《python3 网络爬虫开发实践》笔记
最近阅读了一本书《python3 网络爬虫开发实践》,涉及的工具比较多,这本书可以当工具书来进行查阅。
由于书中内容繁多,所以我记的笔记都是理论部分较多,代码编写以及工具的使用涉及不多,感兴趣可以查阅下该书。
本文大纲如下(预计读完需要 15 分钟):
1、基本的环境和工具
1.1、请求库,发送网络请求
1.2、解析库,解析网页中提取的信息
1.3、数据库,用于存储获得的数据
1.4、Web 库,开发网站和接口
1.5、抓包工具,模拟与分析
1.6、成熟的爬虫框架
1.7、部署工具
2、基础知识
2.1、URL
2.2、HTTPS
2.3、Get & Post
2.4、爬虫定义
2.5、会话 & Cookies
2.5.1、常见误区
3、基本操作
3.1、高级一点的操作
3.1.1、处理二进制数据
3.2、Robots 协议
3.3、会话维持
3.4、使用代理
4、动态渲染数据爬取
4.1、Ajax 定义
4.2、Ajax 数据爬取
4.3、动态渲染页面
5、反爬虫与反反爬虫
1、基本的环境和工具
1.1、请求库,发送网络请求
-
requests : 用于发送请求,阻塞式 HTTP 请求库。
-
urllib : python 内置的 HTTP 请求库。
-
Selenium : 自动化测试工具,可以驱动浏览器执行特定的动作,如点击、下拉等。
-
ChromeDriver : Chrome 浏览器的驱动,只有装上相应浏览器的驱动,才能驱动浏览器完成相应的操作。
-
GeckoDriver : FireFox 浏览器的驱动。
-
PhantomJS : 无界面、可编程的 WebKit 浏览器引擎,这样运行时就不用弹出一个浏览器了。
-
aiohttp : 提供异步 Web 服务的库。
1.2、解析库,解析网页中提取的信息
-
lxml : 支持 HTML 和 XML 的解析,支持 Xpath 解析方式。
-
Beautiful Soup : 支持 HTML 或 XML 的解析。
-
pyquery : 提供类似 jQuery 语法解析 HTML 文档,支持 CSS 选择器。
-
tesserocr : 提供 OCR 识别功能。
1.3、数据库,用于存储获得的数据
-
MySQL : 轻量级的关系型数据库。
- PyMySQL
-
MongoDB : c++ 语言编写的非关系型数据库,基于分布式文件存储。
- PyMongo
-
Redis : 基于内存的高效的非关系型数据库。
-
redis-py
-
RedisDump : 基于 Ruby 实现的,用于 Redis 数据导入/导出的工具。
-
1.4、Web 库,开发网站和接口
-
Flask : 轻量级的 Web 服务程序。
-
Tornado : 支持异步的 Web 框架。
1.5、抓包工具,模拟与分析
现在很多页面都在向 HTTPS 方向发展,HTTPS 通信协议应用得越来越广泛。如果一个 App 通信应用了 HTTPS 协议,那么它通信的数据都会是被加密的,常规的截包方法是无法识别请求内部的数据的。
安装完成后,如果我们想要做 HTTPS抓包的话,那么还需要配置一下相关 SSL证书。
-
Charles : 支持跨平台的网络抓包工具,主要用在移动端。
-
mitmproxy : 支持 HTTP 和 HTTPS 的抓包程序,它通过控制台的形式操作。
-
appium : 移动端的自动化测试工具。
1.6、成熟的爬虫框架
-
pyspider : 支持 JavaScript 渲染的页面爬取,有强大的 WebUI、任务监控器等,支持多种数据库后端。
-
Scrapy : 十分强大的爬虫框架,依赖的库比较多。
-
Scrapy-Splash : 支持 JavaScript 渲染的工具。
-
Scrapy-Redis : 分布式扩展模块。
-
1.7、部署工具
-
Docker : 将应用和环境打包的容器技术。
-
Scrapyd : 用于部署和运行 Scrapy 项目的工具。
-
Scrapyd-Client : 打包代码,上传到远端主机。
-
Scrapyrt : HTTP 的调度接口。
-
Gerapy: 分布式管理工具。
-
2、基础知识
2.1、URL
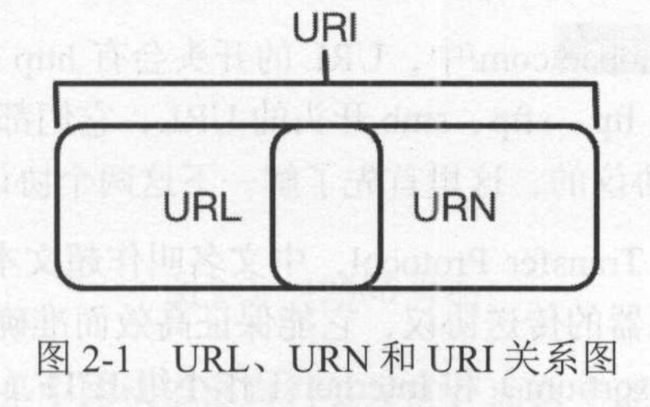
URI:uniform resource identifier,统一资源标志符。
URL:uniform resource loader,统一资源定位符。通过链接找到资源。
URN:uniform resource name,统一资源名称。只命名资源而不指定如何定位资源。
2.2、HTTPS
HTTPS 的安全基础是 SSL,因此通过它传输的内容都是经过 SSL 加密的,它的主要作用可以分为两种。
-
建立一个信息安全通道来保证数据传输的安全。
-
确认网站的真实性,凡是使用了 HTTPS 的网站,都可以通过点击浏览器地址栏的锁头标志来查看网站认证之后的真实信息,也可以通过 CA 机构颁发的安全签章来查询。
2.3、Get & Post
常见的请求方法有两种∶ GET 和 POST。
