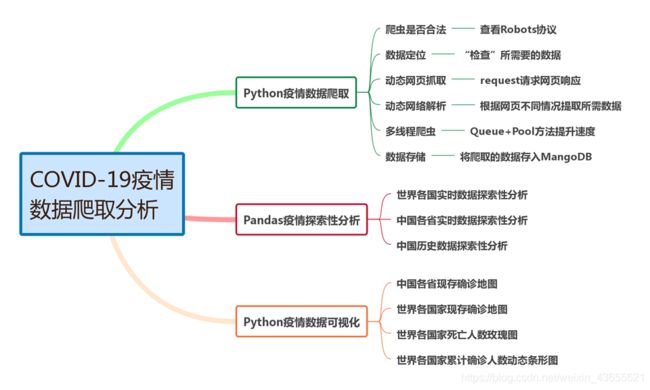
COVID-19疫情数据分析
新型冠状病毒感染的肺炎疫情爆发后,对人们的生活产生很大的影响。
现特对COVID-19疫情实时数据和历史数据进行爬取、分析、可视化展示。
设计框架
一、数据爬取
1.1 选择数据源:
选择网易的疫情实时动态播报平台作为数据源,地址:https://wp.m.163.com/163/page/news/virus_report/index.html?nw=1&anw=1

1.2 数据定位及抓取
导入相关库
import pandas as pd
import requests
import time
pd.set_option('max_rows',500) # 显示500行数据
# 设置请求头,伪装为浏览器
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 Edg/86.0.622.69'
}
# 发送请求
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total' # 定义要访问的地址
r = requests.get(url,headers = headers) # 使用requests发起请求
# 查看请求状态
r.status_code
200
响应码为200,说明页面正常响应成功!
print(type(r.text)) #查看类型。 r.text——文本获取
print(len(r.text)) # 查看文本长度
返回后的内容是一个30万长度的字符串,因字符串格式不方便进行分析,并且在网页预览中发现数据为类似字典的json格式,所以这里将其转为json格式。
import json
data_json = json.loads(r.text) # 按照json格式读取
data_json
data中存放着我们所需要的网页数据
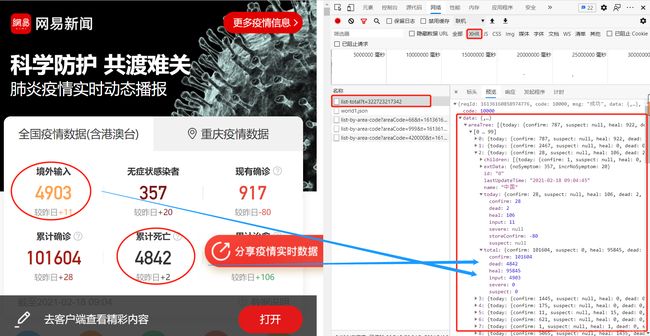
data = data_json['data'] # data中存放着我们需要的数据
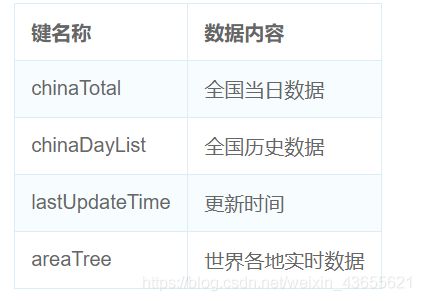
data.keys() # 查看数据键值
dict_keys(['chinaTotal', 'chinaDayList', 'lastUpdateTime', 'areaTree'])
数据中有四个键,每个键值含义不同
1.3 实时数据爬取
1.3.1 自定义函数:get_data(提取数据),save_data(保存数据)
# 将提取数据的方法封装为函数
def get_data(data,info_list):
info = pd.DataFrame(data)[info_list] # 基本信息
today_data = pd.DataFrame([i['today'] for i in data ]) # 获取today的数据
today_data.columns = ['today_'+i for i in today_data.columns] # 修改列名
total_data = pd.DataFrame([i['total'] for i in data ]) # 获取total的数据
total_data.columns = ['total_'+i for i in total_data.columns] # 修改列名
return pd.concat([info,total_data,today_data],axis=1) # info、today和total横向合并最终得到汇总的数据
# 定义保存数据方法
def save_data(data,name):
file_name = name+'_'+time.strftime('%Y_%m_%d',time.localtime(time.time()))+'.csv'
data.to_csv(file_name,index=None,encoding='utf_8_sig')
print(file_name+' 保存成功!')
