并行信号处理技术-序
序之序
下面几篇将连载并行信号处理技术,内容来自于我原来的工作,略作总结。
这个系列在调研国内外通用异构计算技术和软件化雷达技术的基础上,结合某雷达样机验证项目,探寻在基于GPU的通用异构服务器上进行实时信号处理任务和建立软件化信号处理软件开发体系。在此基础上分析阐述了当前通用异构计算领域的关键技术、性能指标、硬件组成和软件开发手段,探索未来全软件化架构的发展和在通用异构服务器上,特别是针对GPU和多CPU情况下进行雷达信号实时处理的可能性。
所用硬件平台是建立在商用COTS服务器基础上,搭载多核多CPU和多GPU加速卡的异构并行处理平台,并在此硬件平台上实现了窄带脉冲多普勒雷达和宽带逆合成孔径雷达的并行化设计和部署,验证了异构环境下运算的实时性和正确性。最后结合前期调研,尝试性的设计了适合于通用异构并行平台的软件化雷达开发体系架构和实现思路,并就可能涉及的关键技术进行了初步分析。
这一篇[补充连接]阐述了本课题的研究背景和研究意义,并调研国内外相关研究的进展,和平行领域对通用异构并行平台的研制情况进和发展经验,对本文课题进行了背景研究和简单综述。
这一篇[补充连接]首先介绍了并行计算体系的原理和可能结构,并针对本文采用的多核多CPU以及GPGPU加速的异构并行平台,分别阐述了相关的并行计算模型和开发手段,特别针对本课题使用的CUDA体系框架和OpenMP并行计算模型进行了详细的阐述。对其计算架构和编程技术做了较为详细的分析,为后文的应用实例奠定基础。
这一篇[补充连接]就窄带脉冲多普勒(PD)雷达在基于GPGPU的通用异构并行平台上的应用设计做出说明,包括对动目标检测理论的分析,关键算法的并行化设计和在本异构并行平台上的部署工作,最后分析了并行设计并实现后的运算性能,并和传统基于TI C6678 DSP的嵌入式平台进行了对比验证,验证了本文阐述的并行化设计方法和实现手段在对于窄带目标检测跟踪雷达的信号处理算法实时实现上的可用性和高效性。
这一篇[补充连接]就宽带逆合成孔径成像雷达(ISAR)在基于GPGPU的通用异构并行平台上的应用设计做出分析,包括对ISAR典型信号处理过程的原理分析,关键算法的并行化设计和在本异构并行平台上的部署工作,最后分析了并行设计并实现后的运算性能,并和传统基于TI C6678 DSP的嵌入式平台进行了对比验证,验证了本文阐述的并行化设计方法和实现手段在对于宽带成像雷达的信号处理算法实时实现上的可用性和高效性。
这一篇[补充连接]就本课题使用的基于GPGPU的通用异构并行平台,结合软件化雷达发展要求,对其软件化体系架构做出分析,尝试性的提出了异构并行通用计算平台上的软件化雷达体系架构。对软件化的综合处理子系统做了概念性分析,阐述了一种采用五层划分软件化体系实现方式,并就其可能需要攻破的关键技术做出了初步分析。
最后,对本文设计采用的COTS硬件,基于GPGPU的通用并行综合处理平台,异构并行模式下的软件开发手段,特别是将GPGPU应用于雷达信号处理领域的探索,以及软件化综合处理子系统的实现方式的探索做出总结,并展望了未来全COTS的、异构的、并行化的、通用的、软件化的雷达综合处理子系统的发展。
背景和意义
然而随着材料科学和电子对抗技术发展,雷达面临着前所未有的挑战。隐身、低空、高速、高机动目标对雷达的探测能力提出了新的要求;电磁波频率的日益紧缺,现代电磁环境复杂多变性对雷达适应能力和抗干扰能力是严峻的考验[2]。传统雷达工作模式固定、可调整参数有限、资源配置僵化、信号处理方案受平台制约,已经难以适应瞬息万变的现代化战场要求。
