Python爬虫及数据可视化网页实现
目录
前言
一 、爬虫部分
(1)基本思路
(2)库的使用
二、数据库部分
三、Flask框架部分
四、数据可视化部分
前言
源码指路!!!GitHub
保姆级教程指路!!!点我点我![Python爬虫编程基础5天速成(2021全新合集)Python入门+数据分析]
- 学前基础
- 掌握Python基本语法(因此直接从教程P15开始即可);
- 掌握一丢丢计网(静态网页,动态网页、get/post请求);
- 掌握一丢丢前端(看得懂HTML基本标签,能写一个啥也不是的登陆界面) ;
- 掌握一丢丢数据库(装过SQL软件,知道这玩意有增删改查罢了,详细语法不了解 血泪教训!) ;
- 了解正则、使用过Pycharm...
- 学习进度:(以教程1.5X播放计)
- 爬虫部分两天 P15-P25,
- 数据库部分一天P27-P28,
- Flask框架部分一天半P29-P33,
- 数据可视化部分半天P34-P35
成品展示!
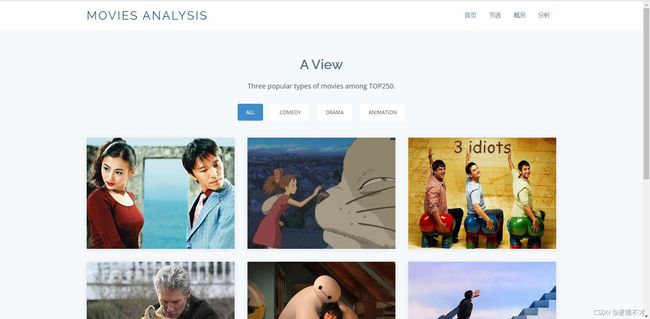
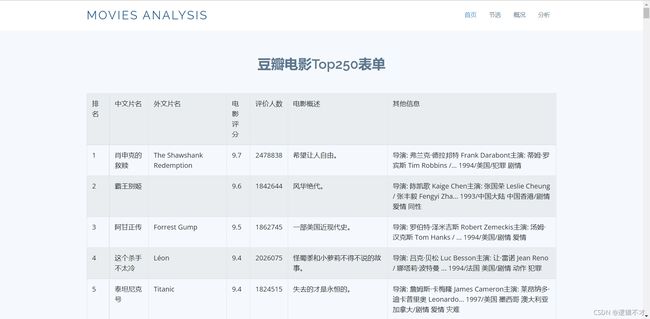