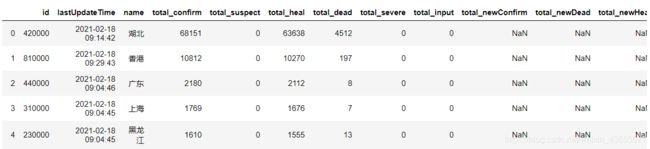
1.3.2 中国各省实时数据
data_province = data['areaTree'][2]['children'] # 取出中国各省的实时数据
today_province = get_data(data_province,['id','lastUpdateTime','name']) # 省略children,去除嵌套字典
save_data(today_province,'today_province')
1.3.3 世界各国实时数据
areaTree = data['areaTree'] # 取出areaTree
today_world = get_data(areaTree,['id','lastUpdateTime','name']) # 获取世界各国实时数据
save_data(today_world,'today_world')
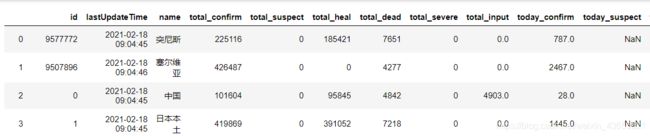
1.4 历史数据爬取
1.4.1 中国历史数据
chinaDayList = data['chinaDayList'] # 取出chinaDayList
alltime_China = get_data(chinaDayList,['date','lastUpdateTime'])
save_data(alltime_China,'alltime_China')
1.4.2 中国各省历史数据
在爬取各省历史数据的过程中,发现参数aeraCode=420000,而这刚好和全国各省实时数据today_province中的id对应,即更改爬取的URL中的aeraCode参数就可爬取不同省市的历史数据。
# 将各省行政区号和各省名称按照字典形式对位
province_dict = {
num:name for num,name in zip(today_province['id'],today_province['name'])}
start = time.time()
for province_id in province_dict: # 遍历各省编号
try:
# 按照省编号访问每个省的数据地址,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode='+province_id
r = requests.get(url, headers=headers)
data_json = json.loads(r.text)
# 提取各省数据,然后写入各省名称
province_data = get_data(data_json['data']['list'],['date'])
province_data['name'] = province_dict[province_id]
# 合并数据
if province_id == '420000':
alltime_province = province_data
else:
alltime_province = pd.concat([alltime_province,province_data])
print('-'*20,province_dict[province_id],'成功',
province_data.shape,alltime_province.shape,
',累计耗时:',round(time.time()-start),'-'*20)
# 设置延迟等待
time.sleep(20)
except:
print('-'*20,province_dict[province_id],'wrong','-'*20)
-------------------- 湖北 成功 (396, 16) (396, 16) ,累计耗时: 1 --------------------
-------------------- 香港 成功 (396, 16) (792, 16) ,累计耗时: 21 --------------------
-------------------- 广东 成功 (394, 16) (1186, 16) ,累计耗时: 42 --------------------
-------------------- 上海 成功 (380, 16) (1566, 16) ,累计耗时: 63 --------------------
-------------------- 黑龙江 成功 (385, 16) (1951, 16) ,累计耗时: 83 --------------------
-------------------- 浙江 成功 (392, 16) (2343, 16) ,累计耗时: 103 --------------------
-------------------- 河北 成功 (387, 16) (2730, 16) ,累计耗时: 124 --------------------
-------------------- 河南 成功 (394, 16) (3124, 16) ,累计耗时: 144 --------------------
......
