协方差、样本协方差、协方差矩阵、相关系数详解(python代码)
对于一个随机变量的分布特征,可以由均值、方差、标准差等进行描述。而对于两个随机变量的情况,有协方差和相关系数来描述两个随机变量的相互关系。
本文主要参考概率论与数理统计的教科书,整理了协方差、样本协方差、协方差矩阵、相关系数的概念解释和代码。
协方差(covariance)
协方差的概念来自概率论,实际应用中的样本协方差则与统计学概念有关。
协方差反应了随机变量 X 、 Y X、Y X、Y之间“协同”变化的关系。也可以说,协方差在某种意义上给出了两个变量线性相关性的强度以及这些变量的尺度。
当 Y Y Y就是 X X X时, c o v ( X , Y ) = c o v ( X ) = v a r ( X ) cov(X,Y)=cov(X)=var(X) cov(X,Y)=cov(X)=var(X)协方差即为方差,这就是我们称其为协方差的原因。1
协方差定义:
c o v ( X , Y ) = E { [ X − E ( X ) ] [ Y − E ( Y ) ] } = E ( X Y ) − E ( X ) E ( Y ) cov(X,Y)=E\{[X-E(X)][Y-E(Y)]\} =E(XY)-E(X)E(Y) cov(X,Y)=E{ [X−E(X)][Y−E(Y)]}=E(XY)−E(X)E(Y)
直观解释
若 c o v ( X , Y ) > 0 cov(X,Y)>0 cov(X,Y)>0,即事件 { X > E ( X ) } ∩ { Y > E ( Y ) } \{X>E(X)\}\cap\{Y>E(Y)\} { X>E(X)}∩{ Y>E(Y)}或 { X < E ( X ) } ∩ { Y < E ( Y ) } \{X
协方差的绝对值如果很大,则意味着变量值变化很大,并且它们同时距离各自的均值很远。
如果协方差是正的,那么两个变量都倾向于同时取得相对较大的值。如果协方差是负的,那么其中一个变量倾向于取得相对较大的值的同时,另一个变量倾向于取得相对较小的值,反之亦然。
样本协方差(sample covariance)
实际应用中,总体 X X X的均值 μ \mu μ、方差 σ 2 \sigma^2 σ2均未知, ( X 1 , X 2 , . . . , X n ) (X_1,X_2,...,X_n) (X1,X2,...,Xn)为取自该总体的一个样本,则样本均值 X ˉ \bar{X} Xˉ是 μ \mu μ的无偏估计量,样本方差 S 2 S^2 S2是 σ 2 \sigma^2 σ2的无偏估计量。
同理,总体 X 、 Y X、Y X、Y的协方差也是一个未知参数,而样本协方差是基于数据得到的估计量。样本协方差是总体协方差的无偏估计。
样本协方差可以用下式计算:
S X Y = ∑ i = 1 n ( X i − X ˉ ) ( Y i − Y ˉ ) n − 1 S_{XY}=\frac{\textstyle\sum_{i=1}^n{(X_i-\bar{X})(Y_i-\bar{Y})}}{n-1} SXY=n−1∑i=1n(Xi−Xˉ)(Yi−Yˉ)
样本方差、样本协方差的分母是n-1而不是n的解释和数学推导可以看下这篇文章。
协方差矩阵(covariance matrix)
随机向量 x ∈ R n \bold{x}\in\R^{n} x∈Rn的协方差矩阵是一个 n × n n×n n×n的矩阵,并且满足:
c o v ( x ) i , j = c o v ( x i , x j ) cov(\bold{x})_{i,j}=cov(x_i,x_j) cov(x)i,j=cov(xi,xj)
协方差矩阵的对角元是方差:
c o v ( x i , x i ) = v a r ( x i ) cov(x_i,x_i)=var(x_i) cov(xi,xi)=var(xi)
代码示例
基于numpy的cov函数2,可以得到协方差矩阵:
import numpy as np
x1 = [-2.1, -1, 4.3]
x2 = [3, 1.1, 0.12]
X = np.stack((x1, x2), axis=0)# 每一行作为一个变量
np.cov(X)
#[out]:array([[11.71 , -4.286 ],
# [-4.286 , 2.144133]])
np.cov(x1, x2)
#[out]:array([[11.71 , -4.286 ],
# [-4.286 , 2.144133]])
np.cov(x1)
#[out]:array(11.71)
或者用公式计算:
def de_mean(x):
xmean = np.mean(x)
return [xi - xmean for xi in x]
