和 [90, 3, 1, 1, 1, 300] 四个六维行向量组成;按列看,则可以看作由
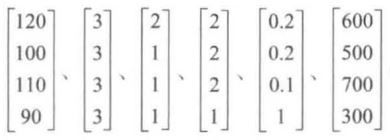 六个四维列向量构成。
六个四维列向量构成。
向量可以看作一种特殊的矩阵, n × 1 n \times 1 n×1 阶矩阵可以称作一个 n n n 维列向量; 1 × n 1 \times n 1×n 阶矩阵也称为一个 n n n 维行向量。
2.2 矩阵与数据
矩阵的外观就是长方形的数表,生活中一些长方形的数表也可以看作矩阵,矩阵在日常生活、科学计算及机器学习中应用广泛,下面列举几个常见的例子。
【例1】生活中对象之间的关系常用表格表示。例如有 A , B 、 C 、 D 共 4 个城市,它们之间的通行关系如图 4 所示,习惯上用表 1 表示该图,行和列分别代表四个城市,用对号表示两个城市可以通行。计算机中可以用矩阵表示,行和列分别代表四个城市,使用 0 和 1 分别代表两个城市不可通行和可通行关系,表 1 对应的矩阵为 A A A。
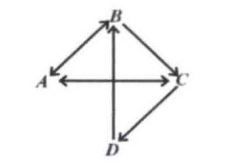
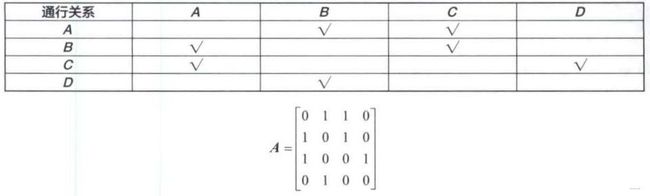
通过矩阵运算,可以判断两个城市间是否可达。
【例2】编号为 1~4 的 4 个学生选修了 A 、 B 、 C 、 D 、 E 共 5 门课,每个学生每门课的成绩对应表 2 ,每行代表某学生 5 门课的成绩,每列代表某科目 4 个学生的成绩,该表格可以用矩阵 A A A 表示。

通过矩阵运算,可以求出每个学生或者每门课的平均分、最高分和最低分,以及每门课的分数分布情况等。
【例3】在机器学习中,样本集合(也称为数据集)常用矩阵表示,每行数据称为一个样本(或一个数据对象),每列表达样本的一个特征 ( 属性 ) 或者标记,例如表 3 的鸢尾花数据集,每一行代表一个样本。前四列分别代表一个特征,最后一列是标记,表示所属类别。 该数据集可以用矩阵 A A A 表示
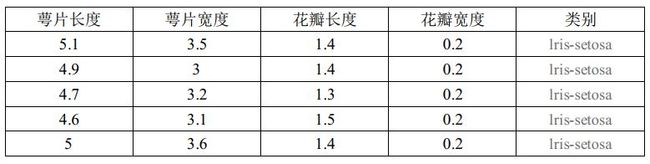

在机器学习中,常用矩阵 X X X 表示矩阵 A A A 的前四列,矩阵 Y Y Y 表示矩阵 A A A 的最后一列,获取 X X X 和 Y Y Y 后,将它们带入机器学习的相关算法中实现分类。
【例4】用矩阵表示线性系统。
描述参数、变量和常量之间线性关系的线性系统常用线性方程组表示,未知量均为一次项的方程组称为线性方程组。
例如,设某个线性系统用如下的线性方程组表示。
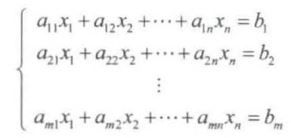
将该方程组左侧的系数用一个 m × n m \times n m×n 阶矩阵 A A A 表示,每行代表一个方程,每列代表在不同方程中不同未知数的系数。方程组右侧的值用 m × 1 m \times 1 m×1 阶矩阵 B B B 表示,每行代表方程右侧的值,未知数 X X X 用 n × 1 n \times 1 n×1 阶矩阵表示。习惯上称 A A A 为系数矩阵, X X X 为未知数矩阵, B B B 为常数项矩阵。 此线性方程组记为 A X = B AX=B AX=B,其中:

记

为增广矩阵。
利用矩阵运算,借助 Python 的 NumPy 库很容易求出 X X X 值。
【例5】在平面坐标系中,一个点的坐标用二维向量存放,如图 5 所示,若干点的坐标可以用矩 A A A 存放。
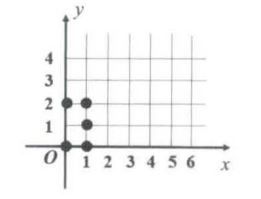
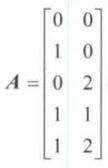
代表平面坐标中的 5 个点。
【例6】数字图像的数据可以用矩阵表示,如灰度图像的像素数据就是一个矩阵,矩阵的行对应图像的高(单位为像素),矩阵的列对应图像的宽(单位为像素),矩阵的元素对应图像的像素,矩阵元素的值就是像素的灰度值。如图 6 所示,数字图像部分的灰度值对应的矩阵为 A A A。

采用矩阵存储数字图像,符合二维图像的行列特性,也便于通过矩阵理论和矩阵算法对数字图像进行分析和处理。
3 矩阵和向量的创建
NumPy 库是 Python 的一种开源的数值计算扩展,提供很多高效的数值编程工具。它的数组计算,是矩阵操作必不可少的包。NumPy 库可用于存储和处理大型矩阵,比 Python 自身的嵌套列表结构要高效得多(该结构也可以表示矩阵)。