结合现代IC和IT技术,雷达信号处理的精细化研发需要从雷达工业体制、雷达系统结构、信号处理平台、雷达算法研究等多方面做出改变。然而功能多样、用途广泛的传统雷达在软硬件选择、设备生产制造一直都是定制的,给雷达系统的开发、维护、升级带来了很大困难。为了统一雷达装备的设计制造、提高装备效费比、缩短研发周期、保证装备研制的可靠性和可维护性,军方对雷达装备特别是信号处理子系统的统型逐渐重视。雷达系统的高度可重构、功能可扩展、模式多样化成为研制开发的迫切需求[3],缩短研制周期、提高可维护能力更是势在必行。自上世纪80年代后期以来,雷达经历了模块化、通用化、数字化、软件化四个发展阶段,其发展趋势始终是信号处理系统的通用化,其它分系统最大程度的数字化,开发验证环境尽可能的软件化。
为此,本文瞄准雷达精细化研发和智能化处理需求,以数字化和软件工程技术为支撑,构建基于通用图形处理器(GPGPU)的通用化雷达综合信息处理平台,其核心为以通用图形处理器为主要运算单元,配合多个高性能多核中央处理器(CPU),在此异构平台上,进行实时的雷达信号信息处理工作。在软件设计上,考虑构件化和通用化[4],以合理的软件框架结构和标准的应用程序接口(API)定义,形成可复用、可重构、组件化的综合雷达信号信息处理软件平台,满足更精细、更灵活多样的雷达处理工作。同时通过软件的逐层抽象和封装,将开发任务分级分层,形成自上而下的逐层开放结构,各级别开发人员及其使用的软硬件资源松耦合,达到快速开发、快速迭代、快速重构的目的,满足新的需求。
现状和趋势
实时处理平台研制技术
(1)高性能运算处理器
随着半导体技术的发展,微处理器的运算性能大幅度提高,但实际处理能力与具体应用算法的实现方法密切相关[5],而实时信号处理中关键性的I/O能力相对较弱,不同类型的微处理器在实时信号处理领域表现不一[6]。在实时信号处理中主流处理器有如下四类:
① 数字信号处理器(DSP),浮点运算能力强、I/O带宽大,适合信号处理运算和高带宽通信。随着多核DSP的成熟其处理能力得到了进一步的提升。目前这类DSP依然是雷达信号处理领域的主流处理设备。
② FPGA构建的专用处理设备,定点运算能力极强、I/O带宽极大,但较难进行软件化设计,且浮点性能不足。一般用在信号处理机前端或作为特定算法的协处理器,如正交插值、滤波、固定系数脉压、FFT、固定权DBF等。
③ 通用CPU具有较高的主频,其运算速度最高达每秒数百亿至千亿次浮点,这一指标远高于DSP,如Intel Core系列主频超3GHz。但其不足是用户开发硬件难度高、功耗大、I/O带宽远低于其运算能力。这类处理器拥有良好的软件生态环境和良好的兼容性,有利于系统设计的可持续性。
④ GPU作为一种新兴的协处理器,补充了CPU在矢量运算上的劣势,利用其大量的运算核心获得了极高的数据吞吐量,在较低核心频率(1.328GHz)下获得了最高达每秒十万亿次浮点的运算能力(GP100)。同时良好的软件生态环境也大大降低了开发周期,但其不足是不能独立于CPU运行且功耗较大。
表1 主流处理器指标和应用情况
| 型号 |
Xeon E5-2450 |
TI C6678 |
Nvidia GP100 |
FPGA |
| 核心频率 |
2.9 GHz |
1.25 GHz |
1328 MHz |
500 MHz |
| 处理内核 |
8 |
8 |
3584 |
- |
| 浮点处理速度 |
410亿/秒 |
160亿/秒 |
10万亿/秒 |
弱 |
| 定点处理速度 |
980亿/秒 |
320亿/秒 |
强 |
>1万亿/秒 |