def covariance(x, y):
n = len(x)
return np.dot(de_mean(x), de_mean(y)) / (n-1)
covariance(x1,x2)
#[out]: -4.2860000000000005
相关系数(Pearson Correlation Coefficient)
协方差可以描述随机变量之间协同变化的关系,但在使用中存在这样一个问题:例如,要讨论新生婴儿的身高X和体重Y的协方差,若采用两种不同的单位,米和千克或者厘米和克,后者协方差是前者的100000倍!由于量纲的不同导致X与Y的协方差前后不同。
为避免这样的情形发生,将随机变量标准化, X ∗ = X − E ( X ) D ( X ) , Y ∗ = Y − E ( Y ) D ( Y ) X^*=\frac{X-E(X)}{\sqrt{D(X)}},Y^*=\frac{Y-E(Y)}{\sqrt{D(Y)}} X∗=D(X)X−E(X),Y∗=D(Y)Y−E(Y),再求协方差 c o v ( X ∗ , Y ∗ ) cov(X^*,Y^*) cov(X∗,Y∗),这就是随机变量X和Y的相关系数,又称为标准化协方差。1
这是统计学家Pearson提出的用于统计两个随机变量之间线性相关程度的统计量,也叫皮尔逊相关系数(Pearson Correlation Coefficient)。
随机变量 X X X和 Y Y Y的相关系数:
ρ X Y = c o v ( X , Y ) D ( X ) D ( Y ) \rho_{XY}=\frac{cov(X,Y)}{\sqrt{D(X)}\sqrt{D(Y)}} ρXY=D(X)D(Y)cov(X,Y)
设二维随机变量 (X,Y) 的相关系数 ρ X Y ρ_{XY} ρXY存在,则:
- 当 ∣ ρ X Y ∣ = 1 |ρ_{XY}|=1 ∣ρXY∣=1时,(X,Y)的取值(x,y)在直线y=ax+b上的概率为1,称X与Y完全线性相关;
- 当 ρ X Y ρ_{XY} ρXY>0时,称X与Y正线性相关;
- 当 ρ X Y ρ_{XY} ρXY<0时,称X与Y负线性相关。
直观解释
与协方差相比,相关系数(correlation)将每个变量的贡献归一化,为了只衡量变量的相关性而不受各个变量尺度大小的影响。
代码实现
对于矩阵a,numpy.corrcoef(a)可计算行与行之间的相关系数,行为一个随机变量,列为其观测值,输出为相关系数矩阵。3
import numpy as np
x1 = [-2.1, -1, 4.3]
x2 = [3, 1.1, 0.12]
X = np.stack((x1, x2), axis=0)# 每一行作为一个变量
np.corrcoef(X)
#[out]: array([[ 1. , -0.85535781],
[-0.85535781, 1. ]])
除了numpy的函数,pandas对象也装配了常用的数学、统计学方法。这些方法从DataFrame的行或列中抽取一个Series或一系列值的单个值(如总和或平均值)。与NumPy数组中的类似方法相比,它们内建了处理缺失值的功能。4
pandas中Series的corr方法计算的是两个Series中重叠的、非NA的、按索引对齐的值的相关性。cov计算的是协方差。
pandas中DataFrame的corr和cov方法会分别以DataFrame的形式返回相关性和协方差矩阵。5
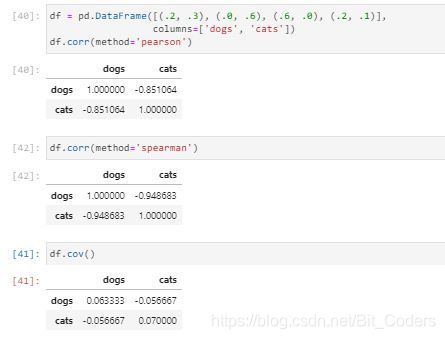
import pandas as pd
df = pd.DataFrame([(.2, .3), (.0, .6), (.6, .0), (.2, .1)],
columns=['dogs', 'cats'])
"""
计算相关系数,支持三种方法
pearson : standard correlation coefficient
kendall : Kendall Tau correlation coefficient
spearman : Spearman rank correlation
"""
df.corr(method='pearson')
"""
计算协方差矩阵
"""
df.cov()
输出:
《概率论与数理统计》 ↩︎ ↩︎
https://numpy.org/doc/stable/reference/generated/numpy.cov.html ↩︎
https://zhuanlan.zhihu.com/p/35122515 ↩︎
《利用python进行数据分析》 ↩︎
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.corr.html ↩︎