2018-4-8免疫算法(Immune IA)
学习资料来源:
【图文】免疫算法_百度文库
https://wenku.baidu.com/view/39eb47ec551810a6f52486ee.html?sxts=1523143415445
《智能优化算法以及matlab实现》包子阳,余继周 编著
自己觉的好资源,但是看不懂
三种人工免疫算法综述_图文_百度文库
https://wenku.baidu.com/view/e84991b3f242336c1fb95e27.html
就是在阅读包子阳老师的那本书的时候会觉的自己动了,但是在看网上的就就的自己看的不是一个版本。很纠结啊。不过包老师的确实讲的很明了。
生物免疫系统是一个分布式、自组织和具有动态平衡能力的自适应复杂系统。它对外界入侵的抗原,可由分布全身的不同种类的淋巴细胞产生相应的抗体,其目标是尽可能保证整个生物系统的基本生理功能得到正常运转。具有较强模式分类能力,尤其对多模态问题的分析、处理和求解表现出较高的智能性和鲁棒性。
1、发展
(1)1958年澳大利亚学者Burnet率先提出了与免疫算法相关的理论-------克隆选择原理
(2)1973年Jerne提出免疫系统的模型,基于Burnet的理论,拆创了独特的网络理论,给出了免疫系统的数学框架,并采用微分方程建模来方阵淋巴细胞的动态变化
(3)1986年Farmal 等人基于免疫网络学说理论构造出的免疫系统动态模型,展示了免疫系统与其他人工智能方法嘉禾的可能性,开创了免疫系统研究的先河。
2.生物免疫系统中的基本的概念
(1)免疫系统

(2)抗原

(3)抗体

(4)T细胞和B细胞
B细胞受到抗原的刺激之后,可以产生大量的浆细胞,而浆细胞具有合成以及分泌抗体的功能(抗体直接与抗原PK)。但是B细胞自己并不能识别抗原,需要接触能够识别抗原的T细胞
(5)生物免疫系统机理
生物免疫系统是由免疫分子,免疫组织和免疫细胞组成的复杂的系统。这些组成免疫系统的组织或器官分布在人体各处,用来完成各种免疫防卫功能
(6)免疫识别
本质就是区分“自己”和“非己”,免疫识别是通过淋巴细胞上的抗原受体与抗原的结合实现的
(7)免疫学习
免疫识别的过程,同时也是学习的过程,学习的结果就是免疫细胞的个体个体亲和度提高,群体规模扩大,并且最优个体以免疫记忆的形式保存(也就是最优的额抗体??、)
(8)免疫记忆‘
当免疫系统初次的遇到抗原时候,淋巴细胞需要一定的时间进行调整去识别抗原,当识别结束后以最有抗体的形式保存对抗原的记忆信息。二挡免疫系统再次遇到相同或结构相似的抗原,在联想记忆的作用下,可以进行快速的应答
(9)克隆选择
免疫应答和免疫细胞的增值在一个特定的匹配阈值上发生。当淋巴细胞实现对抗元的识别,B细胞被集火并增值肤质产生克隆B细胞,随后克隆细胞经历变异过程,产生对抗原具有特异性的抗体
(10)个体多样性
免疫系统有100多种不同的蛋白质,但是外在待识别的模式种类有1000多种就需要抗体多样性的组合机制
(11)免疫调节

3.免疫系统的工作模型:
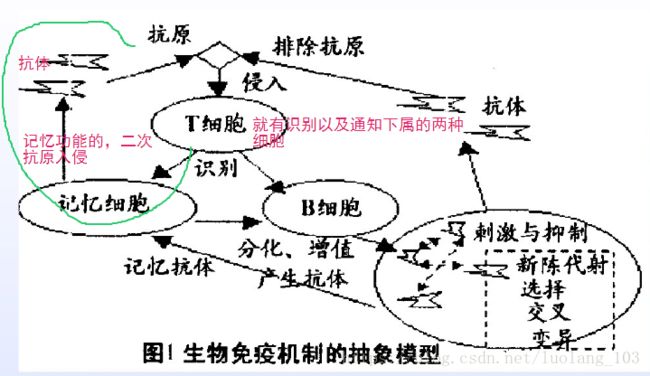
4.免疫系统以及免疫算法的比较
网上的:
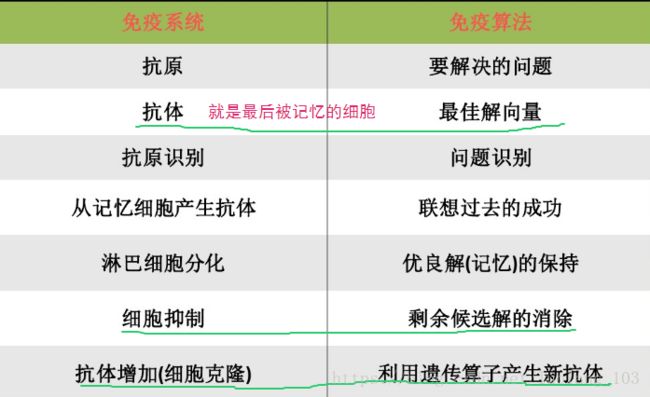
包子阳书籍内容:

而根据包子阳书籍中的对应关系,算法主要的包括以下的几个模块:
(1)抗原识别与初始抗体产生。根据待优化问题的特点设计合适的抗体编码规则,并在此编码下利用问题的先验只剩产生初始抗体种群
(2)抗体评测:对抗体质量进行评价,评价的准则主要包括抗体的亲和度和抗体浓度,评价得出的优质抗体将进行免疫操作,劣质抗体被更新
(3)免疫操作。
免疫算子
(1)亲和度算子:
表征免疫细胞与抗原的结合程度(也就是可行解与待解决问题的结合的程度)。通常函数优化问题可以使用函数的值或者是函数值的倒数作为亲和度评价。aff(x)
----
(2)抗体浓度的评价算子
抗体浓度的是表征抗体种群的多样性好坏。抗体的浓度过高意味着种群中非常类似的个体大量存在,寻优就会集中与一个可行区间的一个区域,不利于全局寻优。
抗体浓度的定义:


抗体间亲和度(表征抗体之间的相似程度)的计算:
基于欧式矩离的抗体间亲和度的方法:
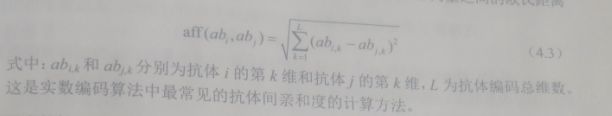
基于海明矩离的抗体-抗体亲和度计算方法

海明矩离:就是抗体A与抗体B的属性值相同的时候才为1,否则为0,然后进行累加的操作。总的来说就是描述其内部属性完全相同的个数的多少啊
(3)激励计算算子
抗体激励是对抗体质量的最终评测结果,需要综合考虑抗体亲和度和抗体浓度,通常亲和度大,浓度低的抗体会得到较大的激励度。
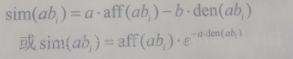
![]()
(4)免疫选择算子
免疫选择算子根据抗体的激励度确定选择那些抗体进入克隆选择操作。激励度高的抗体个体具有更好的质量,更有可能被选中进行克隆选择操作
克隆算子
变异算子
实数编码算大变异算子
克隆抑制算子
种群刷新算子
书本的内容:


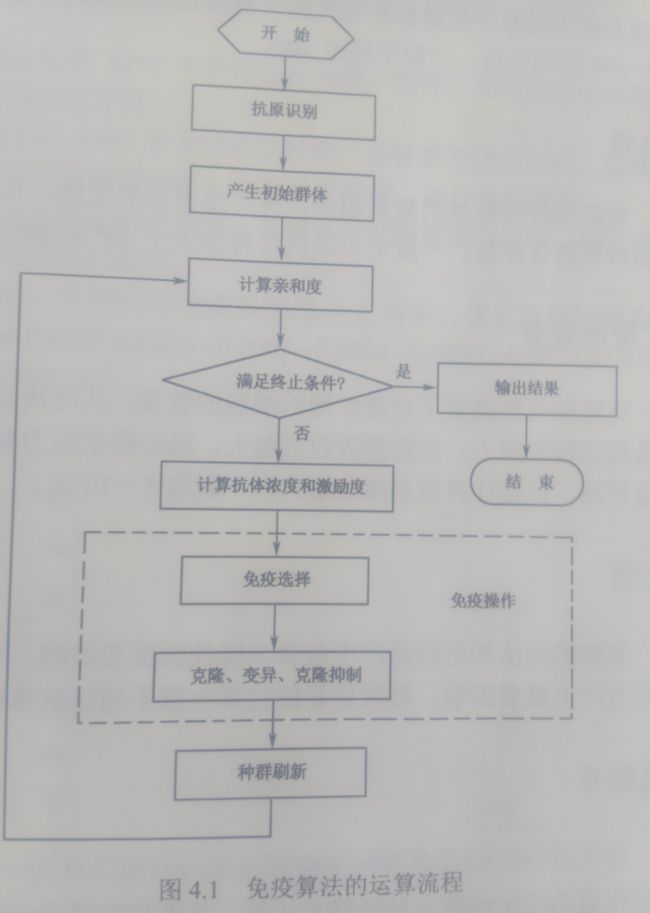
5.算法的流程:
目前没有同一的免疫算法的流程以及框图,以下是对应以上各种的免疫算子的算法流程
(1)进行抗原识别,也就是理解优化的问题------抗原对应的就是待解决的问题.对问题进行分析,提出先验知识,构造合适的亲和度函数,并制约各种约束条件
(2)产生初始抗体群,通过编码将问题的可行解表示成解空间的抗体,在解空间中随机的产生一个初始的种群(其实说的解空间也就是x的取值,而我们最初的设置初始种群就是在解中找到几个起始的位置)
(3)对种群中每一个可行解进行亲和度评价
(4)判断是否满足终止条件,满足条件终止算法寻优过程,输出计算结果
(5)计算抗体浓度以及激励度
(6)进行免疫处理。
免疫选择:根据种群中抗体的亲和度和浓度计算结果选择优质抗体,使其活化
克隆:对活化的抗体进行克隆复制,得到若干副本
变异:对克隆得到的副本进行变异操作,使其发生亲和度突变
克隆抑制:对变异结果进行再选择,一直亲和度低,保留亲和度高的
(7)种群刷新
以随机生成的新抗体替代种群中激励度低的抗体,形成新一代抗体,转到步骤三
流程图:
自己的感想:
无论是哪种算法无非就是怎样的选择个体(或许是每一代的个体,或许是一个大的群体)也就是类似于采样了
采样之后就是怎样的去评价这个采样的结果的好坏
然后再循环的采样直到找到评价函数最好的那一个---而所谓的记忆应该就是有些函数在采样的时候会记录每一代中的最优的个体。有的时候真的想让自己什么都懂,总觉的自己是一个白痴,好吧,还是慢慢的踱步前行吧