| 通信速度 |
38.4 GB/秒 |
10GB/秒 |
160GB/秒 |
>50GB/秒 |
| 功耗 |
95W |
15W |
300W |
5W |
| 硬件设计难度 |
高 |
较高 |
高 |
低 |
| 软件设计成本 |
低 |
较高 |
低 |
高 |
(2)国内外专用信号处理平台研制情况
从设计趋势上看,未来更强调通用化和软件化。从硬件选用上看,处理器发展水平相对雷达应用的运算要求是满足的。因此信号处理设备的设计制造将更多的是系统设计和软件开发。这样规避了先进处理器系统的硬件设计难度大、周期长、成本高的问题。
国外厂商采用DSP、FPGA、CPU等多种处理器混合设计的雷达信号处理机型号多样、规模和处理速度不一,处理机的互连结构、操作系统和软件设计上千差万别。尽管都强调通用化和软件化,也采用可编程、可扩展、可重构的设计方法,但通用性、易用性仍不足,编程效率低,缺乏高层设计软件支持。而在强调通用化特点后,限制了有针对性的优化措施,制约了处理机的运算效率。并且为满足雷达系统特殊要求,在标准总线基础上又设计了背板自定义连线和前面板数据端口(FPDP)增加了系统复杂度,不便于维护和扩展,有悖于通用化的设计需求,同时在软件的可移植性上也由于专用接口和定制总线的存在而带来困难。
国内雷达、声呐、航空等行业的多家单位设计生产的信号处理设备相继采用具备高速通信能力的新型总线,如VPX。国内航天、航空、舰船领域的专业设备研究所,主要雷达研究所,包络北理、西电在内的各大高校先后研制了兼容OpenVPX标准的信号处理设备。
软件化雷达处理平台的发展
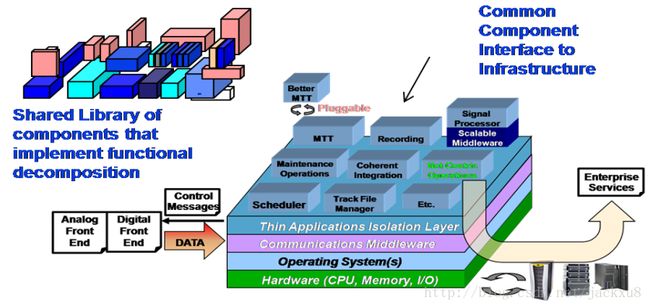
ROSA-II分层架构如图2所示,左侧代表已优化好的组件库,可根据系统设计搭建雷达系统。组件要求具有很好的工程特性、相互松耦合、遵循接口控制文件(ICD)标准。ROSA-II在标准组件库中增加了网络服务组件以支持网络中心化服务,配合控制组件和数据流组件,允许设计者搭建完全网络中心式系统,支持多任务需求,以及传感器数据收集、流数据产生等。ROSA-II结构中自顶向下分别是:应用组件层,应用独立层,中间件,操作系统和硬件层。ROSA-II增加了雷达开放式体系架构应用独立层(RTCL),上层组件以应用程序编程接口形式连接RTCL的通用接口。RTCL将组件和中间件隔离,具有任意多个中间件兼容的特点。例如,在一个系统中可以存在两种中间件,一个可以用来在一个对称多核计算平台上进行组件之间的数据传输,另一个用来支持网间的数据传输。前者采用共享存储器方式,避免数据拷贝,有利于提高系统吞吐量、减小延迟。后者是数据分布服务(DDS)组件,用于B/S模式下的发布-订阅式数据传输。ROSA已成为雷达开放式体系架构ROSA 2020防御系统工程的一部分,由美国USD(AT&L)防御研究团队领导,旨在促进通用开放的、以网为中心的雷达体系架构的发展。
从用户方面看,国内雷达型号多、用途差异大,设计方法、核心器件、性能水平等差别很大,设备整体存在以下诸多问题,严重制约了设备的可维护性和稳定性;硬件设备标准不统一,数据传输协议差异大,软件设计多样化。用户对众多前端信号处理设备和终端的软硬件和接口标准统一化有迫切需求,早在“十五”期间就提出通用信号处理机的发展计划,并已着手标准制定,拟在某些地面情报雷达中推广[16]。