在浏览器中直接输入 URL 并回车,这便发起了一个 GET 请求,请求的参数会直接包含到 URL 里。例如,在百度中搜索 Python,这就是一个 GET 请求,链接为 https://www.baidu.com/s?wd=Python,其中 URL 中包含了请求的参数信息,这里参数 wd 表示要搜寻的关键字。GET 的请求体为空。POST 请求大多在表单提交时发起。比如,对于一个登录表单,输入用户名和密码后,点击"登录"按钮,这通常会发起一个 POST 请求,其数据通常以表单的形式传输,而不会体现在 URL 中。
GET 和 POST 请求方法有如下区别。
-
GET 请求中的参数包含在 URL 里面,数据可以在 URL 中看到,而 POST 请求的 URL 不会包含这些数据,数据都是通过表单形式传输的,会包含在请求体中。
-
GET 请求提交的数据最多只有 1024 字节,而 POST 方式没有限制。
一般来说,登录时,需要提交用户名和密码,其中包含了敏感信息,使用 GET 方式请求的话,密码就会暴露在 URL 里面,造成密码泄露,所以这里最好以 POST 方式发送。上传文件时,由于文件内容比较大,也会选用 POST方式。
2.4、爬虫定义
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序。
最关键的部分就是构造个请求并发送给服务器,然后接收到响应并将其解析出来。
2.5、会话 & Cookies
HTTP 的无状态是指 HTTP 协议对事务处理是没有记忆能力的,也就是说服务器不知道客户端是什么状态。当我们向服务器发送请求后,服务器解析此请求,然后返回对应的响应,服务器负责完成这个过程,而且这个过程是完全独立的,服务器不会记录前后状态的变化,也就是缺少状态记录。这意味着如果后续需要处理前面的信息,则必须重传,这导致需要额外传递一些前面的重复请求,才能获取后续响应,然而这种效果显然不是我们想要的。为了保持前后状态,我们肯定不能将前面的请求全部重传一次,这太浪费资源了,对于这种需要用户登录的页面来说,更是棘手。
这时两个用于保持 HTTP 连接状态的技术就出现了,它们分别是会话和 Cookies。会话在服务端,也就是网站的服务器,用来保存用户的会话信息;Cookies 在客户端,也可以理解为浏览器端,有了 Cookies,浏览器在下次访问网页时会自动附带上它发送给服务器,服务器通过识别 Cookies 并鉴定出是哪个用户,然后再判断用户是否是登录状态,然后返回对应的响应。
我们可以理解为 Cookies 里面保存了登录的凭证,有了它,只需要在下次请求携带 Cookies 发送请求而不必重新输入用户名、密码等信息重新登录了。
2.5.1、常见误区
在谈论会话机制的时候,常常听到这样一种误解——“只要关闭浏览器,会话就消失了”。可以想象一下会员卡的例子,除非顾客主动对店家提出销卡,否则店家绝对不会轻易删除顾客的资料。对会话来说,也是一样,除非程序通知服务器删除一个会话,否则服务器会一直保留。比如,程序一般都是在我们做注销操作时才去删除会话。
但是当我们关闭浏览器时,浏览器不会主动在关闭之前通知服务器它将要关闭,所以服务器根本不会有机会知道浏览器已经关闭。之所以会有这种错觉,是因为大部分会话机制都使用会话 Cookie 来保存会话 ID 信息,而关闭浏览器后 Cookies 就消失了,再次连接服务器时,也就无法找到原来的会话了。如果服务器设置的 Cookies 保存到硬盘上,或者使用某种手段改写浏览器发出的 HTTP 请求头,把原来的 Cookies 发送给服务器,则再次打开浏览器,仍然能够找到原来的会话 ID,依旧还是可以保持登录状态的。
而且恰恰是由于关闭浏览器不会导致会话被删除,这就需要服务器为会话设置一个失效时间,当距离客户端上一次使用会话的时间超过这个失效时间时,服务器就可以认为客户端已经停止了活动,才会把会话删除以节省存储空间。
3、基本操作
# 普通 GET 请求
response = urllib.request.urlopen('https://www.python.org')
print(response.read().decode('utf-8'))
# POST 请求
# 这里我们传递了一个参数 word, 值是 hello, 它需要被转码成 bytes(字节流)类型
# 而转字节流采用了 bytes 方法,该方法的第一个参数需要是 str(字符串)类型
data = bytes(urllib.parse.urlencode({
'word' : 'hello'}), encoding = 'utf8')
# 还有 timeout 设置超时参数
# cafile 和 capath 这两个参数分别指定 CA 证书和它的路径
response = urllib.request.urlopen('http://httpbin.org/post', data = data)
# request 更多的控制参数
# headers 参数通常是设置 User-Agent 来伪装浏览器
# method 代表 GET、POST 等
urllib.request.Request(url, data=None, headers={