在 Python 中使用 NumPy 库,首先需要安装 NumPy 库,导人 NumPy 库之后,就可以使用 NumPy 库中的方法。
对于 NumPy 库的安装由于不同的系统安装方式会有不同,大家可以根据自己的系统自行搜索相关资料进行安装。
3.1 NumPy 库的导入和使用
导入 NumPy 库的方式有以下 3 种,其中第 3 种方式最为常用 。
from numpy import * # 导入 numpy 的所有函数。
import numpy # 这个方式使用 numpy 的函数时,需要以 numpy. 开头。
import numpy as np # 这个方式使用 numpy 的函数时,需要以 np. 开头。
用第 3 种方法导入 NumPy 后,就可以使用 NumPy 库中的函数,如 shape 、 array 、 mat 等,调用方式都是 np.array()、 np.mat()、 np.shape(),不能写为 A.array()、 A.mat()、 A.shape() 等,其中 A 为变量。
3.2 矩阵的创建
NumPy 中常采用 matrix (矩阵)和 array(数组)表示矩阵,主要区别如下。
(1)matrix 是 array 的分支, matrix 和 array 基本上通用,但在大部分 Python 程序里, array 更为常用,因为 array 更灵活,速度更快。 官方文档建议使用二维 array 代替矩阵进行矩阵运算。array 的优势在于不仅可以表示二维数组,还能表示三,四,五, ⋯ \cdots ⋯, n n n 维数组。
(2)NumPy 中 array 的类型是 numpy.ndarray,由相同类型的元素组成。
3.2.1 直接定义
根据给出的具体数据创建矩阵,将一切序列型的对象(包括其他数组) 作为 np.array() 函数的传入数据,进而产生 NumPy 数组。以二维列表或元组作为参数创建的二维数组即矩阵。如果传递的是多层嵌套序列,将创建多维数组。
下面的代码将实现矩阵的直接创建。
【代码】:
import numpy as np
A = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
arr1 = np.array(A) # 将列表转化为矩阵
print("A = ", A)
print("通过列表A创建的矩阵arr1\n", arr1)
B = ((1, 2, 3, 4), (5, 6, 7, 8), (9, 10, 11, 12))
arr2 = np.array(B) # 将元组转化为矩阵
print("B = ", B)
print("通过元组B创建的矩阵arr2\n", arr2)
【运行结果】:
A = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
通过列表A创建的矩阵arr1
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
B = ((1, 2, 3, 4), (5, 6, 7, 8), (9, 10, 11, 12))
通过元组B创建的矩阵arr2
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
【结果说明】:
通过 np.array() 函数将列表 A 或元组 B 生成 3x4 阶的矩阵 arr1 和 arr2 是相同的。
【提示】:
NumPy 中生成的矩阵有两层方括号。
(1)最外层的方括号表示矩阵
(2)内层有3对方括号,表示3行
(3)内存每对方括号内有4个元素,表示4列
(4)矩阵是按照行的顺序显示输出,这与 Python 的 list 类型不同
(5)方括号的形式可以判断数组是否能够代表一个向量或者矩阵
(6)list 类型用 “,”分隔,数组用空格分隔
矩阵的规模(大小) 一般用行数和列数描述,可以通过矩阵的 shape 属性获得,数据的类型可以使用 type() 函数验证。
【代码】:
print("A的类型:", type(A))
print("B的类型:", type(B))