-------------------- 青海 成功 (396, 16) (12889, 16) ,累计耗时: 678 --------------------
-------------------- 西藏 成功 (395, 16) (13284, 16) ,累计耗时: 710 --------------------
爬取成功并保存
save_data(alltime_province,'alltime_province')
1.4.3 世界各国历史数据爬取
# 将世界各国行政区号和世界各国名称按照字典形式对位
country_dict = {
key:value for key,value in zip(today_world['id'], today_world['name'])}
start = time.time()
for country_id in country_dict: # 遍历每个国家的编号
try:
# 按照编号访问每个国家的数据地址,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode='+country_id
r = requests.get(url, headers=headers)
json_data = json.loads(r.text)
# 生成每个国家的数据
country_data = get_data(json_data['data']['list'],['date'])
country_data['name'] = country_dict[country_id]
# 数据叠加
if country_id == '9577772':
alltime_world = country_data
else:
alltime_world = pd.concat([alltime_world,country_data])
print('-'*20,country_dict[country_id],'成功',country_data.shape,alltime_world.shape,
',累计耗时:',round(time.time()-start),'-'*20)
time.sleep(25)
except:
print('-'*20,country_dict[country_id],'wrong','-'*20)
-------------------- 突尼斯 成功 (335, 15) (335, 15) ,累计耗时: 11 --------------------
-------------------- 塞尔维亚 成功 (340, 15) (675, 15) ,累计耗时: 48 --------------------
-------------------- 中国 成功 (377, 15) (1052, 15) ,累计耗时: 73 --------------------
-------------------- 日本本土 成功 (354, 15) (1406, 15) ,累计耗时: 99 --------------------
......
-------------------- 列支敦士登 成功 (48, 15) (52674, 15) ,累计耗时: 5692 --------------------
-------------------- 马达加斯加 成功 (308, 15) (52982, 15) ,累计耗时: 5717 --------------------
爬取成功并保存
save_data(alltime_world,'alltime_world')
1.5 多进程爬取提快速度(queue+pool)
1.5.1 多进程爬取中国各省历史数据
import pandas as pd
import requests
import json
import threading
from multiprocessing import Pool, Manager
import time
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 Edg/86.0.622.69'
}
# 发送请求
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total'
r = requests.get(url, headers=headers)
data_json = json.loads(r.text) # 按照json格式读取
data = data_json['data']
def get_data(data, info_list):
info = pd.DataFrame(data)[info_list] # 主要信息
today_data = pd.DataFrame([i['today'] for i in data]) # 生成today的数据
today_data.columns = ['today_' + i for i in today_data.columns] # 修改列名
total_data = pd.DataFrame([i['total'] for i in data]) # 生成total的数据
total_data.columns = ['total_' + i for i in total_data.columns] # 修改列名
return pd.concat([info, total_data, today_data], axis=1) # info、today和total横向合并最终得到汇总的数据
data_province = data['areaTree'][2]['children'] # 取出中国各省的实时数据
today_province = get_data(data_province, ['id', 'lastUpdateTime', 'name']) # 省略children,去除嵌套字典
province_dict = {
num: name for num, name in zip(today_province['id'], today_province['name'])}
def ergodic(queue, j, q):
try:
province_id = queue.get(j)
# 按照省编号访问每个省的数据地址,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + province_id
r = requests.get(url, headers=headers)
data_json = json.loads(r.text)
# 提取各省数据,然后写入各省名称
province_data = get_data(data_json['data']['list'], ['date'])
province_data['name'] = province_dict[province_id]
q.append(province_data)
print('-' * 20, province_dict[province_id], '成功',
province_data.shape, '-' * 20)
# 设置延迟等待
time.sleep(20)
except:
print('-' * 20, province_dict[queue.get()], 'wrong', '-' * 20)
# # 定义保存数据方法
# def save_data(data, name):
# file_name = name + '_' + time.strftime('%Y_%m_%d', time.localtime(time.time())) + '.csv'
# data.to_csv(file_name, index=None, encoding='utf_8_sig')
# print(file_name + ' 保存成功!')
if __name__ == '__main__':
start = time.time()
alltime_province = []
manager = Manager()
workQueue = manager.Queue(100)
# 填充队列
for province_id in province_dict:
workQueue.put(province_id)
pool = Pool(processes=7)
for j in range(1, len(province_dict) + 1):
pool.apply_async(ergodic, args=(workQueue, j, alltime_province))
print("Started processes")
pool.close()
pool.join()
end = time.time()
print('Pool + Queue多进程爬虫的总时间为:', end - start)
Started processes
-------------------- 湖北 成功 (396, 16) --------------------
-------------------- 香港 成功 (396, 16) --------------------
......
-------------------- 宁夏 成功 (392, 16) --------------------
-------------------- 青海 成功 (396, 16) --------------------
Pool + Queue多进程爬虫的总时间为: 106.41728734970093
整体爬取时间缩短了7倍左右!