}, origin_req_host=None, unverifiable=False, method=None)
3.1、高级一点的操作

# urllib.request 模块里的 BaseHandler 类可以处理 Cookies 等高级操作
# 比如下图的需要身份验证
from urllib.request import HTTPPasswordMgrWithDefaultRealm, HTTPBasicAuthHandler, build_opener
from urllib.error import URLError
username = username
password = 'password'
url = 'http://localhost:5000/'
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
try:
result = opener.open(url)
html = result.read().decode('utf8')
print(html)
except URLError as e:
print(e.reason)
# 设置代理
proxy_handler = ProxyHandler({
'http' : 'http://127.0.0.1:9743',
'https': 'https://127.0.0.1:9743'
})
opener = build_opener(proxy_handler)
# 设置 Cookies
cookie = http.cookiejar.CookieJar()
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open('http://www.baidu.com')
# request 库设置 Cookies,request 库可以直接把 Cookie 参数放到 headers 里
r = requests.get('https://www.baidu.com')
# 从中可以看出 Cookie 的类型
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)
# urlparse() 可以实现 URL 的识别和分段
# quote() 可以将中文字符串转化为 URL 编码
# 对应 unquote() 就是反过来
# 身份验证
r = requests.get('http://localhost:5000', auth=('username', 'password'))
3.1.1、处理二进制数据
# 下载文件
import requests
r = requests.get('https://github.com/favicon.ic')
with open('favicon.ico', 'wb') as f:
f.write(r.content)
# 上传文件
files = {
'file' : open('favicon.ico', 'rb')}
r = requests.post('http://httpbin.org/post', files=files)
3.2、Robots 协议
Robots 协议也称作爬虫协议、机器人协议,它的全名叫作网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。它通常是一个叫作 robots.txt 的文本文件,一般放在网站的根目录下。
当搜索爬虫访问一个站点时,它首先会检查这个站点根目录下是否存在 robots.txt 文件,如果存在,搜索爬虫会根据其中定义的爬取范围来爬取。如果没有找到这个文件,搜索爬虫便会访问所有可直接访问的页面。
User-agent: *
Disallow: /
Allow: /public/
上面案例的文件内容,意思是对所有搜索爬虫只允许爬取 public 目录。
User-agent 用来设置爬虫的名称,* 号代表对所有都适用。
Disallow 代表不能抓取的目录,/ 代表不允许抓取所有的页面。
# 传入 robots.txt 文件的链接即可解析
urllib.robotparser.RobotFileParser(url='')
print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7d'))
3.3、会话维持
在 requests 中,如果直接利用 get 或 post 等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开了不同的页面。
设想这样一个场景,第一个请求利用 post 方法登录了某个网站,第二次想获取成功登录后的自己的个人信息,你又用了一次 get 方法去请求个人信息页面。实际上,这相当于打开了两个浏览器,是两个完全不相关的会话,能成功获取个人信息吗?那当然不能。