print("arr1的类型:", type(arr1))
print("arr1的大小:", arr1.shape)
【运行结果】:
A的类型: <class 'list'>
B的类型: <class 'tuple'>
arr1的类型: <class 'numpy.ndarray'>
arr1的大小: (3, 4)
【结果说明】:
A、B 分别为列表和元组,它们与 arr1 的类型不同。 arr1 为 3x4 阶的矩阵。
【提示】:
可以使用 arr1.shape 或 np.shape(arr1) 获取 arr1 的规模,但是不可以使用 arr1.shape()。
3.2.2 间接创建
(1)随机生成矩阵元素
在机器学习中,常常会用随机数作为参数的数值,NumPy 中可以利用 np.random.random() 函数和np.random.randint() 函数分别随机生成矩阵中指定范围的浮点数和整数。
函数 np.random.random((d0, d1, ... ,dn)) 生成值为 [0, 1) 区间的 n 维浮点数组,函数 np.random.random((d0, d1)) 创建 d0xd1 阶矩阵。
函数 np.random.randint(low, high=None, size=None, dtype='I'),返回随机整数,范围为 [Iow, high)。size 为数组维度,对于 d0xd1 阶矩阵,设 size=[d0, d1]。 dtype 为数据类型,默认的数据类型是 np.int,没有 high 时,默认生成随机数的范围是 [0, low)。
【代码】:
import numpy as np
arr1 = np.random.random((2, 3)) # 默认范围为0~1
print("创建的随机浮点数构成的2x3阶矩阵:\n", arr1)
arr2 = np.random.randint(3, 30, size=[2, 3])
print("创建的3~30(不包括30)之间的随机整数构成的2x3阶矩阵:\n", arr2)
【运行结果】:
创建的随机浮点数构成的2x3阶矩阵:
[[0.5674868 0.54082361 0.93320239]
[0.62330098 0.34546191 0.40427363]]
创建的3~30(不包括30)之间的随机整数构成的2x3阶矩阵:
[[19 22 24]
[11 17 17]]
(2)reshape() 函数通过改变矩阵的大小来创建新矩阵,其参数为一个正整数的元组,分别代表行数和列数
【代码】:
import numpy as np
A = [1, 2, 3, 4, 5, 6]
B = np.array(A) # 一维数组,共6个元素
C1 = B.reshape(2, 3) # 创建2行3列矩阵
C2 = B.reshape(3, 2) # 创建3行2列矩阵
print("矩阵B:\n", B)
print("转换为2行3列矩阵C1:\n", C1)
print("转换为3行2列矩阵C2:\n", C2)
【运行结果】:
矩阵B:
[1 2 3 4 5 6]
转换为2行3列矩阵C1:
[[1 2 3]
[4 5 6]]
转换为3行2列矩阵C2:
[[1 2]
[3 4]
[5 6]]
【提示】:
使用 reshape() 函数改变矩阵大小时,新矩阵的元素个数要与原矩阵的元素个数相等。当一个参数为 -1 时,reshape() 函数会根据另一个参数计算出 -1 代表的具体值,如上例中,C1 = B.reshape(2,3) 可用 C1 = B.reshape(2, -1) 或 C1 = B.reshape( -1, 3) 代替。
3.2.3 矩阵元素的存取操作
Python 中矩阵的下标是从 0 开始的,通过指定矩阵的下标,可实现存取对应的矩阵数据。对上例,获取 C1 和 C2 的部分元素。
【代码】:
import numpy as np
A = [1, 2, 3, 4, 5, 6]
B = np.array(A) # 一维数组,共6个元素
C1 = B.reshape(2, 3) # 创建2行3列矩阵
C2 = B.reshape(3, 2) # 创建3行2列矩阵
print("转换为2行3列矩阵C1:\n", C1)
print("转换为3行2列矩阵C2:\n", C2)