1.5.2 多进程爬取世界各国历史数据
import pandas as pd
import requests
import json
import threading
from multiprocessing import Pool, Manager
import time
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 Edg/86.0.622.69'
}
# 发送请求
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-total'
r = requests.get(url, headers=headers)
data_json = json.loads(r.text) # 按照json格式读取
data = data_json['data']
data.keys()
def get_data(data, info_list):
info = pd.DataFrame(data)[info_list] # 主要信息
today_data = pd.DataFrame([i['today'] for i in data]) # 生成today的数据
today_data.columns = ['today_' + i for i in today_data.columns] # 修改列名
total_data = pd.DataFrame([i['total'] for i in data]) # 生成total的数据
total_data.columns = ['total_' + i for i in total_data.columns] # 修改列名
return pd.concat([info, total_data, today_data], axis=1) # info、today和total横向合并最终得到汇总的数据
areaTree = data['areaTree'] # 取出areaTree
today_world = get_data(areaTree,['id','lastUpdateTime','name']) # 获取实时数据
country_dict = {
key:value for key,value in zip(today_world['id'], today_world['name'])}
def ergodic(queue, j, q):
try:
country_id = queue.get(j)
# 按照省编号访问每个省的数据地址,并获取json数据
url = 'https://c.m.163.com/ug/api/wuhan/app/data/list-by-area-code?areaCode=' + country_id
r = requests.get(url, headers= headers)
data_json = json.loads(r.text)
# 提取各省数据,然后写入各省名称
country_data = get_data(data_json['data']['list'], ['date'])
country_data['name'] = country_dict[country_id]
q.append(country_data)
print('-' * 20, country_dict[country_id], '成功',
country_data.shape, '-' * 20)
# 设置延迟等待
time.sleep(20)
except:
print('-' * 20, country_dict[queue.get()], 'wrong', '-' * 20)
if __name__ == '__main__':
start = time.time()
alltime_world = []
manager = Manager()
workQueue = manager.Queue(1000)
# 填充队列
for country_id in country_dict:
workQueue.put(country_id)
pool = Pool(processes=7)
for j in range(1, len(country_dict)+1):
pool.apply_async(ergodic, args=(workQueue, j, alltime_world))
print("Started processes")
pool.close()
pool.join()
end = time.time()
print('Pool + Queue多进程爬虫的总时间为:', end - start)
Started processes
-------------------- 日本本土 成功 (354, 15) --------------------
-------------------- 突尼斯 成功 (335, 15) --------------------
......
-------------------- 罗马尼亚 成功 (344, 15) --------------------
-------------------- 阿曼 成功 (345, 15) --------------------
-------------------- 马达加斯加 成功 (308, 15) --------------------
Pool + Queue多进程爬虫的总时间为: 643.1728949546814
整体爬取时间缩短了9倍左右
1.6 MongoDB存储数据
from pymongo import MongoClient
client = MongoClient('localhost',27017)
db = client.blog_database
collection = db.today_province
# 修改get_data函数
def get_data(data,info_list):
info = pd.DataFrame(data)[info_list] # 基本信息
today_data = pd.DataFrame([i['today'] for i in data ]) # 生成today的数据
today_data.columns = ['today_'+i for i in today_data.columns] # 修改列名
total_data = pd.DataFrame([i['total'] for i in data ]) # 生成total的数据
total_data.columns = ['total_'+i for i in total_data.columns] # 修改列名
# 同省今日数据&累计数据合并
d = pd.concat([info,total_data,today_data],axis=1)
collection.insert_many(json.loads(d.T.to_json()).values())
爬取并保存举例
# 爬取并保存各省数据
data_province = data['areaTree'][2]['children'] # 取出各省数据
today_province = get_data(data_province,['id','lastUpdateTime','name'])
总结
至此,网易疫情数据爬取已完成,从选取爬取源到数据定位,实时数据数据量较小,用python很快就能爬取下来,但是对于爬取量大一点的数据,即要考虑平台处于性能考虑会进行反爬机制,设置时间延迟来对抗反爬,又要尽量提快爬取速度,最终采用多进程爬取来优化爬取过程。另补充了一种数据库存储。
如有问题,请多指教!多探讨交流,谢谢!
