SVM支持向量机原理(一)12
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC#分类算法
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC#分类算法
from sklearn import datasets2 数据分类
x,y=datasets.make_blobs(n_samples=100,#数量
n_features=2,#两维,并两个特征
centers=2,#两个类别
random_state=3)
display(x.shape,y.shape,np.unique(y))
plt.scatter(x[:,0],x[:,1],c=y)
输出:
(100, 2)
(100,)
array([0, 1]) 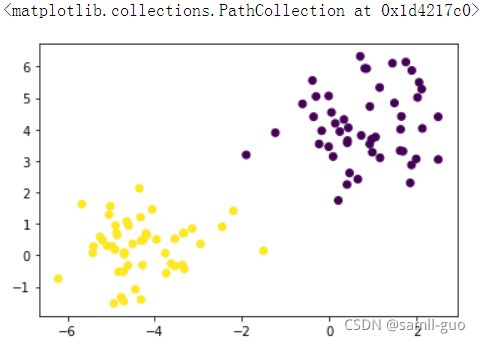
3 建模训练
svc=SVC(kernel='linear')#kernel表示核函数:linear,线性
svc.fit(x,y)
输出:
SVC(kernel='linear')
svc.score(x,y)
输出:
1.0
w_=svc.coef_
b_=svc.intercept_
display(w_,b_)
输出:
array([[-0.69194716, -1.00958201]])
array([0.90732128])y=w.x+b==>f(x)=w1.x1+w2.x2+b==>0=w1.x1+w2.x2+b
转换后:y=-w1/w2*(x)-b/w2
w=-w_[0,0]/w_[0,1]
b,=-b_/w_[0,1]#加逗号可以直接把数组变数值
b
输出:
0.8987098253546204sv=svc.support_vectors_#获取支持向量
sv
输出:
array([[ 0.21219196, 1.74387328],
[-1.8997797 , 3.19111595],
[-2.19341554, 1.41161044]])x,y=datasets.make_blobs(n_samples=100,
n_features=2,
centers=2,
random_state=3)#绘图缘故,从上面搬下来
x_=np.linspace(-5,1,100)
y_result=w*x_+b
plt.scatter(x[:,0],x[:,1],c=y)
plt.plot(x_,y_result,c='r')
#绘制上边界和下边界
#b=y-w.x
b1=sv[0][1]-w*sv[0][0]#把支持向量中的X,Y值代入算式
plt.plot(x,w*x+b1,color='b',ls='--',linewidth=0.5,alpha=0.2)
b2=sv[2][1]-w*sv[2][0]
plt.plot(x,w*x+b2,color='b',ls='--',linewidth=0.5,alpha=0.2)
总结:支持向量SVM确定一个分类线,就是要做大话d=1/||W||,就是最小化分母||W||,但是前提要满足y.(wT.x1+b)>=1的条件。记作:min0.5||w|| st(服从) (wT.Xi+b)>=1,(i=1,2,3,4,5,6....)
作业:
- 使用逻辑回归对手写数字(0~9)进行分类
- 但是分类准确率比较低
- 使用SVM支持向量机,进行分类,对比准确率情况!
- 数据多次(100次)随机拆分train_test_split(),求平均准确率
操作:
1 导包¶
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA#降维,减少数据维度
from sklearn.linear_model import LogisticRegression
2 拆分数据
digits=pd.read_csv('./digits.csv')
index=np.random.randint(0,42000,size=5000)
data=digits.take(index)
x=data.iloc[:,1:]
y=data['label']
display(x.shape,y.shape)
输出:
(5000, 784)
(5000,)x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.1)
display(x_train.shape,x_test.shape)
display(y_train.shape,y_test.shape)
输出:
(4500, 784)
(500, 784)
(4500,)
(500,)
3 建模对比
3.1 逻辑回归得分计算
import warnings
warnings.filterwarnings('ignore')#关闭过滤器报警
model=LogisticRegression(max_iter=1000,)
model.fit(x_train,y_train)
#display(model.coef_,model.intercept_)
model.score(x_test,y_test)
输出:
0.8243.2 SVM支持向量机得分计算
%%time
model=SVC()
model.fit(x_train,y_train)
model.score(x_test,y_test)
输出:
Wall time: 1.45 s
0.9564 100次计算平均分
¶
import matplotlib.pyplot as plt
index=np.random.randint(0,5000,size=1)[0]
num=x.iloc[index].values
plt.imshow(num.reshape(28,28),cmap='gray')
4.1 数据预处理
pca=PCA(n_components=0.95)#降维算法,n_components=0.95-->保留95%重要信息
#依然代表原来的数据
x_pca=pca.fit_transform(x)
x_pca.shape
输出:
(5000, 148)4.2 逻辑斯蒂100次运算平均分
%%time
score=0
for i in range(100):
#随机拆分
x_train,x_test,y_train,y_test=train_test_split(x_pca,y,test_size=0.1)
model=LogisticRegression()
model.fit(x_train,y_train)
score+=model.score(x_test,y_test)/100
print('逻辑回归的100次的平均得分:',score)
输出:
逻辑回顾的100次的平均得分: 0.84276
Wall time: 1min 31s4.3 支持向量机100次运算平均得分
%%time
score=0
for i in range(100):
#随机拆分
x_train,x_test,y_train,y_test=train_test_split(x_pca,y,test_size=0.1)
model=SVC()
model.fit(x_train,y_train)
score+=model.score(x_test,y_test)/100
print('支持向量的100次的平均得分:',score)
输出:
逻辑回顾的100次的平均得分: 0.9587600000000004
Wall time: 2min 20s