print("输出C1的第0行元素C1[0]:", C1[0]) # 获取矩阵的某一行
print("输出C1的前2行元素C1[0:2]:\n", C1[0:2]) # 获取矩阵的前几行
print("输出C2的第0行和第2行元素C2[[0,2]]:\n", C2[[0, 2]]) # 获取矩阵的某几行
print("输出C2的第1列元素C2[:,1]:\n", C2[:, 1]) # 获取矩阵的某一列
print("输出C2的前2列元素C2[:,0:2]:\n", C2[:, 0:2]) # 获取矩阵的前几列
print("输出C1的第0列和第2列元素C1[:,[0,2]]:\n", C1[:, [0, 2]]) # 获取矩阵的某几列
print("输出C2的第2行第1列元素C2[2,1]:", C2[2, 1]) # 获取矩阵的某个元素
【运行结果】:
转换为2行3列矩阵C1:
[[1 2 3]
[4 5 6]]
转换为3行2列矩阵C2:
[[1 2]
[3 4]
[5 6]]
输出C1的第0行元素C1[0]: [1 2 3]
输出C1的前2行元素C1[0:2]:
[[1 2 3]
[4 5 6]]
输出C2的第0行和第2行元素C2[[0,2]]:
[[1 2]
[5 6]]
输出C2的第1列元素C2[:,1]:
[2 4 6]
输出C2的前2列元素C2[:,0:2]:
[[1 2]
[3 4]
[5 6]]
输出C1的第0列和第2列元素C1[:,[0,2]]:
[[1 3]
[4 6]]
输出C2的第2行第1列元素C2[2,1]: 6
【结果说明】:可以用 -1 表示矩阵的最后一行或最后一列。获取到的矩阵的某一行或某一列的数据,类型为一维数组。
3.3 向量的创建
行向量可以看作是 1 × n 1 \times n 1×n 阶矩阵,而列向量可以看作是 n × 1 n \times 1 n×1 阶矩阵,因此可以采用创建矩阵的方式创建向量。
3.3.1 直接创建
直接将数据以排列好的行列向量形式传递给array()函数。
【代码】:
import numpy as np
A = [[1, 2, 3, 4, 5]]
B = [[1], [2], [3], [4], [5]]
C = np.array(A) # 创建行向量
D = np.array(B) # 创建列向量
print("行向量C:\n", C)
print("列向量D:\n", D)
print("A的类型:%s,C的类型:%s" % (type(A), type(C)))
print("B的类型:%s,D的类型:%s" % (type(B), type(D)))
print("C的大小:%s,D的大小:%s" % (C.shape, D.shape))
【运行结果】:
行向量C:
[[1 2 3 4 5]]
列向量D:
[[1]
[2]
[3]
[4]
[5]]
A的类型:<class 'list'>,C的类型:<class 'numpy.ndarray'>
B的类型:<class 'list'>,D的类型:<class 'numpy.ndarray'>
C的大小:(1, 5),D的大小:(5, 1)
【结果说明】:
带有双重括号的 C 为行向量,D 为列向量。
在 NumPy 中用 array() 函数生成的一维数组仅有一对方括号,而实际向量有两层方括号(属于二维数组)。 若 A=[1, 2, 3, 4, 5],则生成的是一维数组。
【代码】:
import numpy as np
A = [1, 2, 3, 4, 5]
C = np.array(A)
print("C = ", C)
print("A的类型:%s" % (type(A)))
print("C的类型:%s,C的大小:%s" % (type(C), np.shape(C)))
【运行结果】:
C = [1 2 3 4 5]
A的类型:<class 'list'>
C的类型:<class 'numpy.ndarray'>,C的大小:(5,)
【结果说明】:
输出的 C 只有一对 [ ] \left [ \: \right ] [], 所以 C 为一维数组,而不是一个行向量或者列向量,C 的大小为 (5 ,) 也说明 C 为一维数组,当需要向量时可以通过 reshape() 函数改变矩阵的维度生成向量。