参考资料:
http://cookdata.cn/note/view_static_note/fa203bf68cc57b10af2773bf5b48fd34/
--------后补充数据探索性分析---------
-----------文章较长,建议收藏--------
我们采用pandas库来进行数据分析
import pandas as pd
# 读取数据
today_world = pd.read_csv("today_world_2021_02_18.csv")
today_world.head()
二、数据探索性分析
英文列名不便于观察,更改为中文,使用rename()函数重命名
# 创建列名对应的中英文字典
name_dict = {
'date':'日期','name':'名称','id':'编号','lastUpdateTime':'更新时间',
'today_confirm':'当日新增确诊','today_suspect':'当日新增疑似',
'today_heal':'当日新增治愈','today_dead':'当日新增死亡',
'today_severe':'当日新增重症','today_storeConfirm':'当日现存确诊',
'total_confirm':'累计确诊','total_suspect':'累计疑似',
'total_heal':'累计治愈','total_dead':'累计死亡','total_severe':'累计重症',
'total_input':'累计输入','today_input':'今日输入'}
# 重命名
today_world.rename(columns=name_dict,inplace=True)
对数据进行简单查看
today_world.info() # 查看基本信息
today_world.describe() # 查看统计信息
today_world.set_index('名称', drop=False, inplace=True) # 将国家设置为索引
使用isnull()查看数据缺失值,计算缺失值比例,并进行缺失值处理
# 计算缺失值比例
today_world_nan = today_world.isnull().sum()/len(today_world)
# 转化为百分比
today_world_nan.apply(lambda x: format(x, '.1%'))
# 对当日现存确诊缺失值进行处理
today_world['当日现存确诊'] = today_world['累计确诊']-today_world['累计治愈']-today_world['累计死亡']
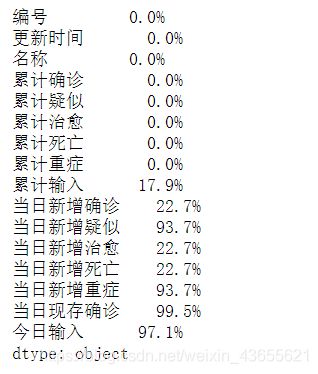
从缺失比例结果发现,当日新增相关数据缺失值较多,这主要由于采集数据的时候部分国家更新时间不一致,没有更新数据,因此我们将不再对其进行分析。
当日现存确诊人数,是由累计确诊人数-累计死亡人数-累计治愈人数所得
2.1 实时数据处理
反映疾病严重程度以及一个地区的医疗水平指标——病死率
计算公式:病死率 = 累计死亡 / 累计确诊
# 计算病死率,且保留两位小数
today_world['病死率'] = (today_world['累计死亡']/today_world['累计确诊']).apply(lambda x: format(x, '.2f'))
# 将病死率数据类型转换为float
today_world['病死率'] = today_world['病死率'].astype('float')
# 根据病死率降序排序
today_world.sort_values('病死率',ascending=False,inplace=True)
# 显示病死率前十国家
today_world.head(10)
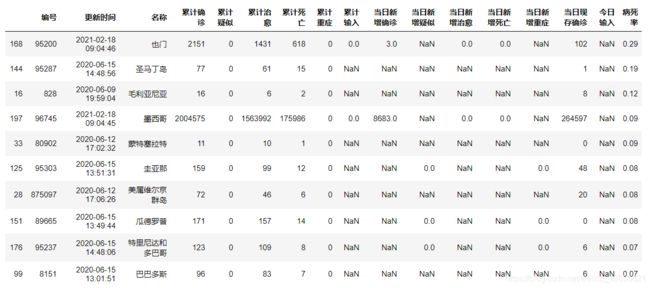
2.1.1 世界各国实时数据
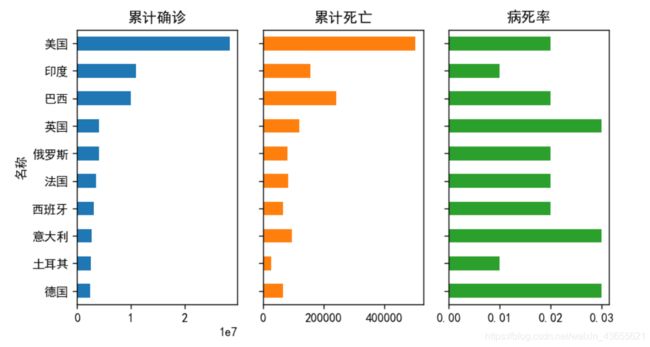
# 查看当前累计确诊人数前十国家
world_top10 = today_world.sort_values(['累计确诊'],ascending=False)[:10]