硬件方面,数字化技术正迅速应用,全数字化雷达已逐步走向成熟应用阶段。其主要技术优点有:系统资源利用率高,易实现同时多功能;动态范围大,测角精度高;超低副瓣以及自适应波束置零;易实现天线阵列自校准和失效单元校正;可实现以距离为函数的自适应处理技术;易实现硬件重构和软件重组,具备可扩充性和柔性制造。国防科技大学已实现多通道射频数字化接收组件,可用于有源/无源相控阵雷达,给软件化雷达发展提供了技术支撑[17]。西安电子科技大学研制的基于TI C6678的多核多处理通用平台,解决了雷达信号处理设计方法软硬件耦合紧、研发低效率、无移植性、通用性差的问题,为软件化雷达的研制提供硬件基础[18]。目前,已经做到信号处理模块通用,数字采样模块通用等,硬件模块通用化,初步制定了一些软硬件规范,为软件化雷达提供有力的基础。
软件方面,国内计算所从事基础软件到应用软件的研发,可以为软件化雷达服务。清华大学推出了多DSP平台上的自动代码生成软件,针对特定多DSP平台上的具体代码进行分类和特征提取,能够在通用代码框架模板下生成DSP源代码,为软件化雷达的发展提供软件支撑。清华大学汤俊教授带领的团队已经完成通用雷达信号实时处理平台RadarLab 2.0的研发工作[3],实现了上层硬件和底层硬件的解耦,可显著提高雷达信号处理系统的开发效率和灵活性。
GPU设备的演进
目前,GPU设备的主要生产商有Intel、AMD(ATI),NVidia和Matrox,作为通用计算设备,且具有较为完善软件开发环境和良好社区生态的是NVidia支持的CUDA体系GPU系列。NVidia GPU主要分为Tesla(2008)、Fermi(2010)、Kepler(2012)、Maxwell(2014)和最新的Pascal(2016)架构,以及即将推出的Volta(2018)架构。图3显示了自2002年以来,NVidia GPU和Intel CPU在浮点运算性能上的比较,可以看出GPU经过几代的发展其浮点运算能力远远高于CPU。




GPU在通用计算领域的推广

当前科学计算领域多数数值模拟问题都是数据产生过程,也就是将数据输入设定的模型来模拟科学试验过程。这类运算主要依赖于计算系统的浮点运算能力,而且对运算精度有较高的要求。一般在数值模拟算法中使用双精度数运算。而NVidia提供的Tesla P100和Tesla K80这类双精度运算能力较强的科学计算加速卡成为科学加速的首选。中国曙光高性能计算公司为中科院重离子研究团队提供了搭载8块Tesla P100加速卡的DGX-1方案,得到了70%以上的加速效果,加速了求解重离子研究遇到的难题。
(2) 卫星通信系统中扩频信号捕获算法的GPU加速
中国科学院大学的数据挖掘与高性能计算实验室在解决扩频捕获技术上提出了基于滑动相关的并行捕获算法,该捕获算法采用4块NVidia K40c计算卡,相对于Intel IPP的多CPU并行加速,实现了400多倍的性能提升,并具有良好的扩展性。在真实遥测数据的测试实验中,获得了显著的效果。
在通信领域,诸如调制解调、目标识别、目标追踪等,都能够使用GPU并行计算平台获得很好的加速效果。
(3) 石油工业勘探中地震资料分析的GPU加速
工业勘探领域需要对地震波信号等计算资料进行水平叠加、偏移校正等处理,以反映地下地层形态和各种地质现象。为了满足是由勘探中地震波分析的计算需求,曙光团队设计了HC2000异构计算方案,采用天阔W580I GPU服务器,具有1TB内存,搭载4块的NVidia K80加速卡,单节点提供高达24 TFLOPS的单精度计算性能。为了解决地震波运算中高I/O请求,采用56G FDR IB网络,配合自研的ParaStor200并行数据持久系统。同时结合专用的Gridview作业调度环境,充分发挥了GPU异构计算系统的运行效率。