有小伙伴可能说了,我在两次请求时设置一样的 cookies 不就行了?可以,但这样做起来显得很烦琐,我们有更简单的解决方法。
其实解决这个问题的主要方法就是维持同一个会话,也就是相当于打开一个新的浏览器选项卡而不是新开一个浏览器。但是我又不想每次设置 cookies,那该怎么办呢?这时候就有了新的利器——Session 对象。
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
3.4、使用代理
对于某些网站,在测试的时候请求几次,能正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验证码,或者跳转到登录认证页面,更甚者可能会直接封禁客户端的IP,导致一定时间段内无法访问。
import requests
proxies = {
"http" : "http://10.10.1.10:3128",
"https" : "http://10.10.1.10:1080",
}
requests.get("https://www.taobao.com", proxies=proxies)
4、动态渲染数据爬取
有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样∶
在浏览器中可以看到正常显示的页面数据,但是使用 requests 得到的结果并没有。这是因为 requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是经过 JavaScript 处理数据后生成的结果,这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在 HTML 文档中的,也可能是经过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式,原始的页面最初不会包含某些数据,原始页面加载完后,会再向服务器请求某个接口获取数据,然后数据才被处理从而呈现到网页上,这其实就是发送了一个 Ajax 请求。
照 Web 发展的趋势来看,这种形式的页面越来越多。网页的原始 HTML 文档不会包含任何数据,数据都是通过 Ajax 统一加载后再呈现出来的,这样在 Web 开发上可以做到前后端分离,而且降低服务器直接渲染页面带来的压力。
所以如果遇到这样的页面,直接利用 requests 等库来抓取原始页面,是无法获取到有效数据的,这时需要分析网页后台向接口发送的 Ajax 请求,如果可以用 requests 来模拟 Ajax 请求,那么就可以成功抓取了。
4.1、Ajax 定义
Ajax ,全称为 Asynchronous JavaScript and XML ,即异步的 JavaScript XML 它不是一门编程语言,而是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了 Ajax ,便可以在页面不被全部刷新的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行了数据交互,获取到数据之后,再利用 JavaScript 变网页,这样网页内容就会更新了。
4.2、Ajax 数据爬取
发送 Ajax 请求到网页更新的这个过程可以简单分为以下几步:
1、发送请求
2、解析内容
3、渲染网页
通过开发者模式找到 type 为 XHR 的请求,查看请求的 url 和请求体,同样进行模拟即可。
并非所有页面都可以通过分析 Ajax 来完成抓取,一些页面的参数比较复杂,可能会包含加密密钥,想自己构造参数,还是比较困难的。
通过直接模拟浏览器操作,就不需要再关注这些接口参数。
4.3、动态渲染页面
不过 javaScript 动态渲染的页面不止 Ajax 这一种, 某些网页的分页部分是由 JavaScript 生成的,并非原始 HTML 代码,这其中并不包含 Ajax 请求,比如 ECharts 的官方实例,其图形都是经过 JavaScript 计算之后生成的。
为了解决这些问题,我们可以直接使用模拟浏览器运行的方式来实现,这样就可以做到在浏览器中看到是什么样,抓取的源码就是什么样,也就是可见即可爬。这样我们就不用再去管网页内部的 JavaScript 用了什么算法渲染页面,不用管网页后台的 Ajax 接口到底有哪些参数。
比如下一页,怎么判断当前是哪一页?

获取高亮显示的 css 选择器。
Chrome Headless 模式:Chrome 59 版本开始支持无界面模式,这样爬取的时候就不会弹出浏览器了。
5、反爬虫与反反爬虫
- 许多网站使用花样繁多的验证码来反爬虫。
采用 OCR 技术识别验证码,由 tesserocr 库提供支持。
- 使用滑块验证码
识别滑动缺口的位置,模拟拖动滑块。(多缺口图、滑动时才闪现缺口),完全模拟加减速可行。
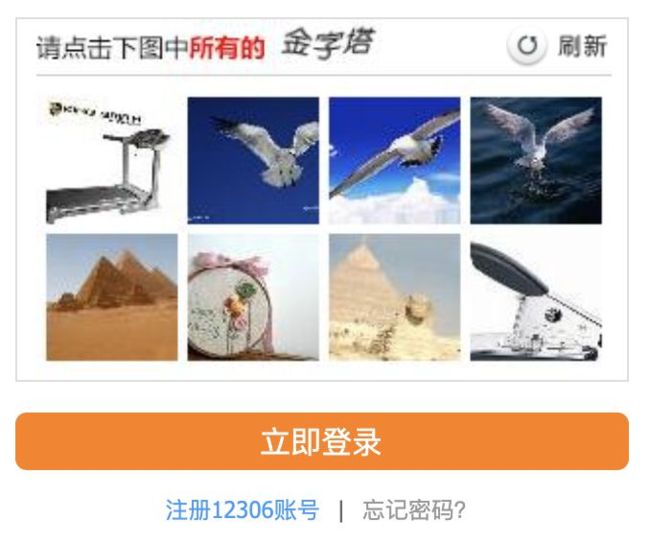
12306 的难度:首先需要识别文字,再识别图片找出文字对应的。
- 服务器识别 ip 的请求次数
使用代理伪装 ip