world_top10 = world_top10[['累计确诊','累计死亡','病死率']]
# 导入matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #正常显示中文
plt.rcParams['figure.dpi'] = 120#设置所有图片的清晰度
# 绘制条形图
world_top10.sort_values('累计确诊').plot.barh(subplots=True,layout=(1,3),sharex=False,
figsize=(7,4),legend=False,sharey=True)
plt.tight_layout() #调整子图间距
plt.show()
2.1.2 中国各省实时数据
# 读取数据
today_province = pd.read_csv("today_province_2021_02_18.csv")
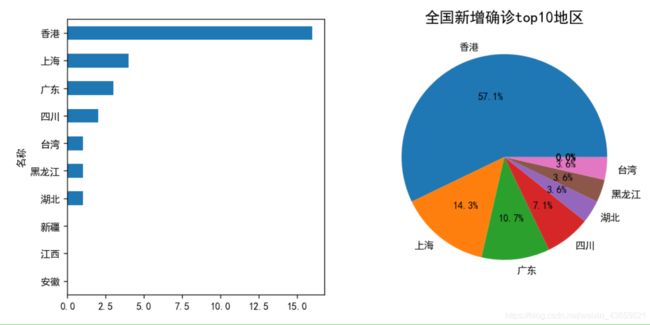
# 全国新增确诊top10地区
new_top6 = today_province['当日新增确诊'].sort_values(ascending=False)[:10]
# 可视化展示全国新增确诊top10地区情况
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
new_top6.sort_values(ascending=True).plot.barh(fontsize=10, ax=ax[0])
new_top6.plot.pie(autopct='%.1f%%', fontsize=10, ax=ax[1])
plt.ylabel('')
plt.title('全国新增确诊top10地区', size=15)
plt.show()
2.2 历史数据处理
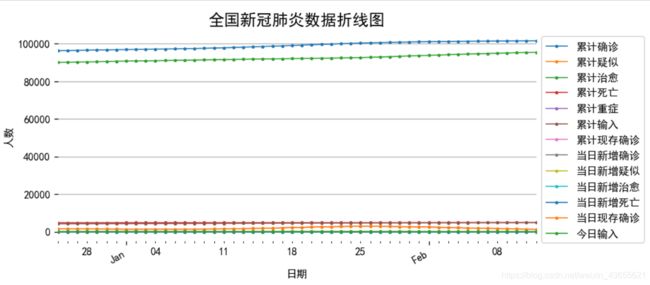
2.2.1 中国历史数据
# 取读数据
alltime_china = pd.read_csv('alltime_China_2021_02_13.csv')
# 将日期改为datetime格式
alltime_china['日期'] = pd.to_datetime(alltime_china['日期'])
# 将日期作为索引
alltime_china.set_index('日期', inplace=True)
对时间序列数据绘制折线图
import matplotlib.pyplot as plt
import matplotlib.dates as dates
import matplotlib.ticker as ticker
import datetime
fig, ax = plt.subplots(figsize=(8, 4))
alltime_china.loc['2020-12-25':'2021-02', ].plot(marker='o', ms=2, lw=1, ax=ax)
ax.xaxis.set_major_locator(dates.MonthLocator())
ax.xaxis.set_major_formatter(dates.DateFormatter('%b'))
fig.autofmt_xdate()
plt.legend(bbox_to_anchor = [1, 1])
plt.title('全国新冠肺炎数据折线图', size=15)
plt.ylabel('人数')
plt.grid(axis='y')
plt.box(False)
plt.show()
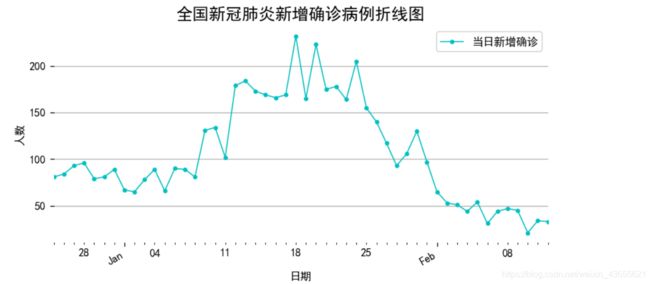
fig, ax = plt.subplots(figsize=(8, 4))
alltime_china['当日新增确诊'].loc['2020-12-25':'2021-02', ].plot(style='-', color='c', marker='o', ms=3, lw=1, ax=ax)