作为从来没接触过项目实现的菜菜,第一次po长文啦!!有以上基础学起来就算是轻松又好玩了,大家赶紧积极入坑吧,欢迎交流!
一 、爬虫部分
(1)基本思路
-
使用不同的库解决以下几个任务块: 1.爬虫伪装,获取源码 2.选择解析 3.正则表达,筛选数据 4.数据存储
- 代码块实现框架
def main(): #1.爬取数据 #2.解析数据 #3.保存数据 if __name__ == "__main__": main() print('爬取成功')
(2)库的使用
1. requests
似乎教程中用的是Urllib库,但这个库好像不太新,我伪装的请求头总是通不过,于是我毅然决然地投奔requests库
伪装请求头爬取使用 get请求 的网页数据
TIPS:
- get/post下的不同传参函数
- 网页状态码的查询(茶壶418/200/404/403)
- 请求头伪装
- 解码
def askURL(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"
}
try:
request = requests.get(url, headers=head)
html = request.content.decode("utf-8")
except:
print("爬取失败")
return html贴一下对requests库进行测试的代码:
import requests
url = 'https://www.baidu.com'
#伪装请求头爬取get请求网页数据
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"
}
request = requests.get(url, headers=head)
html = request.content.decode('utf-8')
print(request)
print(html)2. bs4
将复杂的HTML文档转化成复杂的树形结构,每个节点是一个Python对象,并且对HTML文件进行标签选择。
贴一下对bs库进行测试的代码:
from bs4 import BeautifulSoup
#转制存储文件
file = open("Douban.html", "rb") #rb:只读/二进制
html = file.read()
bs = BeautifulSoup(html, "html.parser") #将复杂的HTML文档转化成复杂的树形结构,每个节点是一个Python对象,共4种类型
#1.Tag(标签选择器)
print("1,",bs.title)
print("2,",bs.head)
print("3,",bs.input) #拿到第一个此标签元素
print("4,",bs.findAll("input")) #findAll
#2.NavigableString (标签对应元素/属性选择器)
print("5,",bs.title.string) #标签对应元素
print("6,",bs.input.attrs) #标签中所有属性值,字典保存
#3.BeautifulSoup (整个文档)
print("7,",bs)
print("8,",bs.name)
#4.Comment
#---------------------------------------------------
#文档的遍历
print("9,",bs.head.contents) #返回一个包含'\n'元素的列表
print("10,",bs.head.contents[1]) #可以对此列表进行索引
#有更多关于文档生成的树的节点的相关操作
#文档的搜索
#(1)find_all字符串过滤
t_list1 = bs.find_all("input") #标签
t_list1 = bs.find_all("input", 2)
t_list1 = bs.find_all(type = "text")
t_list1 = bs.find_all(text = [])
#(2)搭配正则表达式搜索
import re
t_list2 = bs.find_all(re.compile("input"))
print("11,",t_list2)
#(3)调用自定义函数
def type_is_attr(tag):
return tag.has_attr("type")
t_list3 = bs.find_all(type_is_attr)
print("12,",t_list3)
#(4)搭配css选择器
t_list4 = bs.select(".pwd") #按类名查找
t_list5 = bs.select("input[clss = pwd]") #按类名查找
print("13,",t_list4, t_list5)
t_list6 = bs.select("head > title") #按子标签查找
print("14,",t_list6[0])
print("15,",t_list6[0].get_text())
3.re
通过正则表达过滤HTML文档中的无效信息。这里对正则表达式的运用并不是特别复杂,这里我跟着老师敲总是报错,于是自己改进了一下,贴一下源码:
#正则定义(从html文件中提取信息和并进行分类)
#影片内容链接
findLink = re.compile(r'') # r表示原生字符串, ‘可以避免与提取内容内“冲突, .任一字符, *前一个字符的0次或多次拓展, ?懒惰模式
#影片图片链接
findImg = re.compile(r'', re.S)
#影片名字
findTitle = re.compile(r'(.*?)', re.U)
#影片评分
findRating = re.compile(r'')
#影片评价人数
findJudge = re.compile(r'(\d*)人评价')
#影片概述
findInq = re.compile(r'(.*)', re.S)
#影片其他信息
findBd = re.compile(r'(.*?)
', re.S) 贴一下对re库进行测试的代码:
import re
#搜索
#(1)创建模式对象
pat = re.compile("AA")
res1 = pat.search("AABCDFHAAA")
#(2)不创建模式对象 (校验值, 查找对象)
res2 = re.search("AA", "AABCDFHAAA")
res3 = re.findall("[A-Z]+", "AsdfgHJ")
#替换
print(re.sub("a", "A", "asdfgas")) #A替换“asdfgas”中的a4.xlwt
这个库能够实现与excel表格的交互,用来将爬取的数据写入excel文档。
贴一下对xlwt库进行测试的代码:
import xlwt
'''
workbook = xlwt.Workbook(encoding='utf-8') #1.创建对象
worksheet = workbook.add_sheet('sheet1') #2.创建工作表
worksheet.write(0, 0, 'hello') #3.数组定位写入
workbook.save('student.xls') #4..xls格式保存
'''
#打印 9*9 乘法表
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet('sheet1')
for i in range(0, 9):
for j in range(0, i+1):
worksheet.write(i, j, '%u * %u = %u'%(i+1, j+1, (i+1)*(j+1)))
workbook.save('99table.xls')二、数据库部分
1.相关插件准备
教程中使用的是sqlite,并且是在程序中创建数据库。由于我之前接触的是MySQL因此决定用MySQL和已有的数据库重新实现一下,用到的是MySQLdb库。
- 数据库:使用PhpStudy中的MySQL,图形化管理插件是其软件库的PhpAdmin
- Pycharm(社区版)数据库图形化管理界面:下载插件DB Navigator,在view -> tool windows -> DB Browser中打开
2.具体操作
3.一些可能的debug
由于没有系统地学习过数据库的语法,具体SQL语句都得现查,导致我这部分出现了很多状况,在这里记录一下吧。
- DB Navigator 中 test connection 报错 :
- 错误信息:The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the serverTimezone configuration property) to use a more specifc time zone value if you want to utilize time zone support ; 错误类型:MySQL时区错误 ; 错误解决:在MySQL的bin目录下打开cmd并进行以下操作,即可修改时区并检查。
mysql -u root -p set global time_zone='+8:00'; show variables like '%time_zone%'; - 数据库SQL语句报错,出现这样的错误可以检查一下SQL语句是否有误:

三、Flask框架部分
1.相关插件准备
由于Pycharm社区版不能默认搭建flask框架,需要手动配置:
1.创建虚拟环境:通过新建项目中 new environment using Virtualenv 进行配置。
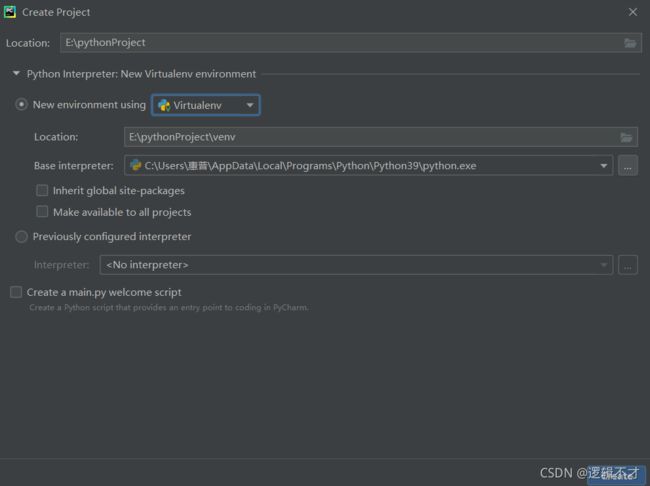
2.导入Flask库:setting中添加库即可。
3.新建相应文件夹:static文件夹用于存放模板样式,templates文件夹用于存放网页文件,app.py文件是框架主程序。

四、数据可视化部分
数据可视化部分需要从MySQL中查询数据并