ax.xaxis.set_major_locator(dates.MonthLocator())
ax.xaxis.set_major_formatter(dates.DateFormatter('%b'))
fig.autofmt_xdate()
plt.legend(bbox_to_anchor = [1, 1])
plt.title('全国新冠肺炎新增确诊病例折线图', size=15)
plt.ylabel('人数')
plt.grid(axis='y')
plt.box(False)
plt.show()
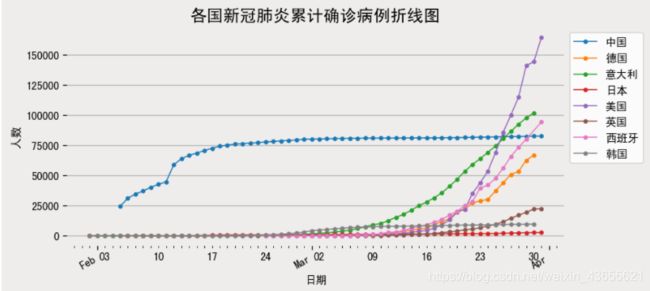
2.2.2 世界历史数据
alltime_world = pd.read_csv("alltime_world_2021_02_18.csv")
alltime_world['日期'] = pd.to_datetime(alltime_world['日期'])
alltime_world.set_index('日期', inplace=True)
# 取2020-03-31之前的数据,可视化展示好看
alltime_world = alltime_world.loc[:'2020-03-31']
# groupby创建层次化索引
data = alltime_world.groupby(['日期','名称']).mean()
# 提取部分国家数据
data_part = data.loc(axis=0)[:,['中国','日本','韩国','美国','意大利','英国','西班牙','德国']]
# 将层次索引还原
data_part.reset_index('名称',inplace=True)
绘制多个国家的累计确诊人数折线图
fig, ax = plt.subplots(figsize=(8,4))
data_part['2020-02':].groupby('名称')['累计确诊'].plot(legend=True,marker='o',ms=3,lw=1)
ax.xaxis.set_major_locator(dates.MonthLocator()) #设置间距
ax.xaxis.set_major_formatter(dates.DateFormatter('%b')) #设置日期格式
fig.autofmt_xdate() #自动调整日期倾斜
plt.title('各国新冠肺炎累计确诊病例折线图',size=15)
plt.ylabel('人数')
plt.grid(axis='y')
plt.box(False)
plt.legend(bbox_to_anchor = [1,1])
plt.show()
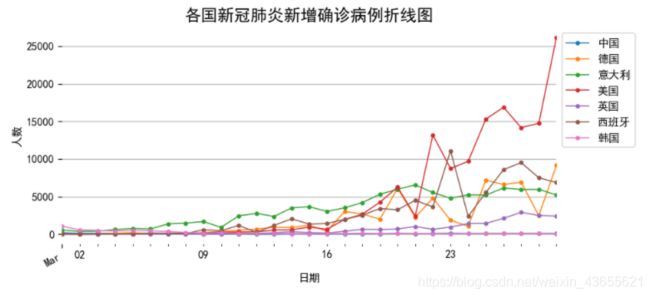
fig, ax = plt.subplots(figsize=(8,4))
data_part['2020-03':'2020-03-29'].groupby('名称')['当日新增确诊'].plot(legend=True,marker='o',ms=3,lw=1)
ax.xaxis.set_major_locator(dates.MonthLocator()) #设置间距
ax.xaxis.set_major_formatter(dates.DateFormatter('%b')) #设置日期格式
fig.autofmt_xdate() #自动调整日期倾斜
plt.title('各国新冠肺炎新增确诊病例折线图',size=15)
plt.ylabel('人数')
plt.grid(axis='y')
plt.box(False)
plt.legend(bbox_to_anchor = [1,1])
plt.show()
总结
本篇博客对新冠肺炎疫情数据的探索性分析。其中数据预处理主要包括特征列重命名、缺失值处理、查看重复值、数据类型转换等操作。此外,使用了Pandas进行数据可视化,通过图表的绘制探索数据的内涵。对时间序列数据采用折线展示处理、使用Groupby进行数据分组,学习了层次化索引的操作方法。
第三部分: